SWE-fficiency: Can Language Models Optimize Real-World Repositories on Real Workloads?
Abstract: Optimizing the performance of large-scale software repositories demands expertise in code reasoning and software engineering (SWE) to reduce runtime while preserving program correctness. However, most benchmarks emphasize what to fix rather than how to fix code. We introduce SWE-fficiency, a benchmark for evaluating repository-level performance optimization on real workloads. Our suite contains 498 tasks across nine widely used data-science, machine-learning, and HPC repositories (e.g., numpy, pandas, scipy): given a complete codebase and a slow workload, an agent must investigate code semantics, localize bottlenecks and relevant tests, and produce a patch that matches or exceeds expert speedup while passing the same unit tests. To enable this how-to-fix evaluation, our automated pipeline scrapes GitHub pull requests for performance-improving edits, combining keyword filtering, static analysis, coverage tooling, and execution validation to both confirm expert speedup baselines and identify relevant repository unit tests. Empirical evaluation of state-of-the-art agents reveals significant underperformance. On average, agents achieve less than 0.15x the expert speedup: agents struggle in localizing optimization opportunities, reasoning about execution across functions, and maintaining correctness in proposed edits. We release the benchmark and accompanying data pipeline to facilitate research on automated performance engineering and long-horizon software reasoning.
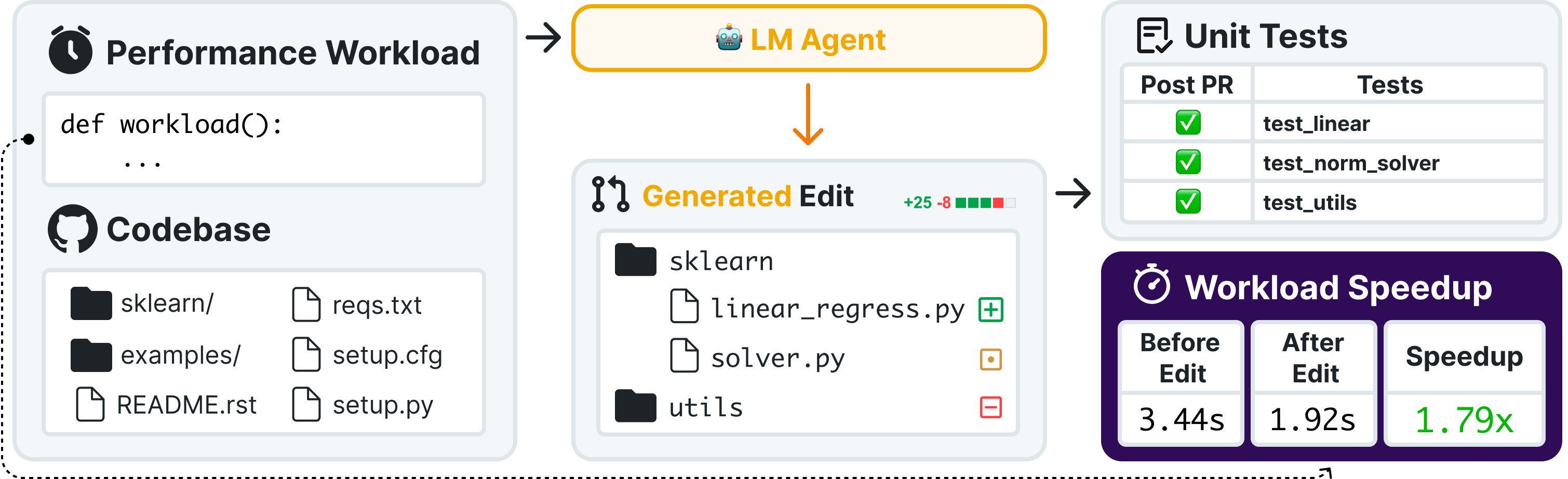

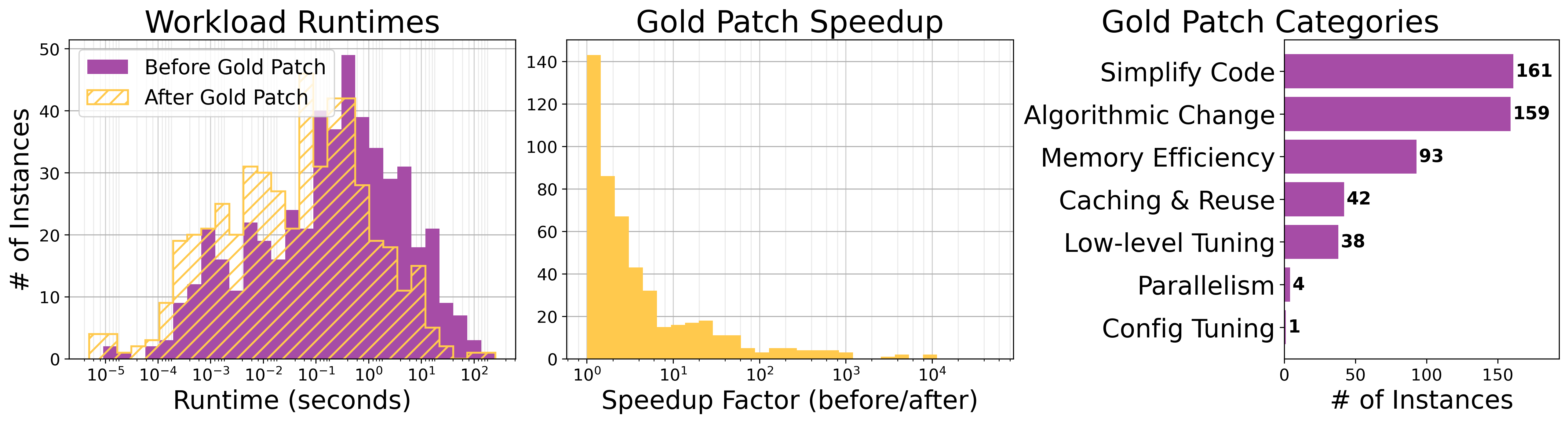
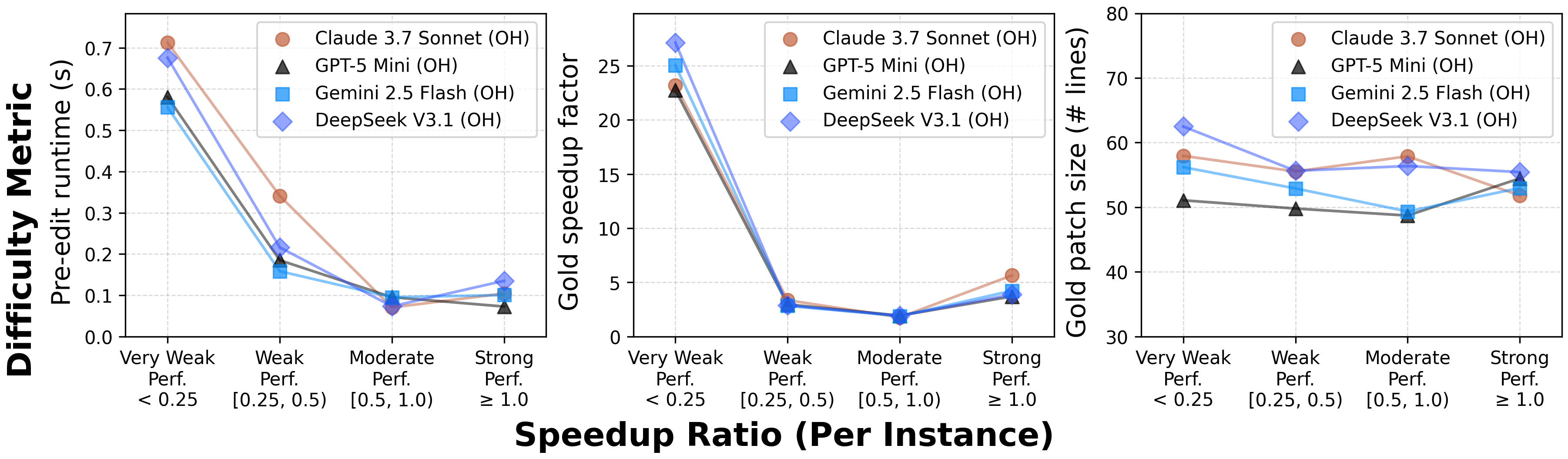
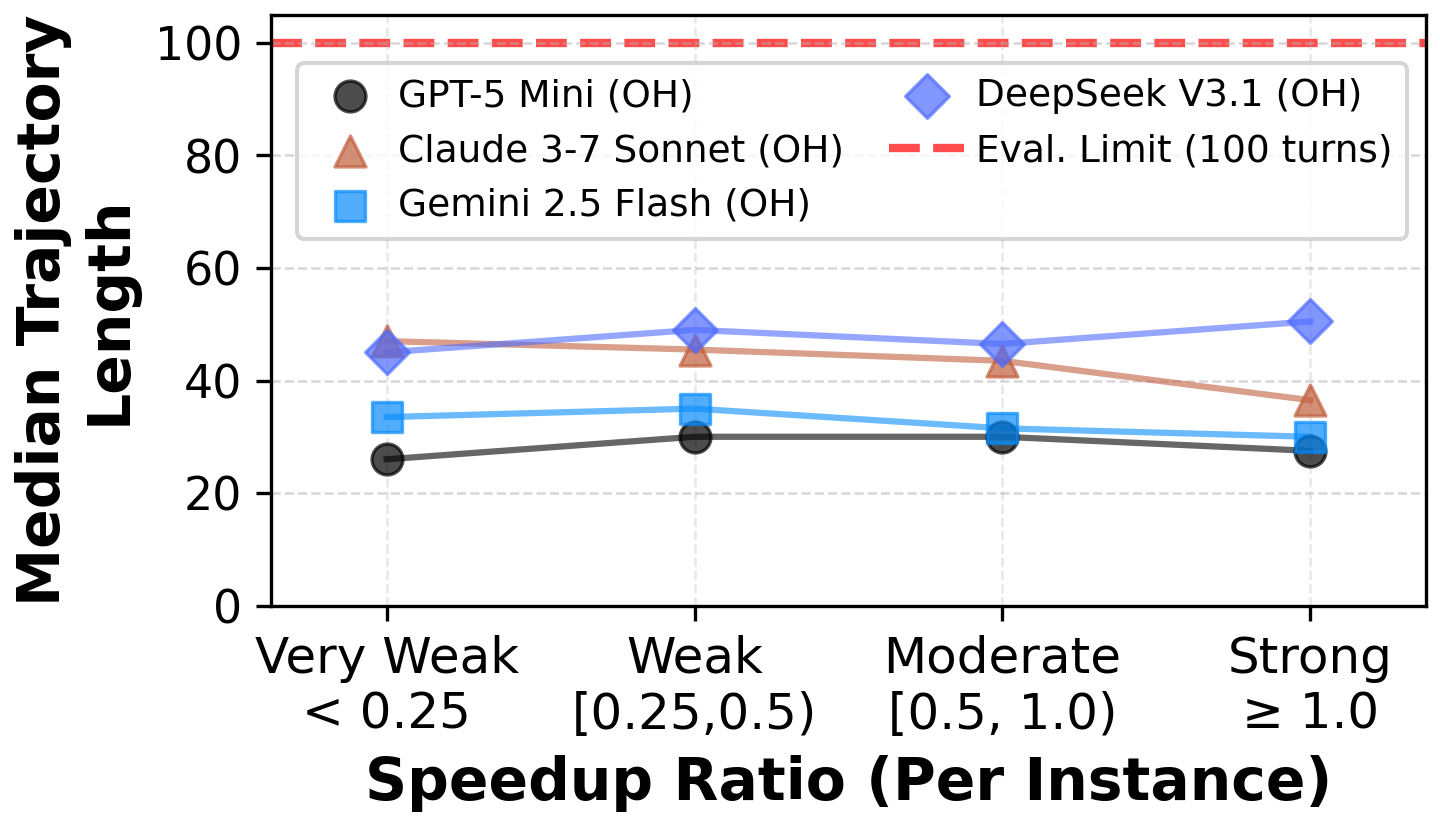
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces SWE-fficiency, a big test (called a benchmark) that checks whether AI coding assistants (LLMs) can make real software run faster without breaking anything. Instead of fixing bugs, the challenge is to take a complete codebase (like NumPy or pandas), a slow “workload” (a script that uses the code in a realistic way), and then change the code so the workload runs faster while all the project’s tests still pass.
