- The paper presents a systematic evaluation showing that reasoning-enabled high-level VLM planners greatly improve performance in long-horizon, semantic robotic tasks.
- The paper demonstrates that steerable, high-capacity low-level VLAs preserve command fidelity, while excessive fine-tuning risks overfitting and reduces generalization.
- The paper reveals that adaptive success detection and augmented observation encoding are critical for effective hierarchical coordination, outperforming monolithic VLA designs.
Systematic Dissection of Hierarchical Vision-Language-Action Architectures for Robotic Manipulation
Introduction and Motivation
This paper presents a comprehensive empirical study into the operational factors underpinning hierarchical Vision-Language-Action (Hi-VLA) systems in robot manipulation. Hi-VLAs, composed of a high-level Vision-LLM (VLM) planner and a low-level VLA controller, are an emerging paradigm to address compositionality, reasoning, and high-level task decomposition deficiencies in monolithic VLA models. The lack of standardized design choices and scant causal understanding across the VLM-VLA interface, termination schemes, observation representations, and memory encodings has impeded progress toward robust and generalizable hierarchical robotic controllers. This work formalizes a unifying options-style control loop and systematically benchmarks the critical axes of Hi-VLA agent design across a spectrum of manipulation tasks.
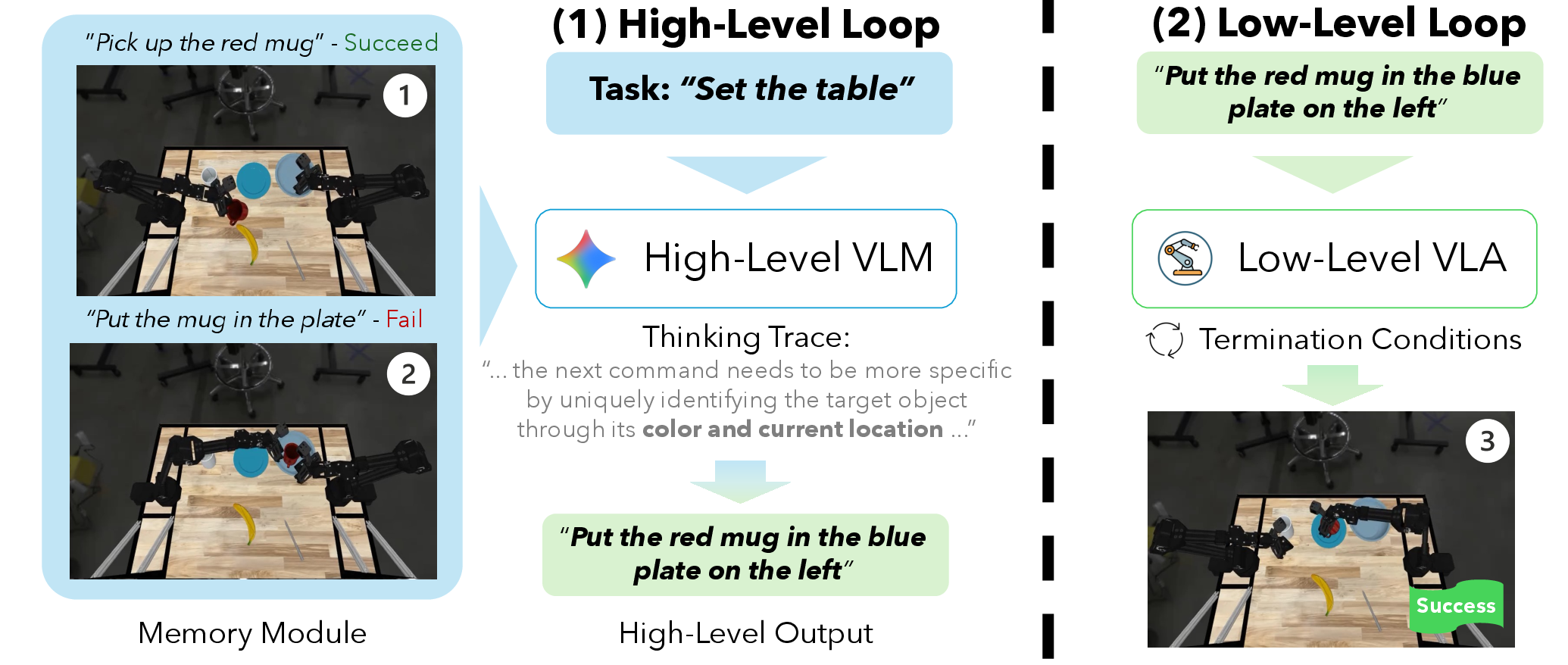
Figure 1: Hi-VLA systems compensate for low-level VLA limitations by generating contextually-appropriate commands, enabling compositional generalization for high-level tasks.
