- The paper demonstrates that fully GPU-resident KV caching (vLLM) achieves the highest throughput and lowest latency, while alternative methods trade memory usage for performance.
- H2O employs static sparsification with heavy-hitter eviction to significantly reduce GPU memory by selectively pruning the cache, albeit with moderate accuracy loss in long-context tasks.
- InfiniGen uses a dynamic CPU-GPU approach with recoverable eviction, balancing high accuracy and early-context retention against reduced throughput due to serialized data transfers.
Comparative Characterization of KV Cache Management Strategies for LLM Inference
Introduction
Key-Value (KV) cache management has become a primary bottleneck for efficient LLM inference, especially as model sizes escalate and context windows approach hundreds of thousands of tokens. While the Transformer architecture’s self-attention mechanism relies on the retention and reuse of key/value tensors for computational efficiency, the resultant memory footprint for the KV cache can quickly surpass the size of the model weights, necessitating advanced strategies for both memory reduction and computational performance. This paper conducts an in-depth comparative analysis of three leading frameworks—vLLM, H2O, and InfiniGen—that epitomize, respectively, the paradigms of contiguous full-cache GPU memory management, static sparsification with eviction, and hierarchical dynamic selection. The analysis spans a range of inference scenarios, including scaling with context length, batch size, and output length, as well as the retention and accuracy under KV cache sparsification.
Frameworks and KV Cache Management Paradigms
Three distinct architectural philosophies underpin the selected frameworks:
- vLLM uses PagedAttention with contiguous batching, maintaining the complete KV cache in GPU memory, minimizing memory fragmentation, and ensuring maximum computational throughput. There is no sparsification or eviction; all tokens are retained for the duration of the request.
- H2O implements Heavy Hitter eviction, scoring tokens by attention-weighted relevance and retaining only a subset within a sliding window, with permanent eviction for the remainder. This static sparsification drastically reduces GPU memory pressure but can degrade accuracy, especially for tasks relying on information located far back in the context.
- InfiniGen maintains the full KV cache in CPU memory and dynamically speculates on which entries to transfer to the GPU at each decode step, leveraging offline SVD-based importance identification. This paradigm enables recoverable eviction, trading off throughput for high accuracy, particularly under extreme memory pressure or long-context scenarios.
Time-to-First-Token (TTFT) and Long-Context Behavior
The initial latency for token generation (TTFT) exposes foundational differences between paradigms. vLLM consistently achieves the lowest TTFT and can process input sequences up to 128K tokens, due to native FlashAttention-2 and chunked prefill optimizations.
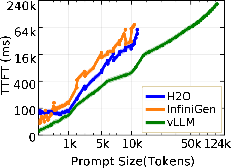
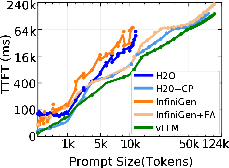
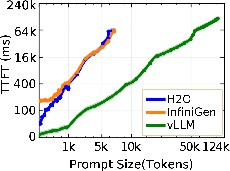
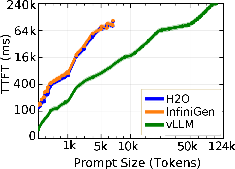
Figure 1: TTFT for Llama-3.1-8B on a single H100 GPU shows vLLM's superior scaling in prompt length compared to OOM failures faced by H2O and InfiniGen.
Both H2O and InfiniGen, in their baseline implementations, suffer OOM errors at prompt lengths around 10K tokens due to the necessity of materializing the complete O(n2) attention matrix during sparsification or heavy-hitter selection, regardless of total GPU capacity. This bottleneck is partially addressable. FlashAttention-2 integration enables InfiniGen to match vLLM’s context range while reducing prefill memory usage by 85% and latency by 77% compared to chunked prefill, but offers no benefit to H2O since its static eviction mechanism fundamentally requires full attention matrix storage.
