WorldMemArena: Evaluating Multimodal Agent Memory Through Action-World Interaction
Abstract: Multimodal LLMs are increasingly deployed as long-horizon agents, where memory must do more than recall: it must track an evolving world, revise what has gone stale, and surface the right evidence at decision time. Existing benchmarks measure recall over static dialogue, collapse memory into a single end-of-task accuracy, and reduce visual observations to captions, leaving us unable to localize failures to writing, maintenance, retrieval, or use. The rise of agent harnesses that author their own memory sharpens this gap, since we have no principled way to compare hand-designed pipelines with self-managing alternatives. To close these gaps, we formulate multimodal agent memory as an Action-World Interaction Loop with an observable four-stage lifecycle, and instantiate it in WorldMemArena: 400 multi-session multimodal tasks spanning Lifelong Evolution (evolving personal and task states) and Agentic Execution (memory from real observations, actions, and feedback), annotated with gold memory points, updates, distractors, and evidence chains for stage-level diagnosis. This enables the first head-to-head comparison of long-context, manually designed (RAG and external memory systems), and harness-based memory agents. Results show that: (1) better memory writing and storage do not guarantee better performance; (2) multimodal memory still struggles to fully use visual evidence; (3) systems are unstable across domains and degrade on realistic agentic trajectories; and (4) harness memory is more flexible but remains costly and less reliable.
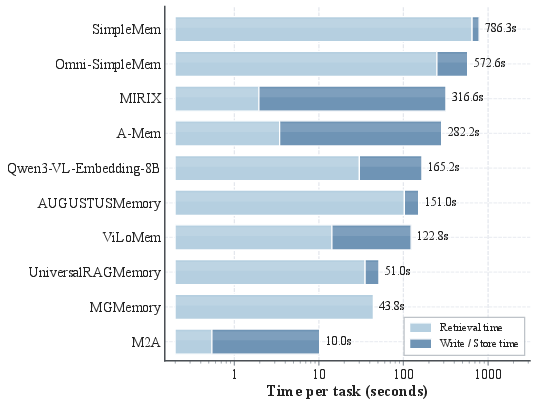
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A clear, simple guide to “WorldMemArena: Evaluating Multimodal Agent Memory Through Action–World Interaction”
What is this paper about?
This paper introduces WorldMemArena, a big “testing ground” for checking how AI assistants with eyes and ears (they can read text and look at images) remember things over time. These AIs don’t just answer questions—they act in apps or virtual worlds, get feedback, and need memory to make smart choices later. The goal is to test memory the way it’s really used: taking notes, keeping them up to date, finding the right notes when needed, and actually using them to decide what to do.
What questions did the researchers ask?
To make this easy to picture, think of an AI like a student working on a long project:
- Can the student take useful notes during each study session?
- Can they update or fix notes when facts change and ignore distractions?
- Can they find the right notes quickly when a question comes up?
- Do they use those notes correctly to answer the question or choose the next action?
The paper asks: Which kinds of AI memory systems do this best—reading a long history, using a hand-built “notes app,” or managing their own memory on the fly?
How did they study it?
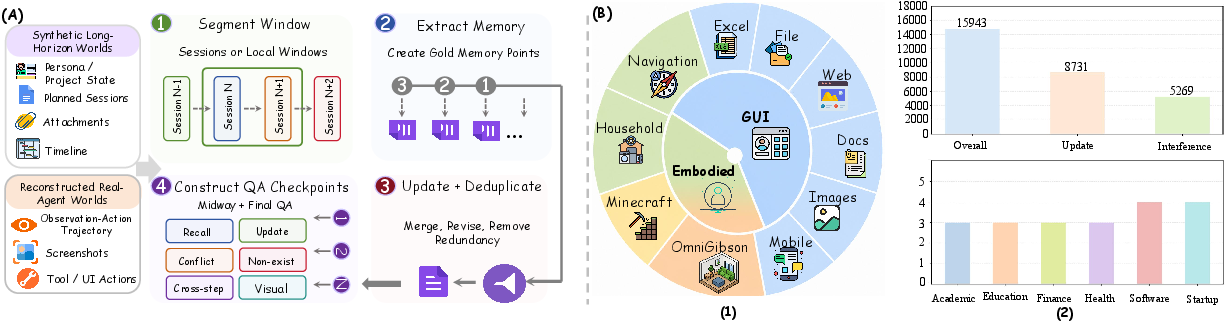
The authors built a large benchmark called WorldMemArena with 461 long, multi-session tasks that include both text and images. Each task unfolds over time, so the AI has to keep track of what matters and what’s changed.
