CodeScout: An Effective Recipe for Reinforcement Learning of Code Search Agents
Abstract: A prerequisite for coding agents to perform tasks on large repositories is code localization - the identification of relevant files, classes, and functions to work on. While repository-level code localization has been performed using embedding-based retrieval approaches such as vector search, recent work has focused on developing agents to localize relevant code either as a standalone precursor to or interleaved with performing actual work. Most prior methods on agentic code search equip the agent with complex, specialized tools, such as repository graphs derived from static analysis. In this paper, we demonstrate that, with an effective reinforcement learning recipe, a coding agent equipped with nothing more than a standard Unix terminal can be trained to achieve strong results. Our experiments on three benchmarks (SWE-Bench Verified, Pro, and Lite) reveal that our models consistently achieve superior or competitive performance over 2-18x larger base and post-trained LLMs and sometimes approach performance provided by closed models like Claude Sonnet, even when using specialized scaffolds. Our work particularly focuses on techniques for re-purposing existing coding agent environments for code search, reward design, and RL optimization. We release the resulting model family, CodeScout, along with all our code and data for the community to build upon.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
Imagine you’re handed a giant code project with thousands of files and asked to fix a bug. Before you can fix anything, you first have to find the exact places in the code that matter—like the right files, classes, and functions. This paper is about training an AI helper, called CodeScout, to do that “finding” step really well.
Instead of giving the AI lots of fancy, language-specific tools, the authors show that you can train it to be very good using just a simple command-line terminal (the same kind you use to run basic commands on a computer) and a smart training method called reinforcement learning (RL). They also release their models, code, and data so others can build on their work.
The main questions the paper asks
The authors focus on a few easy-to-understand questions:
- Can an AI learn to locate the right parts of a huge codebase using only a simple terminal (no special tools)?
- Is there a practical RL “recipe” that teaches the AI to search efficiently and stop at the right time with a solid answer?
- Can this simple approach match or beat other systems that rely on complex, language-specific tools?
- Will better “finding” help coding agents fix bugs faster and more accurately later on?
How they trained the AI (explained simply)
To make this understandable, think of RL like training a player in a video game using rewards:
- If the player explores smartly and reaches the goal, they get points.
- If they wander aimlessly or don’t finish on time, they get fewer or no points.
- Over time, the player learns what actions lead to more points.
Here’s what the authors did:
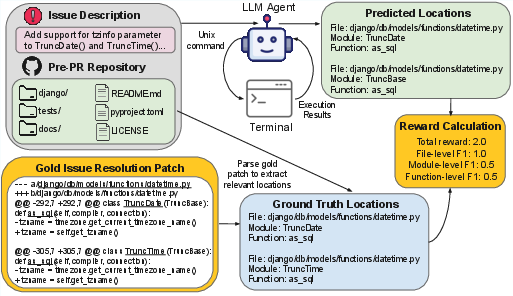
1) Building training examples
They collected real GitHub issues where developers fixed bugs and used the final “fix” (the patch) to create answer keys. For each issue, they recorded:
- Which files were changed,
- Which modules (think: logical parts of the code) were touched,
- Which functions or methods were edited.
These become the “ground truth locations” the AI should find.
2) A simple agent with a terminal
Instead of special tools, the AI uses a standard Unix terminal—just like a programmer would:
- It can search text with tools like “ripgrep” (a super-fast search command),
- View files, list folders, and run basic shell commands,
- When it’s ready, it submits its list of files/modules/functions through a structured “Finish” tool (so its answer is easy to check).
This setup is programming-language agnostic—no complicated parsers or language servers needed.
3) Rewarding good behavior
The AI gets a score based on how well its answer matches the ground truth. The score combines:
- Precision (Are the suggested places actually relevant?),
- Recall (Did it find all the relevant places?),
- And a combined measure called F1 (a simple way to balance both).
The AI also gets a small bonus for finishing within a set number of steps, so it learns not to stall.