What questions did the researchers ask?
- Can AI agents find and fix slow parts of real software projects, not just small code snippets?
- Can they improve speed while keeping the software correct (no new bugs)?
- How close can AI get to expert human performance on speed improvements?
- What kinds of mistakes do AI agents make when trying to optimize code?
How did they do the study?
Think of a software repository as a giant toolbox, and a “workload” as a practical activity that uses that toolbox (like processing a big dataset). The researchers built tasks where an AI gets the whole toolbox plus a slow activity, and must change the toolbox to make the activity faster—without breaking any rules (unit tests).
Building the benchmark
They created 498 optimization tasks from 9 popular Python libraries (like NumPy, pandas, SciPy). Each task is based on a real GitHub pull request (PR) where a human expert made the code faster. To build reliable tasks, they used five steps:
- Choose popular, performance-sensitive repos: Pick widely used libraries where speed matters.
- Filter for true performance changes: Keep PRs that mention speed/specific performance words and that don’t change tests (to avoid “new behavior” pretending to be speed).
- Find tests that cover the changed code: Ensure the repo’s existing unit tests actually touch the edited lines, so correctness can be verified.
- Write a clear performance workload: Create a script that shows the real speedup before vs. after the expert’s change.
- Run everything in controlled containers: Make sure results are reproducible and speedups are real, not random noise.
How performance is measured
They compare an AI’s speedup to the human expert’s speedup using “speedup ratio” ():
- Example: If the expert made the workload 5× faster and the AI made it 1.2× faster, then .
This metric:
- Rewards matching or beating experts (above 1× is superhuman).
- Avoids “all-or-nothing” scores and gives room to compare progress over time.
How models were tested
- Agents (AI coding assistants) were given full codebases and tools to edit files and run commands.
- Everything ran inside containers on pinned CPUs for fair comparisons.
- They tested multiple top models and agent frameworks.
- Each task allowed multiple steps (like editing, running, profiling), but the agent submits one final patch.
What did they find?
- AI agents are far from expert speedups: The best models reached at most 0.15× of the expert’s improvement on average. Many were below 0.1×.
- They often break correctness: A noticeable share of AI patches make unit tests fail, which cancels any speed gain.
- Good at “easy wins,” weak on harder cases: AI can handle small shortcuts (like simple fast paths), but struggles on longer-running workloads and bigger opportunities that need deeper algorithm changes.
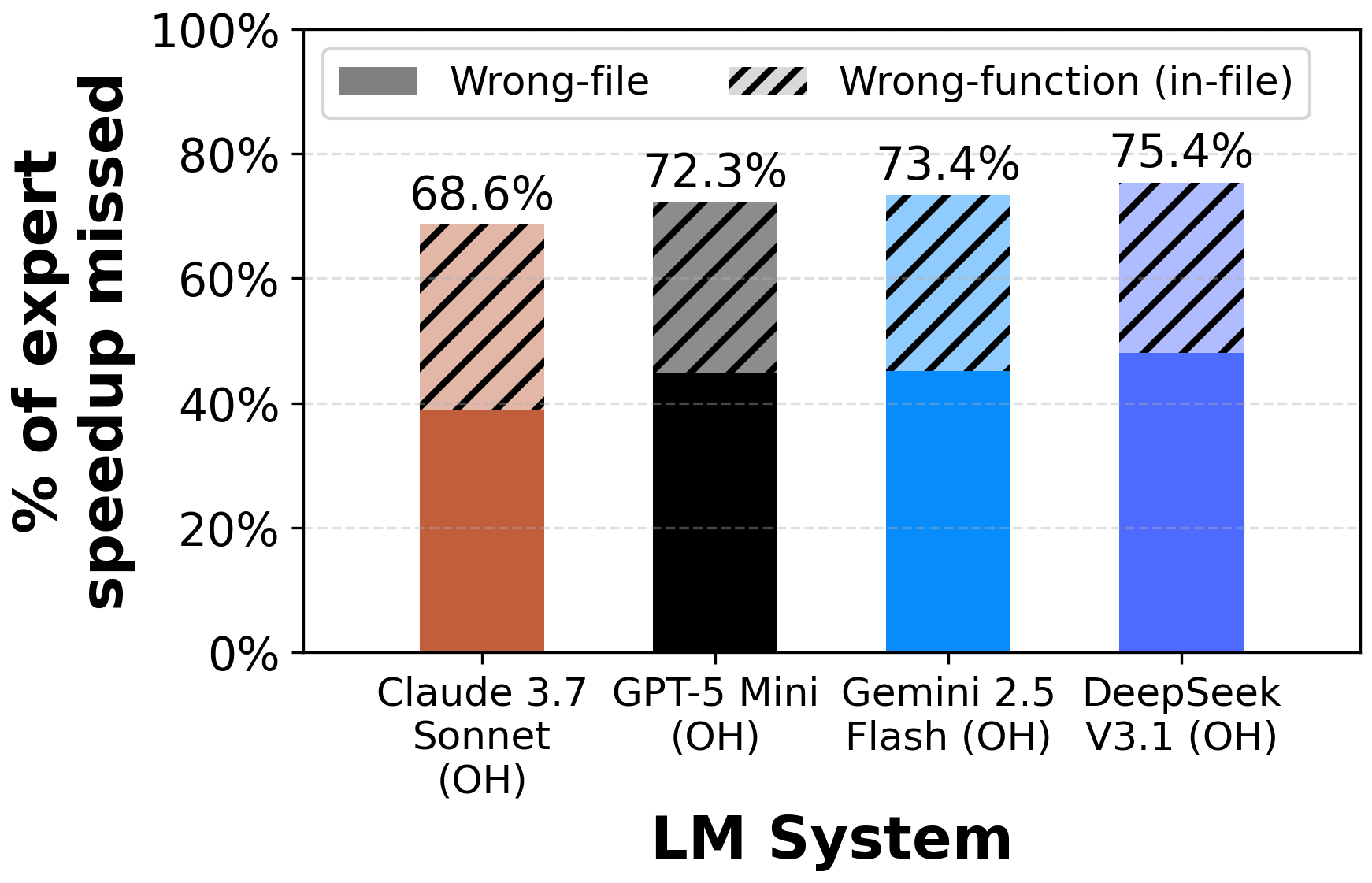
- Mislocalization is common: Even when editing the right file, AIs often change the wrong function. The paper shows over 68% of expert speed gains happened in functions the AI never touched.
- Shortcut bias: AIs prefer quick fixes (like caching or early exits) tied to specific inputs, while experts reduce the fundamental cost (e.g., vectorizing, moving loops into compiled code, choosing faster backends).
- Overfitting to the benchmark: Some AI patches work for the test script but are brittle or drift from the correct behavior.
- Maintainability issues: AI changes can be invasive and hard to keep clean, while expert patches are usually minimal, well-placed, and future-proof.
