- The paper introduces a white-box analytical predictor that accurately estimates vLLM’s CPU-bound cold start latency.
- It decomposes the startup process into six phases, revealing linear scaling behaviors and distinct hardware dependencies.
- Empirical results underscore that CPU optimizations yield greater latency improvements than GPU or storage upgrades.
A Systematic Analysis of vLLM Cold Start Latency
Introduction
This paper presents a comprehensive characterization and modeling of cold start latency in vLLM, currently a dominant engine for LLM inference workloads. While vLLM underpins many production- and research-scale LLM deployments, prior work lacks a detailed decomposition of its startup pipeline and robust understanding of how hardware, model, and software configurations influence initialization latency. This work addresses these limitations by dissecting the startup pipeline into six distinct steps, rigorously quantifying latency sources, and elucidating their hardware and scaling dependencies. A modular, white-box analytical predictor is constructed, offering practical and interpretable estimation of cold start latency for resource management in serverless and dynamically scheduled inference settings (2606.07362).
Decomposition of the vLLM Startup Pipeline
The startup process—the interval from process launch to readiness for serving inference requests—is dissected into six foundational phases:
- Framework Bootstrapping: Environment setup and dependency import, largely independent of model parameters and primarily implementation-dependent.
- Tokenizer Initialization: Vocabulary and merge rules are loaded; this is a CPU-bound, strictly linear function of tokenizer size.
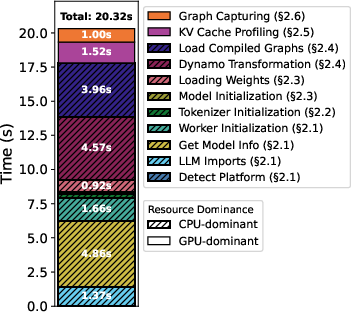
Figure 1: Breakdown of vLLM startup latency steps on Llama3.2-3B, identifying dominant steps and their resource (CPU/GPU) dependency.
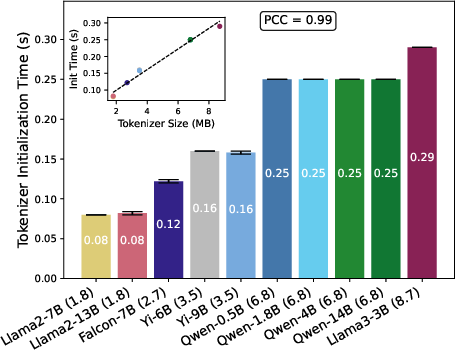
Figure 2: Linear scaling of tokenizer initialization with tokenizer file size, illustrating how vocabulary inflation directly increases cold start time.
- Model Loading: The model architecture is instantiated, followed by checkpoint loading. Weight loading costs scale strictly with the number of parameters and precision. Empirical trends confirm strong linearity.
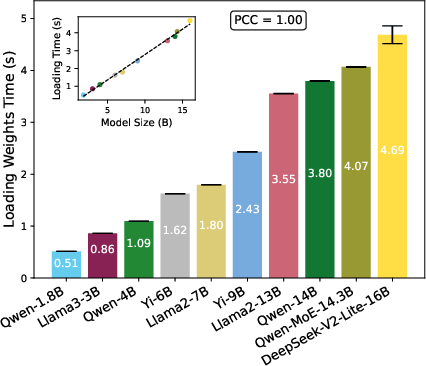
Figure 3: Weight loading latency scales linearly with model size, highlighting predictable I/O–driven loading characteristics.
- Torch Compile (Graph Generation and Loading): torch.compile, now integral to vLLM, captures compute graphs for compiler-based optimization. Both the Dynamo graph generation and graph loading scale linearly with the aggregate size of the compiled artifacts, which itself is an explicit function of architecture complexity and layer count.
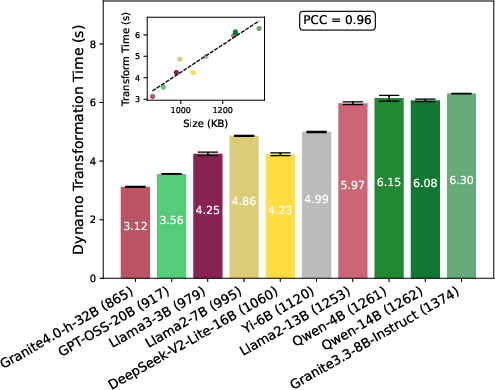
Figure 4: Dynamo transformation costs are strictly linear in compiled graph size.
