- The paper introduces LLM-Emu, a serving-native emulator that replaces GPU forward execution with latency sampling to accurately emulate LLM inference.
- It leverages a profile oracle with 2D-keyed batch size and request concurrency for density-aware sampling, achieving key metric errors below 5%.
- The design seamlessly integrates with vLLM, eliminating the need for custom scheduler reimplementation or CUDA interception while preserving production APIs.
LLM-Emu: Native Runtime Emulation of LLM Inference via Profile-Driven Sampling
Introduction
The paper "LLM-Emu: Native Runtime Emulation of LLM Inference via Profile-Driven Sampling" (2605.00616) introduces LLM-Emu, a serving-native emulator that enables accurate, efficient, and wall-clock online emulation of LLM inference within the vLLM system. The authors address a critical gap in the evaluation of LLM serving systems: the lack of realistic, low-cost emulators that fully preserve online serving stacks and precisely reproduce dynamic, heterogeneous workloads without recourse to extensive hardware resources. The proposed framework preserves the native execution paths of vLLM—including scheduling, HTTP stack, KV-cache management, and output processing—replacing only the GPU forward execution with latency sampled from offline profiles. This design eliminates the need for scheduler reimplementation, per-operator latency abstraction, CUDA interception, or offline-only operation, thereby minimizing maintenance and ensuring direct compatibility with rapidly evolving production serving stacks.
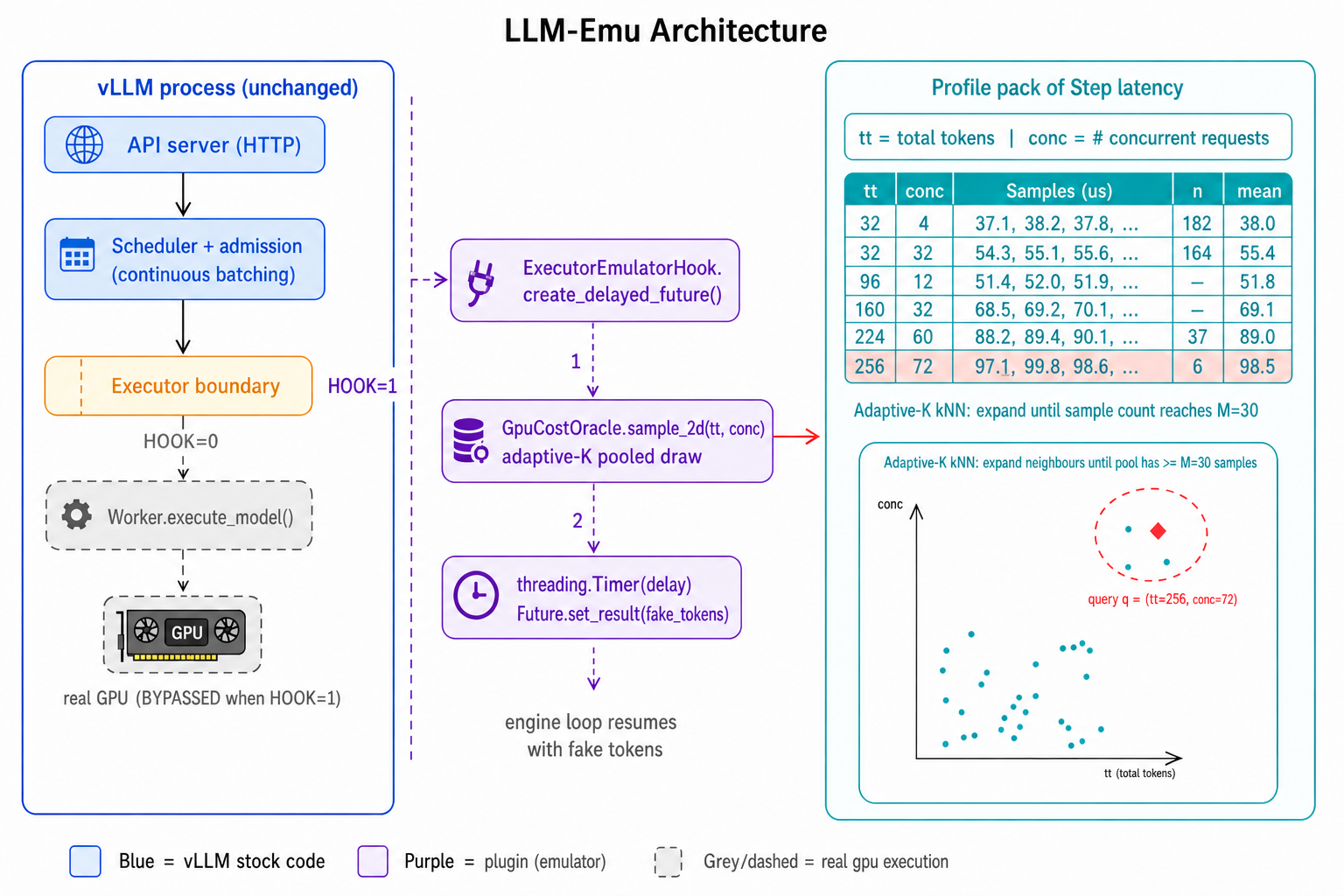
Figure 1: Integration of LLM-Emu at the executor boundary; all other components are vLLM native code.