4) Training with RL
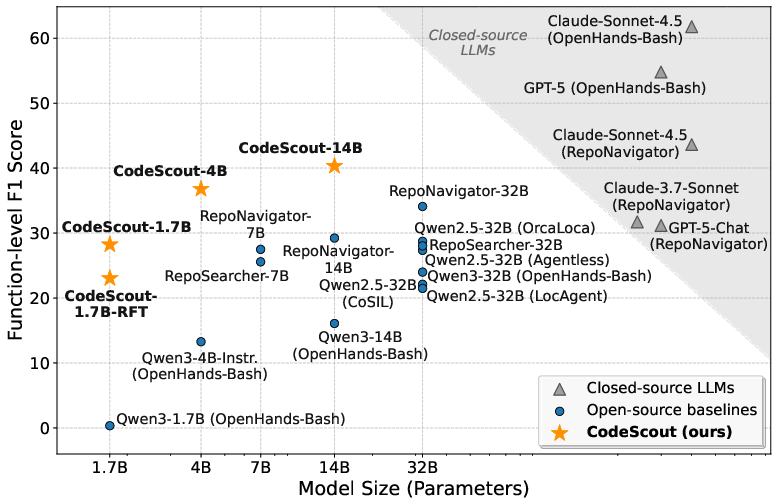
They used a modern RL method (a variant of PPO called GSPO) and an efficient training system so the AI can learn from many “attempts” in parallel. They trained several model sizes (1.7B, 4B, and 14B parameters), and for the smallest one they first “warmed it up” with examples from the bigger model before using RL.
5) Testing on tough benchmarks
They measured performance on three widely used code benchmarks (SWE-Bench Lite, Verified, and Pro), which contain realistic software issues across many repositories.
What they found and why it matters
Here are the key findings, explained in everyday terms:
- A simple toolkit can work surprisingly well: Even with just a terminal and search commands, the AI learned to find the right files/functions impressively well after RL training.