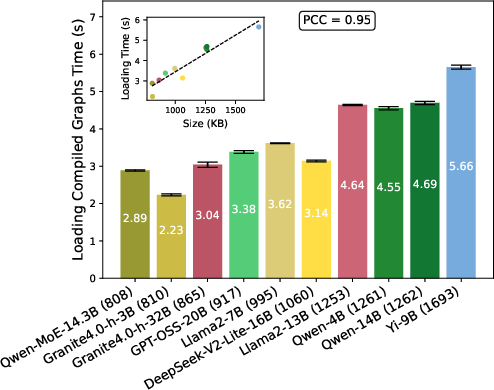
Figure 5: Loading time for compiled graphs correlates linearly with compiled graph file size.
- KVCache Profiling: Dummy forward execution determines required memory for key–value caching. Non-MoE models exhibit linear scaling with model size; deviations are observed with MoE due to expert routing dynamics.
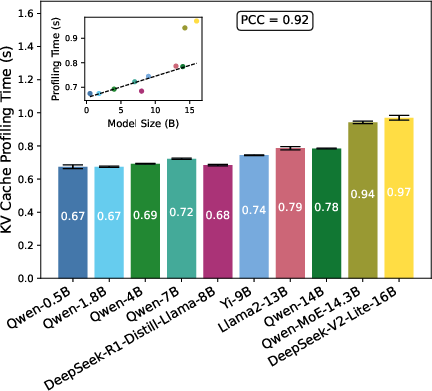
Figure 6: KVCache profiling time linearly tracks model size for non-MoE, with outliers for MoE models due to additional complexity.
- CUDA Graph Capturing: Dummy batches are executed to record CUDA graphs for accelerated subsequent inference, with duration scaling linearly in both model size and batch count.
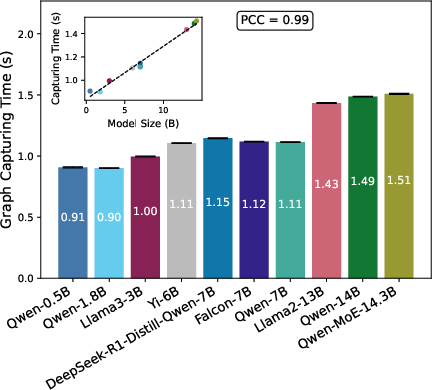
Figure 7: CUDA graph capture time as a linear function of model size.
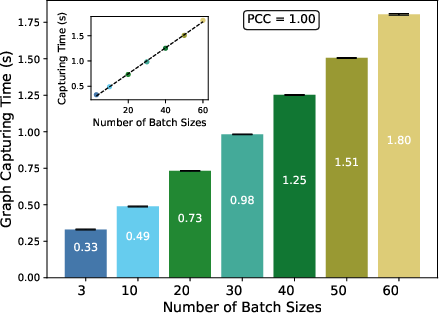
Figure 8: CUDA graph capture time increases proportionally with batch count for a fixed model.
This decomposition reveals that, except for the last two steps (profiling and CUDA capture), cold start latency is overwhelmingly CPU-bound.
Empirical Evaluation Across Hardware and Models
The authors benchmarked 22 models, 4 node types (combinations of recent AMD/Intel CPUs and NVIDIA H100/L40S GPUs), and multiple storage backends. Key observations include:
- GPU Type: Startup steps (apart from CUDA capture) exhibit negligible speedup when using an H100 versus an L40S, confirming non-GPU-bound latency.
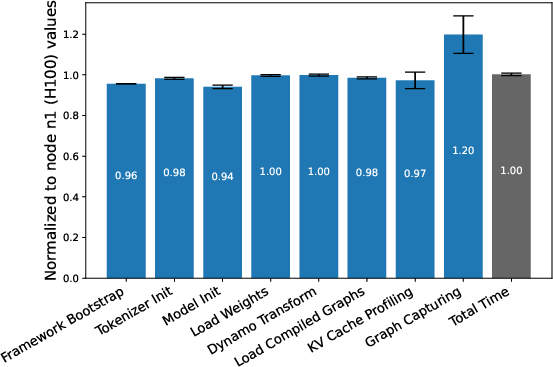
Figure 9: Normalized startup latency per step, comparing H100 and L40S GPUs—most steps show near-identical timing.
