- The paper introduces XtraMAC, which decomposes mixed-precision MAC operations into a common integer multiplication core to optimize DSP utilization.
- It employs lane packing and cycle-level runtime datatype switching to support up to four concurrent MAC operations per DSP, ensuring constant throughput.
- Evaluations on an AMD Xilinx U55c FPGA demonstrate 1.4–2.0× compute density improvements and up to 1.9× enhanced energy efficiency in LLM GEMV integration.
XtraMAC: An Efficient MAC Architecture for Mixed-Precision LLM Inference on FPGA
Introduction and Motivation
The increasing adoption of mixed-precision quantization in LLMs has led to a diversity of MAC patterns that mix integer and floating-point datatypes, with frequent runtime switching between them. Existing FPGA MAC solutions, including both upcasting methods and runtime reconfigurable designs, are fundamentally limited by poor DSP utilization and hardware resource inefficiency, especially as LLM quantization trends exacerbate operand heterogeneity (Figure 1).

Figure 1: Distribution of MAC operations during the decode stage for various quantized LLM checkpoints; each segment corresponds to a unique MAC configuration, demonstrating the heterogeneity introduced by practical LLM quantization schemes.
Traditional approaches for supporting mixed-precision or runtime datatype switching on FPGAs have relied either on operand upcasting—leading to significant DSP under-utilization—or on spatial/temporal hardware sharing, which incurs high area overhead or severely restricts parallelism. Quantitative analysis reveals that standard vendor MAC IPs utilize only 26.7--32.4% of DSP resources in such scenarios, while temporal sharing architectures can degrade utilization to below 10% for high-precision operations (Figure 2, Figure 3).
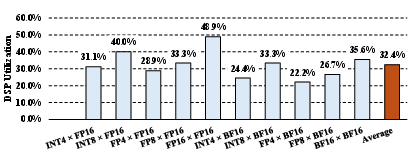
Figure 2: DSP utilization of upcasting-based designs under different mixed-precision datatype combinations (FP8 = E4M3, FP4 = E2M1), illustrating how operand promotion leads to wasted multiplier bits.
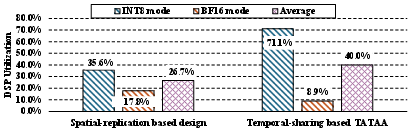
Figure 3: DSP utilization comparison of existing FPGA-based MAC architectures supporting runtime datatype switching. Spatial replication and temporal sharing both achieve poor effective DSP utilization for heterogeneous workloads.
These limitations motivate the XtraMAC architecture, which seeks to unify integer, floating-point, and mixed-precision MAC support within a single, datatype-adaptive hardware datapath that closes the utilization gap while exposing maximal parallelism.
XtraMAC Architectural Design
The central insight behind XtraMAC is a microarchitecture that decomposes all supported MAC operations—integer, floating-point, and mixed-precision—into a common integer mantissa multiplication with lightweight, configurable sign and exponent handling. This formulation allows datatype adaptation to occur in peripheral logic, decoupling structural arithmetic from numerical semantics.
Processing Pattern Abstraction
All MAC operations, expressed as P=A×B+C, are mapped to three steps:
- Extraction of operand sign, mantissa, and exponent fields, with special rules for integer-to-floating-point scenarios.
- Packing of multiple mantissas into a single DSP multiplier input, enabling fine-grained lane-based parallelism within a DSP slice.
- Lightweight sign/exponent post-processing, normalization, and per-datatype accumulation via separate integer or FP adders.
This design permits multiple mixed-precision MAC lanes to simultaneously utilize a single DSP, maximizing throughput subject to input bitwidth constraints. The architecture is realized as a four-stage pipeline supporting cycle-level datatype switching without any pipeline stalls or reconfiguration delays (Figure 4).
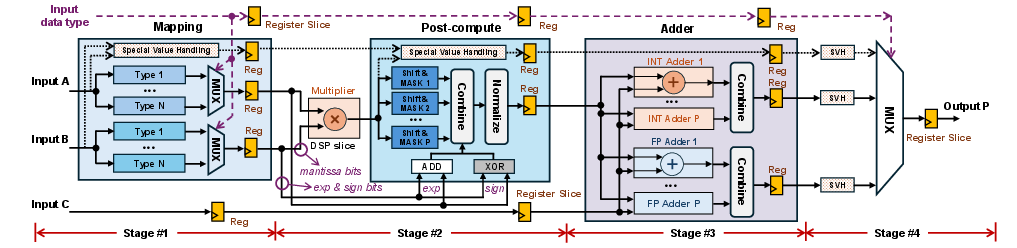
Figure 4: Overview of the XtraMAC architecture supporting N datatype combinations and up to P-way parallelism per DSP.