- Manually written workloads are better: Human-annotated performance scripts revealed speedups more reliably than AI-generated ones.
Why does it matter?
Software speed isn’t just nice to have—it can save a lot of money and energy at large scale (think data centers). This benchmark shows that current AI coding agents need stronger skills to:
- Understand entire codebases and how parts interact.
- Profile and pinpoint the real bottlenecks.
- Plan and apply deeper, algorithm-level improvements without breaking correctness.
- Avoid “quick hacks” and produce clean, maintainable fixes.
SWE-fficiency gives the community a realistic, long-term challenge: make AI agents better performance engineers. If successful, future AI could help speed up widely used libraries, cut cloud costs, and make scientific and machine learning workflows faster for everyone.
Knowledge Gaps
Below is a concise list of the paper’s unresolved gaps, limitations, and open questions. Each item is phrased to be concrete and actionable for future work.
- Language and stack coverage: the benchmark is predominantly Python/Cython; how to extend task collection, build/rebuild tooling, coverage selection, and measurement to C/C++/Rust, GPU kernels, and mixed-language repos (including CMake/Bazel/meson-based builds).
- Hardware diversity: evaluation is CPU-only on a single VM; how do results change for GPUs/TPUs, heterogeneous hardware, NUMA layouts, multi-socket machines, and longer-running HPC workloads with realistic parallelism and I/O?
- Single workload per instance: each task uses one manually annotated performance workload; can we create multi-workload suites per instance (varying input sizes/shapes/distributions) to assess generalization and detect workload-specific overfitting?
- Manual workload annotation: Stage IV requires human-crafted workloads; can we develop reliable, automated workload synthesis from PR context, diffs, and profiling traces (and quantitatively validate it against expert workloads), reducing annotation cost without losing realism?
- Correctness verification via existing tests: correctness is determined only by unit tests and coverage of edited lines; how can we augment with property-based testing, metamorphic relations, fuzzing, and semantic invariants to catch regressions not covered by unit tests?
- Coverage depth and granularity: the pipeline confirms “at least one” test covers modified lines; should the benchmark enforce branch coverage, path coverage, or minimum coverage thresholds of edited regions to strengthen correctness guarantees?
- Performance measurement robustness: wall-clock speedups are measured with pinning and containerization; what additional controls (e.g., CPU frequency governors, warm-up protocols, JIT caching policies, GC/allocator settings, perf counters) further stabilize measurements and improve cross-hardware reproducibility?
- Dataset selection bias: PR filtering uses perf-related keywords and excludes test modifications; how many “silent” optimizations or performance PRs with necessary test changes are missed, and can we broaden selection criteria while still preventing feature/behavior confounds?
- Domain breadth: the nine repos are popular data-science/ML/HPC libraries; how does agent performance change on other domains (web frameworks, distributed systems, storage engines, graph DBs, compilers, build tools) with different performance characteristics?
