MemLens: Benchmarking Multimodal Long-Term Memory in Large Vision-Language Models
Abstract: Memory is essential for large vision-LLMs (LVLMs) to handle long, multimodal interactions, with two method directions providing this capability: long-context LVLMs and memory-augmented agents. However, no existing benchmark conducts a systematic comparison of the two on questions that genuinely require multimodal evidence. To close this gap, we introduce MEMLENS, a comprehensive benchmark for memory in multimodal multi-session conversations, comprising 789 questions across five memory abilities (information extraction, multi-session reasoning, temporal reasoning, knowledge update, and answer refusal) at four standard context lengths (32K-256K tokens) under a cross-modal token-counting scheme. An image-ablation study confirms that solving MEMLENS requires visual evidence: removing evidence images drops two frontier LVLMs below 2% accuracy on the 80.4% of questions whose evidence includes images. Evaluating 27 LVLMs and 7 memory-augmented agents, we find that long-context LVLMs achieve high short-context accuracy through direct visual grounding but degrade as conversations grow, whereas memory agents are length-stable but lose visual fidelity under storage-time compression. Multi-session reasoning caps most systems below 30%, and neither approach alone solves the task. These results motivate hybrid architectures that combine long-context attention with structured multimodal retrieval. Our code is available at https://github.com/xrenaf/MEMLENS.









Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
MemLens: A simple explanation
What is this paper about?
This paper introduces MemLens, a big test (called a benchmark) to check how well AI systems that understand both pictures and text can remember things over long, multi-turn conversations. The focus is on “long-term memory” across many chat sessions that mix images and words, like a long text thread where you sometimes share photos.
The authors compare two main kinds of AI:
- Long-context models: they try to read the whole long conversation at once.
- Memory-augmented agents: they don’t read everything every time; instead, they save notes and pull out the parts they think they need later.
What questions were the researchers trying to answer?
In simple terms, they asked:
- Can today’s AIs remember details from both images and words across long chats?
- Which approach works better as conversations get really long: reading everything (long-context) or saving/retrieving notes (memory agents)?
- Do these AIs actually use the pictures, or are they guessing from text alone?
- What kinds of memory skills are hardest for AIs?
- How should future AIs be built to do better?
How did they test the AIs?
Think of a “needle in a haystack” game, but the haystack is a long chat with mixed images and text, and the needle is a small detail you have to find and reason about.
They built MemLens with:
- 789 questions spread across four standard input sizes (like growing chat lengths): 32K, 64K, 128K, and 256K “tokens” (you can think of tokens as tiny pieces of words or image information).
- Five memory skills (each question checks one). These are:
- Information Extraction (IE): find a specific fact that depends on recognizing what’s in a picture.
- Multi-Session Reasoning (MSR): combine clues across several sessions, like adding numbers or matching the same person/object across different images.
- Temporal Reasoning (TR): reason about time (e.g., which event happened first) using hints from dates, calendars, or clock faces in images and text.
- Knowledge Update (KU): track how a user’s info changes over time (e.g., “I used to like apples; now I prefer kiwi”) and give the latest truth.
- Answer Refusal (AR): when the needed evidence is missing, the AI should say “I can’t answer,” not make something up.