Parallel Mixed-Precision MACs and Lane Packing
Rather than processing only a single fixed-precision multiply-accumulate per DSP, XtraMAC uses bit-level operand packing and lane extraction (as in Eq. (dsp_pack) and (dsp_cross)) to perform up to four concurrent MAC operations (for sub-8b datatypes) within the same DSP hardware, constrained only by the multiplier's input width. Per-datatype mapping logic handles bit offset assignment and normalization, ensuring strict lane isolation.
Peripheral logic (LUT/FF usage) is kept minimized via analytical design of barrel shifters and adders, with separate circuits for integer and floating-point accumulation to prevent resource blow-up (Figure 5, Figure 6).
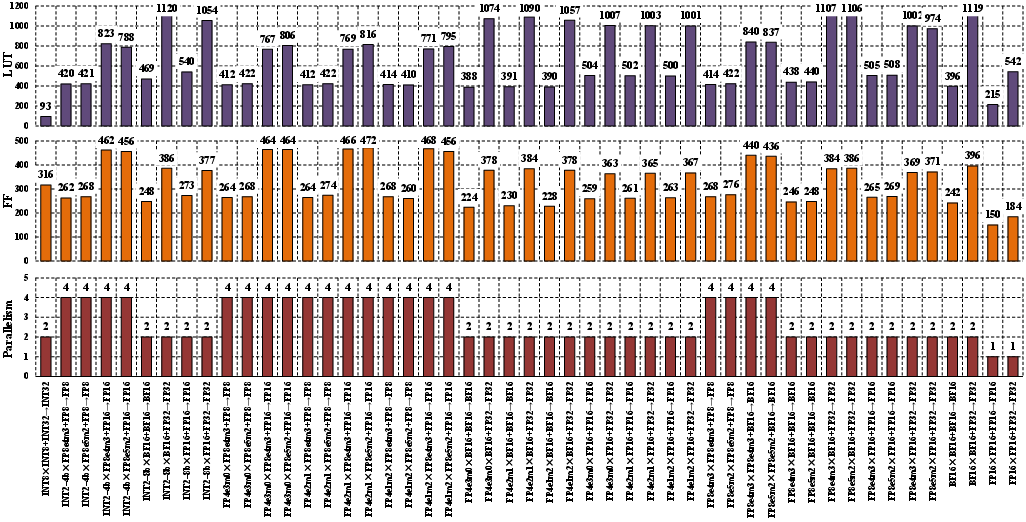
Figure 5: Resource consumption and parallelism of XtraMAC across all A×B+C→P configurations. High parallelism is achievable for sub-8b data types, with constant pipeline latency and initiation interval.
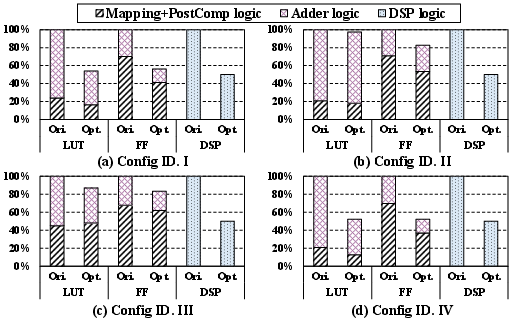
Figure 6: Normalized resource breakdown for various runtime-switching configurations, highlighting the relative overhead due to mapping, arithmetic, and adder logic for each mixed-precision combination.
Runtime Datatype Switching
A key property is that datatype adaptation (switching between, e.g., INT4×BF16 and BF16×BF16) occurs every cycle via a pipeline-aligned control signal, without requiring hardware reconfiguration or pipeline flushes. The architecture maintains constant throughput and latency (four cycles, II=1) regardless of datatype or precision.
Exception handling for IEEE-special values (NaN, inf, subnormals) is integrated as non-blocking sideband logic, ensuring that pipeline timing is not perturbed by exceptional cases.
Evaluation
Hardware Efficiency and Resource Utilization
Under comprehensive evaluation on an AMD Xilinx U55c FPGA:
- XtraMAC reduces per-operation LUT/FF/DSP consumption by 27–51% compared to state-of-the-art vendor IP and temporal sharing baselines.
- Packaged in GEMV kernels, XtraMAC provides 1.4–2.0× improvement in compute density over standard designs (Table: mixed_precision_comparison; Figure 7).
- Frequency overhead vs. vanilla MACs is modest (≈22% decrease; >400MHz easily sustained), while per-DSP throughput is improved by 1.56× due to increased lane-level parallelism (Figure 8).
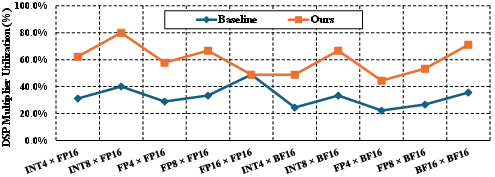
Figure 7: DSP utilization under different data types (FP8=E4M3, FP4=E2M1). Sub-8b modes achieve near-ideal utilization via lane packing.
