- The paper introduces M3-Agent, which integrates real-time visual and auditory data to form both episodic and semantic memories for improved long-term reasoning.
- It employs parallel memorization and control processes to extract sensory details and retrieve structured memories for iterative decision-making.
- Experimental results on the M3-Bench demonstrate significant performance gains over baselines, underscoring the impact of semantic memory in complex reasoning tasks.
"Seeing, Listening, Remembering, and Reasoning: A Multimodal Agent with Long-Term Memory" Summary
Introduction to M3-Agent
The paper presents the M3-Agent, a sophisticated multimodal agent framework that features long-term memory capabilities. Inspired by human cognitive processes, M3-Agent processes real-time visual and auditory data to establish both episodic and semantic memories. This agent facilitates the autonomous execution of tasks via iterative reasoning and memory retrieval, akin to human decision-making mechanisms.
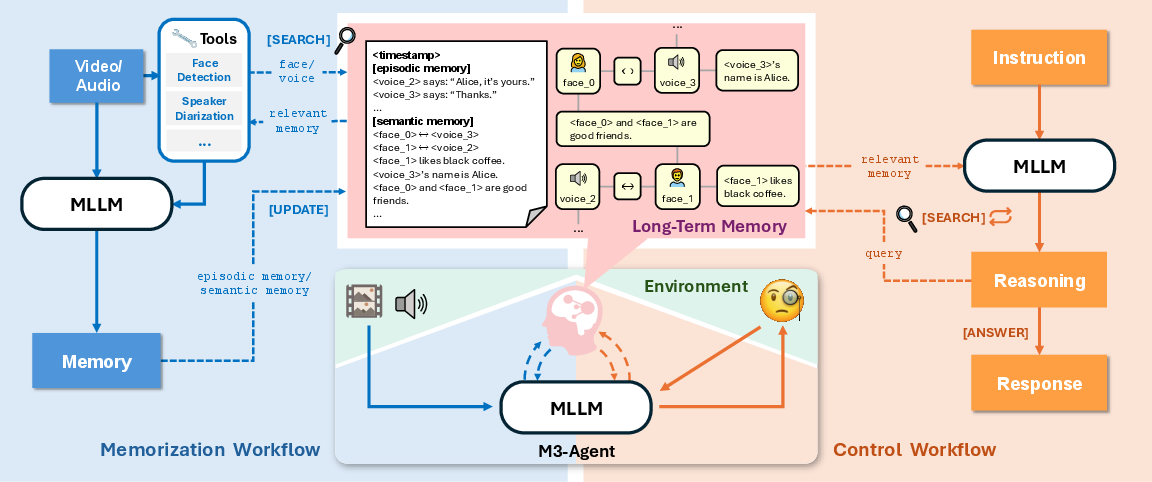
Figure 1: Architecture of M3-Agent, comprising a multimodal LLM (MLLM) and a multimodal long-term memory. The system consists of two parallel processes: memorization and control. During memorization, M3-Agent processes video and audio streams online to generate episodic and semantic memory. During control, it executes instructions by iteratively reasoning and retrieving from long-term memory. The long-term memory is structured as a multimodal graph.
Memorization and Control Processes
M3-Agent's functionality is divided into two parallel processes: memorization and control. During memorization, the agent extracts fine-grained details and high-level abstractions from incoming sensory data, creating entity-centric multimodal memories. These allow the agent to capture and understand diverse environmental factors and develop continuous, structured knowledge represented in a graph format. The control process employs long-term memory, facilitating multi-turn reasoning and memory-based decision making effectively.
The memory structure consists of episodic memories that document specific events and semantic memories that infer general knowledge. This dual-memory framework supports consistent and accurate memory retrieval for subsequent task execution.
Evaluation with M3-Bench
To empirically evaluate the M3-Agent, the paper introduces M3-Bench, a benchmark for evaluating memory-based reasoning in multimodal agents. M3-Bench includes realistic long-video question-answering tasks derived from videos that simulate a robotic perspective, measuring key agent skills such as human understanding and cross-modal reasoning.
