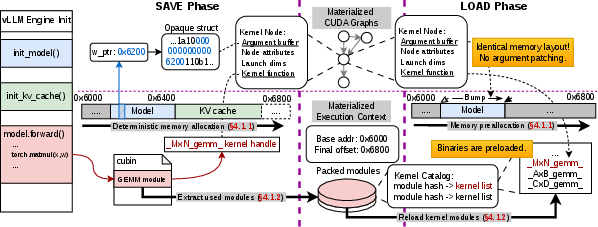
- The paper introduces Foundry, which persistently captures both CUDA graph topology and full execution context to drastically reduce cold-start latency for LLM serving.
- It employs a two-phase SAVE and LOAD pipeline that leverages deterministic memory layouts and kernel binary extraction for rapid, kernel-agnostic graph restoration.
- Evaluation results show up to a 99% reduction in initialization time with preserved throughput, enabling efficient scaling in distributed, multi-GPU environments.
Foundry: Template-Based CUDA Graph Context Materialization for Fast LLM Serving Cold Start
Motivation and Background
Dynamic autoscaling and rapid parallelism reconfiguration are essential for operational efficiency in production-scale LLM inference, especially under highly dynamic workloads where request rates and sequence lengths fluctuate significantly. While recent advances have reduced model weight loading to mere seconds via optimized transfer protocols, cold-start latency remains dominated by CUDA graph capture, which can require tens of seconds to minutes even after prior optimizations. The inability to serialize CUDA graphs—due to their deep entanglement with device-specific execution context, such as embedded device pointers and kernel handles—renders existing solutions brittle or heavyweight, limiting their applicability and generality.
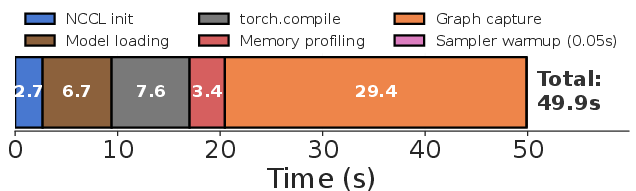
Figure 1: Breakdown of vLLM worker initialization when serving Qwen3-14B on 2xH200s. The graph capture step dominates the initialization time.
CUDA graphs are critical for high-throughput LLM inference engines; disabling them results in significant performance degradation due to increased host-to-device launch overhead.
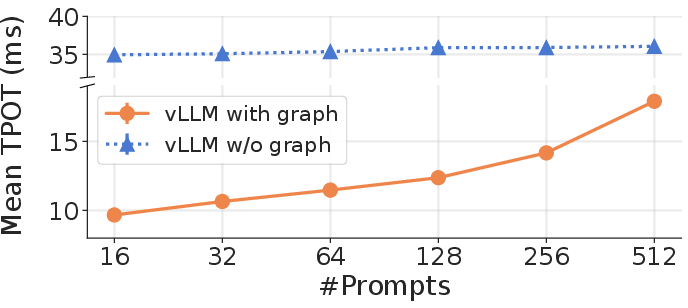
Figure 2: Time per output token (TPOT) increases notably when decoding with vLLM without CUDA graphs (across batch sizes), reflecting the critical impact of graph-level kernel fusion.
Medusa exemplifies topology-only capture, which demands fragile, kernel-specific patching at restore-time and fails to robustly accommodate evolving kernel layouts or new hardware and model architectures. By contrast, Foundry’s approach is to persist both the graph topology and its full execution context.
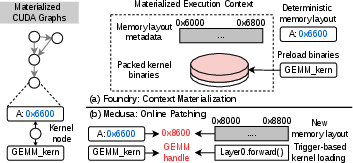
Figure 3: Medusa captures only topology, while Foundry persists the necessary execution context, making restoration kernel-agnostic.