They test memory in four simple stages—like a note-taking analogy:
- Write: After each session, does the AI save the important bits, not just everything?
- Maintain: Does it update or replace out-of-date notes when things change?
- Retrieve: When it gets a new question, can it find the specific notes that matter?
- Use: Does it actually use those notes correctly to answer or act?
They built two kinds of scenarios:
- Lifelong Evolution: The “world” changes across sessions—like a friend’s preferences or a project’s progress. The AI must track evolving facts across time.
- Agentic Execution: The AI acts in apps or environments (like clicking in a GUI or moving around), gets feedback, and must turn what it sees and does into useful memory for the future.
To make the tests fair and precise, each session is labeled with:
- Gold memory points: the facts the AI should keep
- Updates: facts that change and need replacing
- Distractors: look-alike but misleading info
- Evidence chains: the specific pieces of memory needed to answer each question
They compared three types of systems:
- Long-context agents: shove everything into a very long prompt and hope the AI can read it all (no special memory tools)
- Manually designed memory systems: tools like RAG (retrieval) or structured “memory notebooks”
- Harness-based agents: systems that let the AI manage its own memory during interaction (more flexible, more complex)
What did they find, and why is it important?
Here are the big takeaways, in everyday terms:
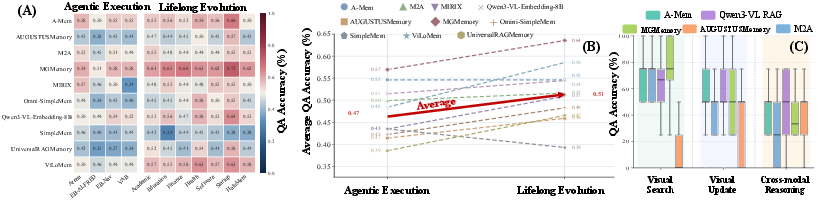
- Storing more isn’t enough: Writing a lot of correct notes doesn’t guarantee better answers. What matters most is finding and using the right notes at the right time.
- Pictures are still hard: Even though these AIs can look at images, they struggle to keep and reuse visual evidence well—especially for multi-step or tricky visual reasoning.
- Realistic settings are tougher: Systems are unstable across different domains and get worse in more realistic, action-heavy tasks where useful information is spread across actions, screenshots, tool feedback, and time.
- Self-managed memory is flexible but pricey: Agents that manage their own memory during interaction can be more adaptable, but they’re slower, more complex, and not always reliable.
- Updating and ignoring distractions is weak: Many systems are “append-only”—they keep adding notes but rarely fix or remove old ones. They’re also easily confused by distractors.
Why this matters: In real life, an AI helper needs to keep up with changing plans, remember what worked before, and use the right evidence—not just memorize a giant log.
What’s the impact, and what could happen next?
This work encourages a shift in how we think about AI memory:
- Treat memory as a skill, not just a storage box: Good memory grows through interaction—writing, revising, and using notes under pressure—not just by saving more text.
- Make updating a first-class habit: AIs need to revise and forget outdated notes, not just keep everything forever.
- Keep visual details usable: Don’t just turn images into text and lose the helpful visual cues (like positions, steps, or layouts).
- Test learning from experience: Benchmarks should reward AIs for using past experience to do better in the future, not just for answering quiz questions about the past.
In short, WorldMemArena gives researchers a clearer, fairer way to see where AI memory fails: taking notes, maintaining them, finding them, or using them. That helps build AIs that don’t just remember—they remember the right things and use them at the right time.
Knowledge Gaps
Unresolved Knowledge Gaps, Limitations, and Open Questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored based on the paper.