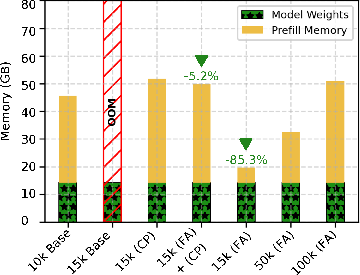
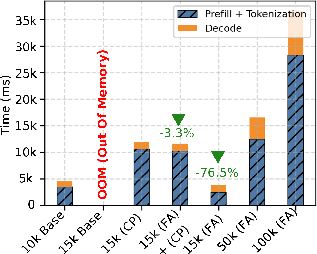
Figure 2: GPU memory breakdown during the prefill phase with InfiniGen highlights reduced usage with FlashAttention-2.
Resource Utilization and Throughput Under Concurrency
With batch sizes scaling from 16 to 96 and multi-thousand token inputs, the frameworks exhibit sharp divergence in raw resource utilization and throughput. vLLM saturates the full physical GPU memory (≈72GB for Llama-3.1-8B) but achieves the highest decode throughput with effectively flat latency scaling.

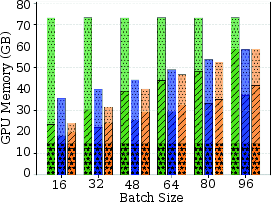
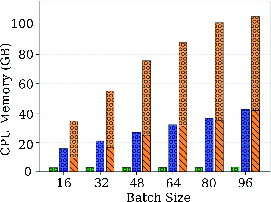
Figure 3: GPU memory usage across batch sizes shows vLLM's fixed allocation, H2O's efficient dynamic scaling, and InfiniGen's low GPU but high CPU memory consumption.
H2O consistently requires less than 40GB GPU memory even at maximum concurrency via aggressive cache pruning, achieving a 2× memory efficiency gain over vLLM though at the expense of a moderate increase in latency due to cache management overhead. InfiniGen’s offloading brings GPU usage down to H2O’s level but shifts the burden to >100GB CPU memory due to pinning and buffer requirements for fast CPU-GPU KV movement. Its decode throughput is consistently an order of magnitude below vLLM/H2O due to serialized transfers at every decode step.
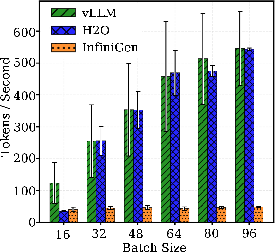
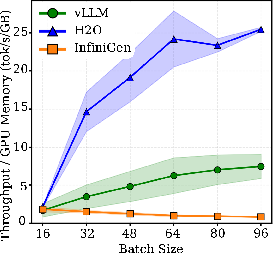
Figure 4: Decode throughput scaling with batch size, illustrating the constant throughput advantage of vLLM and H2O over InfiniGen.
Normalized throughput per GB of GPU memory underscores H2O's advantage (≈3× higher than vLLM), whereas InfiniGen’s normalized throughput degrades with batch size, emphasizing the transfer-induced inefficiencies.
Output Length Scaling and End-to-End Latency
For long-form generation tasks with outputs up to 8,192 tokens, throughput and latency gaps compound. vLLM holds a 15–17× throughput and walltime advantage over InfiniGen for maximum-length generations, with H2O again offering a compromise between memory usage and latency. Prefill costs are constant with output length, but decode time scales linearly. For InfiniGen, the per-token transfer cost dominates such that longer generations do not amortize fixed startup costs.
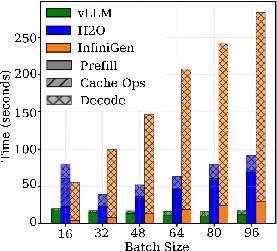
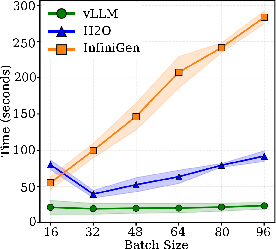
Figure 5: Walltime breakdown for extended output lengths highlights the persistent decode-phase penalty of InfiniGen relative to the GPU-resident approaches.