Unified Control Architecture for Hierarchical VLAs
The core architectural insight is the mapping of heterogeneous Hi-VLA systems onto a formal options framework. In this abstraction:
- The high-level VLM serves as an option selector, inferring task-aligned subgoal commands from rich observations and task instructions.
- The low-level VLA executes these commands as temporally extended actions, grounded in sensorimotor feedback.
- Control transfer between VLM and VLA is governed by a termination condition (e.g., success detection).
- Observation pipelines and memory modules mediate what state information reaches the VLM.
This schema enables precise isolation and equitable evaluation of each system component by holding all but the variable under test constant, thus unifying comparative analysis.
Experimental Framework
Experiments are conducted predominantly in MuJoCo-based ALOHA manipulation environments, augmented with real-world ALOHA robot trials for ecological validity. The benchmark includes three task genres:
- Short-horizon: atomic skills, commensurate with VLA training data distributions
- Long-horizon: multi-step, compositional, and temporally extended objectives
- Reasoning: tasks demanding abstraction, indirect instruction following, or semantic inference
Design variables under study include VLM capacity and reasoning mode, VLA model size and fine-tuning strategies, termination mechanisms, observation encoding strategies (textual and privileged), and memory context/summarization approaches.
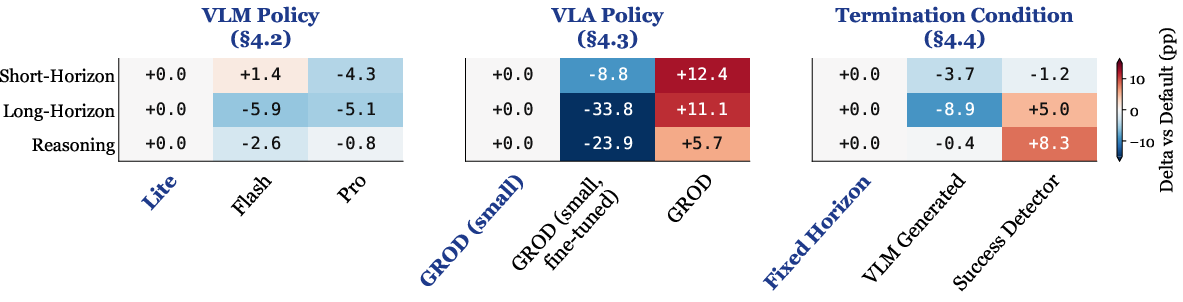
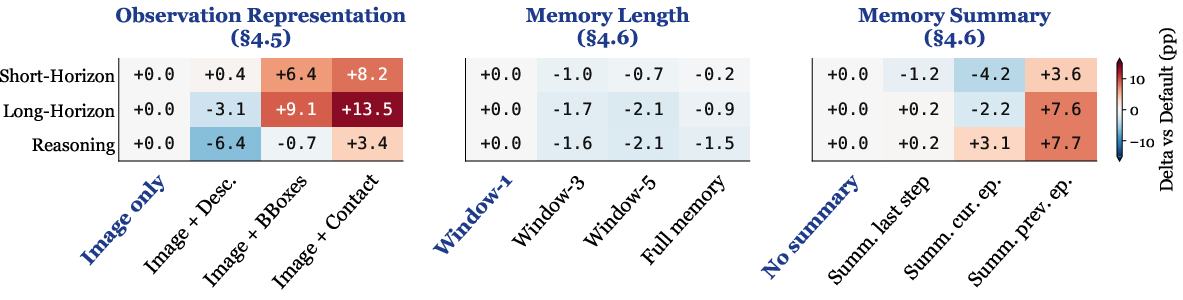
Figure 2: Visualization of how varied design choices modulate Hi-VLA system performance across task categories.
Analysis of Key System Components
1. High-Level VLM Policy: Reasoning Capabilities Dominate
The results validate that VLMs with explicit step-by-step reasoning ("thinking") substantially elevate Hi-VLA performance, especially for long-horizon and semantic tasks. Notably, increasing the underlying VLM size (Lite vs. Flash vs. Pro) confers negligible further benefit when reasoning is enabled. This indicates that, within current robotic task regimes, reasoning depth outstrips model platitude or capacity as the key driver of effective high-level orchestration.
2. Low-Level VLA Policy: Model Capacity and Steerability
The VLA model size exerts a pronounced influence on overall success. Steerable large VLAs preserve command-following fidelity and compositionality, while excessive domain-specific fine-tuning (notably on in-domain simulation data) degrades such capabilities via overfitting and reduced instruction invariance. The findings underscore that for seamless VLM-VLA integration, the low-level module's generalization and robustness to language variation are critical and can be fragile under naive fine-tuning procedures.
