- The paper introduces a benchmark that tests both superficial and deeper reasoning via seven question types, addressing cultural and contextual nuances in LLMs.
- It employs a rigorous dataset of over 1,032 annotated meme clips from diverse sources, ensuring evaluation across languages, audio types, and cultural contexts.
- Empirical findings reveal significant performance gaps in higher-order inference and non-linguistic audio comprehension when compared to human benchmarks.
AVMeme Exam: Multimodal Evaluation of Contextual and Cultural Competence in LLMs
Introduction and Motivation
The AVMeme Exam ("AVMeme Exam: A Multimodal Multilingual Multicultural Benchmark for LLMs' Contextual and Cultural Knowledge and Thinking" (2601.17645)) addresses a vital deficiency in multimodal AI systems: the lack of robust contextual and cultural understanding when interpreting dynamic audio-visual content. Most existing benchmarks focus on literal recognition tasks, neglecting higher-order inference, pragmatic intent, and culturally-grounded reasoning. AVMeme Exam fills this gap by systematically evaluating the capabilities of state-of-the-art multimodal LLMs (MLLMs) against human-constructed queries targeting surface semantics, contextual inference, usage conventions, emotional resonance, and encyclopedic world knowledge, across diverse languages and cultures.
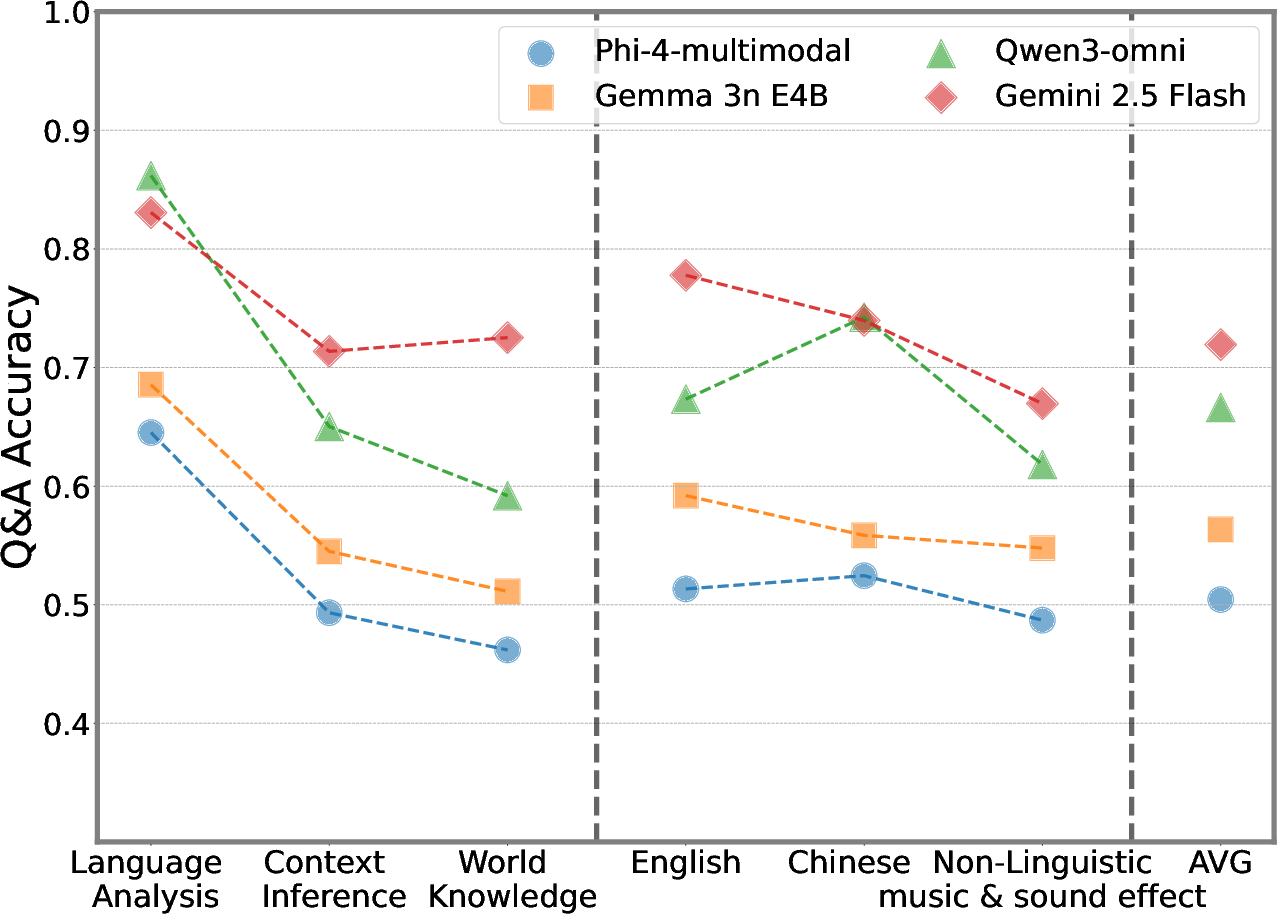
Figure 1: AVMeme Exam includes seven question types that dissect content, context, emotion, usage, humor, and world knowledge, revealing the domain strengths and weaknesses of contemporary MLLMs.
