- The paper systematically analyzes 25 LLM inference engines, correlating architectural features with runtime performance and scalability.
- It categorizes optimization methods like batching, parallelism, compression, caching, and attention improvements to enhance inference speed.
- Empirical benchmarks validate that advanced hardware and design optimizations can dramatically reduce latency and increase throughput.
A Framework-Centric Survey of Inference Engines for LLMs: Optimization and Efficiency
This essay presents a comprehensive, structured analysis of "A Survey on Inference Engines for LLMs: Perspectives on Optimization and Efficiency" (2505.01658). The paper systematically assesses 25 open-source and commercial LLM inference engines, correlating architectural features and optimization techniques with performance, scalability, and ecosystem maturity. It contextualizes recent advances in LLM inference and provides a clear taxonomy for engine selection and development.
Architectural Overview and Inference Process
Recent advances in transformer-based LLMs—particularly decoder-only architectures—have made model-scale and hardware-optimized inference the determinant drivers of latency, throughput, and deployment cost. The standard inference flow consists of prefill and decode phases, each with distinct computational and memory characteristics. In prefill, batch GEMM/attention operations (quadratic in input length) dominate computation and memory. Decode is memory-bandwidth limited, with a linear increase in time-between-tokens (TBT) as output length grows. Performance-critical metrics include Time-to-First-Token (TTFT), TBT, end-to-end latency, and throughput—each targeted by specialized optimizations in inference engines.
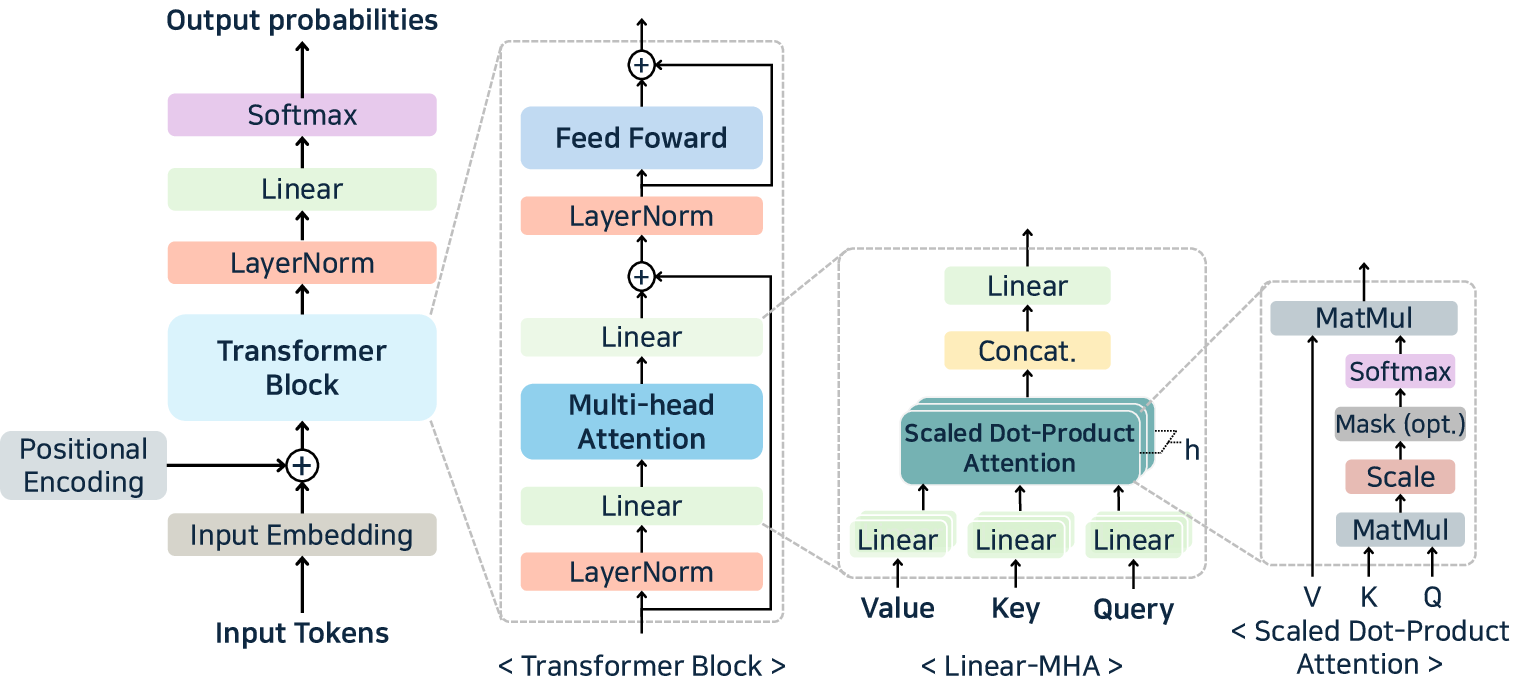
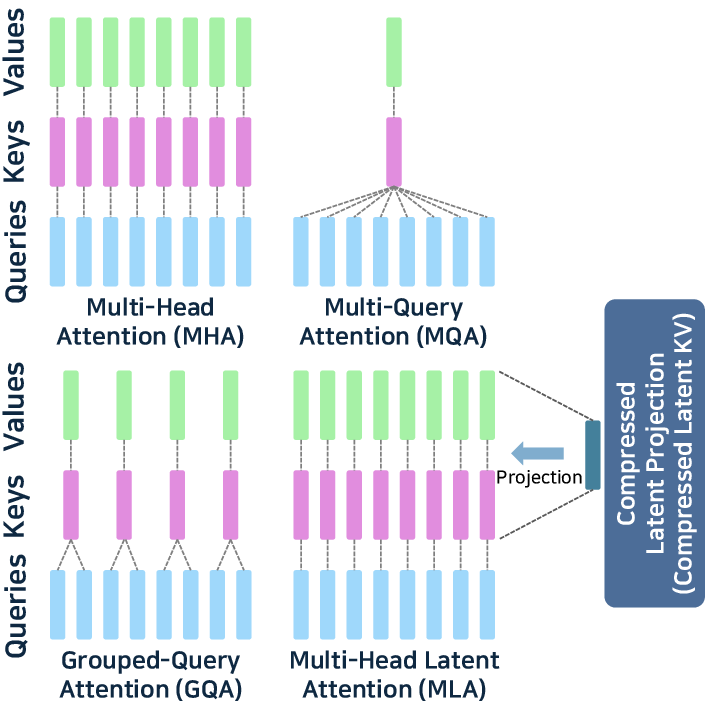
Figure 1: Decoder-only transformer architecture and attention mechanism—core compute structures in contemporary LLM inference pipelines.
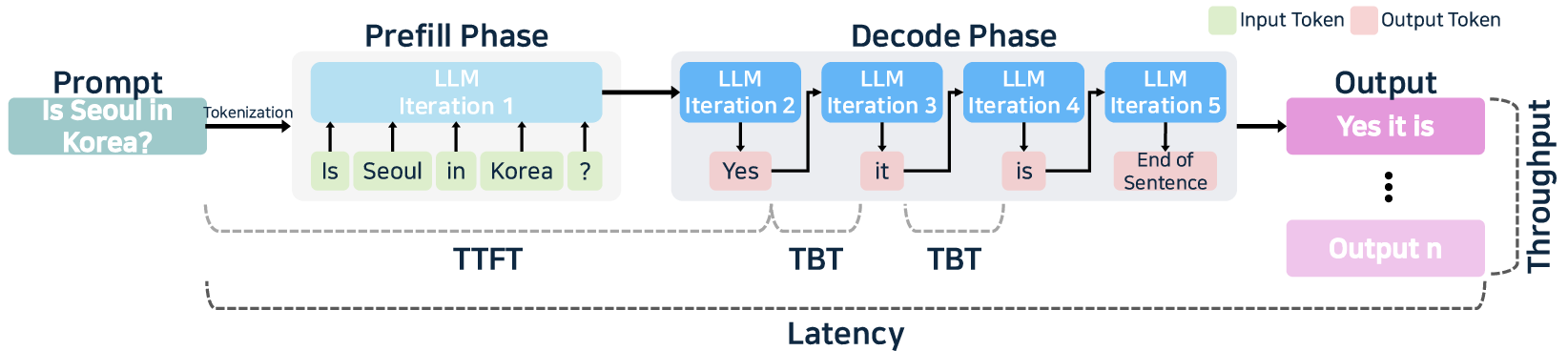
Figure 2: LLM inference system and serving process, highlighting the division between prefill and decode phases, and the modular flow from tokenization through to completion.