- It beats or matches much larger models: Their mid-sized models (4B and 14B) often outperformed other systems powered by much larger models (8–18 times bigger), including those with special tools and complex setups.
- It closes the gap with top proprietary systems: While the very best closed-source models can still be stronger in some cases, CodeScout often narrows the distance—and sometimes even wins—especially considering it uses a simpler setup.
- It helps with actual bug fixing later: When they fed the found locations into a bug-fixing agent, it improved both success rates and efficiency (fewer steps, fewer tokens used). In other words, better “finding” leads to better “fixing.”
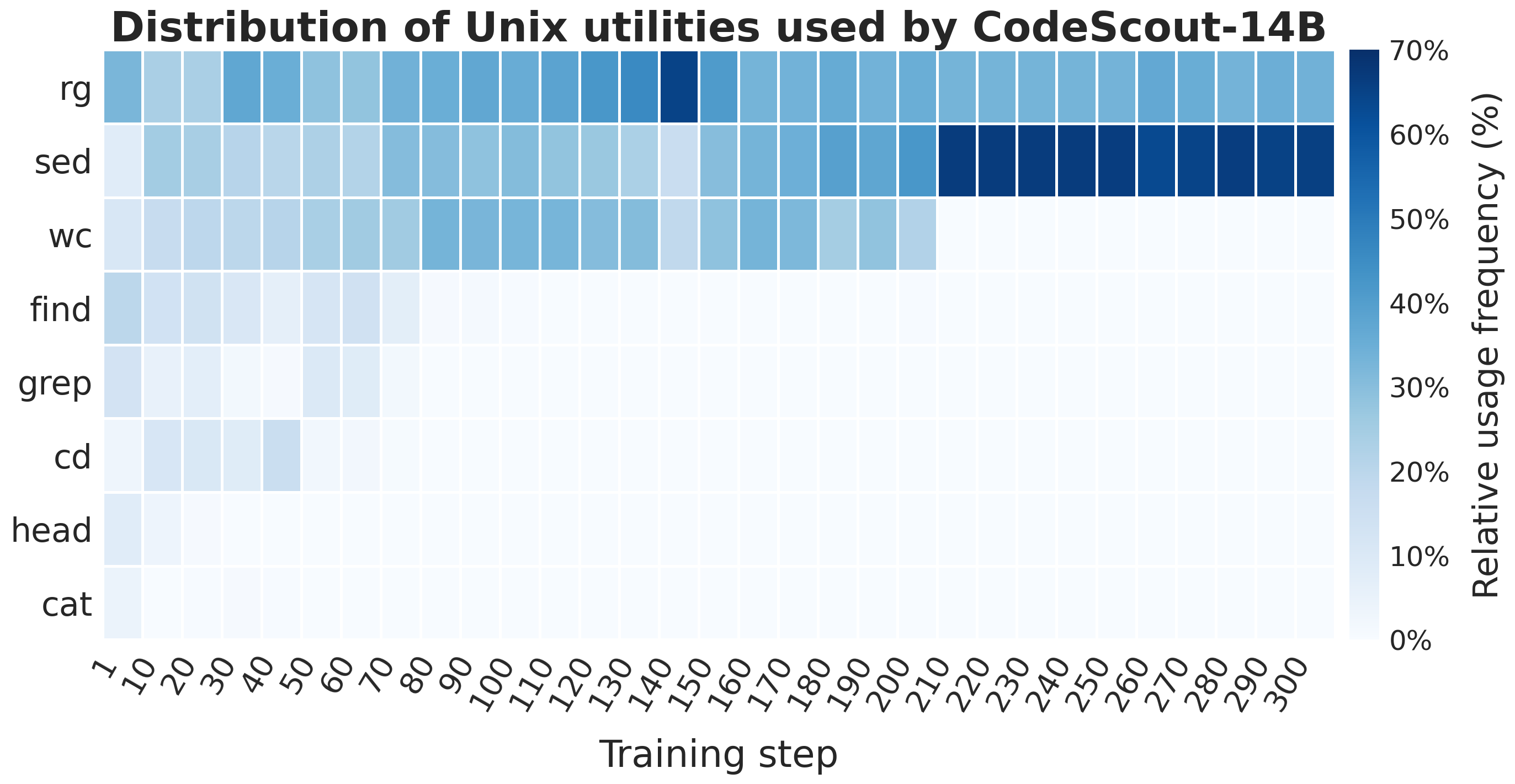
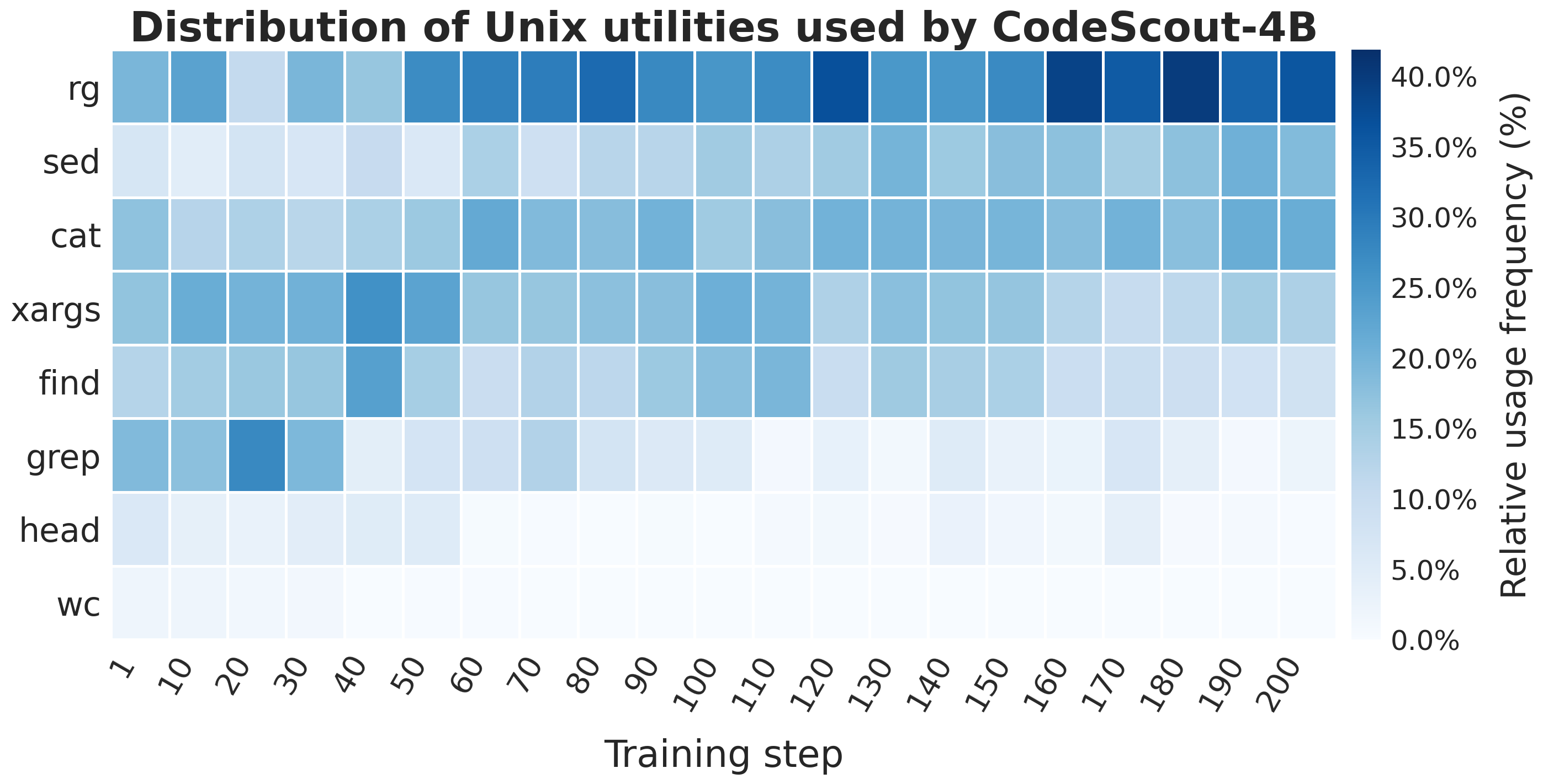
- The AI learned to keep it simple: As training progressed, the model relied on only a few core commands (mostly “ripgrep” and “sed”), suggesting it discovered a clean, efficient search strategy.