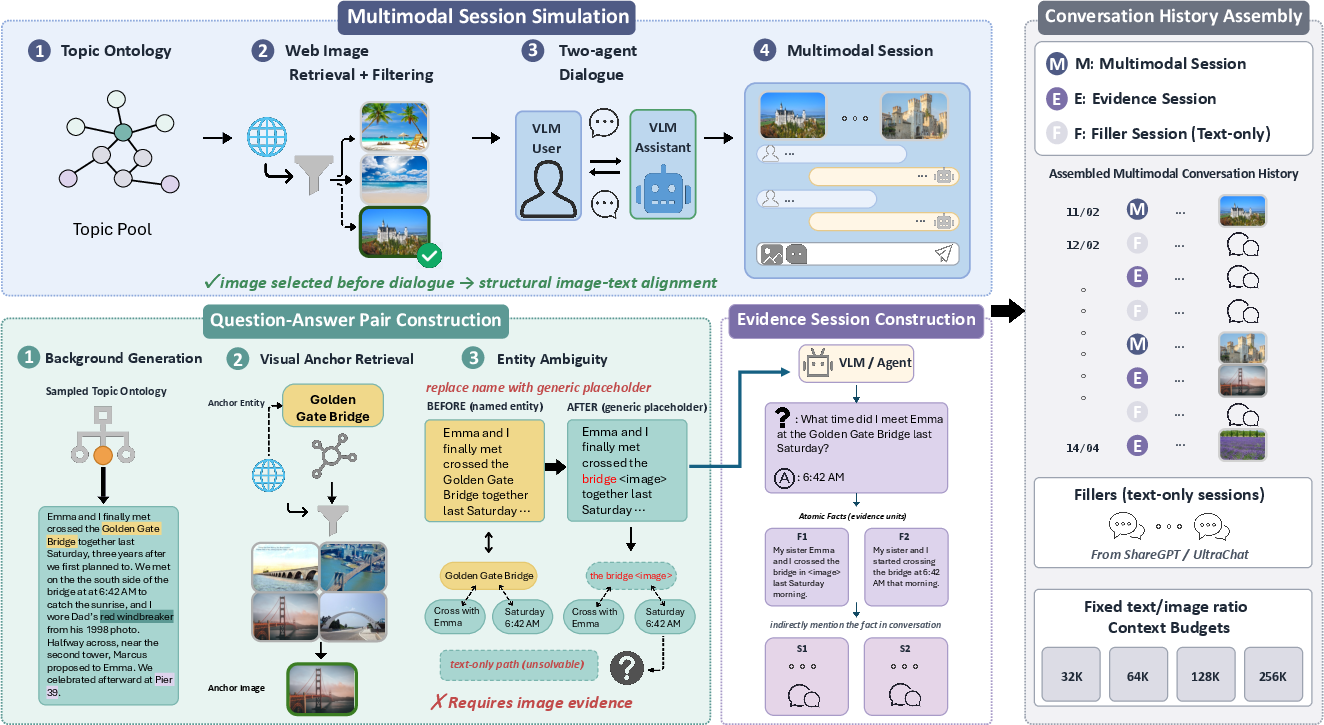
To make sure pictures really matter, they used a trick called “entity abstraction”: they replaced specific names in the text (like “Golden Gate Bridge”) with general hints (like “the bridge shown in the image”), so you must look at the image to know which thing it is.
They also:
- Mixed the real clues with lots of related but unhelpful chat turns and images (distractors), so the AI can’t cheat by surface matching.
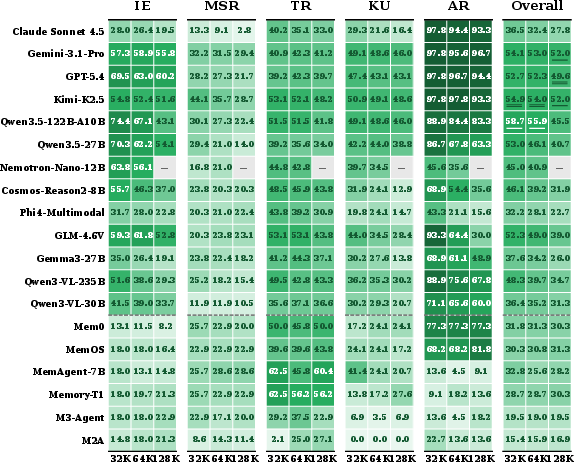
- Tested many different systems: 27 vision-LLMs and 7 memory-augmented agents.
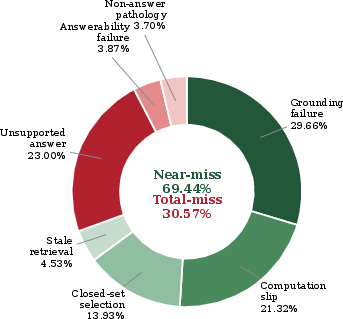
- Checked “image necessity” by running an ablation: when they removed the evidence images, accuracy on image-dependent questions fell to below 2% for leading models. In other words, pictures were truly needed.
What did they find, and why does it matter?
Here are the main results in everyday language:
- Pictures are essential. On 80.4% of questions that included images as evidence, removing the images made top models drop to under 2% accuracy. So these aren’t text-only questions with random pictures—the images carry crucial information.