Taxonomy and Ecosystem Maturity of LLM Inference Engines
The surveyed inference engines are classified by organizational origin, open/closed-source status, hardware support, and user/developer ecosystem maturity. Notably, the paper avoids the overgeneralization of prior surveys by explicitly mapping optimization coverage to each engine and including recent commercial entrants. Key ecosystem findings include:
- Open-source activity is distributed across academic, startup, and community organizations, with permissive licensing predominating.
- User traction (GitHub stars, daily star growth) is tightly correlated with documentation quality and ease of deployment (Homebrew, pip, Docker, etc.).
- Model and hardware support is highly heterogeneous; some engines (e.g., vLLM [kwon2023efficient], TGI [tgi]) are targeting multi-node, multi-GPU clusters and various accelerators, whereas others (e.g., llama.cpp [llamacpp]) focus on resource-constrained edge devices.
- Commercial offerings (Friendli, Fireworks, GroqCloud, Together Inference) extend cloud-based, horizontally-scalable inference stacks and offer comprehensive model support, fine-grained instance types, and industry certifications.
The taxonomy matrix (Figure below) organizes inference engines by scale (single/multi-node) and device diversity (homogeneous/heterogeneous), providing a framework for mapping service requirements to architectural traits.
Optimization Methodologies: Canonical Techniques and Novel Approaches
A critical contribution of the paper is the cross-sectional synthesis of inference-time optimizations, mapped stepwise through the software/hardware co-design stack.
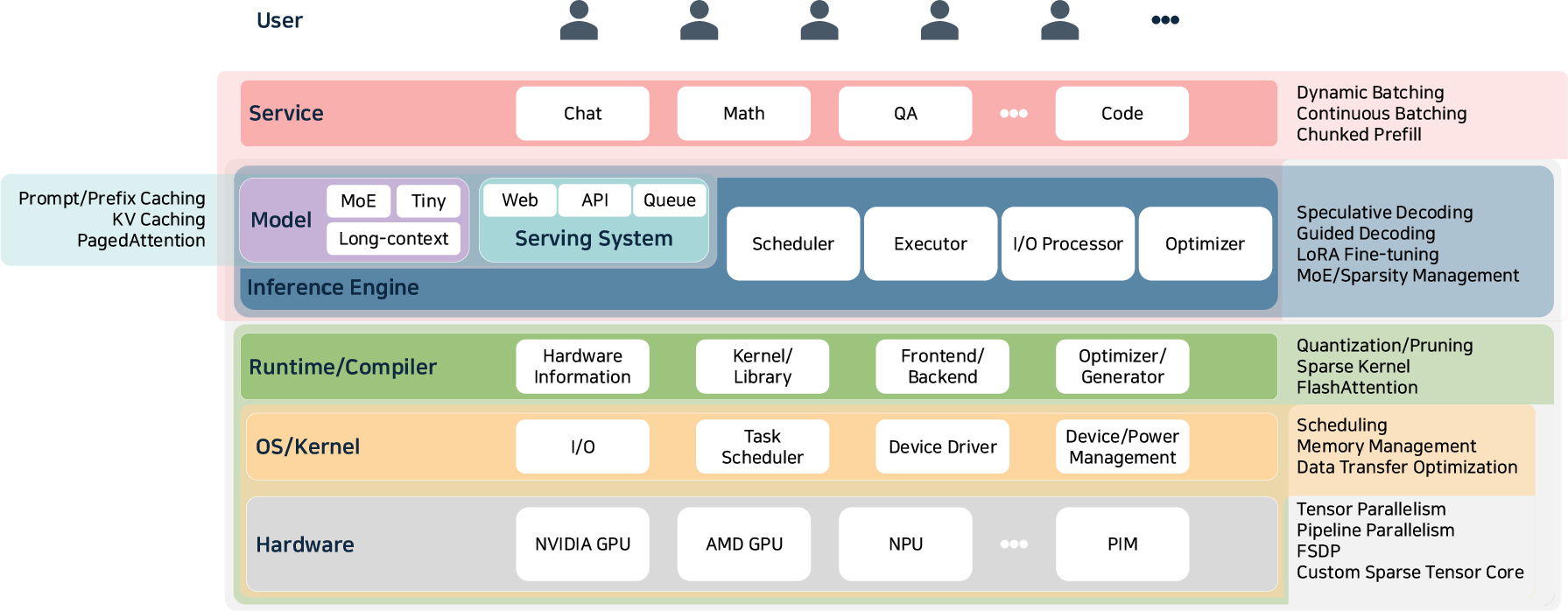
Figure 3: Organizational view of optimization techniques across the full LLM inference stack, from service-level batching down to hardware kernel co-design.
Optimization approaches are rigorously categorized (see also Table~\ref{tab:llm_inference_optimizations} in the paper):
- Batch Optimization: Techniques such as static, dynamic, continuous, and nano-batching maximize hardware utilization. Continuous and nano-batching (NanoFlow [zhu2024nanoflow]) address request-level stragglers and GPU underutilization, but require sophisticated scheduling and memory forecasting.
- Parallelism: Advanced tensor, pipeline, and expert parallelism (notably, MoE-aware) enable the scaling of ultra-large models. DeepSeek-v3 [liu2024deepseek-v3] introduces hierarchical load balancing for expert assignment, and vLLM supports cascade inference for high prefix-reuse workloads.