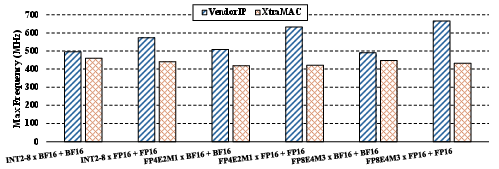
Figure 8: Maximum frequency comparison; XtraMAC's denser datapath causes moderate Fmax reduction, but delivers net throughput gain per DSP.
Scalability experiments confirm that adding support for more mixed-precision modes increases only peripheral LUT/FF cost, while the DSP core is fully shared across all configurations (Figure 9).
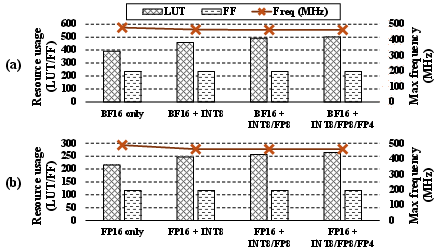
Figure 9: LUT usage only increases modestly as datatype support is expanded; DSP occupancy remains optimal.
System-Level LLM Inference—GEMV Integration
A practical evaluation instantiates tile-based GEMV pipelines with XtraMAC, directly replacing scalar MAC units in an HBM-driven array architecture (Figure 10). For key LLM GEMV kernels (e.g., INT4×BF16, FP4×BF16), XtraMAC-based implementations achieve 1.2× speedup versus a H100 GPU's highly optimized INT4/FP8 GEMV routines using equivalent memory bandwidth (Table: mixed_gemv_perf), and achieve up to 1.9× energy efficiency improvement.
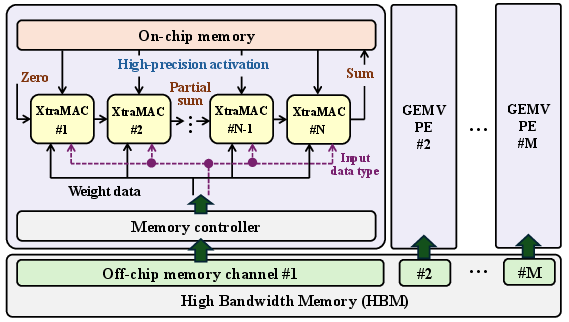
Figure 10: A mixed-precision GEMV architecture based on XtraMAC.
At large batch sizes, where arithmetic unit density rather than memory bandwidth constrains throughput, XtraMAC's improved packing enables 1.5×–1.8× reductions in end-to-end LLM decode-stage latency on large Transformer models (Figure 11).
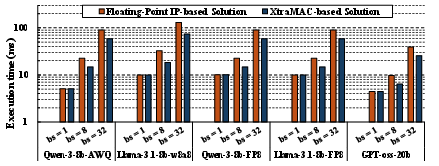
Figure 11: Decode-stage execution time for different LLM workloads at context length 512 and batch sizes {1,8,32}; substantial speedup is realized at high batch sizes as compute resource density becomes the bottleneck.
Implications and Future Directions
XtraMAC meaningfully closes the gap between hardware efficiency and software quantization trends found in practical LLM deployments. By generalizing mixed-precision execution onto a compact, invariant MAC core, designers can aggressively deploy sub-8b quantization, dynamically switch numeric formats to suit workload demands, and maximize FPGA resource utilization—directly translating into lower inference latency and improved energy efficiency. The open-sourced implementation further enables future extensions in dynamic reconfigurability, finer granularity packing, or integration with next-generation DSP slice architectures.
As quantization schemes in LLMs evolve to exploit even more diverse and hardware-specific numeric representations (e.g., per-layer/per-token adaptivity), architectures such as XtraMAC that cleanly separate numerical semantics from parallel datapath scheduling will likely become the new baseline for FPGA and adaptive hardware LLM acceleration. Similar hardware principles may influence future ASIC or SoC designs for mixed-precision ML workloads.
Conclusion
XtraMAC demonstrates that the central bottleneck in mixed-precision LLM inference on FPGAs—inefficient DSP utilization—can be systematically addressed by decomposing MAC computation into a shared integer-multiplier core with datatype-specific peripheral mapping. This approach produces substantial gains in hardware efficiency: 1.4–2.0× higher compute density per resource, up to 1.9× better energy efficiency, and sublinear resource scaling with increased datatype coverage, while supporting cycle-level runtime adaptation. These improvements position XtraMAC as a key architectural primitive for future LLM inference workloads on FPGAs and similar reconfigurable platforms.