- CPU Type: CPU selection alters startup latency substantially; per-core utilization heatmaps show sequentially saturated CPU usage, limited parallelism, and stepwise serialization.
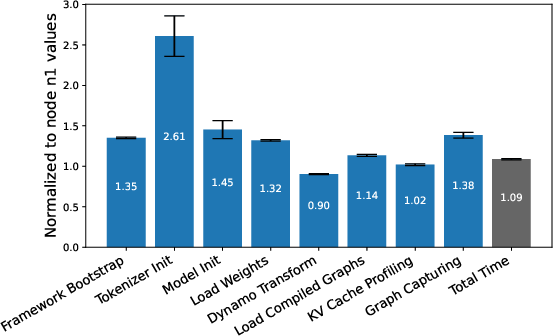
Figure 10: Impact of CPU microarchitecture on startup latency; significant variance across frameworks.

Figure 11: CPU per-core utilization during vLLM startup, showing serial critical-path bottlenecking.
- Storage Backend: With weights loaded directly from SSDs instead of DRAM, only the Model Loading phase is impacted, but overall startup time remains nearly unchanged. Storage optimizations affect only a small fraction of total cold start costs.
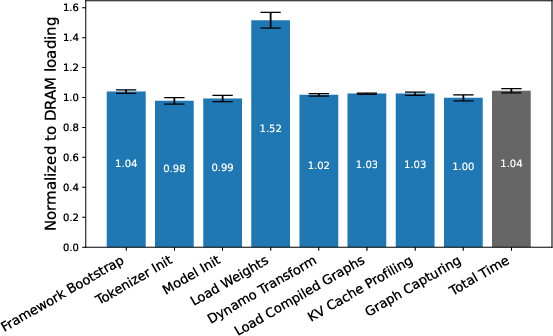
Figure 12: SSD impact on cold start—model loading is slowed, but dominant CPU-bound steps remain unaffected.
- Weight Loading Methods: Alternative methods (Run:ai Model Streamer, CoreWeave Tensorizer) can significantly reduce checkpoint loading time but have marginal effect on the end-to-end startup duration.
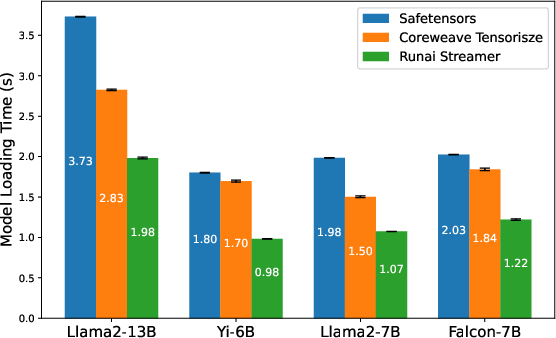
Figure 13: Different weight deserialization schemes; Tensorizer and streaming optimize only the model loading phase.
- Compiled Graph Caching: Disabling compiled graph cache (triggering a true cold compile) inflates latency by a factor of up to 4× in that step.
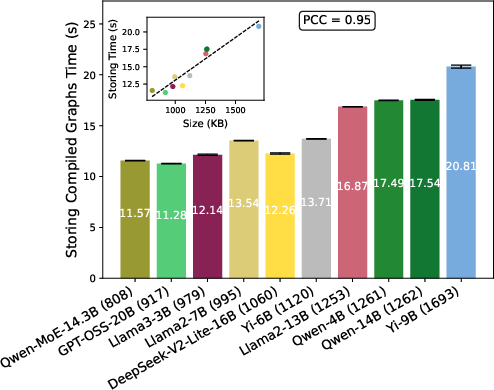
Figure 14: Cost of storing compiled graphs without a cache—latency scales with graph size, rivaling or exceeding loading time for some models.