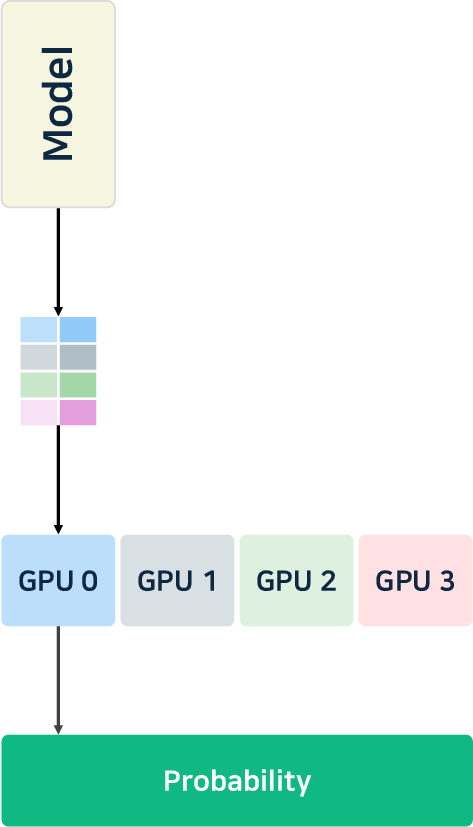
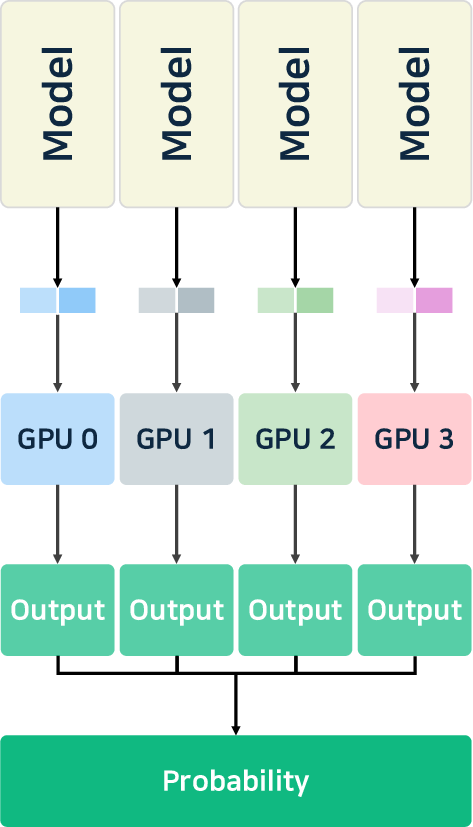
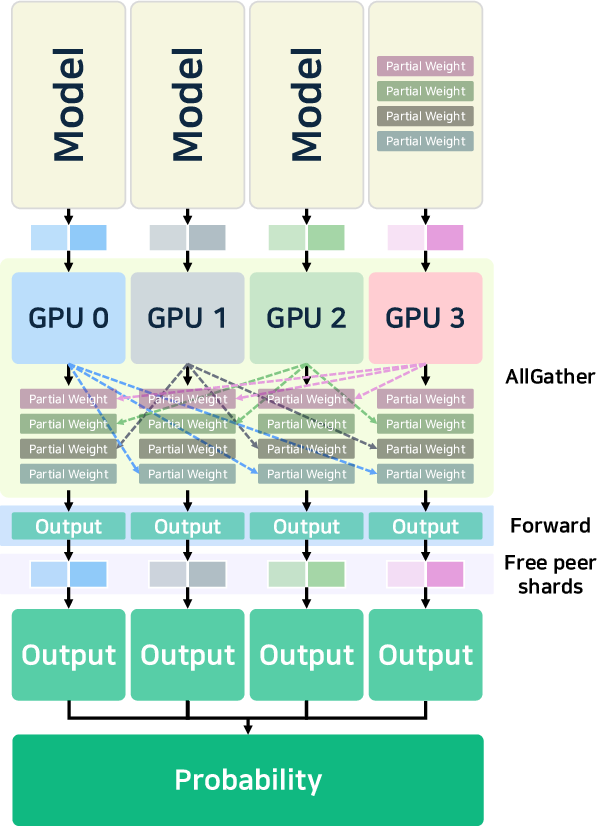
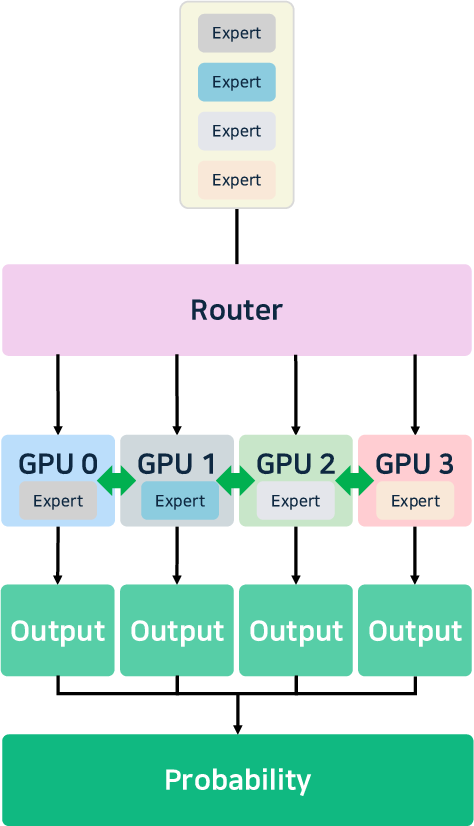
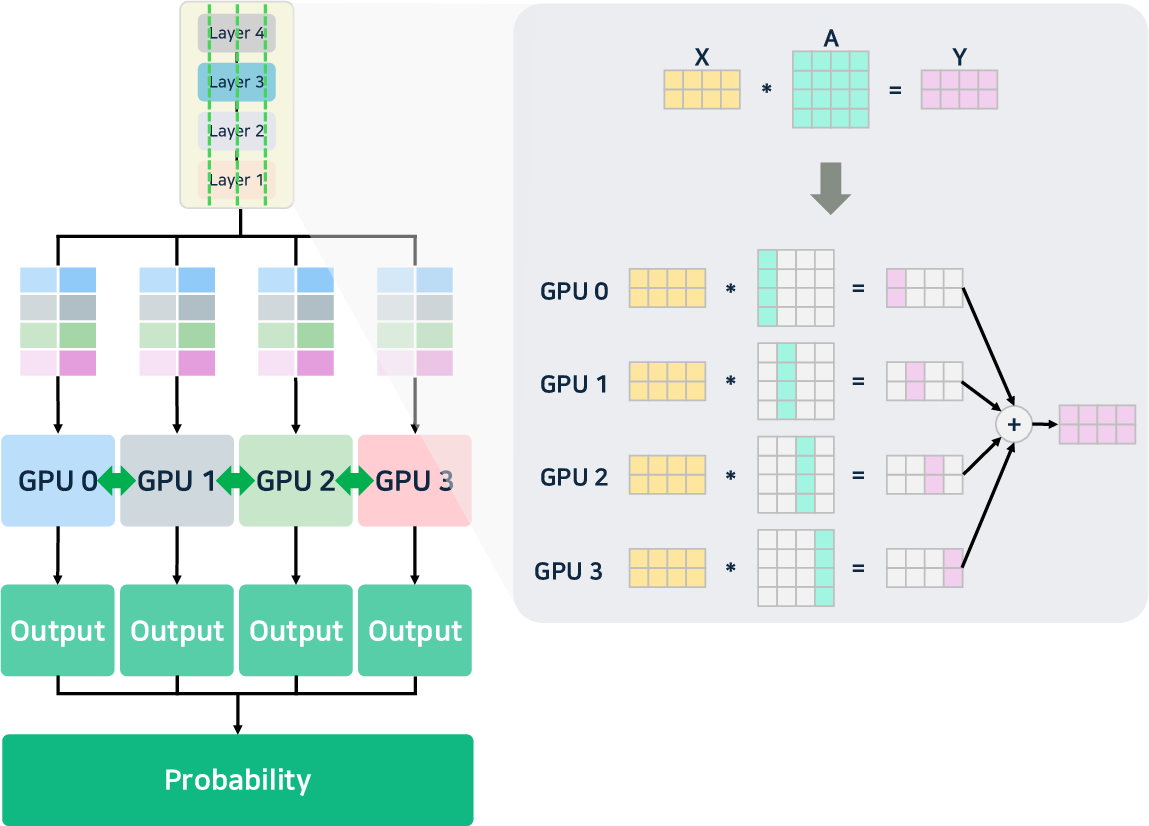
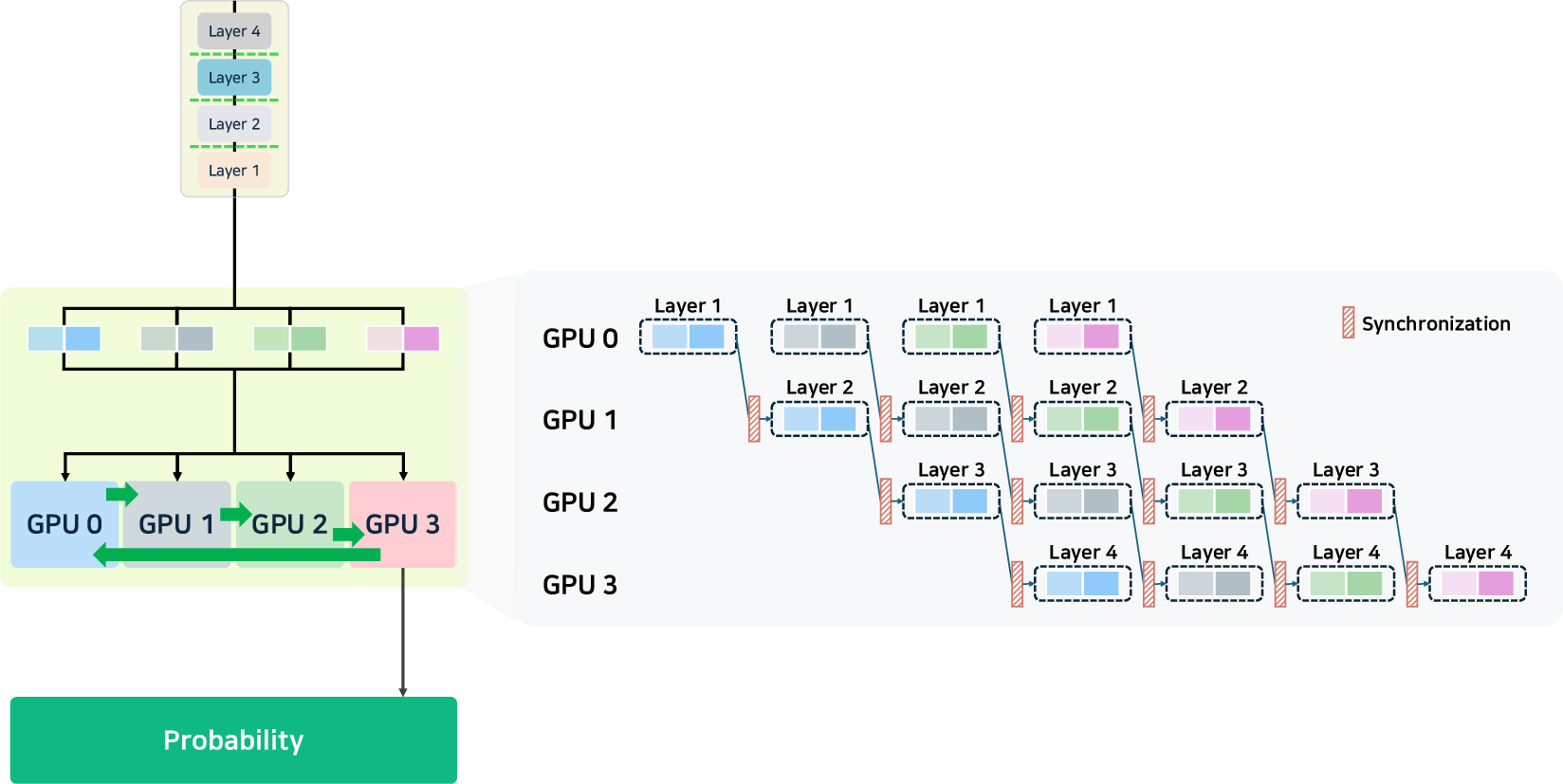
Figure 4: Illustration of pipeline, tensor, and data parallelism strategies for multi-GPU/model distribution.
- Compression: Quantization (e.g., 4-bit, 8-bit, mixed formats), weight pruning, and structured sparsity (N:M) are standard for