The dataset comprises over 1,032 iconic internet meme clips, sampled from sources such as YouTube and Bilibili, annotated with metadata (transcription, summary, onset/offset, year, sensitivity, emotion, usage), and paired with manually designed multiple-choice queries. Critically, question categories traverse seven semantically distinct axes, ensuring a comprehensive interrogation of model abilities beyond transcription and visual recognition.
Dataset Scope and Curation Pipeline
AVMeme Exam's collection leverages the expertise and cultural exposure of 27 researchers, detailing the composition and provenance of meme clips. The benchmark's sound categories include speech, song, instrumental music, and sound effects, with language coverage spanning English, Chinese, Japanese, Korean, Persian, and non-linguistic audio tracks. Strict safeguards are implemented to exclude political, explicit, or harmful content, with granular sensitivity tagging for implicit cases.
Figure 2: The timeline, distributions, and linguistic diversity of memes in AVMeme Exam showcase coverage across genres, regions, and media types, reflecting contemporary online cultural patterns.
The data pipeline incorporates manual collection, metadata annotation, and rigorous verification by independent reviewers. To eliminate trivial shortcuts, two adversarial procedures are applied: "text-cheat" detection using leading text-only LLMs and "visual-cheat" screening based on presence of solution-revealing on-screen text. This design ensures that model assessment probes genuine multimodal reasoning rather than recall or OCR.
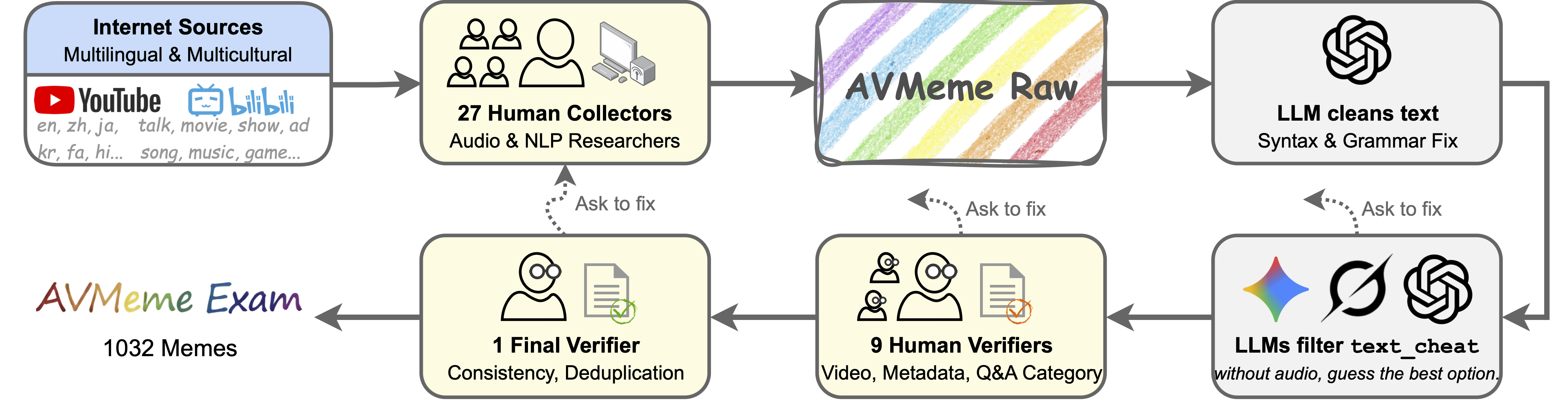
Figure 3: The AVMeme Exam collection and verification pipeline combines human expert annotation with systematic cheat detection, balancing quality control and evaluation rigor.