- Live, closed-loop evaluation gap: Current assessments rely on offline staged QA over fixed trajectories; they do not test whether memory improves behavior in ongoing interaction with environment state changes and task rewards. How to design online tasks where memory causally affects success over multiple sessions?
- Limited modality coverage: The benchmark primarily uses text and images/screenshots. It lacks audio, continuous video, temporal streams, and richer sensory inputs (e.g., IMU, speech). How does memory behave with streaming multimodal inputs and temporal alignment constraints?
- Monolingual scope: Tasks appear English-only. How do memory construction, updating, and retrieval perform in multilingual, code-switched, and low-resource languages?
- Harness introspection deficit: Harness-based agents are evaluated end-to-end but cannot be diagnosed at write/update/retrieve/use stages. Can we standardize tracing hooks/APIs that expose internal memory operations for stage-level measurement?
- Evaluation over-reliance on LLM-as-a-Judge: Key metrics (correctness, hallucination, irrelevance, QA grading) depend on an LLM evaluator, which may be biased and inconsistent. What is the inter-rater reliability, and how can we calibrate with human judgments, reference-based metrics, or model-agnostic verifiers?
- Evidence-chain rigidity: Gold evidence chains may not capture all valid reasoning paths; alternative supports can be penalized. How to allow multiple acceptable evidence sets, use entailment-based validation, or counterfactual perturbations to verify true evidence use?
- Coarse update metrics: Update success is treated as a binary “new present + old removed.” There is no graded evaluation for partial consistency, merge quality, conflict resolution, or selective forgetting. Can we introduce precision/recall metrics for obsolete-memory removal and conflict reconciliation?
- No capacity/budget constraints: Systems are not tested under bounded memory size, retrieval budget, latency, or energy limits. How do eviction policies, compression, and selective retrieval perform under strict resource constraints?
- Privacy, security, and safety unaddressed: The benchmark does not evaluate PII handling, GDPR-like “right to be forgotten,” poisoning attacks, or malicious distractors beyond benign interference. What protocols and tasks can stress-test privacy-preserving updates and poisoning resilience?
- Timescale limitations: With an average of ~18 sessions per sample, the benchmark may not reflect months-long projects or user lifetimes. How do agents maintain, compress, and revise memory across hundreds of sessions and long dormancy intervals?
- Agentic Execution realism: Many trajectories are “real or realistic” but not clearly live or stochastic. Can we integrate interactive environments where actions change future states (with noise) and the agent must learn from consequences?
- Visual memory fidelity: Current evaluation infers visual memory via QA performance; it does not directly probe spatial/temporal precision (e.g., re-identification, layout, state changes). What probes can validate faithful, queryable visual-state retention without lossy text-only compression?
- No training benchmarks for memory learning: The paper evaluates fixed systems but does not provide train/val/test splits or protocols to learn memory policies end-to-end (e.g., via RL or supervised memory editing). How should we train agents whose memory improves with experience?
- Reproducibility constraints: Several baselines/harnesses are proprietary (e.g., GPT-5.4), hindering replicability and ablation. Can open baselines with frozen weights and seeds be added for stable comparisons?
- Cost and efficiency metrics incomplete: Token efficiency is shown, but standardized compute/latency/throughput/energy reporting is missing. How to define and enforce cost KPIs so methods can be compared under the same budget?
- Robustness beyond benign distractors: The benchmark includes plausible distractors but not adversarially crafted ones, distribution shifts, or deceptive evidence. What adversarial memory stress tests can expose brittleness in write/update/retrieve pipelines?
- Causal attribution of failures: Stage metrics are correlational; they do not establish that fixing a stage fixes outcomes. Can intervention experiments (e.g., targeted ablations or counterfactual edits) isolate causal contributions of each stage?
- Multi-agent and shared memory absent: The benchmark focuses on single agents. How do coordination, memory sharing, and consistency work across agents with overlapping and conflicting memories?
- User-controlled memory editing: No tasks require user-initiated correction/deletion with compliance and auditability. How can we evaluate edit latency, accuracy, and side-effect containment?