memory-limited environments. State-of-the-art approaches like GPTQ, SmoothQuant, and Marlin are now tightly integrated in most engines.

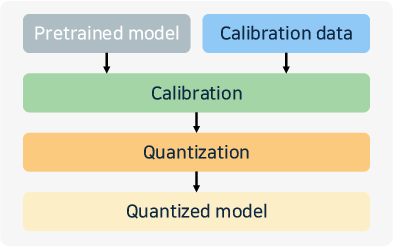
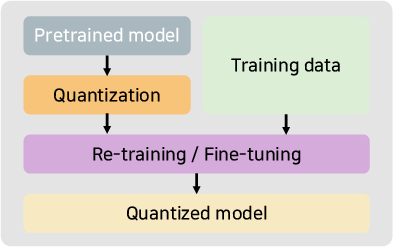
Figure 5: Quantization methods and workflow: PTQ, QAT, AWQ.
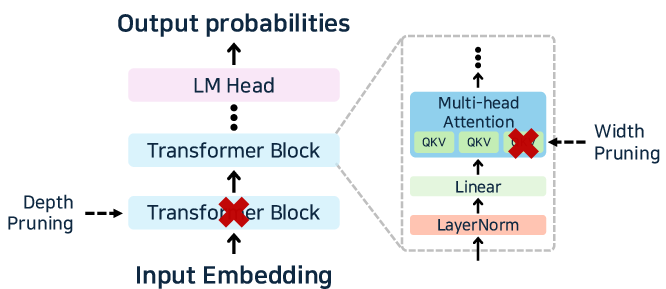
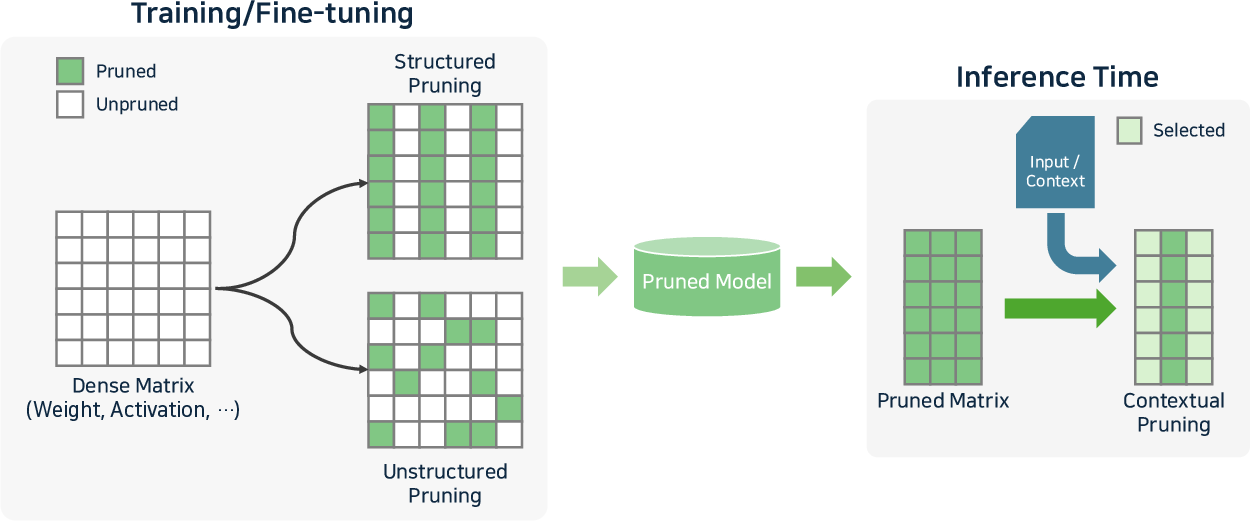
Figure 6: Pruning in transformer-based LLMs, and taxonomy of structured, unstructured, and contextual pruning mechanisms.