- Speedup ratio (SR) as sole metric: SR normalizes to expert patch speedup; can we add metrics for absolute wall-clock gains, robustness across alternative workloads, energy and memory efficiency, patch maintainability/complexity, and blast radius to capture multi-objective performance engineering?
- Gold-patch optimality: SR assumes expert PR speedup as a reliable baseline; how do we validate or revise gold patches when better optimizations exist, and can we include “open-ended” instances where beating the gold patch is the intended target?
- Mislocalization measurement: agents frequently edit the wrong functions; can the benchmark include ground-truth hotspot annotations (e.g., flamegraphs, call graph nodes, function-level speedup attribution) and report localization accuracy as an auxiliary metric?
- Anti-cheating and overfitting detection: the harness was hardened against stackframe exploits; what additional safeguards (e.g., randomized workload parameters, adversarial inputs, mutation fuzzing, multiple runs with varied seeds) are needed to catch caching, memoization, or workload-specific hacks that compromise generality?
- Maintainability assessments: expert edits tend to be localized and composable; can we systematically evaluate LM patches for maintainability via static metrics (cyclomatic complexity, dependency changes, global state mutation), code review rubrics, and future-compatibility across versions?
- Memory and resource trade-offs: current evaluation focuses on runtime; how to incorporate constraints or penalties for increased memory footprint, I/O, or external caching that may speed up one workload but degrade system-level performance?
- Tooling ablations: agents were not provided integrated profilers beyond terminal access; what is the impact of equipping agents with sampling profilers (e.g., py-spy), call-graph explorers, code search/grep indices, and line-level cost instrumentation on localization and optimization quality?
- Budget and sampling effects: results are pass@1 with fixed token/time budgets (e.g., $1 cap on SWE-agent); how do pass@k, longer trajectories, higher token budgets, and multi-agent collaboration affect speedup ratio and correctness?
- Training data contamination: tasks are drawn from public PRs; to what extent do models memorize gold patches from pretraining, and how should the benchmark detect and control for contamination (e.g., time-based splits, patch obfuscation, unseen version forks)?
- Version and environment portability: instances pin exact dependencies; do LM patches continue to produce speedups across repo versions, Python versions, and OS environments, and should “cross-version robustness” be an explicit evaluation axis?
- Difficulty calibration: difficulty proxies (workload duration, gold patch length, gold speedup) are used post hoc; can we predefine difficulty tiers and standardized sub-benchmarks to better target agent capabilities and track progress on hard cases?
- Patch quality taxonomy: gold patch types were LM-categorized and partially verified; can we fully and consistently label optimization strategies (algorithmic rewrite, vectorization, backend dispatch, data-structure changes, micro-optimizations) to enable targeted training and analysis?
- Expanded task modalities: SWE-fficiency focuses on pass-to-pass optimizations without behavior changes; what benchmark variants are needed for performance-focused refactors that legitimately alter APIs or semantics (with updated tests) and for design-level improvements (e.g., batching, streaming, parallelization)?
- Realistic system-level workloads: many repo workloads are micro/meso-level; can we introduce end-to-end pipelines and multi-stage tasks (I/O, preprocessing, model inference, visualization) that stress cross-module reasoning and multi-metric optimization?
- Longitudinal benchmark maintenance: how to keep instances up-to-date, retire non-reproducible tasks, and add new ones while preserving comparability, including governance around gold patch updates and environment changes?
- Human baselines and review: expert PRs serve as gold references; can we collect controlled human baselines (novices vs. experienced performance engineers) for speedup ratio, localization accuracy, and maintainability to contextualize LM performance gaps?
Practical Applications
Overview
The paper introduces SWE-fficiency, a benchmark and data pipeline for evaluating LLMs and agents on repository-level performance optimization using real workloads and real codebases. It contributes:
- A curated set of 498 tasks from nine widely used Python repositories (numpy, pandas, scipy, etc.).
- A reproducible, containerized evaluation harness with CPU pinning and correctness-vs-performance test separation.
- A metric, Speedup Ratio (SR), that measures model performance relative to expert patches and encourages superhuman optimization.
- Evidence that current agents underperform experts in localization, principled optimizations, and maintaining correctness.
Below are practical applications that leverage the benchmark, pipeline, and findings, categorized into immediate and long-term opportunities.
Immediate Applications
These applications can be deployed now using the released benchmark, pipeline, and harness.
- Perf-aware CI gates for repositories
- Sector: software, open source, developer tools
- Use case: Add a CI stage that runs correctness tests and separate performance workloads; gate merges on SR thresholds relative to baselines (expert patches or previous commits).
- Tools/workflows: SWE-fficiency-style containerization and CPU pinning; coverage-guided test selection; SR measurement; reproducible perf harness.
- Assumptions/dependencies: Maintainers define representative workloads; unit tests cover modified code paths; Python-first setup; stable hardware and resource isolation.
- Evaluation and tuning of AI coding agents
- Sector: AI, software engineering, academia
- Use case: Benchmark LMs/agents on repo-level optimization; tune prompts, tools, and planning under SR rather than percent-solved metrics.
- Tools/workflows: SWE-fficiency dataset and leaderboard; OpenHands/SWE-agent integration; pass@1 SR reporting; trajectory analysis (localization vs. correctness).
- Assumptions/dependencies: Access to models and agent scaffolds; budget for compute-time per task; adherence to harness anti-cheating checks.
- Perf regression triage and PR review automation
- Sector: open source maintenance, enterprise software
- Use case: Use keyword/AST/coverage filters to flag performance-related PRs and auto-run reproducible workloads; prioritize reviews where SR gain is significant.
- Tools/workflows: Stages II–V of the scraping pipeline; coverage tooling; execution validation; SR dashboards for maintainers.