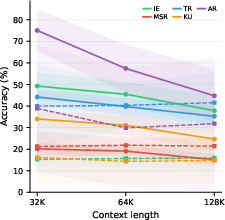
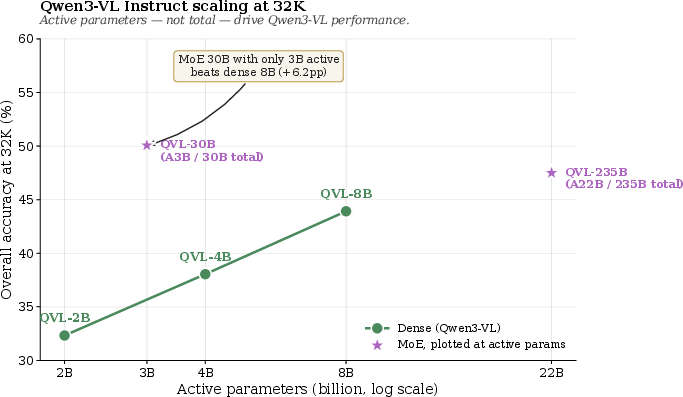
- Long-context models are great at short lengths but get worse as chats get longer. They’re good when they can directly “see” the right image in a short context, but they struggle to find the right information when the conversation gets huge.
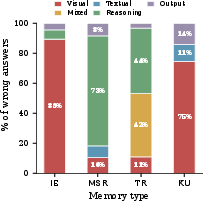
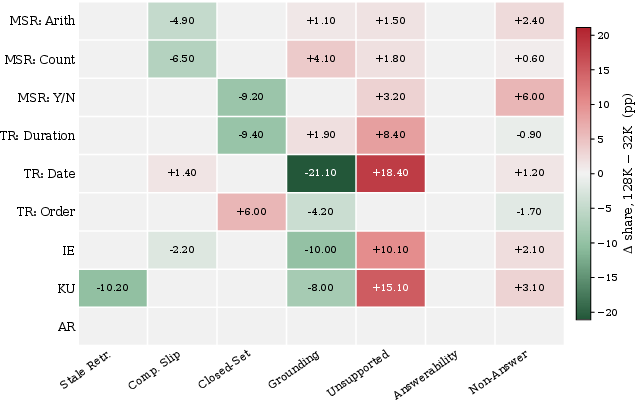
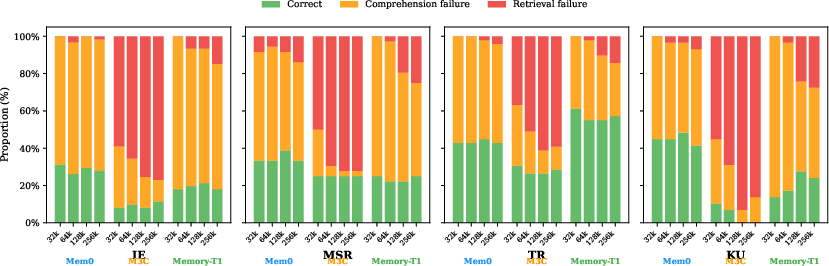
- Memory agents are steady with length but lose visual detail. Because they save compressed summaries or captions, they’re stable even when the chat is huge—but they often miss fine-grained image details (like exact counts, small labels, or subtle differences), which hurts accuracy on image-heavy tasks.
- Multi-session reasoning is the hardest. When questions need combining info from several sessions, most systems score under 30%. This is the current ceiling.
- Saying “I don’t know” is harder than it looks. Some memory agents that were trained to optimize for “getting answers right” became worse at refusing unanswerable questions. In other words, they started guessing more when they should have abstained.
Why it matters:
- Real assistants need to handle long, messy chats with both pictures and text, remember updates, and avoid making things up. Knowing where current systems fail helps us build safer, more reliable AIs.
What’s the big takeaway for the future?
No single approach wins by itself:
- Long-context models need better ways to keep track of what matters as the chat gets longer.
- Memory agents need better ways to store and retrieve the original image evidence (not just short captions), so they don’t lose important visual details.
- The best path forward is likely a hybrid: combine long-context attention (so the model can directly use the original images when needed) with smart, structured retrieval (so it doesn’t get lost in super-long chats).
If this works, future AI assistants could:
- Remember more accurately across long conversations,
- Use pictures and text together more reliably,
- Update knowledge safely over time,
- And know when to say “I’m not sure” instead of guessing.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper.
- Benchmark coverage is limited to text+image; no evaluation of long-term memory with audio, video, or sensor streams, which are common in real-world multimodal assistants.
