- The paper introduces M³Exam, a benchmark for evaluating long-term multimodal memory in realistic, multi-session user-agent interactions.
- The methodology integrates staged LLM-driven dialogue synthesis with explicit modality bias detection and cascaded retrieval to assess cross-modal reasoning and implicit inference.
- Results show that modality-aware retrieval in M³Proctor dramatically reduces token costs and improves accuracy compared to global retrieval methods.
Multimodal Conversational Memory Evaluation with M3Exam
Motivation and Benchmark Construction
Addressing the gap in evaluating long-term multimodal memory capabilities for task-oriented agents, M3Exam establishes a comprehensive benchmark for realistic, persistent, heterogeneous user–agent interactions. Unlike prior work, which is either text-only, static with sparse visuals, or limited to single-session/single-document memory scopes, M3Exam models the organic accumulation and use of multimodal memory over extended, multi-session user histories (Figure 1).
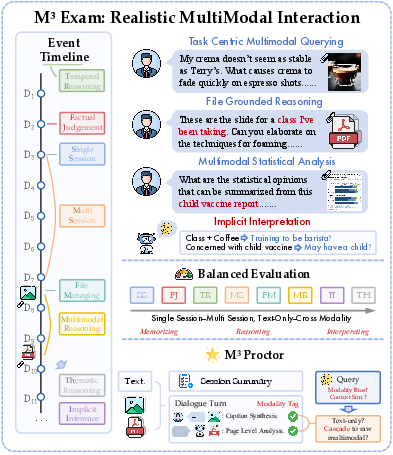
Figure 1: Overview of M3Exam, emphasizing its long-horizon, cross-modality conversational scope.
The M3Exam benchmark is constructed to capture the following evaluation axes:
- Content Complexity: Agents must sustain memory over 239 synthetic multi-session conversations, each spanning 15 distinct persona scenarios and covering 3,025 dialogue rounds, with 1,799 multimodal artifacts (images, PDFs, charts). The sessions are heterogeneously structured, with attached files spanning technical documents, daily-life photos, and domain-specific charts.
- Temporal and Cross-Modal Reasoning: 5,150 evaluation questions are carefully balanced across single-session, multi-session, cross-modal, retrieval, and interpretation-oriented tasks. Ground-truth supporting-fact annotations pinpoint the cross-session span and modalities for each query.
- Implicit Inference: Unlike benchmarks limited to direct QA, M3Exam includes questions demanding inference from unstated, globally distributed, or persona-grounded cues, requiring agents to reconstruct the user’s latent intent or contextual state.
The benchmark features rigorous pipeline synthesis (Figure 2), combining staged LLM-driven event generation, event-to-session mapping, dialogue and artifact alignment, and question bank synthesis, with extensive validation overlays (self-checks, expert audits).
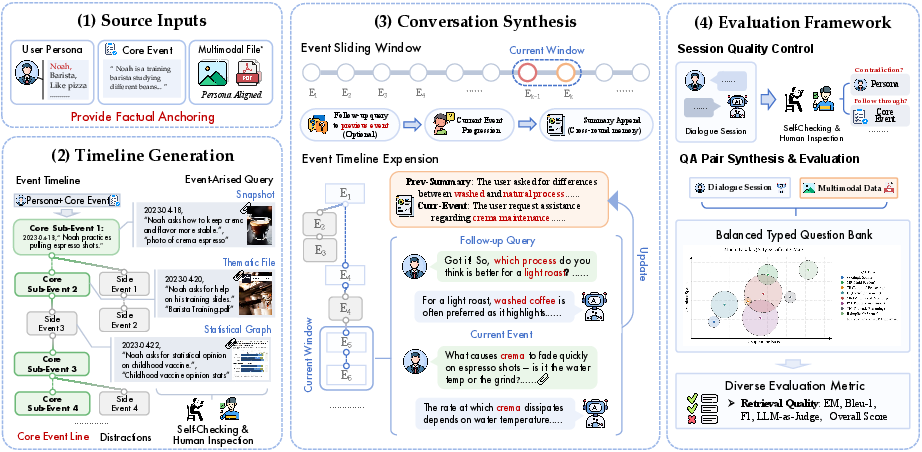
Figure 2: The M3Exam construction pipeline: from persona and event seeds to synthetic multimodal dialogues and QA.