- Caching: Prompt, prefix, and KV caching prevent redundant computations, particularly effective in high-context and conversation-based deployments.
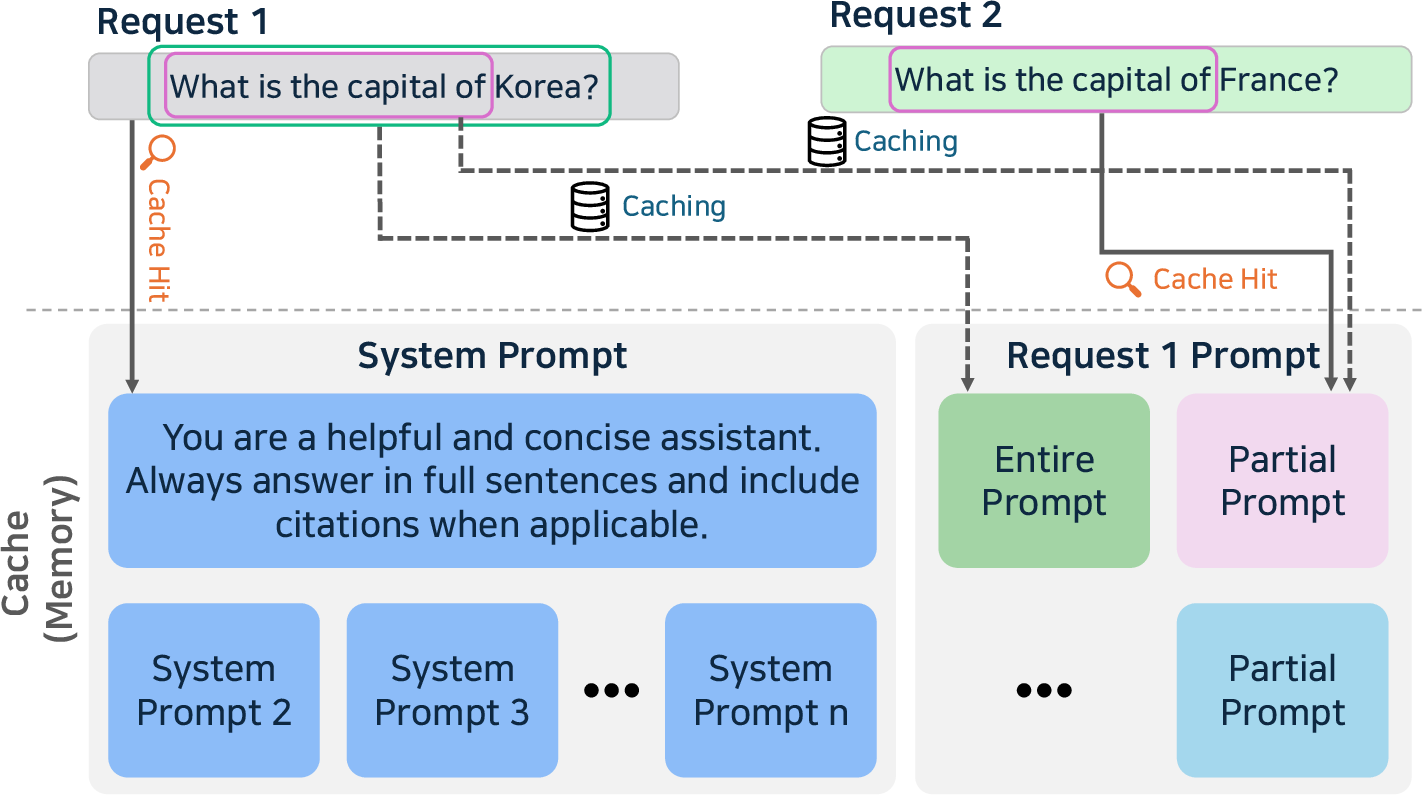
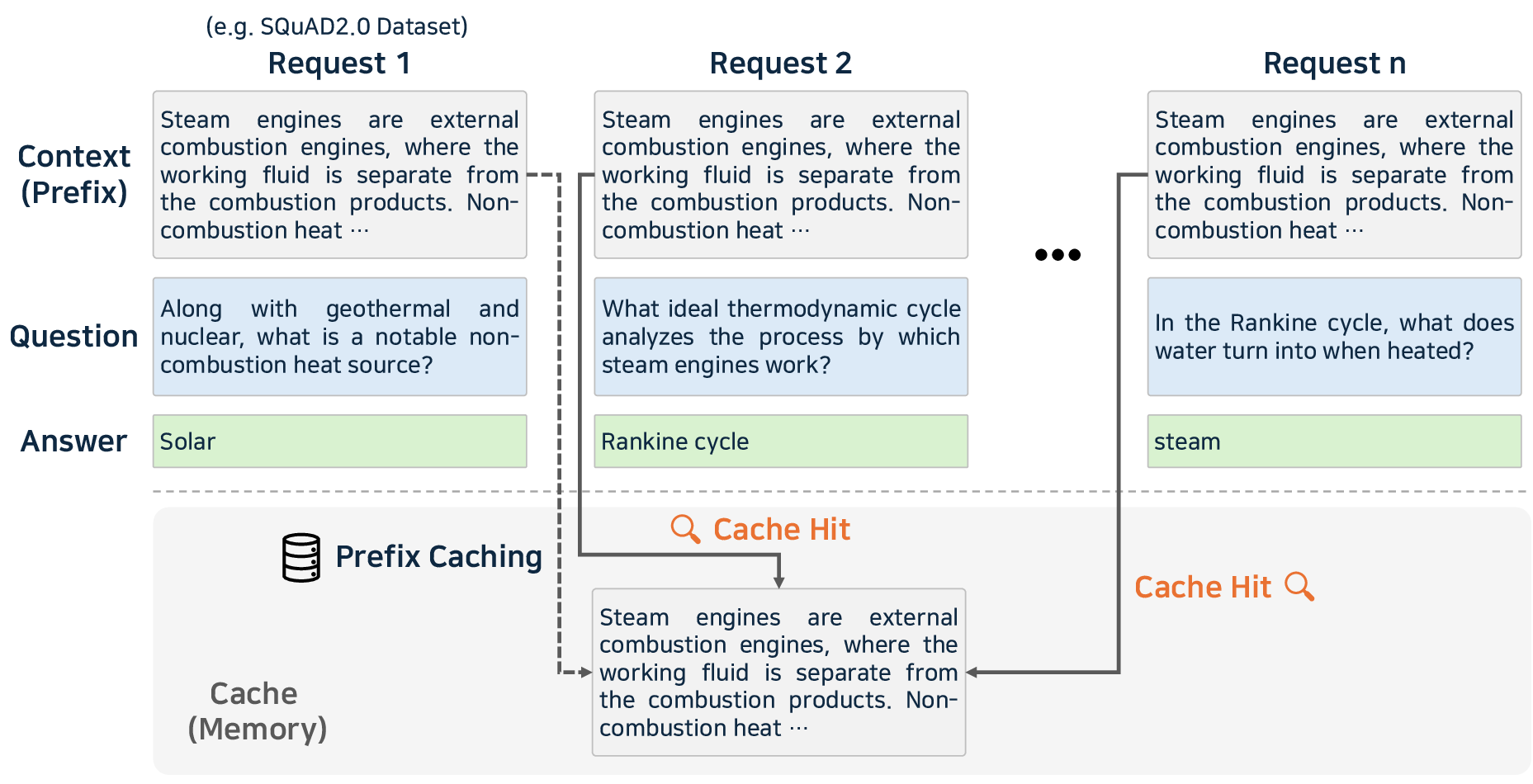
Figure 7: Prompt and prefix caching—reusing precomputed context to accelerate repeat queries and high locality prompt structures.