- All multi-session dialogues are largely synthetic (LLM-simulated with web-retrieved images); the ecological validity of results under real human–AI conversational histories remains untested.
- The benchmark focuses on five abilities; important memory skills such as selective forgetting, uncertainty-aware recall, causal/relational memory, and consistency maintenance across sessions are not directly evaluated.
- Knowledge Update chains are fixed-length (four steps) and narrowly scoped; scalability to longer, noisier, or contradictory update sequences is not assessed.
- Multi-session reasoning spans 3–8 sessions with numeric/counting aggregates; broader forms of cross-session composition (e.g., graph reasoning, temporal+spatial+entity joint inference) are not exercised.
- Image evidence is required by construction, but the data do not probe robustness to degraded, occluded, adversarial, or low-resolution images common in user-uploaded content.
- Visual categories and tasks emphasize entity abstraction; other visually grounded cues (e.g., OCR-heavy documents, charts/diagrams, UI screenshots) are underrepresented or absent.
- The cross-modal token-counting scheme (~2000 “tokens/image”) assumes uniform alignment across LVLMs, but different models encode images differently; fairness and sensitivity to tokenization choices are not quantified.
- LVLMs are evaluated on the full 789 questions, while agents are scored on a 195-question subset; cross-approach comparisons may be biased by non-identical item sets.
- Some LVLMs are not evaluated at 256K (lack native support); scaling conclusions across 32K–256K are therefore uneven and may mix model capacity with length effects.
- LLM-as-judge accuracy is the primary metric; there is no assessment of robustness to judge choice beyond two families, nor of calibration, evidence grounding, or citation-based verification.
- Open-ended answers are judged for correctness, but the benchmark does not require evidence attribution (e.g., citing session IDs or image references), limiting diagnostics of retrieval faithfulness.
- The paper attributes agent visual failures to lossy storage-time compression, but lacks controlled ablations on memory representation (captions vs dense embeddings vs hybrid caches vs raw-image retrieval-on-demand).
- Text-only agents receive BLIP-2 captions for images; the performance gap may partially stem from captioner limitations. No ablation with stronger captioners, multi-caption ensembles, or OCR-enabled captioning is provided.
- No agent stores or retrieves raw images for re-encoding at answer time; whether “retrieve-then-re-encode” mitigates visual fidelity loss remains an open, testable hypothesis.
- Reward shaping and post-training are implicated in weakened abstention, but the paper lacks controlled experiments varying reward functions to explicitly optimize refusal on unanswerable items.
- The benchmark shows ability specialization and low cross-type correlations but does not provide psychometric validation (e.g., reliability across parallel forms, IRT-based difficulty calibration).
- Error analysis aggregates “visual” failures but does not disaggregate core sub-failures (e.g., retrieval miss vs mis-localization vs attribute misread vs counting vs OCR), limiting targeted remediation.
- Oracle-retrieval analyses focus on MSR; analogous oracles for IE/KU (e.g., providing the correct image set but varying distractor density) are not reported to separate perception vs retrieval failures.
- Distractor similarity is controlled, yet the impact of semantic similarity, recency, or timestamp confounds on retrieval errors is not systematically ablated.
- Temporal Reasoning leverages timestamps and calendars but does not test challenging temporal phenomena (relative, ambiguous, nested, or overlapping intervals; time-zone shifts; noisy time mentions).
- The benchmark keeps a fixed text-per-image ratio and curated haystacks; real-world drift in image density, topic shifts, and mixed-quality inputs is not modeled or stress-tested.
- Generalization across domains (e.g., clinical, industrial, or privacy-preserving settings) is untested, and the ontology skews toward non-person-centric, web-retrievable topics.
- Compute/latency/memory-footprint trade-offs for agents vs long-context LVLMs are not measured; practitioners lack guidance on throughput vs accuracy optimization.
- Closed-source model versions may change over time; stability of leaderboard rankings across API updates is not evaluated.
- The public release lacks a hidden/held-out test split to discourage tuning on the evaluation set; risk of overfitting and leaderboard gaming is not addressed.
- The study proposes hybrid architectures but does not instantiate or benchmark concrete designs (e.g., structured multimodal indexes + long-attention; routing policies; budget allocation strategies).
- Safety/calibration is tested only via answer refusal; broader hallucination controls (confidence estimation, selective abstention thresholds, uncertainty-aware retrieval) are not benchmarked.