M3Exam’s distribution is methodically balanced at the persona, question-type, and artifact levels (Figures 6, 7, 8):
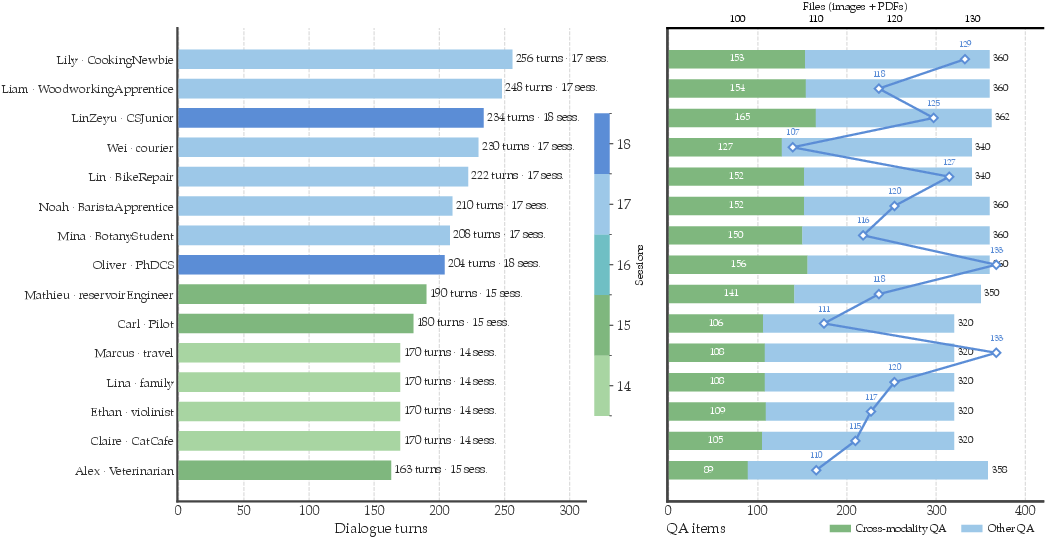
Figure 3: Scaling properties per persona; coverage of dialogue size, QA instances, and file attachment across scenarios.
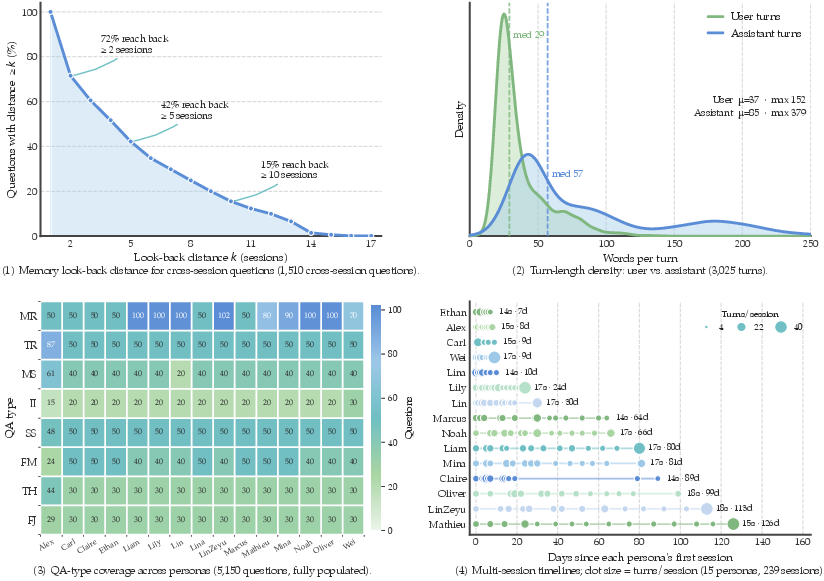
Figure 4: Properties such as memory look-back distributions, turn-length densities, QA-type per persona, and session timelines.