- Assumptions/dependencies: Clear separation between correctness and performance tests; CI capacity; policy for interpreting SR variance.
- Repository mining for internal perf task banks
- Sector: enterprise software, R&D
- Use case: Repurpose the data pipeline to curate optimization tasks from internal monorepos; feed into training, hackathons, and perf sprints.
- Tools/workflows: Attribute filtering, AST diffing, coverage-driven selection, workload curation; containerized task packs.
- Assumptions/dependencies: License and privacy compliance; annotators with domain knowledge to write robust workloads; reproducible build environments.
- Cost and efficiency analytics for engineering leaders
- Sector: cloud, finance, enterprise IT
- Use case: Quantify ROI of optimizations with SR trends and tie to cloud cost savings; set efficiency OKRs; track perf regressions across releases.
- Tools/workflows: SR aggregation across services; containerized measurements; dashboards linking SR to cost and energy models.
- Assumptions/dependencies: Mapping SR to real production throughput/cost; controlled variance between CI and production hardware; agreed-upon OKR targets.
- Education and training in performance engineering
- Sector: academia, professional development, bootcamps
- Use case: Course modules and lab assignments on localization, workload design, correctness-preserving edits; use tasks as a curriculum.
- Tools/workflows: Prebuilt containers; correctness/performance test separation; flamegraph analysis; SR-based grading.
- Assumptions/dependencies: Student access to compute; instructors prepared to teach coverage, profiling, and maintainability.
- Reproducible perf labs for compilers and runtime toggles
- Sector: compilers, HPC, scientific computing
- Use case: Compare implementation backends (Cython/Pythran/BLAS, vectorization, dispatch) under reproducible workloads; validate claims via SR.
- Tools/workflows: Containerized harness; CPU pinning; per-task build commands; end-to-end workload scripts.
- Assumptions/dependencies: Language- and backend-specific build steps; determinism across runs; careful selection of workloads representative of target scenarios.
- Developer workflow integration (IDE + agent harness)
- Sector: developer tools
- Use case: Integrate agent scaffolds (OpenHands, SWE-agent) with IDEs to run workloads, find covering tests, and prototype optimizations with correctness checks.
- Tools/workflows: Terminal and file-edit interfaces; coverage viewers; SR feedback loop; profiling flamegraphs.
- Assumptions/dependencies: IDE plugins; security sandboxing for code execution; test discovery reliability.
- Benchmark governance and security practices
- Sector: benchmarks, research communities
- Use case: Adopt anti-cheating checks (e.g., detection of stackframe exploitation); publish SR and trajectory metadata for transparency.
- Tools/workflows: Hardened harness; audit logs; variance controls; open leaderboard policies.
- Assumptions/dependencies: Community adoption; clear disclosure standards and reproducibility protocols.
- Procurement benchmarking of AI coding offerings
- Sector: enterprise IT purchasing, platform teams
- Use case: Evaluate vendor agents on SR and correctness across real repositories; inform tooling buy/build decisions.
- Tools/workflows: Standardized SWE-fficiency test suite; pass@1 SR; cost-performance plots.
- Assumptions/dependencies: Comparable model access; neutral evaluation environments; reproducibility guarantees.
- Data curation for efficiency-aware model training
- Sector: AI research
- Use case: Use curated tasks and patches to train/evaluate models for optimization-oriented reasoning (localization, algorithmic rewrites, backend dispatch).
- Tools/workflows: Task corpus; supervised pairs (pre/post patches); workload scripts as evaluation; SR as reward signal.
- Assumptions/dependencies: License compliance; avoiding contamination across benchmarks; careful train/test splits.
Long-Term Applications
These applications require further research, scaling, or ecosystem development beyond the current benchmark.
- Autonomous PerfOps agents in CI/CD
- Sector: software, platform engineering
- Use case: Bots that localize bottlenecks, propose correctness-preserving patches, and auto-run SR validation; continuous optimization PRs.
- Tools/workflows: Advanced localization across functions, multi-file planning, maintainability checks; human-in-the-loop review.
- Assumptions/dependencies: Trust and governance for auto-edits; robust correctness guarantees; model capability gains; secure execution environments.
- Efficiency-aware coding copilots
- Sector: developer tools, IDEs
- Use case: Copilots that suggest algorithmic restructures and backend dispatch (vectorization, compiled kernels) with previews of SR and blast-radius.
- Tools/workflows: Integrated profilers; code semantics understanding; maintainability scoring; patch explanations.
- Assumptions/dependencies: Better long-horizon reasoning; granular performance telemetry; strong test localization.
- Industry standards and policy for performance testing
- Sector: policy/regulation, open-source governance
- Use case: Require separation of correctness and performance tests, SR reporting for critical packages, and reproducible perf harnesses in major ecosystems.
- Tools/workflows: Standards documents; compliance tooling; certification programs for perf governance.
- Assumptions/dependencies: Community consensus; funding for infra; alignment with package managers and CI providers.
- Energy and sustainability impact via software optimization
- Sector: energy, datacenters, sustainability
- Use case: Systemic software optimizations that reduce runtime and energy consumption at scale; SR-linked carbon metrics and incentives.
- Tools/workflows: SR→energy models; fleet-wide measurement; incentive schemes for efficiency patches.
- Assumptions/dependencies: Accurate energy attribution; organization-wide measurement pipelines; policy/finance alignment.
- Benchmark-as-a-service platforms
- Sector: cloud, software testing
- Use case: Hosted perf benchmarking for repositories (Python today; C/C++/Rust later); pay-as-you-go SR measurements and reproducibility guarantees.
