- The paper introduces EdgeFlow, a co-designed system that applies NPU-aware adaptive quantization, SIMD-friendly packing, and fine-grained pipeline scheduling to reduce mobile LLM cold start latency.
- It achieves up to 4x faster first-token times across models (e.g., Llama3 8B, Mistral 7B) while maintaining near-lossless accuracy compared to INT8 baselines.
- Empirical evaluations on devices like the Xiaomi 15 Pro demonstrate significant latency improvements and energy savings, making mobile LLM deployments more feasible.
EdgeFlow: Fast Cold Starts for LLMs on Mobile Devices
Motivation and Systemic Bottlenecks of Mobile LLM Cold Starts
EdgeFlow addresses a critical challenge in on-device LLM inference for mobile platforms: cold-start latency, defined as the time to first token (TTFT) when the LLM weights are not resident in device memory. Empirical profiling reveals that the cold start process on state-of-the-art frameworks such as LLM.npu is dominated by two components: weight loading from flash storage and computation graph preparation. Even with optimized techniques like materialization (offline graph compilation) and pipeline overlapping, TTFTs remain well beyond acceptable human-interaction thresholds (e.g., over 9s for Llama3 8B, considerably above the 7s user patience limit) (Figure 1).
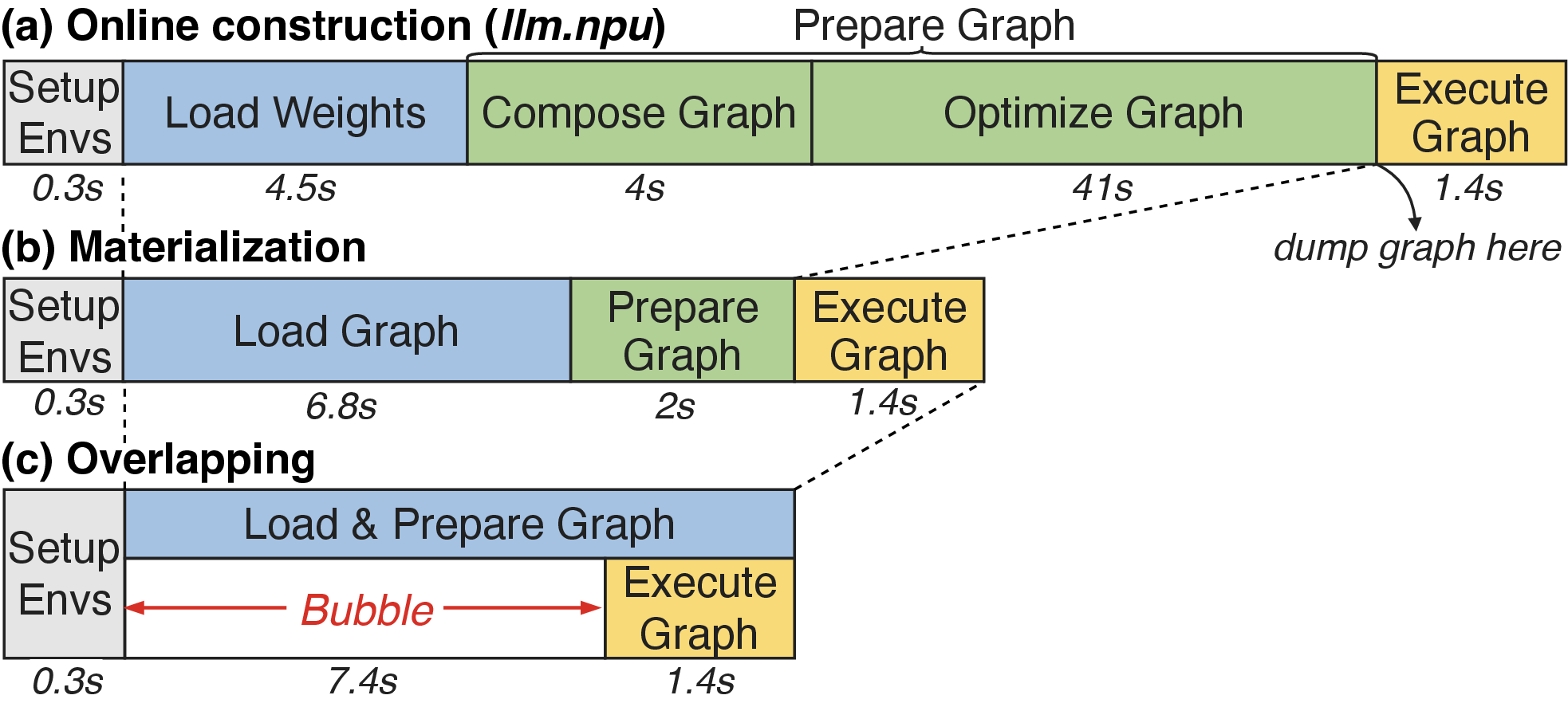
Figure 1: Breakdown of the cold-start latencies of LLM.npu and two straightforward optimizations, materialization and overlapping.