- Confidence and calibration: Retrieval/QA confidence and selective abstention are not measured. How to assess calibration for memory use (e.g., reporting uncertainty when memory is stale or missing)?
- Annotation transparency: Inter-annotator agreement, coverage audits, and evidence completeness are not reported. Can annotation guidelines, IAA statistics, and audit reports be released to quantify label quality?
- Benchmark contamination risk: Public release invites model training on the test set. Is there a hidden test split and evaluation server to prevent leakage and overfitting?
- Lack of a common memory schema/API: Cross-system comparability is hindered by heterogeneous memory formats. Can a standard memory exchange format (with types, timestamps, provenance, and confidence) be defined?
- Tool feedback representation: The benchmark includes tool traces, but systematic evaluation of noisy/ambiguous tool logs and tool-version drift is limited. What tasks quantify robustness to tool-output variability?
- Embodied realism: Embodied tasks appear simulated; there is no evaluation on real robots or sensors with latency, actuation noise, and partial observability. How does memory fare in real-world embodied settings?
- Long-term drift and catastrophic forgetting: Although degradation trends are shown, there is no explicit measurement of forgetting curves or stability under prolonged updates. Can we introduce repeated-probe protocols to quantify memory retention vs. drift?
- Harm from memory errors: While hallucination and irrelevance are measured, downstream harm from acting on incorrect memory is not. What safety metrics capture the impact of memory mistakes on decision quality and user risk?
Practical Applications
Overview
WorldMemArena introduces a practical framework and dataset for evaluating multimodal agent memory as a four-stage lifecycle (Write, Maintain/Update, Retrieve, Use) embedded in real interaction loops. Its findings—especially that storage quality alone does not predict downstream performance, retrieval is a key bottleneck, visual evidence is underused, and append-only updates cause state inconsistency—translate into concrete applications across sectors.
Below are actionable applications grouped by deployment horizon. Each item highlights likely sectors, potential tools/products/workflows, and key assumptions or dependencies affecting feasibility.
Immediate Applications
The following applications can be deployed now using the WorldMemArena dataset, code, and evaluation protocol.
- Memory lifecycle diagnostics for AI agents
- Sectors: software, enterprise AI, customer support, e-commerce, finance ops.
- Tools/Workflows: Stage-level dashboards that score Write, Update, Retrieve, Use; metrics like retrieval coverage and NDCG; “memory diff” reports to flag obsolete vs. active facts; per-domain scorecards.
- Dependencies/Assumptions: Access to agent logs and memory states or retrieval traces; ability to map internal memory items to benchmark annotations; evaluator (LLM-as-a-judge) reliability for qualitative scoring.
- CI/CD regression testing for agent releases
- Sectors: software (MLOps), SaaS products embedding LLM/MM agents.
- Tools/Workflows: Automated test suites using WorldMemArena as a gate in CI; per-commit regression on update handling, interference rejection, and retrieval precision; token/time budget vs. accuracy trade-off tracking.
- Dependencies/Assumptions: Compute budget for repeated evaluations; stable seeds/prompts; dataset licensing and internal mirroring.
- Vendor/model selection and procurement scorecards
- Sectors: healthcare, finance, education, public sector IT.
- Tools/Workflows: RFP annex requiring reporting on lifecycle metrics across Lifelong Evolution and Agentic Execution; domain-specific scorecards; red-team scenarios (distractors, conflicts).
- Dependencies/Assumptions: Domain shift from benchmark to production; calibration of acceptable failure rates; clear weighting of lifecycle metrics vs. final accuracy.
- RAG and external-memory system tuning
- Sectors: enterprise search, knowledge management, customer support.
- Tools/Workflows: Evaluate retrieval cutoffs, filters, and ranking (NDCG) to reduce long-context degradation; anti-accumulation policies (merge/revise/delete) validated via update tests; boundary tests for memory conflicts.
- Dependencies/Assumptions: High-quality indexing; governance to suppress PII or stale data; monitoring for retrieval drift across domains.
- GUI automation and embodied agent debugging
- Sectors: RPA, productivity tools, robotics, logistics.