Accuracy, Sparsity, and Contextual Retention
Critical to the utility of sparsification is the accuracy impact for downstream tasks. With moderate sparsity (KV budget = 0.3–0.5), both H2O and InfiniGen preserve accuracy within 10pp of vLLM across six reasoning benchmarks. At aggressive sparsity (budget = 0.1), InfiniGen suffers moderate (6pp, but up to 17–20pp for knowledge-centric tasks), while H2O can lose up to 23pp—especially on benchmarks requiring broad contextual integration. At extreme sparsities (2–4%), both degrade to near-random on complex reasoning.

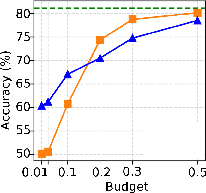
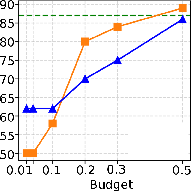
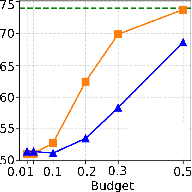
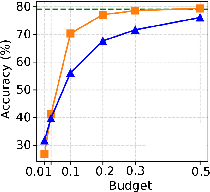
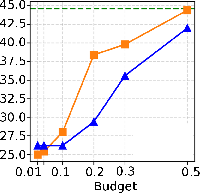
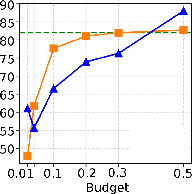
Figure 6: PIQA accuracy profile demonstrates severe degradation for both strategies under extreme sparsity.
Custom retention experiments in multi-turn conversations with early-context fact injection show InfiniGen retaining 92–94% factual accuracy, closely tracking vLLM (94–96%), while H2O degrades to 70–78% (up to 27pp lower at longer context windows). This property is significant for applications demanding reliable extraction or recall of tokens appearing early in an extended context window.
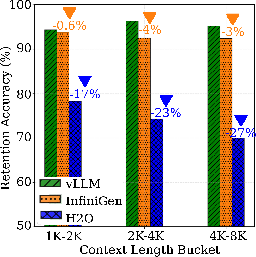
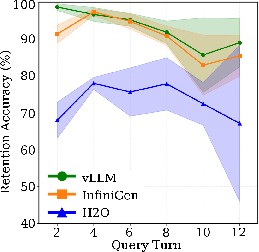
Figure 7: Retention accuracy by context-length bucket quantifies degradation for H2O under increasing context window lengths.
Implications and Future Directions
The findings delineate no single dominant approach: if GPU memory is unconstrained, fully GPU-resident caching with vLLM delivers maximal throughput and minimal latency with zero degradation in accuracy or retention. Where memory pressure is severe, H2O enables substantial memory savings with only moderate impact on throughput, but can severely penalize context retention and reasoning as sparsity increases. InfiniGen is appropriate where accuracy and early-context retention are paramount but throughput is secondary, as in knowledge retrieval systems or compliance settings. The cost is major: CPU-GPU interconnect bandwidth and serialization of decode steps. Improvements in inter-GPU and CPU-GPU bandwidth (such as with NVLink-C2C) could mitigate InfiniGen’s primary bottleneck in future deployments.
Theoretically, static sparsification frameworks are fundamentally limited by the need for full prompt attention to identify heavy-hitter tokens. Dynamic selection opens the door for more context-aware, query-driven retrieval and compression. Future directions could involve integrating more advanced predictive strategies, adaptive quantization, or favoring ever-finer hierarchical placements of KV cache across heterogeneous memory/storage subsystems.
Conclusion
This work's rigorous empirical analysis elucidates the core trade-offs of KV cache management in LLM inference. vLLM remains optimal for maximal hardware utilization scenarios. H2O, while highly memory-efficient, can compromise task accuracy and retention. InfiniGen achieves superior accuracy under extreme memory constraints but suffers substantial throughput collapses, determined by CPU-GPU bottlenecks. The nuanced guidance provided allows practitioners to select and configure KV cache strategies as a function of their deployment’s memory, throughput, and accuracy constraints, and indicates that as system interconnects evolve, the space of feasible design points for LLM inference will also shift accordingly.
Reference: "Comparative Characterization of KV Cache Management Strategies for LLM Inference" (2604.05012)