System Overview and Key Insights
Foundry introduces a two-phase template-based pipeline for rapid, kernel-agnostic CUDA graph restoration:
Crucially, Foundry generalizes efficiently to distributed, multi-GPU environments: a single-GPU offline capture suffices to generate templates that can be patched online with rank-dependent communication state (e.g., for NCCL or NVSHMEM), supporting dynamic parallelism reconfiguration with no redundant warmups.
This interposition is achieved by Foundry acting as a CUDA driver hook.
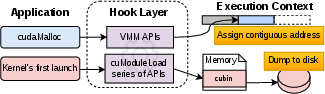
Figure 5: Foundry is injected via a CUDA driver hook, redirecting allocations and kernel loading for deterministic replay.
Design: Context Materialization and Templating
Execution Context Materialization
- Deterministic Memory Layout: By intercepting and redirecting memory allocations using CUDA’s virtual memory management APIs, Foundry ensures that device pointers embedded in captured graph nodes remain valid and consistent across SAVE and LOAD. The allocation sequence is recorded and deterministically replayed to guarantee pointer stability—even when transient intermediates differ between phases.
- Kernel Binary Extraction and Reload: By intercepting module load APIs, Foundry captures both the payload and function mapping (by content hash and mangled name) for all relevant kernel binaries, enabling precise function handle restoration without re-triggering warmup logic.
Efficient Graph Reconstruction via Templating
Graph captures for different batch sizes and ranks typically share a small set of unique topologies, varying only in per-node parameters (e.g., arguments, launch dimensions).
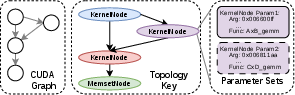
Figure 6: Graph templates encode shared topologies, while parameter sets provide per-instance specialization.
Rather than instantiating one graph per instance, Foundry builds one template per unique topology; parameter updates are issued on demand, leveraging the CUDA driver’s efficient in-place node parameter update API. Topology grouping is encoded during SAVE and exploited during LOAD for concurrent, lock-free preparation of parameter sets, significantly reducing wall-clock graph build time and resource contention.
Evaluation
Cold-Start Latency and Scalability
Foundry achieves up to 99% cold-start latency reduction compared to native vLLM with CUDA graphs, shrinking initialization from minutes to a few seconds across both dense and MoE models up to 235B parameters.

Figure 7: Foundry reduces engine initialization time by up to 99% relative to vLLM’s default CUDA graph capture across multiple model-parallelism configurations.
A detailed breakdown systematizes this improvement across both dense and expert-parallel deployments.
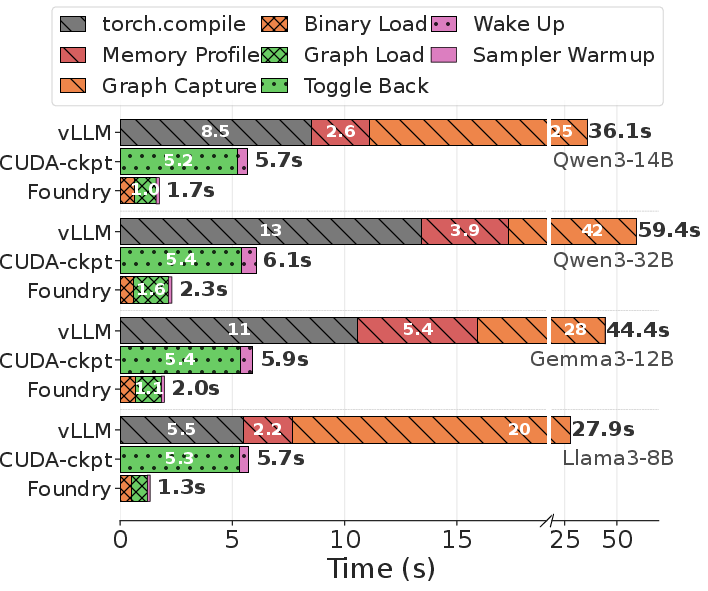
Figure 8: Phase analysis of end-to-end initialization: Foundry consistently outperforms both vLLM and CUDA-checkpoint, eliminating graph capture as a bottleneck.