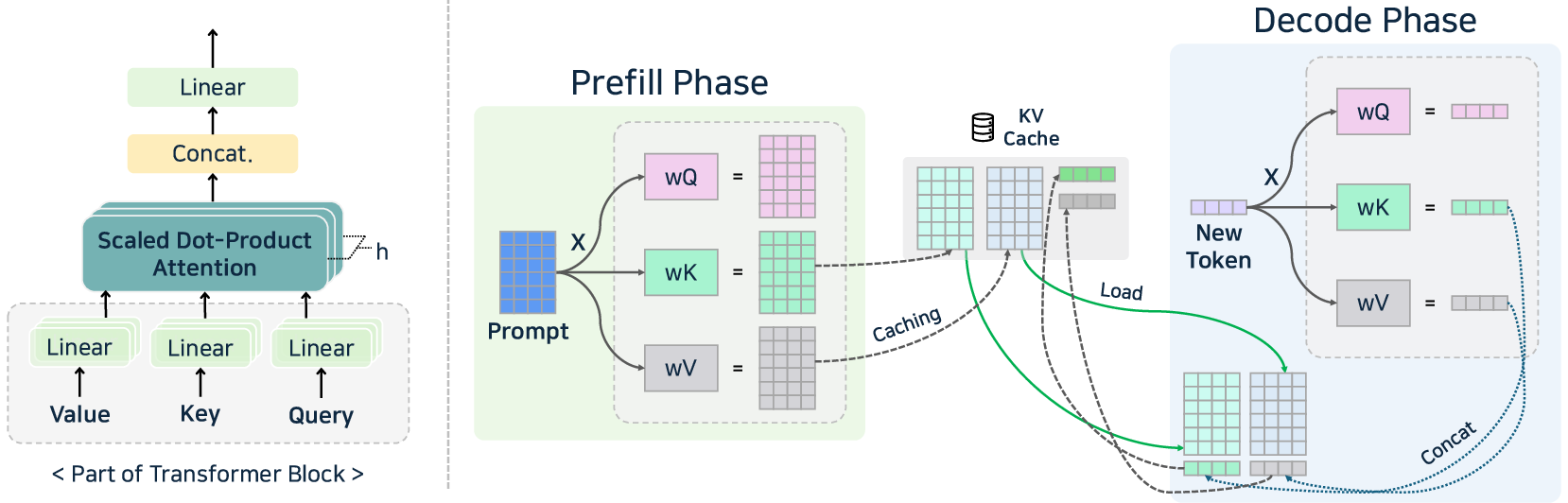
Figure 8: KV caching—reuse of K/V pairs across token generation steps, foundational to contemporary decode optimization.
- Attention Optimization: Memory bottlenecks in attention are addressed with PagedAttention (vLLM), TokenAttention (LightLLM), and fused-kernel approaches like FlashAttention v2/v3.
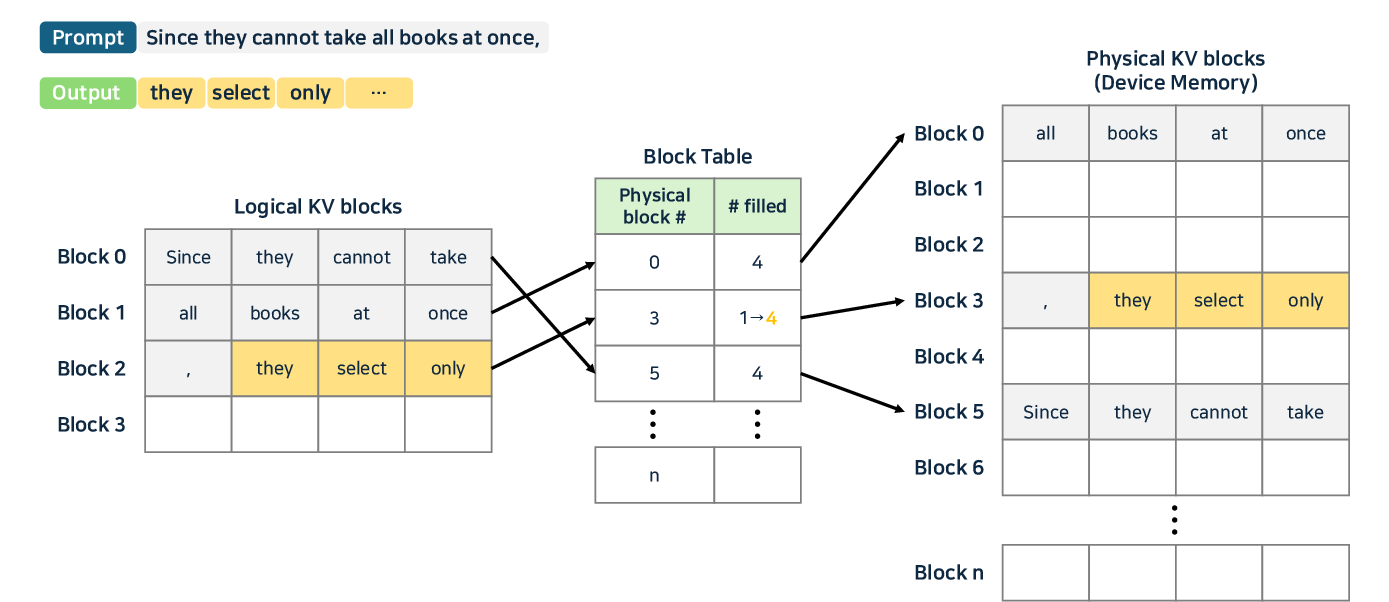
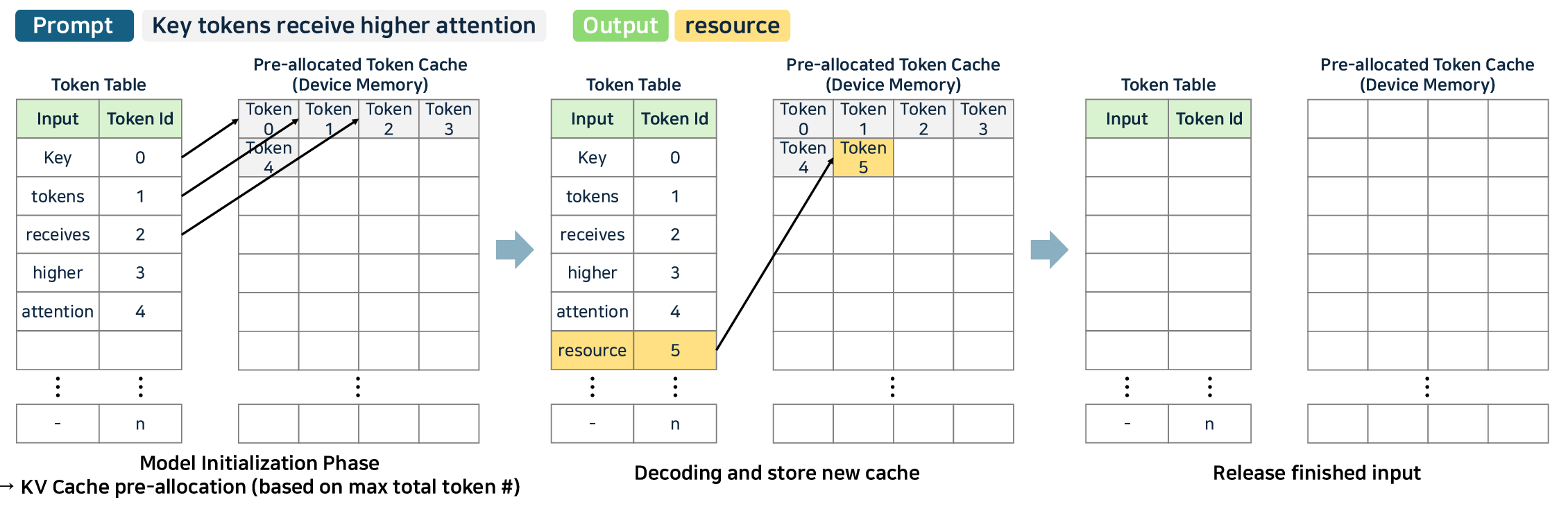
Figure 9: PagedAttention—page-table style memory management for contiguous/noncontiguous KV cache and improved reuse rates.