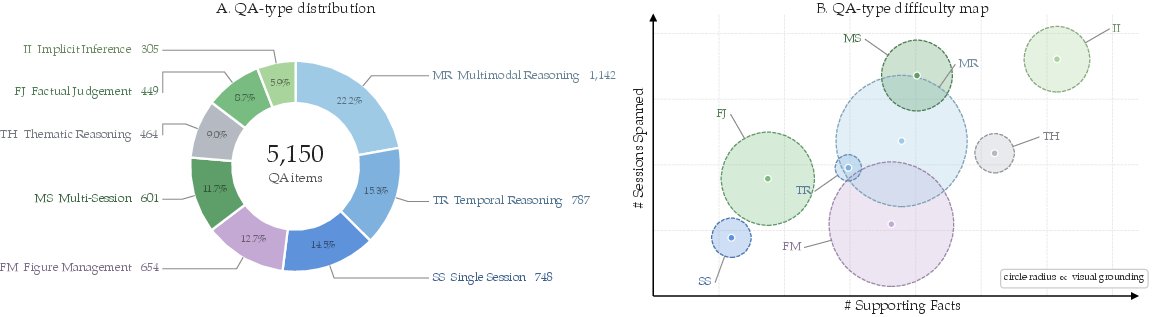
Figure 5: QA composition, with separation by difficulty, evidence load, memory span, and visual dependence.
Benchmark Protocol and Evaluation Metrics
M3Exam defines the agent’s task as: given a temporally ordered multimodal history H, answer query 30 by retrieving relevant spans and artifacts and emulating human-like inference. Evaluation focuses sharply on capabilities that probe long-range memory and cross-modal reasoning, using a suite of metrics:
- Exact Match (EM, including image identifier matching and multiple-choice)
- F1 (token-level overlap)
- BLEU-1
- LLM-as-a-Judge (LLM-J): five-level rubric assessing semantic adequacy beyond lexical overlap
All metrics are reported by question subtype and aggregated into a weighted overall score, with particular emphasis on the LLM-J metric for compositional, open-ended tasks. The design controls for reasoning quality rather than mere retrieval by providing “oracle” supporting facts during closed-book evaluation and contrasting with long-context ingestion policies (Figure 6).
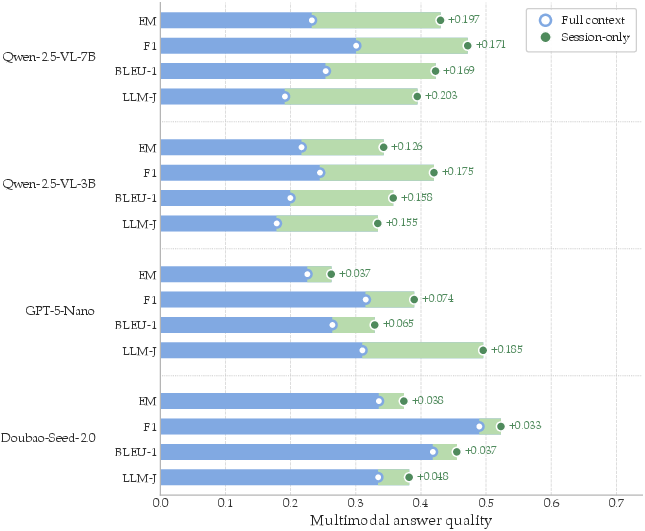
Figure 6: Performance penalty when answering from the full conversation history versus the supporting sessions only, isolating the importance of targeted retrieval.
Agentic Memory Systems and Multimodal Modality-Aware Baseline
Baseline methods span text-only and multimodal retrieval-augmented architectures, including NaiveRAG, A-Mem, Mem0, MemoryOS, UniversalRAG, RAG-Anything, MIRIX, MemVerse, and NGM. Notably, M31Exam exposes the brittleness of context-insensitive “global” retrieval for memory over heterogeneous, temporal dialogue.
The authors introduce M32Proctor: the first open multimodal memory system that incorporates query modality bias, performing explicit bias detection (by instruction-tuned LLMs), re-ranking retrieval by modality, and modality-aware cascaded retrieval (Figure 7). The pipeline (indexing, retrieval, escalation) is optimized for minimal reliance on raw visual input unless necessary for answer quality, dramatically reducing token and compute costs.
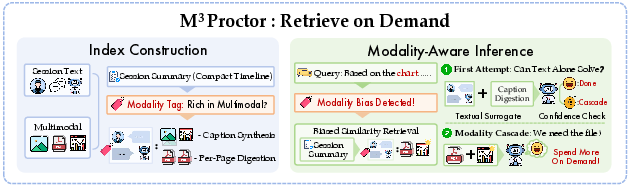
Figure 7: Architecture of M33Proctor, which detects query modality demand and escalates to raw artifacts only as required.
Cascade behaviors are measured in detail (Figure 8), demonstrating that visual input is consumed almost exclusively for those QA types that require it, while most queries are resolved in the text surrogate regime—preserving both efficiency and accuracy.