- Less engineering, more flexibility: Because there are no language-specific tools (like Python-only parsers), the approach is easier to deploy in different programming languages and across many projects.
Why this is important (the impact)
- Faster development: If an AI can quickly point to the right parts of a huge codebase, human developers and coding agents can fix problems faster and with less guesswork.
- Lower costs: Using smaller models and simple tools cuts compute and engineering overhead.
- Easier to adopt: No need for custom analyzers or code graphs per programming language—just a terminal.
- Strong baseline for the community: The authors released their models, code, and data, making it easy for others to improve, adapt, or apply this in new settings.
Final takeaway
CodeScout shows that you don’t need fancy, language-specific gadgets to teach an AI to find the right places to edit in large code projects. With a well-designed reward system and reinforcement learning, a terminal and good search commands are enough to train a strong, practical code search agent. This makes AI-assisted software development more accessible, efficient, and easier to scale.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored in the paper, phrased to guide concrete follow-up work.
- Language generalization is untested: despite a language-agnostic scaffold, all training/evaluation are on Python repositories; it is unknown how the approach transfers to languages with different module/function constructs (e.g., Java, C/C++, Go, JS/TS).
- Multi-language repositories are out of scope: the method ignores non-Python files in ground truth and does not handle polyglot repos where fixes span code, configs, docs, tests, or build files.
- File creation/deletion tasks are excluded: issues with newly created or deleted files are filtered out; methods to predict or propose new file names/locations remain open.
- Ground-truth extraction reliability is under-examined: module/function-labeling depends on patch parsers adapted from prior work; the error rate and noise in these labels are not quantified, especially for complex edits (e.g., refactors, moved code, nested functions).
- Reward design may bias behavior: summing unweighted F1 scores across file/module/function assumes equal importance; it is unknown if alternative weightings or hierarchical constraints yield better training signals.
- Termination reward may incentivize late finishing: rewarding termination “exactly at the step limit” risks encouraging last-turn submissions rather than early, confident termination; alternative step-penalties or early-finish rewards are unexplored.
- No intermediate/trajectory shaping: the reward is only computed at episode end; credit assignment for useful intermediate actions (e.g., discovering key files) is not leveraged, limiting learning signal density.
- RL stability and reproducibility need study: training collapse was observed and mitigated with a simple auxiliary reward; variance across seeds, sensitivity to hyperparameters, and reproducibility across runs are not reported.
- Effect of removing KL and entropy regularization is unclear: the recipe drops KL and entropy terms; potential overfitting, reward hacking, or degradation of general capabilities is not evaluated.
- Asynchronous training staleness is unablated: the impact of trajectory staleness (t=4) on stability and sample efficiency is not analyzed.
- Parallel tool-calling remains an open optimization problem: auxiliary rewards for parallelization hurt performance; principled approaches to jointly optimize accuracy and wall-clock efficiency are untested.
- Command repertoire collapses to a few utilities (rg/sed): whether reliance on minimal commands harms recall on atypical repo layouts (e.g., generated code, monorepos, non-standard directory structures) is unknown.
- Efficiency and scalability on very large repos are not measured: no analysis of latency, memory, or throughput when ripgrep scans hundreds of thousands of files or multi-GB repositories.
- No environment sandboxing during training: the agent runs shell commands without containerization; risks from destructive or adversarial commands, symlinks, or huge files are not assessed, nor are command whitelists explicitly defined.