- Tools/Workflows: Use Agentic Execution tasks to pinpoint where tool feedback and visual states are dropped; add “failed-action memory” logging; incorporate corrective updates after environment changes.
- Dependencies/Assumptions: Availability of GUI/robot trajectories with observations, actions, feedback; consistent screenshot/state capture.
- Education and training of researchers and engineers
- Sectors: academia, corporate AI training programs.
- Tools/Workflows: Course modules and labs using lifecycle diagnosis; assignments comparing long-context vs. RAG vs. harness memory; ablations on retrieval scope and update policies.
- Dependencies/Assumptions: Access to benchmark artifacts; instructor familiarity with multimodal evaluation.
- Product UX for “evidence-aware” assistants
- Sectors: consumer AI assistants, productivity suites.
- Tools/Workflows: Surface “evidence used” panels; highlight which memory items were retrieved and updated; flag potential conflicts or outdated entries to users for confirmation.
- Dependencies/Assumptions: Traceable provenance; UI space for transparency; user consent and privacy controls.
- Internal dataset curation with memory annotations
- Sectors: enterprises building proprietary agents.
- Tools/Workflows: Adopt WorldMemArena’s schema (gold memory points, updates, distractors, evidence chains) to label in-house logs; bootstrap with LLM annotators plus spot human review.
- Dependencies/Assumptions: Annotation budget; IP/PII handling; QA criteria for annotation consistency.
- Risk and safety audits for long-horizon agents
- Sectors: healthcare, finance, government services.
- Tools/Workflows: Periodic audits stressing interference rejection, conflict resolution, dynamic update; quantify hallucination/omission rates under evolving states; build “safe fallback” triggers when retrieval confidence is low.
- Dependencies/Assumptions: Risk thresholds per domain; robust logging; governance for audit findings and remediation.
- Training curricula that mirror the memory lifecycle
- Sectors: model training orgs, applied research labs.
- Tools/Workflows: Multi-objective fine-tuning (e.g., update consistency, retrieval grounding, use-of-evidence rewards); distillation from harness agents to lighter models.
- Dependencies/Assumptions: Label availability for write/update/retrieve/use steps; cost of reinforcement/fine-tuning; stability of reward models.
Long-Term Applications
These concepts are high-impact but require further research, scaling, or engineering investment.
- Adaptive, harness-managed memory as a learned capability
- Sectors: robotics, enterprise AI platforms, autonomous systems.
- Tools/Workflows: Jointly learning policy and memory under interaction objectives (not a fixed module); online memory shaping, task-driven consolidation, and selective forgetting.
- Dependencies/Assumptions: Efficient training loops; safe exploration in production-like environments; robust credit assignment across sessions.
- Multimodal-native memory representations
- Sectors: vision-centric assistants, robotics, design/creative tools.
- Tools/Workflows: Persist visuals beyond captions (scene graphs, keyframes, spatial-temporal embeddings); memory queries that mix text and visual indexes; cross-modal retrieval with temporal alignment.
- Dependencies/Assumptions: Storage and compute overhead; scalable multimodal indexing; evaluation of visual-use fidelity beyond text proxies.
- Standards and certification for agent memory lifecycle
- Sectors: policy/regulatory, compliance tech.
- Tools/Workflows: A “Memory Lifecycle Compliance” standard with minimum bars for update handling, conflict resolution, provenance, and retrieval precision; third-party certification bodies.
- Dependencies/Assumptions: Community consensus; reproducible tests; sector-specific requirements (e.g., HIPAA, SOX).
- Privacy-preserving lifelong memory and governed forgetting
- Sectors: healthcare, finance, HR tech, personal assistants.
- Tools/Workflows: Retention schedules tied to memory items; right-to-be-forgotten workflows; privacy-safe indexing (e.g., selective encryption or on-device stores).
- Dependencies/Assumptions: Legal validation; secure deletion semantics in distributed systems; user-level consent management.
- Continual and test-time learning with state consistency
- Sectors: fast-changing domains (market research, security ops).
- Tools/Workflows: Conflict-aware merging, versioned memory timelines, counterfactual rollbacks; “temporal QA” and “state-reconciliation” training objectives.