Serving Throughput Preservation
Throughput analysis demonstrates no statistically significant degradation: TPOT with Foundry overlaps nearly perfectly with baseline native graph-capture performance.

Figure 9: Mean TPOT as a function of batch size for vLLM and Foundry: identical throughput confirms semantic equivalence.
This validates the semantic fidelity of Foundry’s execution context materialization and template-based restoration.
Templating Efficiency
Templating compresses the large set of captured graphs (e.g., 512 for batch sizes 1–512) to a handful of templates (12–25 per model, comprising 2–5% of graphs), allowing over 95% of graphs to be served via rapid in-place parameter update rather than full reconstruction.
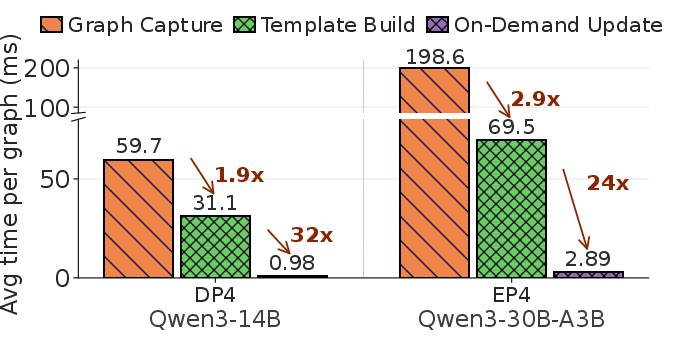
Figure 10: Per-graph construction cost: parameter update is 24–32x faster than template instantiation; both far surpass native stream capture speed.
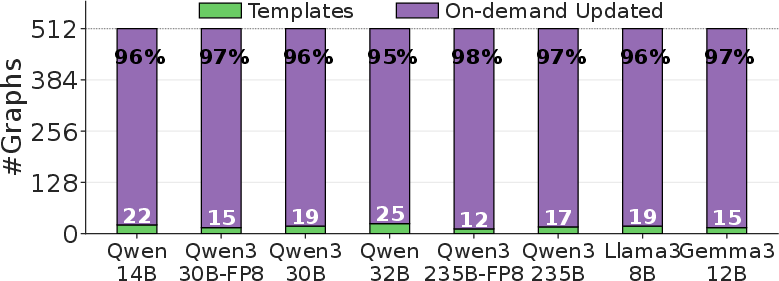
Figure 11: Fraction of graphs (per model) that can be served by on-demand parameter update, highlighting the dramatic compression to a small set of templates.
Theoretical and Practical Implications
The separation of topology and execution context enables kernel/dashboard/library-agnostic graph restoration, removing the need for kernel-specific patching and enhancing portability to evolving model architectures and hardware platforms. By generalizing to SPMD-style parallel inference, Foundry reduces both the hardware cost and storage requirements of graph materialization, facilitating flexible, fine-grained autoscaling and dynamic parallelism policy optimization.
Practically, Foundry enables large-scale LLM deployments to minimize the "time to first token" during autoscale-up or parallelism reconfiguration events, directly improving resource elasticity and user experience.
Theoretically, this approach suggests a path toward general-purpose, hardware-agnostic snapshotting of heterogeneous accelerator execution graphs—a direction with potential applicability to other domains beyond LLM inference.
Conclusion
Foundry provides a robust, kernel-agnostic solution to the cold-start bottleneck in scalable LLM serving by coupling template-based CUDA graph context materialization with deterministic execution context restoration. Empirical results demonstrate orders-of-magnitude latency reduction while maintaining peak throughput and minimal storage overhead. Foundry establishes a general, portable, and efficient framework for rapid LLM service startup and dynamic reconfiguration (2604.06664).