Evaluation Protocol and Methodology
AVMeme Exam benchmarks ten leading audio-only LLMs and nine audio-visual models, including both open-source and commercial systems (e.g., GPT-4o, Gemini 2.5/3, Qwen3-Omni). All models receive standardized input formatting (mono 16kHz audio, frame-reduced video, sanitized file names) to preclude metadata leakage. Each sample features a multiple-choice question with randomized answer ordering, stratified by question type, sound category, and language. Human baselines are established via controlled user studies (n=20), using IRB-approved protocols, with demographic, familiarity, and background checks to calibrate comparative analysis.
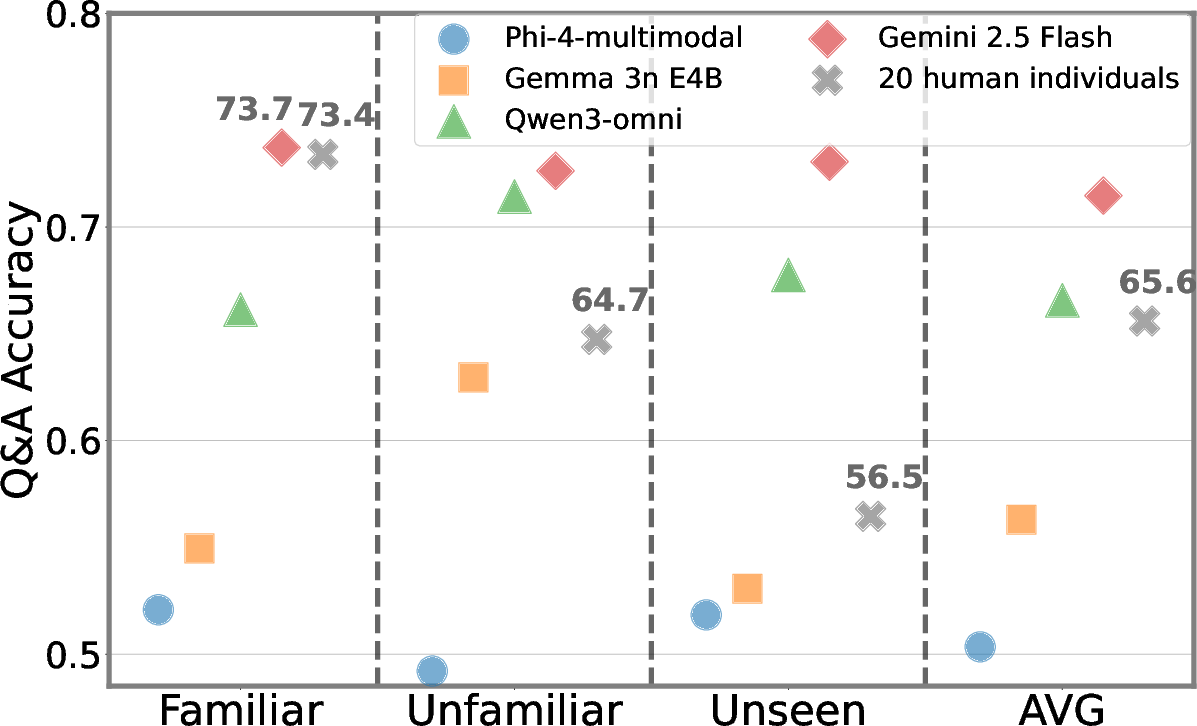
Figure 4: Comparative evaluation between MLLMs and human individuals, stratified by meme familiarity, quantifies AI-human gaps in surface and contextual meme comprehension.
Key Empirical Findings
Models demonstrate strong proficiency on surface linguistic tasks (Language Analysis), with closed-source systems (Gemini 3 Pro) achieving up to 80.0% accuracy in aggregate. Open-source models (Qwen3-Omni) lag substantially, with maximums near 57.4%. Audio-visual integration consistently provides a 5–10% bump in mean accuracy over audio-only configurations. However, model performance declines precipitously—by 15–30%—on higher-order reasoning tasks: Contextual Inference, Usage Application, Humor, and World Knowledge categories (Figure 1).