- Realism without build/dependency setup is limited: some repos only reveal relevant locations after building or codegen; how to incorporate safe, language-agnostic pre-indexing or read-only build steps is unaddressed.
- Evaluation scope is narrow: results are limited to SWE-Bench (Lite/Verified/Pro); generalization to other public benchmarks or real-world internal repos is untested.
- Baseline comparability remains imperfect: many baselines use fixed top-K predictions; the study argues for variable-K but does not re-run those baselines under a harmonized protocol to isolate methodological factors.
- Sensitivity of closed-source models to prompt engineering complicates comparisons: the need for a “submission reminder” indicates evaluation fragility; more robust, model-agnostic scaffolding and reporting of failure cases are needed.
- Downstream impact on repair is modest and under-explored: augmenting fixers with names of localized entities yields limited gains; richer integration strategies (e.g., auto-including snippets, structured plans, iterative retrieval) remain unexplored.
- Context-window and “thinking” ablations are missing: effects of context length, reasoning mode on/off, and scratchpad preservation on localization quality are not systematically studied.
- Post-RL capability drift is unmeasured: potential degradation or improvement on general coding/Reasoning tasks (e.g., HumanEval, MBPP, general instruction following) after RL is not evaluated.
- Calibration of predicted set size is unstudied: mechanisms to decide how many files/modules/functions to output, and errors from over/under-prediction, are not analyzed; no explicit constraints enforce hierarchical consistency between predicted functions, files, and modules.
- Handling low-information or noisy issues is not addressed: robustness to sparse, ambiguous, or poorly written issue descriptions (or leveraging commit history/linked discussions) remains open.
- Training data bias and coverage are unclear: SWE-Smith-derived instances may skew towards certain project types; the effects of broader or more diverse data (including synthetic edge cases) are not evaluated.
- Compute/cost transparency is limited: training uses 8×H100 with relatively few RL steps, but total tokens/compute are not reported; lighter-weight recipes for smaller labs are not proposed.
- Alternative learning recipes are under-explored: comparisons to other RL (PPO/V-trace), preference optimization, ReST, RFT-only, or hybrid pipelines are limited; the contribution of each design choice (e.g., GSPO vs GRPO) lacks thorough ablation.
- Reward granularity could be finer: the method evaluates at file/module/function only; line-range, class-level, or span-level localization (which may better support downstream edits) is unaddressed.
- Error analysis is missing: there is no breakdown of common failure modes (e.g., confusing test vs source directories, third-party/vendor code, nested packages), limiting targeted improvements.
- Schema standardization is not formalized: while a structured finish tool improved parsing, a shared, language-agnostic schema for localization outputs (and validators) for community benchmarking is not proposed.
Practical Applications
Immediate Applications
The following applications can be deployed now, leveraging the paper’s released models, code, datasets, and the bash-only agent scaffold (OpenHands-Bash + ripgrep) with structured finish tooling and RL reward design.
- Code localization pre-step for coding agents (software)
- Use case: Improve success rate and reduce token/cost for issue-fixing agents by supplying precise files/modules/functions before code edits.
- Tools/products/workflows: Plug-in for OpenHands/SWE-Agent/Claude Code; “localize-then-edit” workflow; microservice/API that returns file/module/function sets from issue text and repo; VS Code/JetBrains extension to prefetch relevant code panes.
- Assumptions/dependencies: Access to repository and issue text; terminal tool (ripgrep) installed; best results in Python repos (training domain), but bash scaffold is language-agnostic; ensure finish tool behavior is handled (e.g., prompt “submission reminder” for some frontier LLMs).
- GitHub/GitLab/Jira triage assistant (software, product management)
- Use case: Automatically comment on issues with likely impacted files/functions to speed up routing and assignment.
- Tools/products/workflows: GitHub Action / GitLab CI job triggered on issue creation; Jira app that annotates tickets with code locations; Slack/Teams notifications for on-call teams.
- Assumptions/dependencies: Repository checkout available on CI runner; permission to read private code; noise control to avoid over-notification.
- Code review context prep (software, QA)
- Use case: Pre-highlight relevant files/functions for reviewers, link to call sites/imports, and reduce context overload.
- Tools/products/workflows: PR bot that posts a “likely impact set” and suggested diffs to inspect; IDE panel showing localized hotspots; integration with review platforms (GitHub PRs, Gerrit).
- Assumptions/dependencies: Works best when PR/issue text describes intent; no static analysis required, but larger diffs may still benefit from supplementary tooling.