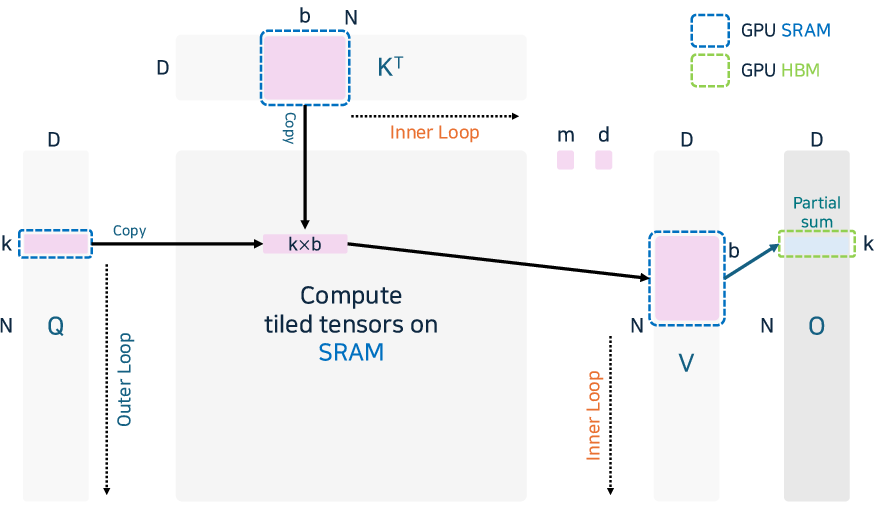
Figure 10: Simple FlashAttention fusion of softmax and GEMM operations, optimizing IO and shared memory usage for deep-sequence inference.
- Sampling Acceleration: Speculative decoding and guided constrained decoding (draft/target models, Medusa/EAGLE) deliver multi-token parallelism in the autoregressive loop and are increasingly vital for sub-second response time constraints.
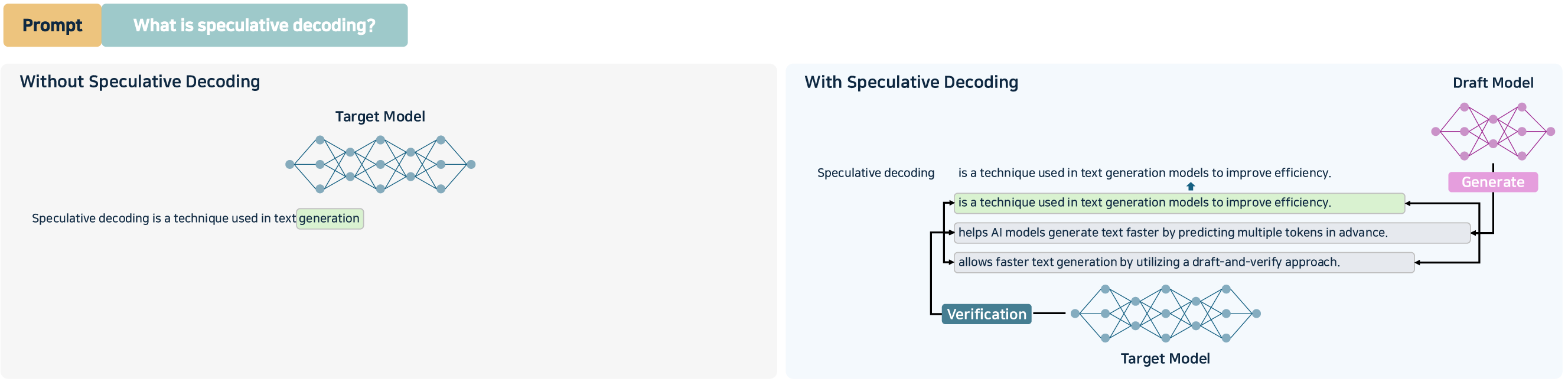
Figure 11: Speculative decoding using draft/target model for parallel token prediction and validation.
- Structured Outputs: FSM/CFG-constrained decoding, with libraries like Outlines and XGrammar, enforce well-formed outputs in code, JSON, or SQL, essential in agent, database, or function calling scenarios.
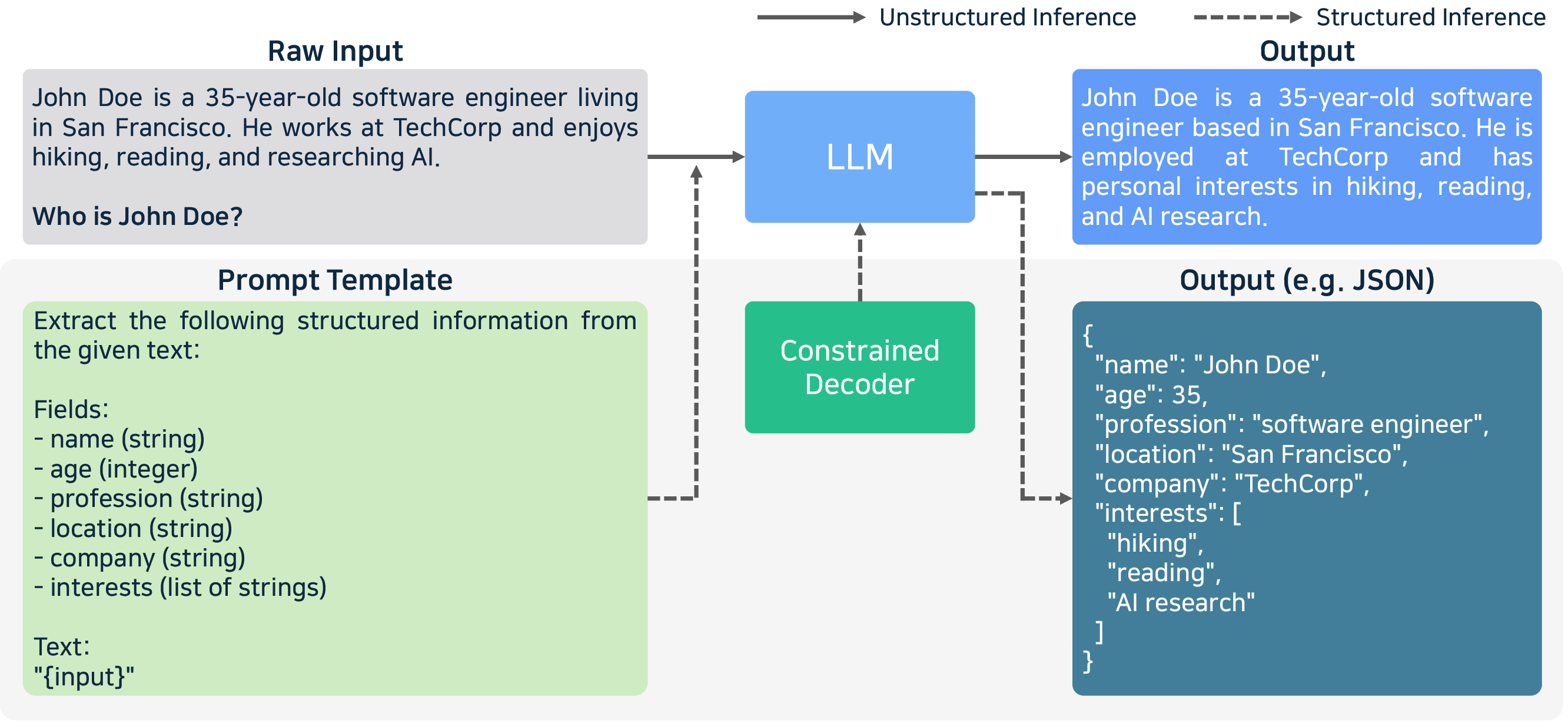
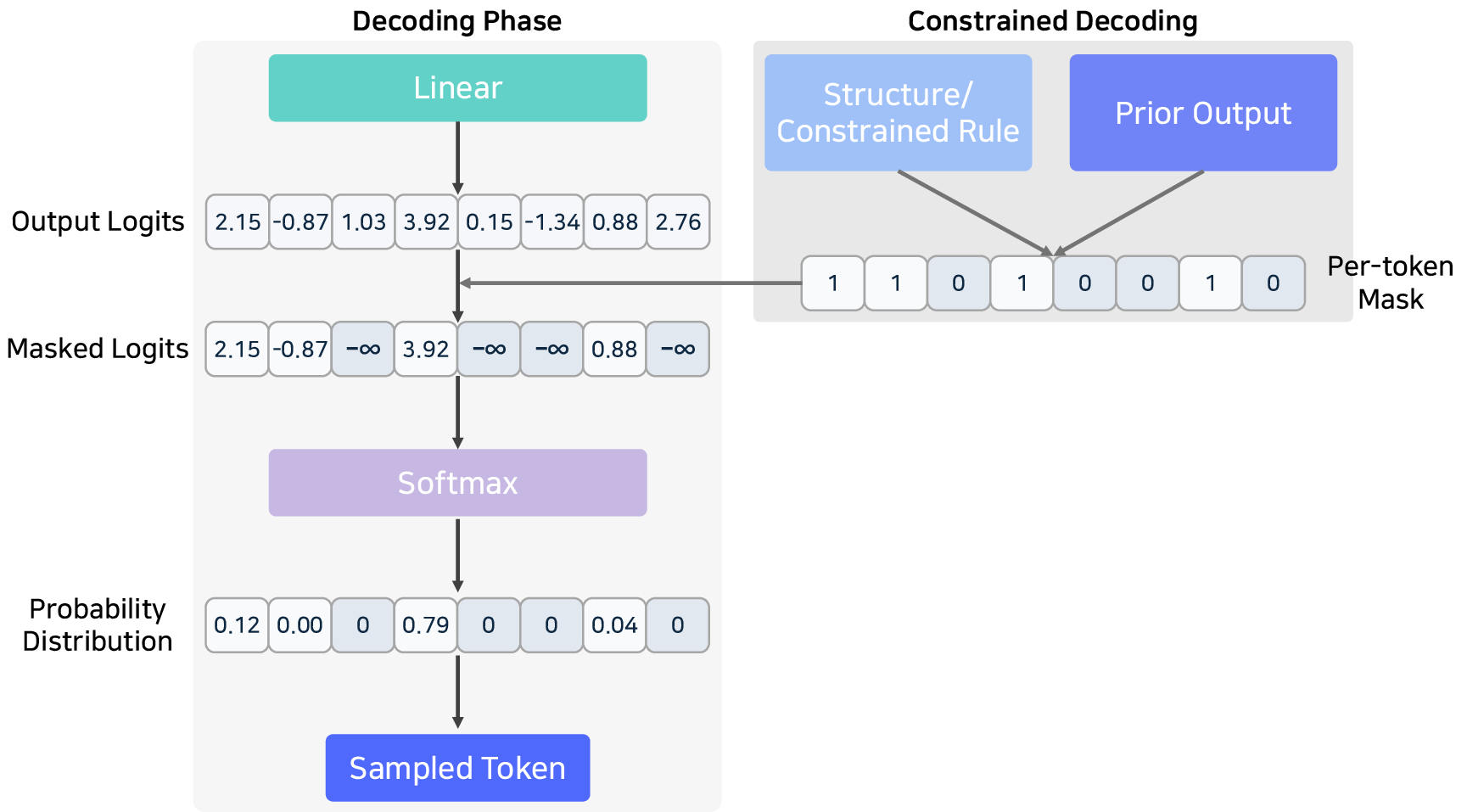
Figure 12: Constrained decoding and schema enforcement in the decoding phase for structured outputs.
The experimental benchmark results, using real-world GuideLLM scenarios across 21 inference engines, highlight several critical patterns:
- Quantized Inference Engines (Ollama, LLaMA.cpp, MLC LLM): Achieve superior throughput on A6000/H100 but exhibit sharp TTFT increases with longer contexts. MLC LLM on H100 achieves minimal TTFT (2,076 ms for 1k-token prompts).
- Full-precision Engines (vLLM, TGI, etc): Dominate throughput and request per second metrics for high-concurrency, high-batch settings, benefiting from mature continuous batching and advanced attention optimizations. vLLM on H100 records >1.2k tokens/sec in optimal conditions.
- Specialized Deployments (PowerInfer, bitnet.cpp, edge devices): Demonstrate the value of sparsity-aware pruning and hot/cold neuron allocation for environments with strict RAM/power limitations.
Throughput sharply increases on H100 relative to A6000, with advanced engines such as TensorRT-LLM exploiting kernel fusion and in-flight batching to reach near-peak hardware saturation.
Theoretical and Practical Implications