White-Box Analytical Predictor for Startup Latency
The authors design an analytical, white-box predictor, implementing independent linear regressors for each of the six startup steps (excluding model architectures with known non-linearities such as MoE). The modeling process involves gathering training data via systematic profiling, training step-specific models, and aggregating predictions. Validation shows high accuracy (MSE ≈ 2.4 s, maximum error ≈ 2.1 s), and accurate transfer across vLLM versions (from 0.10 to 0.11).
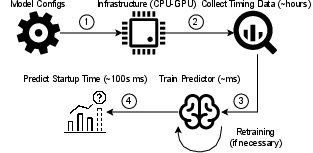
Figure 15: Workflow of the stepwise, modular vLLM startup latency predictor.
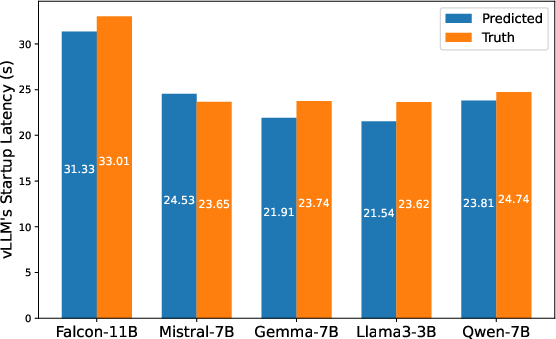
Figure 16: Accuracy of predicted versus measured cold start latencies across held-out models.
Strong claim: Cold start latency can be accurately and robustly predicted in an interpretable way using modular per-step regressors, without requiring end-to-end black-box modeling. This enables actionable policies for serverless LLM scheduling and resource planning.
Theoretical and Practical Implications
Theoretical Implications
- Isolation of Latency Sources: Distinguishing CPU-dominant versus I/O or GPU-bound phases refines resource provisioning strategies and challenges prior assumptions that LLM serving is universally GPU-bound.
- Modular Predictive Modeling: Stepwise decomposition of initialization logic can be extended to other distributed inference and containerized deployments, and forms a template for future LLM-serving systems and runtime analysis research.
- Linearity and Exceptions: Model-independent, near-linear stepwise latency enables interpretable, extrapolatable scheduling, but deviations (MoE, SSM, diffusion) must be addressed for coverage expansion.
Practical Implications
- Guidance for Autoscaling and Scheduling: Operators can perform lightweight offline profiling, then generalize predictions to new models/hardware for just-in-time autoscaling, improving TTFT and minimizing overprovisioning, crucial for bursty, cost-sensitive serverless workloads.
- Hardware Investment: Investment in improved CPUs and compiler/runtime optimizations will yield more meaningful reductions in cold start latency than simply upgrading GPU hardware or storage, under current vLLM architectures.
- Directions for vLLM Optimization: Parallelization of startup steps (tokenizer, compilation, profiling) or persistent process design should yield practical startup latency reductions. For instance, the decomposition identifies torch.compile and compilation artifact management (both generation and cache load) as next targets for software optimization.
Limitations and Future Directions
- Non-linear Models: The predictor only addresses non-MoE architectures with strictly linear scaling. Profiling and predictive methodologies will need to expand to fully support MoE, latent, and hybrid architectures.
- Beyond Local Engine Context: The paper intentionally isolates the inference engine, without encompassing network, distributed storage, or container initialization delays. Integration into full end-to-end deployment studies remains as future work.
- Real-World Variance: Empirical measurements are subject to minor platform- and workload-driven deviations; predictor tuning required for heterogeneous deployments.
Conclusion
This paper constitutes the first rigorous, systematic decomposition and analysis of vLLM's startup latency, demonstrating that cold start is dominated by CPU-bound and serialized phases, with stepwise latency scaling that is strongly linear with simple, observable configuration parameters. The proposed analytical predictor delivers step-explainable, accurate initialization time estimations and lends itself to real-world autoscaling and scheduling use in large-scale, dynamic serverless LLM infrastructure. The methodology and findings have generalizability to other inference frameworks and outline next-stage research challenges in minimizing startup latency—both via software parallelism and upstream predictive scheduling.
Reference:
Breaking the Ice: Analyzing Cold Start Latency in vLLM (2606.07362)