- Test selection and CI optimization (DevOps)
- Use case: Use localized file sets to drive test impact analysis, reducing CI time and flakiness from running all tests.
- Tools/products/workflows: CI step that maps predicted files to test suites; selective test execution; caching and sharding based on predictions.
- Assumptions/dependencies: Mapping from files to tests (can be heuristic or historical); ensure recall is adequate for critical paths; fallback to full test runs on low confidence.
- Security incident triage (cybersecurity)
- Use case: Rapidly identify code areas related to a vuln report/CVE to focus SAST/DAST and manual review.
- Tools/products/workflows: SOC playbook step for code impact scoping; bot that links advisories to candidate modules/functions; prioritization queue for rapid remediation.
- Assumptions/dependencies: Issue/vuln description quality; secret code must remain on-prem (prefer on-device inference); may need higher recall in critical incidents.
- Repository onboarding and comprehension (education, software)
- Use case: Guide new contributors to relevant modules/functions for a feature/bug, with minimal setup and no language-specific static analysis.
- Tools/products/workflows: CLI “codescout” that answers “where do I start?”; IDE quick-start panel; courseware labs demonstrating terminal-first navigation on large repos.
- Assumptions/dependencies: Most effective when issues are well-scoped; generalization beyond Python is feasible at inference (bash tools) but accuracy is currently strongest for Python-trained models.
- Developer productivity bots for maintainers (daily life, OSS)
- Use case: For small teams/maintainers, quickly surface likely files to edit, saving time on grep/navigation.
- Tools/products/workflows: Preconfigured GitHub Action for OSS repos; local CLI that suggests locations given an issue text; TUI panel for terminal-centric workflows.
- Assumptions/dependencies: Requires repo clone; ripgrep available; acceptable false-positive rate for small teams.
- Internal compliance and data-residency friendly deployments (policy, enterprise IT)
- Use case: Run localization without shipping code to external services; leverage open models and bash-only tools on-prem.
- Tools/products/workflows: Private vLLM servers; SkyRL-based retraining internally; integration with existing DLP/IR frameworks.
- Assumptions/dependencies: Model licenses compatible with enterprise; GPU availability for local inference; RBAC controls for repo access.
- Research baseline for RL of code agents (academia)
- Use case: Reproducible RL recipe (GSPO, async rollouts, structured finish tool, F1 reward) to study reward shaping, optimization staleness, and agent behavior.
- Tools/products/workflows: SkyRL training runs; ablation on auxiliary termination reward; comparisons with GRPO/DR.GRPO variants; tool-use analyses over time.
- Assumptions/dependencies: Compute availability; adherence to dataset splits to avoid contamination; careful prompt templates for robust finish behavior.
- Cost and latency reduction for code agent platforms (software, finance/ops)
- Use case: Reduce tokens and steps by front-loading localization, as shown by reduced token usage and steps in the paper’s downstream SWE-Bench experiments.
- Tools/products/workflows: Add “localization stage” to pipelines; dynamic budget allocation (more compute for localization, less for generation); monitor precision/recall trade-offs.
- Assumptions/dependencies: Monitor failure modes when localization precision drops; fallback to extra searches when recall is insufficient.
Long-Term Applications
These opportunities are promising but require additional research, scaling, or engineering (e.g., multi-language training data, robust evaluation, enterprise hardening).
- Multi-language, multi-platform repository localization (software, education)
- Use case: Apply the bash-only RL recipe to Java, JS/TS, C/C++, Go, Rust, mobile, and polyglot monorepos without language-specific static analysis.
- Tools/products/workflows: Language-agnostic “localize-then-edit” agents; IDEs with unified localization panels across languages; repository-scale search copilot.
- Assumptions/dependencies: New training data and ground-truth extraction for non-Python ecosystems; evaluation benchmarks beyond SWE-Bench derivatives.
- End-to-end autonomous repair pipelines (software, DevOps)
- Use case: Pair CodeScout with patch-synthesis/repair agents to propose tests + fixes, creating PRs autonomously for routine bugs.
- Tools/products/workflows: CI bots that localize → propose patch → run selective tests → open PR; human-in-the-loop approval flows.
- Assumptions/dependencies: Robust fixers; safety and rollback mechanisms; stronger guarantees on precision to avoid spurious edits.
- Dynamic change-impact and risk analysis for governance (policy, enterprise)
- Use case: Provide change boards and auditors with machine-generated impact maps from issues/requirements to code and dependent modules.