Efforts to reduce latency through aggressive preloading are constrained by mobile device memory budgets, where satisfying TTFT SLOs (~7s) could require reserving up to 4GB, which is prohibitive for many devices (Figure 2). Thus, a reduction in transferred weights—not merely I/O scheduling—is essential.
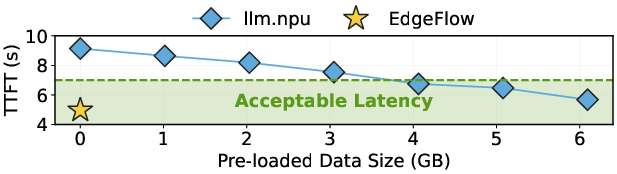
Figure 2: TTFT v.s. pre-loaded data size for LLM.npu, showing user-acceptable latency region and EdgeFlow’s measurements.
Technical Innovations: System-Quantization Co-Design
EdgeFlow introduces three synergistic techniques, explicitly co-designed with the constraints of NPUs and mobile storage systems:
- NPU-aware adaptive quantization: Unlike uniform quantization (INT8 for all weights), EdgeFlow applies per-output-channel precision assignment, subject to strict NPU requirements (symmetric, uniform per-channel quantization). The algorithm selects bit-widths for each channel based on an efficient, local relative error metric grounded in cosine distance approximations, enabling greedy, optimal allocation to fit a global bandwidth budget.
- SIMD-friendly packing and unpacking: Mixed-precision tensors present considerable unpacking overheads, especially with non-byte-aligned weights (e.g., 3- or 5-bit). EdgeFlow proposes a weight packing format that decomposes each weight into “weightlets” of 1, 2, or 4 bits and stores them in an interleaved SIMD-parallel manner (Figure 3). Unpacking utilizes SIMD masking, shifting, and merging, achieving an average of 0.48 SIMD instructions per unpacked weight (Figure 4).
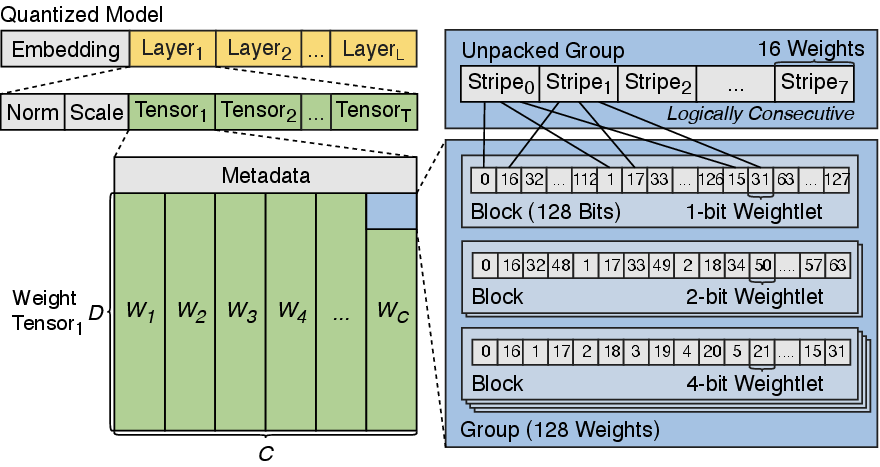
Figure 3: SIMD-friendly packing format. The index in each weightlet corresponds to the weight’s channel.