- The benchmark does not evaluate explanation quality or faithfulness; correct answers may still arise from spurious cues without verifying evidence-consistent reasoning.
- Memory update consistency over long horizons (e.g., maintaining stable preferences while updating facts) is not explicitly measured beyond final-answer correctness.
- Effects of memory-store size, eviction policies, and compression levels on performance are not systematically varied to reveal fidelity–capacity trade-offs.
- Impact of different visual encoders, tokenizers, or vision-token scaling (e.g., multi-scale image chunking) on length scaling and retrieval is not studied.
- No analysis of robustness to paraphrasing or rephrasings of evidence-bearing turns; susceptibility to minor wording changes in the haystack remains unknown.
- The benchmark excludes person-centric images; thus, identity/face-driven memory tasks (a practical use case) are out of scope and remain unassessed.
Practical Applications
Overview
MemLens is a new benchmark for evaluating long-term multimodal memory in large vision–language systems. It exposes two complementary failure modes in today’s systems: (1) long-context LVLMs degrade as conversation length grows (retrieval and abstention erode), and (2) memory-augmented agents are length-stable but lose visual fidelity when they compress images into text/embeddings. It also identifies multi-session reasoning as a common capability ceiling and shows that reward-tuning agent backbones can weaken refusal behavior. These findings suggest immediate steps for model selection, QA, and memory-system design, and longer-term directions for hybrid architectures, training objectives, and standards.
Below are actionable applications, grouped by deployment horizon.
Immediate Applications
The following applications can be deployed with today’s tools and the released MemLens code/dataset.
- Memory-aware model selection and acceptance testing for multimodal assistants
- Sectors: customer support, e-commerce, insurance claims, telecom, healthcare telemedicine, enterprise IT helpdesk.
- What to do: Use MemLens as a pre-deployment gate to choose between long-context LVLMs (better at short contexts with visuals) vs. memory agents (more length-stable). Set per-ability thresholds (e.g., AR ≥ 80%, IE 32K→128K drop ≤ 10%, MSR ≥ 30%) and run regression tests before each model update.
- Tools/workflows: MemLens evaluation harness; nightly CI jobs on a 200–300 item canonical subset; dashboards reporting IE/MSR/TR/KU/AR separately.
- Dependencies/assumptions: Access to long-context models/APIs; GPU budget for 64K–128K contexts; ensure dataset license compliance.
- Redesign memory stores to preserve visual evidence (not captions only)
- Sectors: field service, manufacturing QA, construction, logistics, insurance, healthcare triage.
- What to do: Store raw images (or high-fidelity thumbnails/patches) alongside embeddings/captions; retrieve and re-render the original image at answer time; surface “evidence cards” with image snippets and timestamps in the UI.
- Tools/workflows: Object storage with content-addressed image IDs; vector DB with multimodal indexes (image embeddings + text); retrieval pipelines that include image URIs in the prompt/context.
- Dependencies/assumptions: Storage/latency budgets; image privacy/compliance (GDPR/HIPAA); end-user consent for image retention.
- Incorporate evidence-aware refusal into training and evaluation
- Sectors: healthcare, finance, legal, public sector—any safety-critical assistant.
- What to do: Add AR-style negatives to evaluation gates and reward functions; penalize answers when evidence is absent; monitor AR separately from accuracy.
- Tools/workflows: Multi-objective RLHF/SFT with abstention reward; calibrated uncertainty triggers (e.g., “insufficient evidence” templates); post-hoc refusal classifiers.
- Dependencies/assumptions: Access to preference data or synthetic refusal data; careful reward design to avoid over-refusal.
- Ability-specific monitoring in production (not just one overall score)
- Sectors: MLOps/AI platform teams across industries.
- What to do: Track IE, MSR, TR, KU, AR as separate service-level indicators; alert on length-driven degradation (e.g., IE and AR dips after context ≥ 64K); run shadow MemLens subsets on sampled logs.
- Tools/workflows: Observability dashboards; periodic on-policy evals using MemLens canonical subset; drift detection on per-ability metrics.
- Dependencies/assumptions: Safe log handling; evaluation cost control.
- Hybrid quick wins: short-context grounding + selective memory retrieval
- Sectors: general software, search/RAG products.
- What to do: For queries near the end of a session, rely on LVLM’s window; for older content, retrieve only K relevant sessions and original images by timestamp/entity keys; cap retrieval depth and enforce diversity across sessions.