- Dependencies/Assumptions: Robust time-aware data models; scalable diff/merge across modalities.
- Memory governance and observability platforms
- Sectors: platform engineering, AI ops, MSPs.
- Tools/Workflows: Centralized observability for memory CRUD (create/read/update/delete); drift detection in retrieval; policy engines that block stale/conflicting evidence from use.
- Dependencies/Assumptions: Unified memory abstractions across teams/tools; APIs for introspection across vendors.
- Human-in-the-loop memory editing and curation
- Sectors: enterprise knowledge management, legal, research, education.
- Tools/Workflows: Review queues for proposed updates/deletions; “memory merge requests” with justification; curator incentives and audit trails.
- Dependencies/Assumptions: Usable UX for non-ML experts; organizational roles and workflows; cost of human review.
- Reliable agentic execution for high-stakes workflows
- Sectors: clinical decision support, financial analysis, incident response.
- Tools/Workflows: Agents that can re-use tool feedback and past failures; “experience libraries” mined from trajectories; guardrails that downgrade autonomy when retrieval/use confidence drops.
- Dependencies/Assumptions: Strong guarantees on provenance and timeliness of updates; human override; liability frameworks.
- Safety research on contamination and memory compartmentalization
- Sectors: all long-lived agent deployments.
- Tools/Workflows: Separation of ephemeral vs. persistent memory; quarantine of low-confidence facts; “shadow memory” for experimentation without polluting core state.
- Dependencies/Assumptions: Formal risk models; performance overhead of duplication/compartmentalization.
- Extending benchmarks to new modalities and environments
- Sectors: autonomous vehicles, AR/VR, voice-first devices.
- Tools/Workflows: Add audio, video, and sensor streams; embodied interaction with richer feedback loops; evaluate multi-agent shared memory.
- Dependencies/Assumptions: Data collection and consent; scalable annotation for multimodal evidence chains; simulator fidelity for safety-critical testing.
These applications leverage WorldMemArena’s core innovations—its actionable lifecycle decomposition, multimodal multi-session tasks, and stage-level annotations—to improve the reliability, transparency, and usefulness of memory in real-world AI agents.
Glossary
- Action-World Interaction Loop: A framework that models agent memory as a cyclical process of observing, writing, retrieving, and acting within an environment. "WorldMemArena formulates multimodal agent memory as an Action-World Interaction Loop, where agents write observations, update evolving memory, retrieve evidence for decisions, and act in the world with feedback."
- Agent harness: A framework that orchestrates tools and memory management during agent execution, often letting agents author and reorganize their own memory. "The rise of agent harnesses that author their own memory sharpens this gap,"
- Agentic Execution: A regime where memory is built from real agent observations, actions, and feedback along realistic trajectories. "Agentic Execution places memory in realistic agent trajectories, where systems must extract reusable evidence from observations, actions, and feedback rather than relying on pre-organized textual narratives."
- append only updates: An update strategy that accumulates new information without revising or removing outdated entries. "most systems rely on append only updates, adding new information when evidence changes rather than revising, removing, or reorganizing obsolete memories."
- BLEU: An n-gram precision-based metric for evaluating text generation quality. "Each question is jointly evaluated using LLM-as-a-Judge, F1, and BLEU to reduce biases from any single metric."
- cross-modal reasoning: Reasoning that integrates and uses evidence across different modalities (e.g., text and images). "Multimodal covers visual fact recall, visual search, visual update, and cross-modal reasoning."
- distractors: Plausible but irrelevant or outdated information added to test whether systems can resist misleading content. "Distractors introduce plausible but irrelevant or superseded information, testing whether the system can distinguish currently valid evidence from noise."
- Embodied: Refers to tasks or settings where an agent acts within a simulated or physical environment, often requiring perception and control. "covering 6 GUI subcategories and 4 Embodied subcategories."
- evidence chains: Annotated sequences of supporting items that link questions to the specific evidence needed for correct answers. "annotated with gold memory points, updates, distractors, and evidence chains for stage-level diagnosis."
- external memory agents: Agents that use explicit memory modules outside the base model for writing, maintaining, and retrieving information. "External memory agents such as MemGPT and Mem0 perform information abstraction, consolidation, and retrieval through learned or hand-crafted modules."