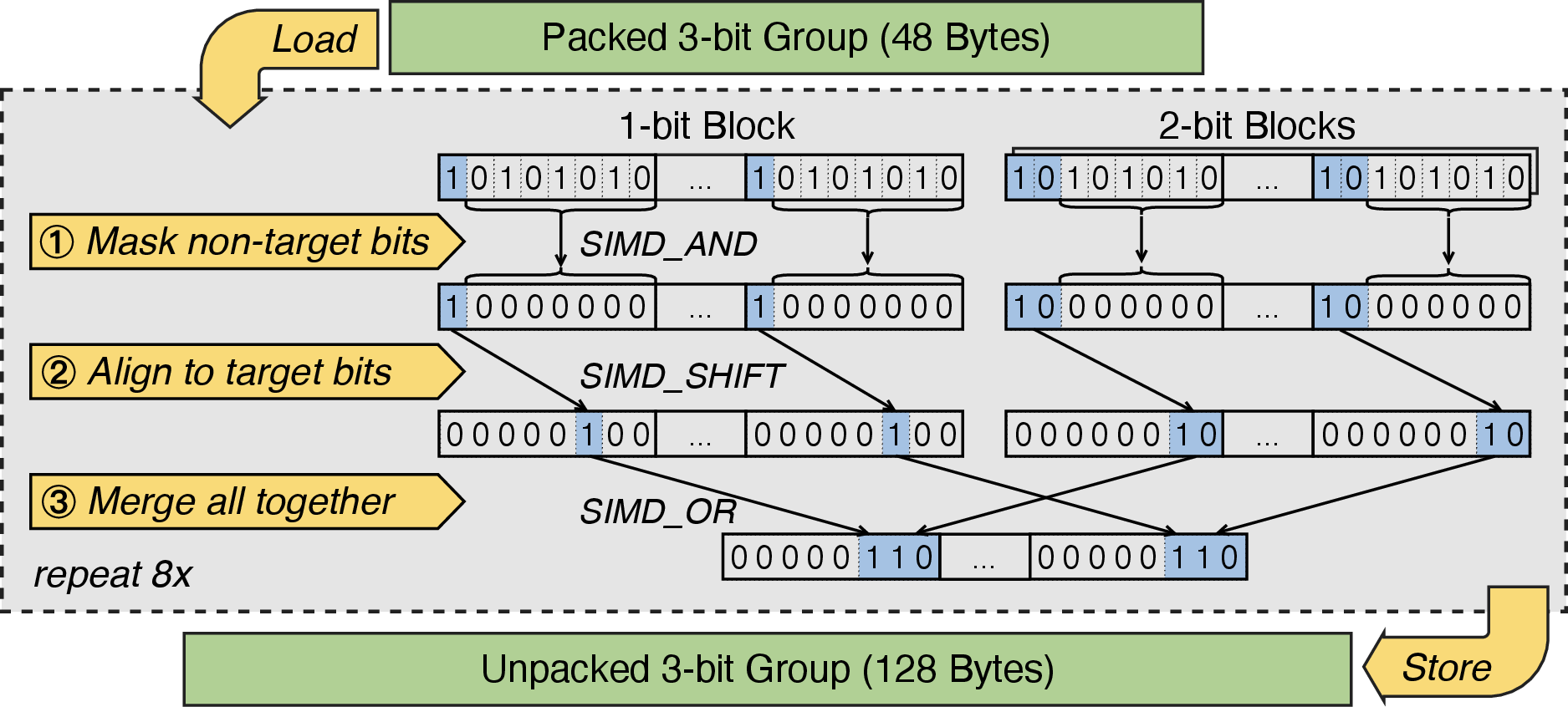
Figure 4: SIMD-based unpacking algorithm for heterogeneous bit-precision weights.
- Synergistic granular pipeline: EdgeFlow refines operator placement and scheduling between the NPU and CPU. All INT8 matrix multiplications are dynamically dispatched to the NPU, while element-wise, low-arithmetic-intensity operators are placed on the CPU. The pipeline utilizes position-guided task prioritization and CPU-side task stealing to minimize idle (bubble) time and correct load imbalance, which is prevalent in static, coarse-grained schedules (Figure 5).