- Tools/workflows: Time-aware BM25/ANN retrieval over session metadata; entity/timestamp indices; top-K+diversity routing.
- Dependencies/assumptions: Engineering effort to add routing; domain-specific indexing quality.
- Internal test-set synthesis using MemLens pipelines
- Sectors: product QA teams in domain-specific verticals.
- What to do: Reuse MemLens’ multi-session generator and entity-abstraction prompts to create domain-aligned tests (e.g., device SKUs, SOP diagrams) where images are necessary to answer.
- Tools/workflows: Prompt templates from the repo; organization-specific image libraries; human audit for realism.
- Dependencies/assumptions: Rights to use internal images; reviewer time for quality control.
- Cross-modal token budgeting and UX design
- Sectors: product and platform teams managing AI cost/perf.
- What to do: Adopt cross-modal token counting to estimate cost; guide UX to avoid unnecessary image spam; chunk long histories with session resets; prefer retrieval for older content.
- Tools/workflows: Token accounting scripts; product telemetry to measure context growth; UI affordances for session archiving.
- Dependencies/assumptions: Pricing variability by provider; need to balance user experience with cost.
- Procurement and vendor evaluation guidelines
- Sectors: enterprise IT, public procurement, regulated industries.
- What to do: Require MemLens-style reporting by ability and length; set SLAs for long-context accuracy and AR; demand disclosure of whether images are preserved or compressed.
- Tools/workflows: RFP checklists; pilot bake-offs on the 32K/64K subsets; red-teaming on AR.
- Dependencies/assumptions: Vendor cooperation; consistent judging protocols.
- Data governance for multimodal memory
- Sectors: compliance, legal, platform governance.
- What to do: Track image provenance and takedown paths (as in MemLens); define retention policies for images; document what is stored (pixels vs. captions vs. embeddings).
- Tools/workflows: Provenance metadata stores; data catalogs; privacy impact assessments.
- Dependencies/assumptions: Regulatory constraints; internal review processes.
Long-Term Applications
These require further research, scaling, or productization beyond current off-the-shelf capabilities.
- Hybrid architectures that combine long-context attention with structured multimodal retrieval
- Sectors: AI platforms, autonomous agents, robotics.
- What to build: Models that attend over retrieved image patches plus recent text; learn retrieval policies that minimize length-driven degradation while preserving image fidelity.
- Tools/workflows: Cross-modal encoders for patch-level retrieval; late fusion cross-attention; train-time supervision with MemLens-style labels.
- Dependencies/assumptions: Efficient long-context training; scalable multimodal indexes; inference latency budgets.
- Visual-evidence–preserving memory compression
- Sectors: vector databases, edge/IoT, mobile assistants.
- What to build: Compression that retains counts, attributes, and spatial relations (e.g., region-level embeddings, scene graphs); reconstructible “evidence thumbnails” at query time.
- Tools/workflows: Region proposal + embedding storage; content-addressed chunking; image–text co-retrieval APIs.
- Dependencies/assumptions: Storage/compute trade-offs; GPU-friendly retrieval at scale.
- Multi-objective training that optimizes accuracy, retrieval fidelity, and abstention
- Sectors: safety-critical deployments (healthcare, finance, legal).
- What to build: RL/SFT with explicit refusal rewards and evidence-check constraints; selective generation calibrated to evidence presence.
- Tools/workflows: Reward models that score evidence attribution; mixture-of-objectives schedulers; evaluation on AR-heavy suites.
- Dependencies/assumptions: High-quality preference data; avoiding mode collapse toward over-refusal.
- Dedicated multi-session reasoning modules
- Sectors: finance (report aggregation), healthcare (patient timelines), education (portfolio tracking), project management.
- What to build: Differentiable aggregators or program-of-thought executors that operate over retrieved sessions and image evidence (counting, arithmetic, entity resolution).
- Tools/workflows: Toolformer-like function libraries; schema-aware memories for time/entity; train/dev on MSR-heavy subsets.
- Dependencies/assumptions: Stable APIs for tool execution; supervision for aggregation steps.
- Standards and certification for long-term multimodal assistants
- Sectors: policy/regulation, enterprise governance.
- What to build: Ability- and length-specific certification suites (IE/MSR/TR/KU/AR at 32K–256K), procurement baselines, incident reporting tied to ability failures.
- Tools/workflows: Public leaderboards; third-party audit harnesses; versioned benchmarks (as MemLens releases).