The analysis confirms and extends the understanding that LLM inference is no longer simply a matter of maximizing FLOPs; memory, I/O, cache bandwidth, and service-level heterogeneity (multi-turn, multi-model, multi-agent) are the dominant axes for optimization (2505.01658). Key patterns include:
- Optimization strategies are context-dependent:
- Serving workloads (high concurrency, variable prompt length) focus on batching, continuous scheduling, and advanced caching.
- Edge and resource-limited deployments extract maximum efficiency from quantization, distillation, and aggressive pruning.
- Research and experimental engines prioritize extensibility (e.g., SGLang’s programmable LM programs, MLC LLM’s TVM backend) to accommodate new attention variants, decoding policies, and multi-agent extensions.
- Emerging challenges include:
- Efficient long-context processing (>10,000 tokens), where TTFT and KV cache scalability becomes the dominant bottleneck.
- MoE model deployment, demanding load-balancing expert parallelism and all-to-all communication schedules.
- Multi-agent orchestration and memory sharing, particularly as LLM-based agents and tool-use frameworks proliferate.
- Future directions: Anticipate standardized runtime APIs for structured output enforcement, proliferation of hybrid (FP8/NF4/MXINT8) kernels, on-device speculative execution for low-latency edge inference, and system-level co-design for disaggregated (prefill/decode-separated) inference architectures.
Conclusion
This survey (2505.01658) provides an authoritative resource for LLM inference system researchers and practitioners, rigorously mapping the spectrum of optimization techniques, architectural tradeoffs, and deployment considerations in current inference engines. Its comprehensive taxonomy and comparative benchmarks serve as an effective reference for engine selection and future system research. By dissecting the interaction between model architecture, hardware, and deployment pipeline, it frames a clear direction for the continued evolution of scalable, cost-efficient, and robust LLM inference.