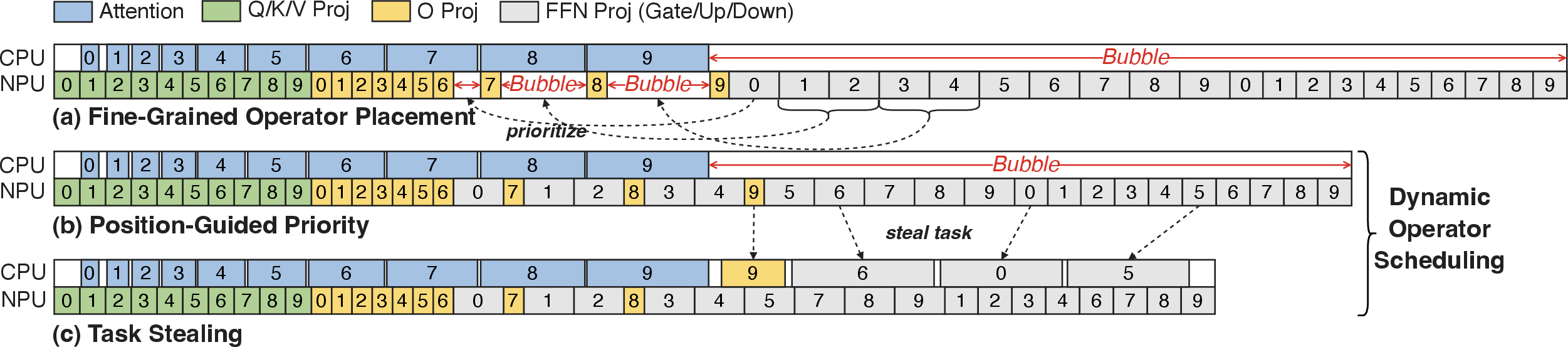
Figure 5: The synergistic granular pipeline with fine-grained operator placement and dynamic operator scheduling; each block is an operator, chunked for parallel scheduling.
Empirical Evaluation and Ablation
EdgeFlow is implemented with full stack visibility (custom Python quantization utilities, C++ runtime, direct QNN API integration for dynamic weight injection), running on Xiaomi 15 Pro with Hexagon NPU. Comprehensive evaluation covers Llama3 8B, Mistral 7B, Phi3 3.8B, and Qwen1.5 1.8B, spanning a wide prompt-length distribution (LAMBADA, WinoGrande, OBQA, MMLU, HellaSwag).
Significant speedups are demonstrated for cold TTFT:
- At 7-bit average quantization, EdgeFlow achieves 3.92×, 2.28×, 1.47× TTFT reduction over llama.cpp, MNN, and LLM.npu, respectively.
- At 4 bits, TTFT improvements reach 4.24×, 2.53×, 1.63×.
- Even at long prompts, the pipeline’s operator scheduling yields 1.37×–1.41× speedup beyond the best NPU-optimized baseline (LLM.npu).
Crucially, these latency gains are attained while maintaining equivalent or improved accuracy compared to INT8 baselines (EdgeFlow’s 5-bit configuration shows a negligible —0.03%—accuracy drop to LLM.npu). The adaptive quantization outperforms both uniform INT4 and competitor mixed-precision schemes (AWQ, CMPQ) in top-1 accuracy and perplexity, especially at low bit-widths (Figure 6, Figure 7).
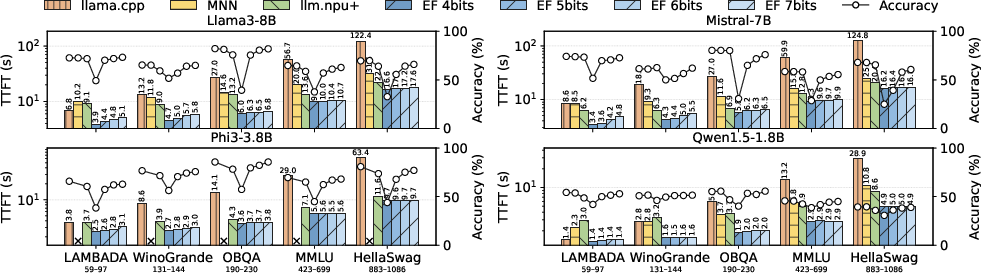
Figure 8: Cold start latency (TTFT) and accuracy of different methods on various models and datasets.

Figure 6: Accuracy of quantization schemes across precisions on Llama3 8B; dotted line: FP16 accuracy.

Figure 7: Accuracy of quantization schemes across precisions on Phi3 3.8B; dotted line: FP16 accuracy.
EdgeFlow also demonstrates state-efficient unpacking/packing, balancing I/O and compute for minimum total pipeline blocked time (Figure 9), and a detailed breakdown shows energy savings of 12.9% against the closest NPU-based baseline with only a minor increase in mean power draw (Figure 10).