3. Termination Mechanism: Success Detection as a High-Leverage Hyperparameter
The termination condition dictates when control is handed back from VLA to VLM. A learned or privileged "success detector"—even when moderately inaccurate—yields robust performance over naïve periodic or fixed-horizon switching. However, excessively long low-level horizons can induce timeouts and performance collapse on compound tasks, and inaccuracies with high false positive rates disproportionately degrade outcomes by inappropriately advancing task stages.
Encoding raw images as summarized textual scene descriptions, especially those incorporating bounding box outputs or simulator-provided contact states, renders the VLM planner vastly more effective. This outcome highlights a notable deficiency in VLM perceptual grounding and spatial reasoning: the pipeline benefits from explicit, structured information that, while technically redundant with the visual input, shields the planner from typical VLM weaknesses such as "image neglect" under challenging scenarios.
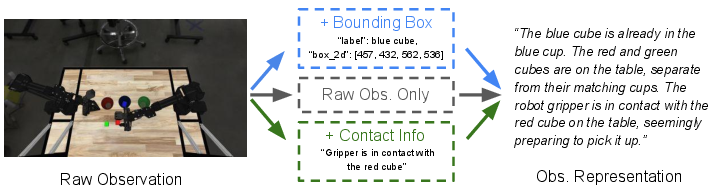
Figure 3: Illustration of observation encoding strategies: naive VLM image query, bounding box augmentation, and addition of privileged contact data.
5. Memory and Episodic Summarization: Mixed Benefit for In-Episode, High Utility for Cross-Episode
VLM performance is largely invariant to the memory window size, and in-episode memory, even if summarized, does not offer consistent gains. In contrast, cross-episodic knowledge distillation—summarizing affordances or lessons from prior successful episodes—yields notable improvements, indicating that current VLMs remain limited in in-context learning within episodes but can capitalize on distilled knowledge across temporal boundaries.
Empirical Synthesis and Cross-Category Gains
The aggregation experiment assembles a "best-of-breed" Hi-VLA architecture using the optimal component choices from prior ablations (thinking VLM, steerable VLA, success detection, contact-augmented scene summary, cross-episodic summary). Performance is compared against both a flat VLA and a "naive" Hi-VLA (no memory, direct image input, no VLM thinking, fixed-horizon termination). Results reveal:
- Even a naïve hierarchical decomposition reliably outperforms a monolithic VLA, confirming the fundamental value of modular orchestration.
- However, as task complexity rises (especially in long-horizon scenarios), the performance gap between well-designed and naïve Hi-VLA agents becomes acute, demonstrating that careful system-level decisions are required for compositional and semantic generalization.




Figure 4: Example manipulation task context ("Dining Scene") representative of the perceptual complexity in the benchmark suite.
Furthermore, experiments with a scripted, "perfect" VLA indicate that ablations in hierarchy or interface design can degrade near-perfect success to failure, justifying the enduring role of orchestration even as low-level policies grow more accurate.
Real-World Transfer
Experiments on the real ALOHA platform confirm simulation findings, with hierarchical agents demonstrating both recovery skills and task success across multiple real object placements and error recovery steps.








Figure 5: A step in the ALOHA real-robot manipulation sequence, demonstrating hierarchical policy orchestration in action.
Theoretical and Practical Implications
This work provides an operational foundation for principled design and diagnosis of Hi-VLA agents. It rigorously refutes the notion that improvements to monolithic VLAs obviate the need for hierarchy; rather, the bottleneck is shifted but not removed. Success detection, spatially-aware state summarization, and cross-episode memory distillation are identified as high-leverage axes.
Practically, the results establish a roadmap for modular, robust, and generalizable robotic controllers, prioritizing reasoning-enabled planners, instruction-invariant controllers, and rich, structured interfaces. Theoretically, the findings suggest open research challenges in VLM grounding, memory-based learning, and online policy improvement via hierarchical feedback, potentially integrating reinforcement learning to further close the loop between high-level planning and low-level execution.
Conclusion
This systematic evaluation of Hi-VLA system design distills actionable principles for advancing robotic policy orchestration. Critical factors include reasoning-enabled VLM planners, robust and steerable VLAs, adaptive success detection, spatially augmented observations, and episodic knowledge summarization. The framework and conclusions here provide a benchmark for future work, suggesting that as low-level policies mature, the need for principled hierarchical design—especially around interfaces and episodic integration—will persist as a central requirement for embodied intelligence (2606.10267).