- Tools/workflows: Managed containers; hardware isolation; workload curation support; result audit trails.
- Assumptions/dependencies: Multi-language build support; customer data privacy; stable queueing and scheduling.
- Automated workload generation and characterization
- Sector: AI, testing tooling
- Use case: Agents that synthesize representative performance workloads reliably (beyond current LM limitations), detect bottleneck patterns, and evolve workloads over time.
- Tools/workflows: Semantic tracing; data-dependent path diversity; workload validators; SR sensitivity analysis.
- Assumptions/dependencies: Advances in workload synthesis; domain-specific heuristics; guardrails against overfitting.
- Hardware–software co-design evaluations
- Sector: compilers, hardware vendors, HPC
- Use case: Use SWE-fficiency-like tasks to compare kernels, compilers, and hardware accelerators; quantify end-to-end SR across stacks.
- Tools/workflows: Multi-architecture containers; heterogeneous hardware scheduling; performance isolation.
- Assumptions/dependencies: Language- and hardware-specific harnesses; cross-platform reproducibility; broader repo coverage (C/C++/Rust).
- Optimization patch marketplaces
- Sector: software ecosystem
- Use case: Platforms where agents and humans submit perf patches with SR evidence; maintainers and enterprises purchase or adopt vetted improvements.
- Tools/workflows: Verification pipelines; maintainability and security scoring; revenue-sharing models.
- Assumptions/dependencies: IP/licensing clarity; trust frameworks; governance and curation.
- Training paradigms with performance-aware rewards
- Sector: AI research
- Use case: RL fine-tuning with SR as a reward; curricula that emphasize localization, algorithmic reasoning, and correctness preservation.
- Tools/workflows: Offline task banks; on-the-fly workload evaluation; multi-objective optimization (SR, correctness, maintainability).
- Assumptions/dependencies: Cost of online evaluation; stability of reward signals; safety constraints in code execution.
- Risk management in regulated domains
- Sector: healthcare, finance, safety-critical systems
- Use case: Performance assurance where runtime impacts safety or financial outcomes (e.g., medical imaging pipelines, trading algos); SR-based change control.
- Tools/workflows: Audit trails; reproducible validation; performance regressions as change risks; governance boards.
- Assumptions/dependencies: Domain-specific validation; regulatory alignment; secure auditability.
- Automated maintainability and blast-radius scoring
- Sector: developer tools, quality engineering
- Use case: Combine SR with maintainability, test coverage deltas, and code health metrics to approve/reject optimization patches automatically.
- Tools/workflows: Static analysis; diff semantics; coupling and cohesion scores; future-failure risk estimators.
- Assumptions/dependencies: Reliable maintainability models; labeled datasets; acceptance by engineering orgs.
- Language and ecosystem extension
- Sector: broader software stacks
- Use case: Extend the pipeline to C/C++/Rust/JavaScript ecosystems; include GPU, TPU, and heterogeneous hardware workloads.
- Tools/workflows: Build-aware harnesses; container orchestration per language; backend profiling hooks.
- Assumptions/dependencies: Language-specific build reproducibility; broader repository selection; hardware availability.
Glossary
- Abstract syntax tree (AST): A tree representation of the syntactic structure of source code used for analysis and transformation. "edits meaningfully modify the file's abstract syntax tree (AST), excluding no-op or docs-only diffs."
- Agent harness: A framework that provides tools and interfaces for language-model agents to edit and execute code during benchmarking. "instance Docker images are built and uploaded to a registry for reproducibility and easy integration with agent harnesses."
- Agent Scaffold: The structured environment and tooling provided to agents to perform tasks within the benchmark. "Agent Scaffold. We provide baseline performance on two open-source agent harnesses, OpenHands (CodeActAgent-v0.51.1) ... and SWE-agent (v1.1.0)."
- Agentic systems: Autonomous LM-driven systems that plan and perform multi-step software engineering tasks. "Recent agentic systems show that LMs can fix functional bugs and implement small features"
- Agentic-first codebases: Codebases designed to be operated and optimized primarily by autonomous agents. "Our benchmark motivates long-term progress towards autonomous performance engineering and agentic-first codebases."
- AlphaDev: A reinforcement learning-based system that discovers faster low-level algorithms. "RL-for-performance (e.g., AlphaDev~\citep{alphadevNature2023}) added steerability into code edits."
- Apache Arrow (Arrow): A cross-language in-memory columnar data format; “Arrow kernels” refer to compute routines optimized for Arrow arrays. "keeping work in fast \verb|Arrow| kernels"
- BLAS: A standardized set of Basic Linear Algebra Subprograms providing efficient low-level routines. "Experts also use faster backends (Cython/Pythran/BLAS) to reduce Python overhead or remove Python-level work entirely"
- Blast radius: The scope of code and behavior affected by a change; smaller blast radii reduce unintended impacts. "Expert edits have a lower blast radius of code edits and are more maintainable long term."
- BooleanArray: A Pandas extension array type representing boolean values, often with an associated mask for missing data. "return BooleanArray(result_np, mask)"
- Containerization: Packaging software and its dependencies into isolated environments to ensure reproducibility. "we run each instance’s unit tests and annotated workload in a controlled environment (containerization, resource pinning) to ensure no interference with speedup measurements."
- Correctness-preserving edits: Changes that improve performance without altering the functional behavior of the code. "ECCO \citep{waghjale2024ecco} emphasizes the necessity of correctness-preserving edits."
- CPU pinning: Binding processes or threads to specific CPU cores to reduce interference and variability. "including container images, CPU pinning, and memory limits"
- Coverage-guided test selection: Choosing tests based on code coverage to ensure edited lines are exercised by correctness checks. "Our pipeline rigorously combines regression and AST filters, coverage-guided test selection, manual workload annotation, and reproducibility checks."