Design and Methodology
LLM-Emu is implemented as a runtime plugin that hooks at the executor boundary, sampling step-level latencies and returning synthetic tokens via timer-based Futures. The emulator leverages a profile oracle that references a joint distribution table indexed by batch token count and request concurrency. This two-dimensional keyed design enables LLM-Emu to capture the dominant sources of variability in GPU compute for autoregressive generation, including the effects of batch dynamism, prefill, and decode splits.
The offline profiling mechanism collects step-level latency samples across varying workload intensities—covering low load to saturation—across model and hardware axes. Profiles are straightforward JSON artifacts used by the runtime oracle for live emulation, with an adaptive neighbor-pooling algorithm (range-normalized 2D distance thresholding) for density-aware sampling in sparse regions. Notably, all emulator activation is controlled at launch-time via environment variables, and no modification of client code or serving syntax is required.
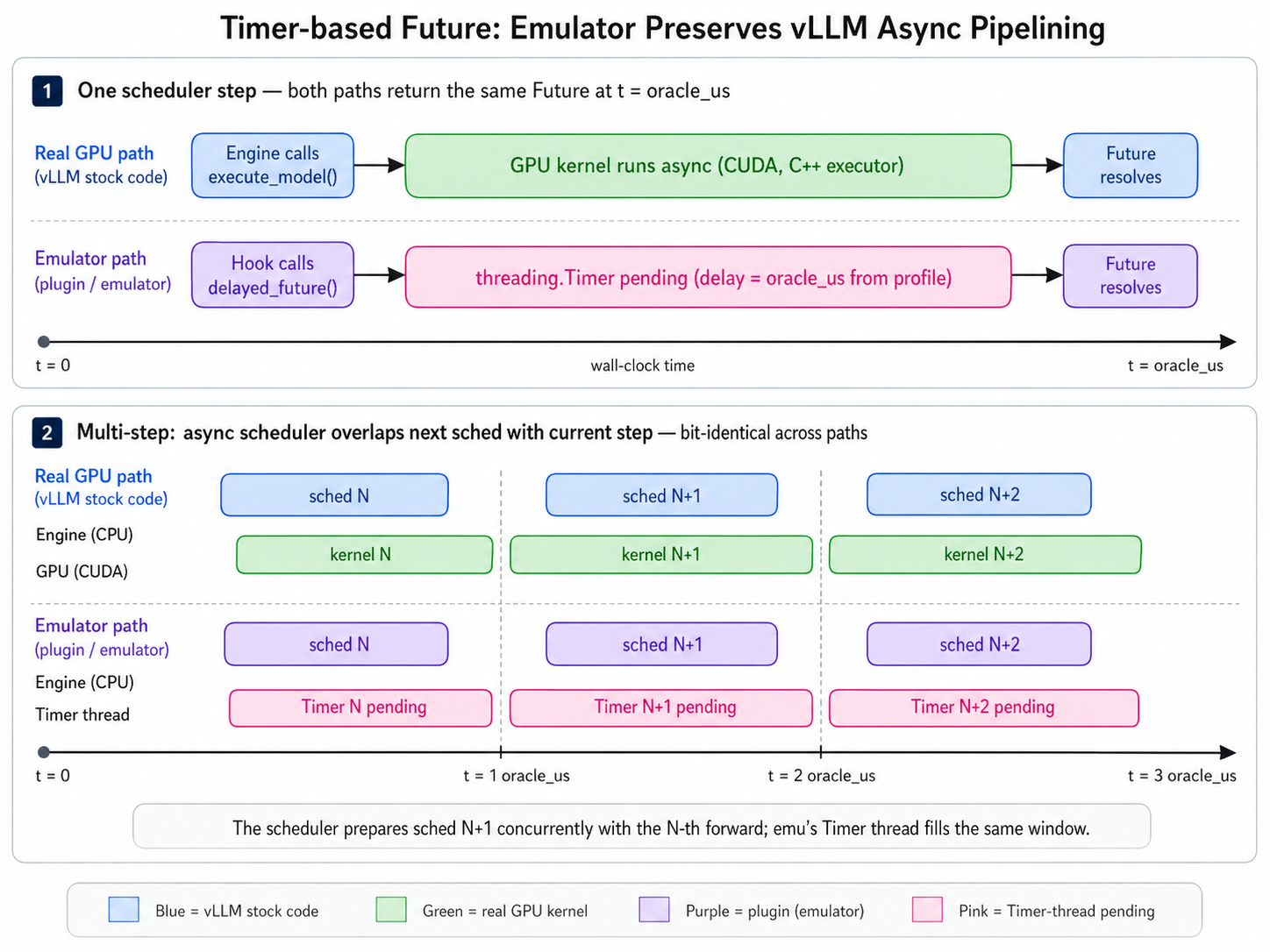
Figure 2: Timer-based Futures ensure overlap of scheduling and worker pipelines as in production serving.