Robustness to Non-Linguistic Audio
Performance is highest on speech and song, decays on instrumental music, and is lowest on sound effects (textless clips). Even state-of-the-art models rarely exceed 45% accuracy for wordless audio, exposing acute deficits in non-linguistic acoustic comprehension and pragmatic inference.
Linguistic and Regional Biases
English and Chinese clips are consistently better handled than Japanese, Korean, Persian, or non-verbal audio. The mean performance for minority languages seldom reaches 55%, even for commercial LLMs, demonstrating inadequate cross-lingual generalization.
Human vs. Model Comparison
Human participants outperform most MLLMs except on familiar memes, where select advanced models approximate individual human accuracy. However, even in this setting, models fall short on clips requiring nuanced contextual or cultural interpretation. Familiarity assessments further reveal that human grounding remains categorically superior on unseen or culturally ambiguous content.
Ablative Insights and Thinking Effects
Evaluations providing explicit meme names or soft cues ("This is a meme") inflate accuracy by 10% and 2% respectively, showing vulnerability to shortcut exploitation. Retaining visual-cheat samples doubles observed accuracy on affected items, justifying their exclusion for fair benchmarking. Extended model "thinking" via longer reasoning prompts aids explicit recognition tasks (surface audio and world facts), but often degrades pragmatic and cultural inference, indicating limits in model reasoning transfer.
Supplementary Analyses
Temporal aggregation shows that memes from 1980–2000 are most accurately recognized, with performance decline for older or newer content—likely an artifact of uneven web coverage in model training corpora.
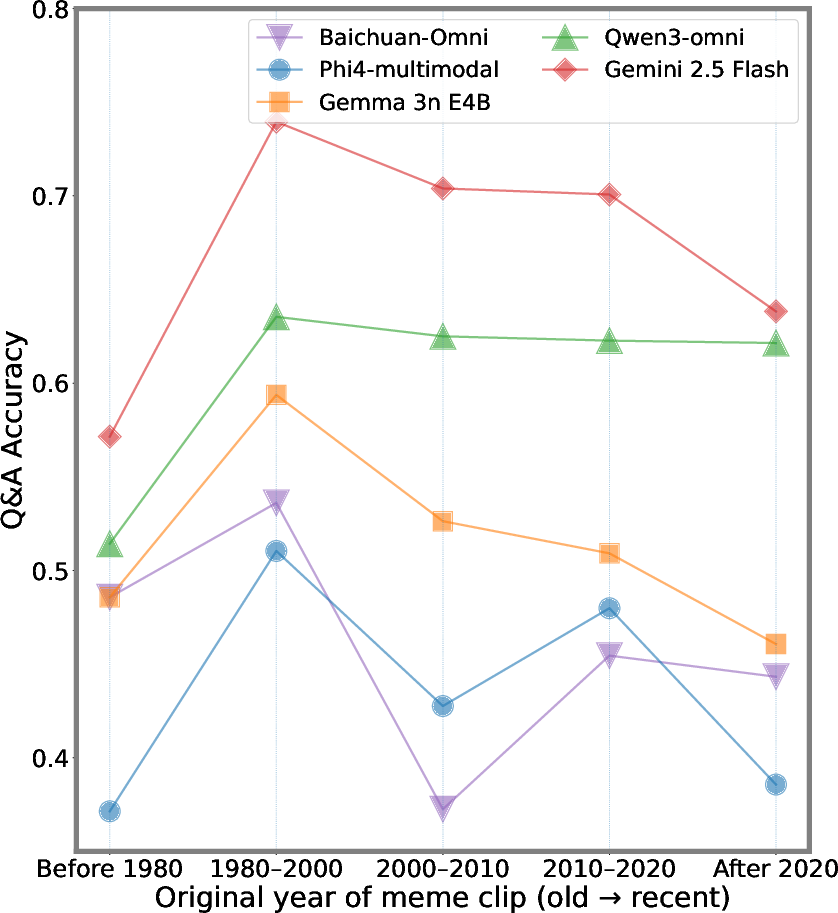
Figure 5: Model performance versus original meme clip year demonstrates sensitivity to Internet-era media, with a peak on 1980–2000 content.