- Dependencies/assumptions: Stakeholder consensus; periodic benchmark refreshes to mitigate overfitting.
- Personal memory AIs that manage photo+chat histories over months/years
- Sectors: consumer productivity, accessibility, elder care, chronic-disease management.
- What to build: Assistants that recall visual events (e.g., medication packaging, receipts, appliance models) and track preference updates; privacy-first designs with on-device tiers.
- Tools/workflows: Tiered memory (on-device pixels + cloud summaries); consented capture and retention; evidence-aware explanations with cited images.
- Dependencies/assumptions: Strong privacy controls; efficient on-device multimodal storage.
- Enterprise knowledge assistants with visual SOP and maintenance memory
- Sectors: energy, manufacturing, construction, aviation, utilities.
- What to build: Assistants that recall visual procedures, parts, and site photos; reason over timelines of repairs/inspections with images.
- Tools/workflows: Integration with CMMS/EDMS; image-first memory ingestion from field apps; time-stamped retrieval across projects.
- Dependencies/assumptions: Data integration and ETL; workforce adoption; device connectivity.
- Multimodal RAG frameworks and vector DBs with first-class image support
- Sectors: software infrastructure, cloud providers.
- What to build: Libraries that index image patches, track image–text co-reference, and return pixels with text in a single retrieval call; native support for timeline queries.
- Tools/workflows: ANN over visual tokens; joint indices (entity, time, region); SDKs for “evidence cards.”
- Dependencies/assumptions: Ecosystem alignment (OpenAPI, LangChain/LlamaIndex plugins); performance tuning.
- Cost-optimized long-context serving and memory hierarchies
- Sectors: cloud AI platforms, SaaS.
- What to build: Dynamic routing between long-context attention and retrieval; caching and paging strategies tailored to multimodal histories.
- Tools/workflows: KV cache policies for interleaved images; budget-aware routers; adaptive truncation with evidence guarantees.
- Dependencies/assumptions: Provider support for long KV caches; robust latency SLAs.
- Expanded evaluation science for multimodal memory
- Sectors: academia, standards bodies.
- What to build: Benchmarks that extend MemLens to video/audio, embodied interactions, and human-in-the-loop updates; causally probe retrieval vs. reasoning failures.
- Tools/workflows: New ablations (image-vs-text), oracle-retrieval diagnostics, error taxonomies.
- Dependencies/assumptions: Data collection/consent for new modalities; compute for long-video contexts.
Notes on Feasibility and Assumptions
- Compute and cost: Long-context evaluations (≥64K) are expensive; plan budgets and use canonical subsets for continuous testing.
- Privacy and compliance: Storing and retrieving raw images requires consent and governance; many applications hinge on GDPR/HIPAA-compliant pipelines.
- Model capabilities: Open-weight LVLMs vary widely in visual grounding; results may not transfer without comparable vision quality.
- Synthetic-to-real transfer: MemLens sessions are carefully curated but synthetic; validate findings with small real-world pilots before broad deployment.
- Avoid training on the benchmark: As with any eval set, do not finetune on MemLens items to preserve diagnostic value.
Glossary
- Ablation study: A method where components are removed to measure their impact on performance. "An image-ablation study confirms that solving MemLens requires visual evidence"
- Abstention behavior: A model’s tendency to refuse to answer when evidence is insufficient or missing. "memory-oriented post-training of agent backbones can additionally weaken their abstention behavior."
- Answer Refusal (AR): The capability to decline answering when supporting evidence is absent. "Answer Refusal (AR) removes all supporting evidence from an otherwise answerable question"
- Backbone (model backbone): The base pretrained model that an agent system builds upon. "the same Qwen3-VL-8B backbone"
- BM25: A classic lexical retrieval scoring function used in information retrieval systems. "BM25 date matching"
- Caption-based compression: Storing images as textual captions, often losing fine-grained visual details. "rather than caption-based compression."
- Context window: The maximum amount of input (tokens) a model can attend to at once. "enlarge the native context window"
- Cross-modal token-counting scheme: A standardized way to count tokens across text and images for length control. "under a cross-modal token-counting scheme"
- Direct visual grounding: Answering by directly linking the response to visual evidence in images. "direct visual grounding"
- Distractor turns: Irrelevant but topically related conversation turns that make retrieval harder. "topically related distractor turns"
- Entity abstraction: Replacing a specific entity with a higher-level category so that an image is needed to resolve it. "Cross-modal dependency is enforced through entity abstraction"
- Entity resolution: Determining when mentions or images refer to the same real-world entity across sessions. "entity resolution determines co-reference by comparing images across sessions."