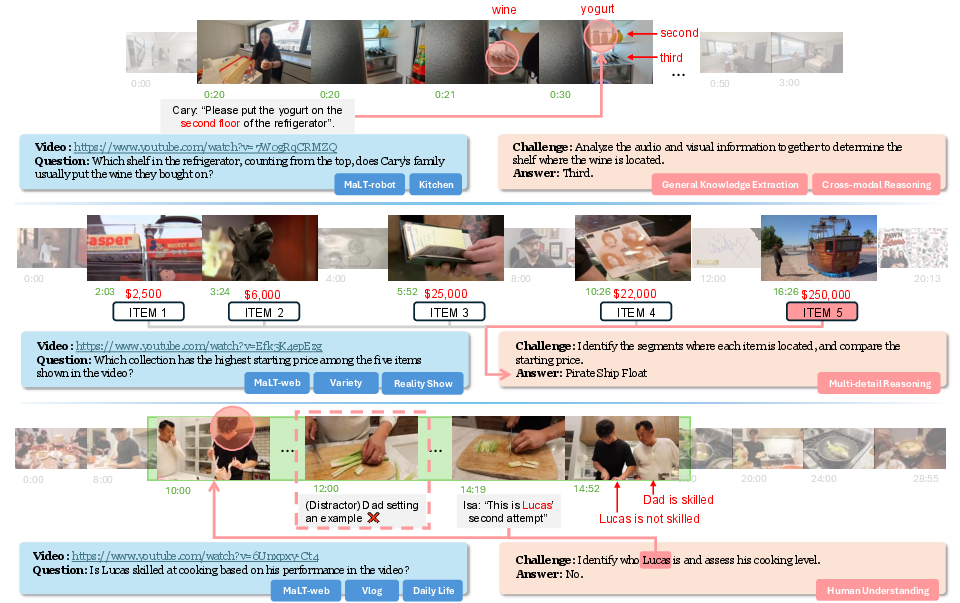
Figure 2: Examples from M3-Bench. M3-Bench-robot features long videos from realistic robotic work scenarios, while M3-Bench-web expands the video diversity to support broader evaluation. The question-answering tasks are designed to assess a multimodal agentâs ability to construct consistent and reliable long-term memory, as well as to reason effectively over that memory.
Experimental Results
The experimental data indicate that M3-Agent, trained with reinforcement learning, significantly outperforms the current strongest baseline agents. This includes improving accuracy by notable margins on multiple benchmarks such as M3-Bench and VideoMME-long. The ablation studies conducted further highlight the nuanced contributions of semantic memory to overall performance accuracy.
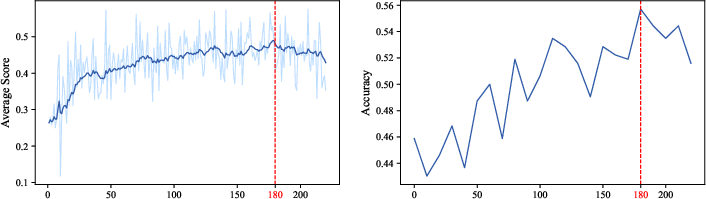
Figure 3: Average scores (on training set) and accuracy (on dev set) curves during the DAPO training process. The smoothing method of the curve in the left figure is the exponential moving average(EMA) formula that aligns with the one used in WandB, and the smoothing weight is set to 0.9
Future Developments and Considerations
The implementation of M3-Agent illustrates a critical step towards multimodal agents with human-like memory integration and reasoning capabilities. Future explorations may involve optimizing memory efficiency, expanding sensory input capabilities, and enhancing interpretability of reasoning pathways. Additionally, integration with existing robotic platforms could facilitate real-world deployment and automated task management in dynamic environments.
Conclusion
M3-Agent exhibits advanced capabilities in continuous, multimodal processing and contextual reasoning, setting a new standard for multimodal agent frameworks. The research advances underscore the potential of integrating structured long-term memory architectures within AI systems to foster human-like environmental interaction and decision-making processes. The availability of model, code, and data resources opens pathways for further research and application development in the field.