Systematic analysis of visual text reveals direct proportionality between the strength of visual hints and accuracy inflation.
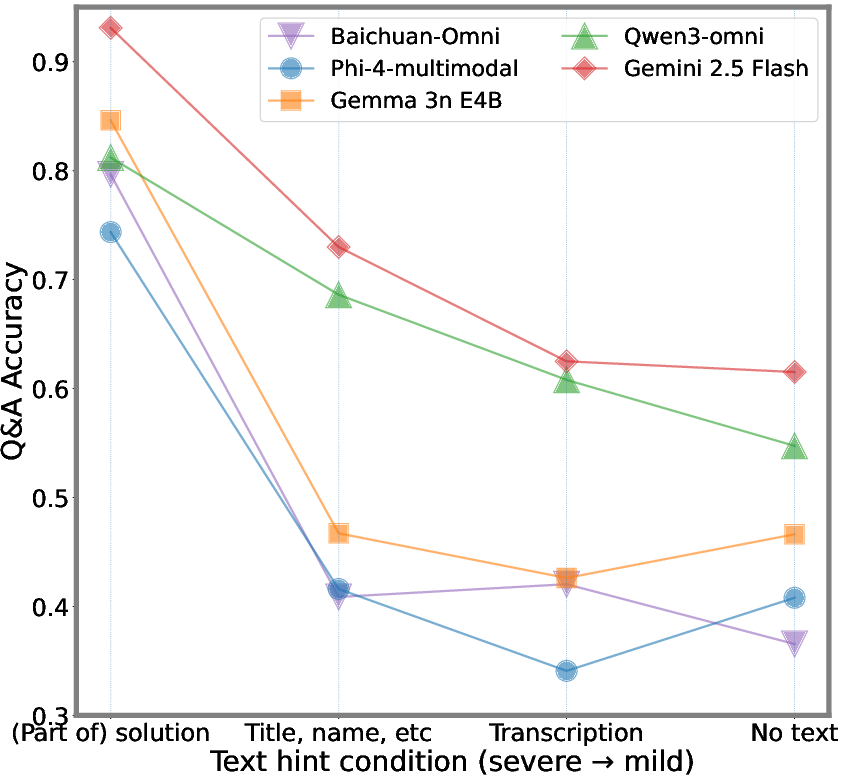
Figure 6: Different levels of visual text hints yield monotonic increases in model accuracy, confirming shortcut susceptibility.
Implications and Prospects for Multimodal AI
The empirical evidence from AVMeme Exam exposes foundational limitations of current MLLMs:
- Surface Bias: Contemporary models excel in parsing overt semantic and linguistic cues, but falter reliably on pragmatic, cultural, and emotional inference tasks.
- Modal/Contextual Deficit: The inability to consistently interpret music and sound effects (especially in absence of textual anchors) indicates insufficient learned representations for non-linguistic audio.
- Culture and Intent Alignment: Models rarely model the operand conventions, cultural idioms, or intent-driven meme usages that characterize real human communication.
These findings have practical ramifications for downstream multimodal systems, e.g., conversational agents, content moderation, or personalized assistants, where misinterpretation of meme culture or contextual signals directly impacts alignment, safety, and user experience. Methodologically, the study underscores the necessity of adversarial, diagnostic benchmarks that rigorously dissect the compositional and generalization boundaries of multimodal AI. AVMeme Exam provides actionable signals for future work: robust fusion of non-linguistic audio, strengthening cultural world knowledge, and training objectives that privilege human-aligned pragmatic reasoning over surface-level recognition.
Conclusion
AVMeme Exam constitutes a comprehensive multimodal benchmark for evaluating contextually and culturally grounded understanding in LLMs. Strong performance on superficial speech and song tasks is offset by substantial deficits on pragmatic, emotional, and world knowledge questions, particularly for non-linguistic audio and less-represented languages. The persistent human advantage in meme comprehension, even as models approach parity on familiar clips, affirms the current gap between web-scale training and true human-aligned multimodal intelligence. The work calls for architecturally and algorithmically novel approaches rooted in pragmatic context modeling and culture-centric supervision. Further expansion of cultural, temporal, and linguistic coverage, as proposed by the authors, remains essential for advancing AI toward deeper, intent-aware comprehension.