- Tools/products/workflows: Change tickets augmented with risk scores and affected components; dashboards for SOX/ISO/SOC2 evidence trails.
- Assumptions/dependencies: Traceability requirements; integration with SBOMs and dependency metadata; organizational acceptance of ML-derived evidence.
- RL with developer-in-the-loop feedback and federated training (academia, enterprise)
- Use case: Train agents on implicit rewards (PR merged, tests passed) and explicit reviewer feedback; keep data on-prem via federated RL.
- Tools/products/workflows: Feedback capture in code review; advantage shaping from CI outcomes; secure aggregation across teams/orgs.
- Assumptions/dependencies: Privacy constraints; careful reward design to prevent shortcutting or reward hacking; infra for safe, asynchronous RL.
- Security incident response automation (cybersecurity)
- Use case: From CVE/advisory to localized code, candidate patches, and backport suggestions across product lines and forks.
- Tools/products/workflows: IR pipelines that localize → generate patch candidates → run targeted tests and SCA checks → stage hotfix PRs.
- Assumptions/dependencies: High-stakes precision; model robustness under adversarial input; policy controls for emergency changes.
- Enterprise-scale repository intelligence and architecture discovery (software, data/knowledge graphs)
- Use case: Aggregate agent navigation logs into dynamic code maps to visualize coupling, hotspots, and ownership; guide refactors.
- Tools/products/workflows: Code knowledge graphs; observability dashboards that track “where agents look” vs “where bugs are fixed.”
- Assumptions/dependencies: Storage and anonymization of navigation traces; organizational buy-in; bias mitigation (agents may overuse grep-heavy patterns).
- Pedagogy and curricula for agentic code navigation (education)
- Use case: Teach practical, tool-centric repo comprehension; compare classical static analysis vs learned terminal behaviors.
- Tools/products/workflows: Course modules and competitions using CodeScout environments; notebooks showing reward shaping and tool-use evolution.
- Assumptions/dependencies: Compute for students; carefully curated repos and tasks; fairness in evaluation.
- Standardization and safety guidelines for agentic tooling (policy)
- Use case: Define best practices for audit logs, reproducibility, sandboxing, and permissions for terminal-equipped agents in enterprises.
- Tools/products/workflows: Reference policies for agent tool access; reproducible run manifests; red-team evaluations of command safety.
- Assumptions/dependencies: Cross-industry collaboration; balancing productivity with least-privilege access.
- Alternatives to heavy static analysis in niche languages/DSLs (software, robotics, embedded)
- Use case: Where parsers/language servers are immature, learned bash-based localization offers a low-overhead path to productivity.
- Tools/products/workflows: Lightweight agents attached to firmware/robotics codebases; terminal-first exploration workflows.
- Assumptions/dependencies: Need domain-specific training data; careful evaluation where build/execution isn’t feasible or safe.
- Organization-wide cost and energy optimization (finance, sustainability)
- Use case: At scale, localization-first workflows reduce tokens and steps across thousands of tickets, lowering cloud spend and energy.
- Tools/products/workflows: FinOps dashboards tracking token/step savings; policy to mandate localization stage for large repos.
- Assumptions/dependencies: Accurate cost attribution; monitoring to prevent regressions when localization confidence is low.