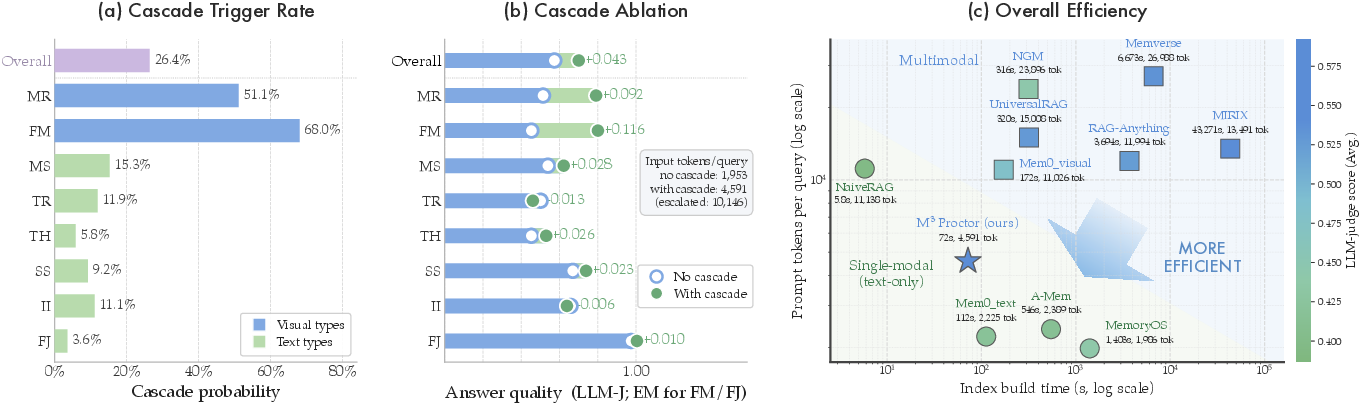
Figure 8: Ablation studies and efficiency/performance tradeoffs for M34Proctor’s modality cascading.
Main Results and Analysis
M35Exam’s evaluation reveals that even state-of-the-art MLLMs (GLM-5.1, Qwen3.6-Plus, GPT-5.4, Claude-Opus-4.6, Gemini-3.1-Pro, etc.) fail to exceed an overall semantic score of 0.55 in an oracle-evidence setting (Figure 9), while agentic-memory baselines fall even shorter absent modality-awareness. The largest performance gaps appear for cross-modal grounding (mr, fm-type queries) and implicit interpreting (thematic th, implicit-inference ii), with open-ended failures persisting even for long-context “buffer” policies.
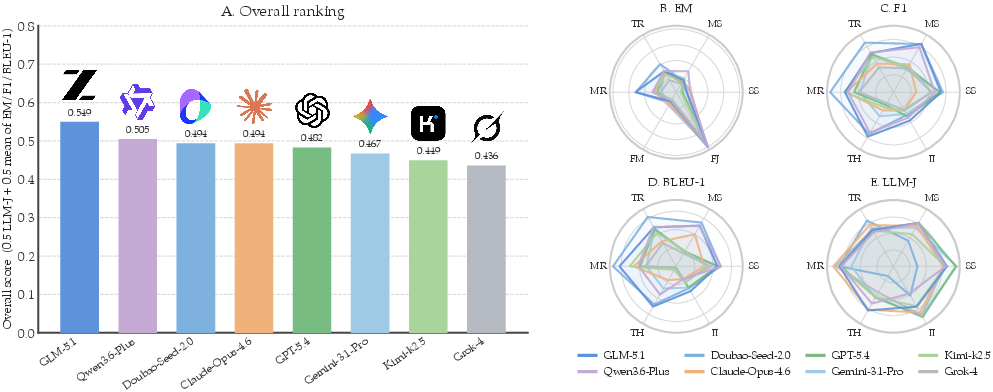
Figure 9: Performance landscape for eight leading closed-source MLLMs, reporting per-type, per-metric breakdowns.
M36Proctor achieves the highest score among open-weight agentic-memory systems across all backbones (Qwen-2.5-VL-7B, GPT-5-Nano, Doubao-Seed-2.0-Pro), closing the gap to frontier MLLMs primarily on cross-modal and implicit-inference categories. Critically, it does so with a 72x reduction in index construction time and a 3–10x reduction in per-query token use compared to indiscriminate multimodal memory architectures.