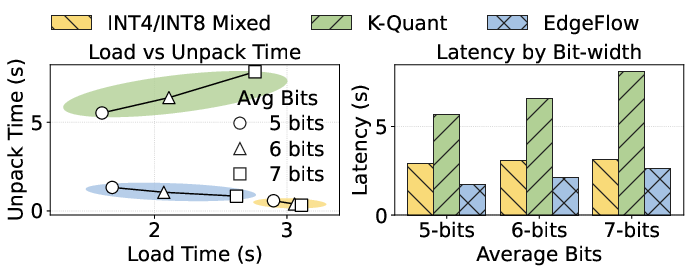
Figure 9: Performance comparison of different storage formats (EdgeFlow vs. K-Quant and INT4/INT8 mixed).
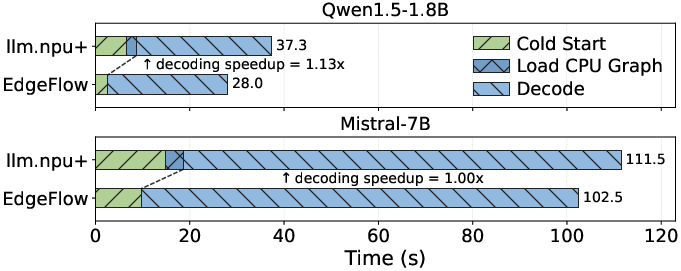
Figure 11: Breakdown of end-to-end completion latency.
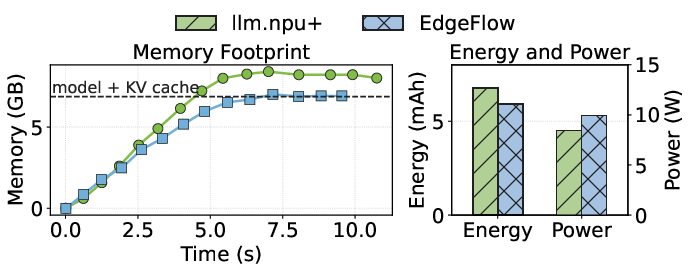
Figure 10: Comparison of resource consumption during the cold start phase of Mistral 7B with 512 tokens.
Implications and Future Directions
EdgeFlow demonstrates that co-designing quantization algorithms and system-level scheduling/packing, cognizant of NPU hardware and mobile storage constraints, can dramatically reduce TTFT for LLMs on mobile platforms, with no substantial loss in model accuracy or decoding throughput.
Practical implications include:
- Broader applicability: The quantization and system organization methods are immediately portable to other NPUs (including MediaTek NeuroPilot and Apple Neural Engine), supporting deployment diversity in mobile ecosystems.
- Orthogonality to other approaches: EdgeFlow’s pipeline and quantization designs are additive to emerging storage-loading and compute optimization techniques (e.g., neuron rematerialization [mobicom25elms], flash-aware bundling [acl24llmflash], speculative decoding [tmc25llmcad], and dynamic input pruning [mlsys25dip]).
- Model scaling: By minimizing memory footprint and I/O, EdgeFlow makes larger LLMs and multi-modal models (e.g., BlueLM-V-3B [cvpr25bluelm], MiniCPM-V [arxiv24minicpm-v]) feasible on commodity mobile devices.
Theoretically, the results validate the hypothesis that weight importance is a local property suitable for efficient mixed-precision assignment, even under severe hardware constraints, and that fine-grained pipeline scheduling is required to leverage NPU acceleration without creating new bottlenecks.
Future work should explore adaptive quantization in conjunction with run-time model adaption (dynamic bitwidth adjustment under real-time energy or latency budgets), tight integration with OS-level data prefetch and memory management, and extending SIMD-friendly packing schemes for more diverse hardware-software stacks.
Conclusion
EdgeFlow establishes a robust, empirical foundation for latency-optimized on-device LLM inference, substantiating that system-level and quantization algorithmic co-design can achieve up to 4.07× faster cold starts with comparable or improved accuracy on modern mobile SoCs. The techniques introduced help shift on-device LLM applications from proof-of-concept toward deployability at interactive latency, broadening the frontier for privacy-preserving, always-available AI on ubiquitous personal devices (2604.09083).