Glossary
- AdamW: A weight-decay variant of the Adam optimizer commonly used for training deep learning models. "the AdamW optimizer"
- advantage: In policy-gradient RL, the advantage estimates how much better an action is than a baseline for a given state. " is the advantage, and is the clipping parameter:"
- agent scaffold: The minimal set of tools and interaction protocol an agent uses to operate in an environment. "an agent scaffold that relies solely on a standard bash terminal"
- agentic code search: An approach where an agent iteratively navigates a repository to gather evidence and identify relevant code. "agentic code search - using agents to iteratively navigate the repository"
- agentic coding loop: The iterative process where an agent plans, acts (e.g., explores code), and revises its approach while attempting a software task. "agentic coding loop"
- AST (Abstract Syntax Tree): A structured representation of source code used in static analysis and tooling. "AST-based parsers"
- asynchronous training: A training setup where rollout generation and optimization proceed in parallel with potentially stale policies to improve throughput. "supports asynchronous training"
- auxiliary binary reward: An additional reward signal (0/1) used to encourage specific behaviors (e.g., timely termination). "we use an auxiliary binary reward"
- bash terminal: A Unix shell interface used by the agent to run command-line tools for searching and inspecting code. "a standard bash terminal"
- call graph: A directed graph capturing calling relationships between functions or modules. "function-call graphs"
- closed-source LLMs: Proprietary LLMs that are not publicly released for inspection or modification. "closed-source LLMs via rejection sampling fine-tuning"
- cosine learning rate scheduler: A schedule that decays the learning rate following a cosine curve, often used to stabilize training. "a cosine learning rate scheduler"
- DR. GRPO: A training recipe variant related to GRPO that removes certain regularizers and variance terms during optimization. "DR. GRPO"
- entropy loss: A term that encourages exploration by penalizing low-entropy (over-confident) policies; sometimes disabled for stability. "We also disable entropy loss"
- F1 score: The harmonic mean of precision and recall, used to assess prediction quality. "F1 score"
- GRPO: A group-based policy optimization method for RL fine-tuning of LLMs. "trained with GRPO/GSPO"
- GSPO (Group Sequence Policy Optimization): A sequence-level, group-based policy optimization algorithm for RL training of LLMs. "Group Sequence Policy Optimization (GSPO)"
- importance ratio: The likelihood ratio between current and previous policies used for off-policy correction in RL. "importance ratio derived from sequence likelihood"
- KL regularization: A regularizer that penalizes divergence from a reference policy to stabilize RL fine-tuning. "remove the KL regularization term"
- language-agnostic: Not tied to a specific programming language; applicable across multiple languages. "programming language-agnostic by design."
- language server: A tooling component that provides code intelligence (e.g., definitions, references) for a language. "a Python language server"
- LocalizationFinish tool: A specialized tool/action the agent uses to submit its final set of predicted code locations. "LocalizationFinish tool"
- maximum staleness: The cap on how many optimization steps an actor’s policy can lag behind the learner in asynchronous RL. "maximum staleness (set to 4 in our experiments)"
- mini SWE-Agent: A lightweight agent framework used in software engineering tasks and benchmarks. "mini SWE-Agent"
- OpenHands Software Agent SDK: A modular framework for building and evaluating software engineering agents with tool support. "OpenHands Software Agent SDK"
- OpenHands-Bash: The bash-only agent scaffold built on OpenHands used in this work for code localization. "OpenHands-Bash"
- OpenHands-Versa: An agent framework variant discussed in prior work on multi-modal browsing and coding tasks. "OpenHands-Versa"
- parallel tool-calling: Executing multiple tool invocations concurrently to speed up evidence gathering. "parallel tool-calling"
- rejection sampling fine-tuning (RFT): An SFT strategy that trains on high-quality trajectories filtered by a reward or success criterion. "rejection sampling fine-tuning (RFT)"
- reinforcement learning: A learning paradigm where a policy is optimized to maximize rewards through interaction with an environment. "reinforcement learning"
- repository graph: A graph representation of a codebase encoding relationships (e.g., imports, calls) across files and modules. "repository graph navigation"
- ripgrep: A fast command-line recursive search tool (rg) used for codebase search with regex. "ripgrep"
- sandboxing/containerization: Isolating code execution in a restricted environment for safety and reproducibility. "sandboxing/containerization"
- sequence extension property: A property ensuring previous steps are strict prefixes of future trajectories, aiding efficient sequence training. "sequence extension property"
- SkyRL: A modular RL framework for training LLMs with support for asynchronous rollouts and optimization. "SkyRL"
- static analysis: Code analysis performed without executing the program, often using parsers and graphs. "static analysis"
- stale checkpoints: Slightly outdated model parameters used for rollout generation in asynchronous training. "slightly stale checkpoints"
- structured output schema: A constrained output format that simplifies parsing and validation of model predictions. "structured output schema"
- SWE-Bench Lite: A dataset/benchmark variant for software engineering tasks focusing on simplified setups. "SWE-Bench Lite"
- SWE-Bench Pro: A more challenging benchmark subset targeting advanced software engineering scenarios. "SWE-Bench Pro"
- SWE-Bench Verified: A curated benchmark split with verified issues for reliable evaluation. "SWE-Bench Verified"
- SWE-grep: An industry-reported method emphasizing search-first workflows for software agents. "SWE-grep"
- vLLM: A high-throughput inference engine for serving LLMs efficiently. "vLLM"
- vector databases: Datastores optimized for similarity search over embeddings, used for semantic code retrieval. "vector databases"
- YaRN: A method for extending LLM context windows efficiently during inference/training. "YaRN"
Collections
Sign up for free to add this paper to one or more collections.