- F1: The harmonic mean of precision and recall, used to evaluate answer quality. "Each question is jointly evaluated using LLM-as-a-Judge, F1, and BLEU to reduce biases from any single metric."
- gold memory points: Ground-truth pieces of information that should be retained after a session. "Gold memory points specify the information that should be retained after a session, representing ground-truth memory content."
- harness-based memory agents: Agents whose memory is authored and managed by the execution harness during interaction. "harness based memory agents are more flexible but remain costly and less reliable."
- latent state: The unobserved underlying state of the environment from which observations are generated. "At step , the world has a latent state , from which the agent receives an observation ."
- Lifelong Evolution: A regime where personal or task states evolve across sessions, requiring ongoing memory tracking and updates. "Lifelong Evolution focuses on personal and task states that evolve across sessions, requiring systems to continuously track, update, and reuse long-term memories."
- LLM-as-a-Judge: Using a LLM to evaluate system outputs (e.g., correctness, hallucination). "Each written item is further assessed by an LLM-as-a-Judge and classified as correct, hallucinated, or irrelevant,"
- long-context agents: Systems that handle memory by concatenating long histories into the prompt without explicit memory mechanisms. "Long-Context Agents. To test whether frontier models can handle long-horizon memory tasks by relying solely on context, these agents concatenate the full interaction history into the prompt as in-context memory, without explicit abstraction, updating, or retrieval."
- long-horizon: Characterizing tasks or agents that operate over extended sequences with many steps and evolving states. "We define each instance as a long horizon agent-world interaction process."
- Normalized Discounted Cumulative Gain (NDCG): A ranking metric that scores retrieval quality based on the relevance and positions of retrieved items. "Normalized Discounted Cumulative Gain (NDCG) measures whether relevant evidence is ranked near the top,"
- Recall@K: A retrieval metric that measures how much required evidence is recovered within the top-K results. "Recall@K and NDCG@K (Normalized Discounted Cumulative Gain) trends under different retrieval cutoffs."
- Retrieval-Augmented Generation (RAG): A method that augments generation by retrieving relevant context from an indexed store. "Retrieval-augmented generation (RAG) systems such as UniversalRAG store historical information in an indexed document store and access it via retrieval."
- Retrieval Coverage (RC): The proportion of necessary evidence successfully retrieved for answering a question. "QA metrics: QA-C = QA Correct, QA-H = QA Hallucination, QA-O = QA Omission, and RC = Retrieval Coverage."
- semantic similarity: A measure of meaning-based closeness between texts used in retrieval; here, the goal extends beyond it to decision relevance. "The goal extends beyond semantic similarity to decision relevance, requiring the retrieved context to contain evidence needed for the current answer or action."
- staged QA checkpoints: Predefined evaluation points within a trajectory to assess memory and reasoning over time. "Each sample further includes staged QA checkpoints with an average of 5 evaluation positions."
- state transition: The change in environment state resulting from an action. "represents the environment response, including both state transition and feedback generation."
- temporal consistency: Maintaining memory that remains coherent and up-to-date as the world evolves over time. "Memory points are merged, revised, and deduplicated across sessions to remove redundancy and ensure temporal consistency."
- test-time learning: Learning or adapting from new experiences during evaluation rather than only from training data. "Reasoning covers temporal reasoning, knowledge reasoning, and test-time learning;"
- tool calls: Agent-initiated invocations of external tools or APIs as part of action execution. "actions may include responses, tool calls, or execution."
- tool feedback: Information returned by tools after invocation, used to inform subsequent decisions or memory. "tool feedback, failed actions, and visual details are often omitted."
- visual grounding: Anchoring questions and answers in visual evidence such as images or screenshots. "supporting broader question coverage and richer visual grounding."
- write-update-retrieve pipeline: A modular view of memory divided into writing, updating, and retrieving steps. "should agent memory be evaluated as a predefined write-update-retrieve pipeline, or as a capability formed through interaction and used to support future decisions over time?"
Collections
Sign up for free to add this paper to one or more collections.