Performance is robust to backbone scale: M37Proctor run on 3B or 7B backbones outperforms stronger baselines on larger models, underscoring that gains stem from modality-aware retrieval and not backbone size.
Analysis (Figure 10) reveals that performance lift from true multimodal evidence reaches +0.3 EM for mr-type and +0.116 for fm-type questions. The modality cascade triggers on 68% of fm and 51% of mr queries, confirming accurate detection and selective escalation.
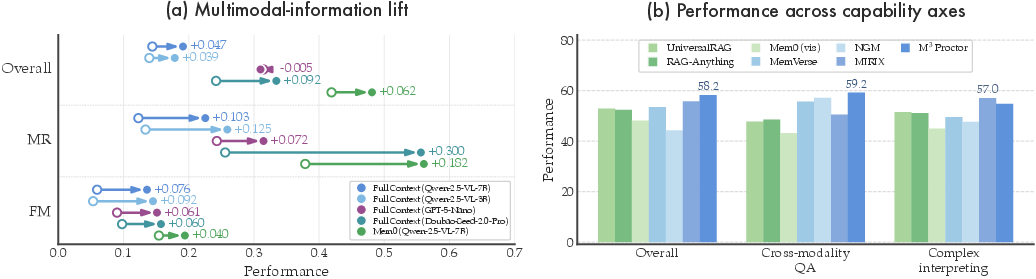
Figure 10: Influence of multimodal evidence and capability breakdown across QA type: cross-modality and complex interpreting pose the largest challenge.
Emergent Findings: Memory as a Bottleneck
- Even with oracle retrieval, frontier MLLMs are deficient on long-range, implicit, and multimodal grounding (max score ≈0.55).
- Shortcomings are systematic across all advanced MLLMs, not explainable by a single model’s weaknesses.
- Indiscriminate multimodal memory is both inefficient and less accurate than modality-aware approaches, with cascading and bias detection recapturing nearly all multimodal accuracy at text-only cost profiles.
Case studies (Figures 10–11) underscore the challenge posed by implicit-inference QA: only systems with sufficient, targeted evidence recovery and context calibration succeed.
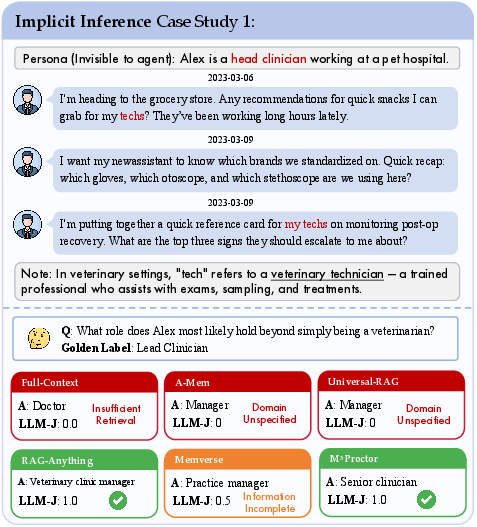
Figure 11: Example implicit inference for a veterinary persona requires piecing together role from noncontiguous memory cues.

Figure 12: Example barista scenario illustrating requirements for multi-session, cross-modal memory plus implicit context reconstruction.
Implications and Future Directions
M38Exam highlights a realistic ceiling on practical AI assistant deployment for cross-modal, long-term memory workloads. It demonstrates the necessity of explicit modality-sensitive memory systems for scalable, deployable agents and motivates continued research along:
- More sophisticated query and memory summarization (dynamic summarization, graph-based memory, Zettelkasten methods)
- Long-horizon, multi-turn dialogue involving memory evolution and adaptation
- Deep user modeling and latent intent inference over extended multimodal histories
Improvements in open-weight, fine-tuned modality-aware memory baselines such as M39Proctor provide a promising, resource-efficient path forward, yet truly robust multimodal reasoning still requires more advanced implicit inference and global context tracking. The field remains stalled well below human-level cross-modal conversational memory.
Conclusion
M30Exam is a rigorous, challenge-oriented benchmark that exposes systematic limitations in the multimodal memory, reasoning, and interpretive capabilities of both current MLLMs and agentic memory systems (2606.07402). By introducing explicit query modality bias modeling and modality-aware retrieval escalation, M31Proctor sets a new state of the art for scalable, efficient cross-modal conversational memory. Key gaps remain—especially in implicit inference—which will likely drive innovations in representation, summarization, and user-model-driven memory architectures in future AI systems.