This architecture enables seamless switching between real and emulated execution using identical process interfaces. The plugin is compact, introducing only ~2.5k lines of code against vLLM 0.18.1, a significant reduction compared to other simulation frameworks such as Vidur, LLMServingSim, or AIConfigurator, all of which require extensive custom or parallel scheduler implementations.
Evaluation
Experimental validation covers a comprehensive matrix of conditions: two GPUs (RTX8000 and A40), four model scales across two families (Qwen3-4B/8B/14B, Llama-3.1-8B), two attention backends (FlashInfer, FlashAttention2), and both Poisson and highly bursty workloads derived from ShareGPT traces. Metrics evaluated include Time to First Token (TTFT), Time Per Output Token (TPOT), Iteration Time Latency (ITL), end-to-end latency (E2E), and output token throughput.
Empirical results demonstrate:
- TPOT and ITL within 4.8% absolute error relative to real vLLM.
- E2E latency within 5.3% absolute error.
- Output throughput within 1.9% absolute error.
- TTFT error is somewhat higher (up to 10.4%) due to its sensitivity to admission control and burst workload transients.
Even under extreme burstiness (γ=0.25, i.e., highly non-Poisson arrivals), the emulator tracks steady-state throughput and latency metrics within 5% of hardware runs. The largest sources of error correspond to workload scenarios where batch composition and startup effects are highly volatile, specifically impacting TTFT but not token-level or macro throughput metrics.
The emulator also closely mirrors queueing, scheduling, and memory pressure, since the rest of the code path (HTTP, admission, KV-cache, chunked prefill, paging) is unchanged from vLLM, and only the forward path is sampled/emulated.
Comparison to Prior Emulation and Simulation Frameworks
Unlike Vidur, LLMServingSim, and AIConfigurator—which either reimplement schedulers, require per-kernel analytical models, or operate strictly offline—LLM-Emu achieves fidelity by directly executing the production code path of vLLM and leveraging end-to-end HTTP/serving interfaces. The only change required for emulation is providing an offline profile matching the target hardware, model, and workload, and activating the plugin.
Comparatively, Revati (Agrawal et al., 1 Jan 2026) employs time-warped emulation via CUDA interception and kernel prediction, but is designed for offline time acceleration rather than serving-native wall-clock operation. LLM-Emu targets wall-clock fidelity and stateful online service, including queueing and dynamic arrival effects. The minimal integration surface also leads to higher maintainability, especially as serving frameworks evolve with revised memory management, caching, or new batching policies.
Implications and Future Directions
LLM-Emu's validation indicates that serving-native profiling and low-dimensional sampling is sufficient to capture critical serving system metrics across significant axes of variability (model, backend, workload, hardware). From a practical standpoint, this enables reproducible, low-cost online experimentation for both academic research and production systems engineering. For capacity planning, the emulator supports realistic exploration of scheduler and admission policies, system bottlenecks, and even the effects of future hardware upgrades, without requiring continuous access to expensive GPU clusters.
The limitations include: (a) the non-trivial cost and duration of offline profiling (hours per model/hardware/configuration); (b) coverage restricted to single-node deployments and matched workloads; and (c) TTFT divergence under highly adversarial burstiness or model cold-start behaviors. The authors note that multi-node and accelerated time-warped emulation are promising future directions, as is automated profile/oracle drift detection in anticipation of rapid API iteration in serving frameworks such as vLLM.
The results make a case for more tightly integrated emulation tooling, with direct code path compatibility, as the state-of-the-art for realistic and low-latency LLM serving research, superseding custom or parallel logical simulators except when specialized kernel or hardware modeling is needed.
Conclusion
LLM-Emu demonstrates that serving-native emulation, leveraging offline profile-driven sampling and minimal executor-boundary intervention, can achieve high-fidelity, maintainable, and wall-clock-accurate emulation of modern LLM serving stacks. The system eliminates the need for scheduler reimplementation, per-operator modeling, or CUDA interception, while retaining compatibility with production APIs and downstream tools. In steady-state regimes, error rates for all macro-level service metrics remain below 5%, with only first-token startup latency reflecting greater variance due to intrinsic system non-determinism. Future advances will likely extend this approach to multi-node and accelerated time domains, further broadening the practical utility of profile-driven emulators for the LLM infrastructure research community.