- Evidence dilution: The weakening of relevant evidence as more irrelevant content accumulates. "evidence dilution at long contexts"
- Evidence session: A full dialogue session that embeds an answer-critical fact to avoid easy retrieval shortcuts. "each evidence fact is wrapped in a complete evidence session"
- Hallucination control: Methods to prevent models from inventing unsupported answers. "hallucination control is the ability most exposed to evidence dilution"
- Hybrid architectures: Systems that combine different mechanisms (e.g., long-context attention and retrieval) to improve performance. "hybrid architectures that combine long-context attention with structured multimodal retrieval."
- Knowledge Update (KU): Tracking and applying the latest state of evolving user information across sessions. "Knowledge Update (KU) tests the ability to track an evolving user attribute"
- Large Vision-LLM (LVLM): A multimodal foundation model that processes both images and text. "large vision-LLMs (LVLMs)"
- LLM-as-Judge: Using a LLM to automatically assess the correctness of answers. "We report LLM-as-Judge accuracy"
- Long-context LVLMs: LVLMs designed with enlarged context windows to process long interaction histories. "Long-context LVLMs enlarge the native context window"
- LoRA (Low-Rank Adaptation): A parameter-efficient fine-tuning method that adds low-rank adapters to a model. "LoRA-tuned session retrieval"
- Memory-augmented agents: Agent systems that store, index, and retrieve past information from external memory to answer queries. "Memory-augmented agents, building on retrieval-augmented generation, instead compress, index, and selectively retrieve past content from an external store"
- Multimodal embeddings: Vector representations that jointly encode information from multiple modalities like text and images. "multimodal embeddings"
- Multi-Session Reasoning (MSR): Aggregating and reasoning over evidence spread across multiple dialogue sessions. "Multi-Session Reasoning (MSR) evaluates aggregation across three to eight sessions"
- Needle-in-a-haystack: A benchmark design where a small relevant “needle” must be found within a large irrelevant “haystack.” "Following the needle-in-a-haystack construction paradigm"
- Open-weight: Models whose weights are publicly available for use and fine-tuning. "open-weight LVLM family"
- Oracle-retrieval diagnostic: An evaluation where the correct evidence is supplied explicitly to diagnose reasoning vs. retrieval failures. "an oracle-retrieval diagnostic"
- Parametric knowledge: Information encoded in a model’s parameters rather than provided in the input context. "solvable from parametric knowledge alone"
- Post-training: Additional training (e.g., RL or SFT) applied after pretraining to adapt a model to specific behaviors. "post-training on memory agent backbones can additionally weaken their abstention behavior."
- Reinforcement learning (RL): A training paradigm that optimizes policies via reward signals. "RL-selected time-aware memory"
- Retrieval-augmented generation (RAG): Methods that fetch external documents or memories to ground generation. "building on retrieval-augmented generation"
- Session timestamps: Time metadata on dialogue sessions used for temporal reasoning. "session timestamps"
- Sliding-window RL agents: Agents trained with reinforcement learning that operate over a moving window of recent context. "sliding-window RL agents"
- Spearman rank correlation: A nonparametric statistic measuring the monotonic relationship between two rankings. "pairwise Spearman correlations"
- Structured multimodal retrieval: Retrieval over organized stores that retain the structure of multimodal evidence (text and images). "structured multimodal retrieval"
- Structured-fact stores: Memory systems that store information as structured facts for precise retrieval. "structured-fact stores"
- Storage-time compression: Compressing information (e.g., images to captions) when storing to memory, potentially losing detail. "lose visual fidelity under storage-time compression"
- Temporal grounding: Identifying when events occurred or ordering them in time. "temporal grounding either orders events chronologically"
- Temporal Reasoning (TR): Reasoning about dates, durations, and temporal relations in a conversation. "Temporal Reasoning (TR) assesses joint reasoning over temporal references"
- Visual fidelity: The degree to which stored representations preserve fine-grained image details. "lose visual fidelity under storage-time compression"
- Visual grounding: Tying answers explicitly to visual evidence rather than relying solely on text. "direct visual grounding"
Collections
Sign up for free to add this paper to one or more collections.