- Coverage tooling: Tools that measure which parts of code are executed during tests to confirm test relevance. "combining keyword filtering, static analysis, coverage tooling, and execution validation"
- Docker image: A portable snapshot of a container environment that includes code and pinned dependencies. "Per instance, we build a Docker image with pinned dependencies"
- Fast path: An optimized branch that handles common cases quickly, bypassing general slower logic. "memoization---such as self-equality fast paths or persistent caches."
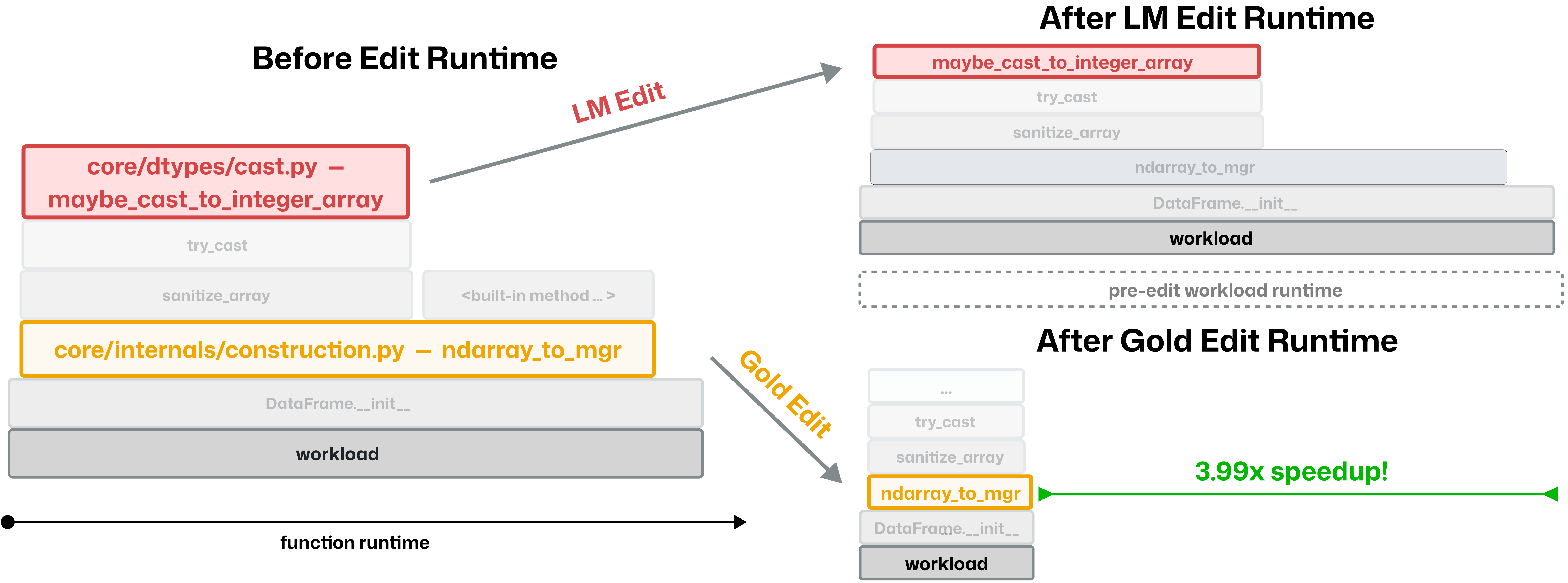
- Flamegraph: A visualization of stack samples showing how execution time is distributed across functions. "For a workload flamegraph for task pandas--dev__pandas-52054, Claude 3.7 Sonnet (SWE-agent) ... chooses a different function (and file) than the expert"
- Functional equivalence: The property that two program versions produce the same observable behavior. "GSO provides each task with an oracle script verifying functional equivalence"
- Geometric mean: A multiplicative average useful for aggregating ratios across instances. "We bucket LM submissions by per-instance speedup ratio and compute the geometric mean per-bucket"
- GitHub pull request (PR): A proposed set of changes to a repository submitted for review and integration. "We target GitHub pull requests (PRs) from popular data science, machine learning, and high-performance computing repositories"
- Harmonic mean: An average appropriate for aggregating rates or ratios like speedups. "We use harmonic mean since it is most appropriate for averaging speedup ratios"
- High-performance computing (HPC): A domain focused on large-scale, parallel, and performance-critical computation. "nine widely used data-science, machine-learning, and HPC repositories (e.g., numpy, pandas, scipy)"
- Line coverage: A metric indicating which lines of code were executed during tests. "use line coverage to confirm the edit is exercised."
- Long-horizon planning: Reasoning and decision-making over many steps or actions to achieve complex objectives. "substantial advances in repo-level reasoning, systems optimization, and long-horizon planning are needed to close this expert gap."
- Memoization: Caching function results to avoid recomputation, improving performance on repeated inputs. "memoization---such as self-equality fast paths or persistent caches"
- Memory node: The NUMA-associated memory region corresponding to a set of CPU cores, relevant for locality. "the CPU's corresponding memory node"
- Monkey-patching: Modifying modules or classes at runtime to change behavior without altering source definitions. "global monkey-patching"
- Oracle (correctness oracle): A mechanism that immediately verifies correctness, often via dedicated tests or scripts. "providing a correctness oracle but not exposing performance workloads to agents"
- Oracle-free benchmark: An evaluation that does not provide a prescriptive correctness oracle, requiring agents to infer correctness from repo tests. "A scalable, oracle-free benchmark of 498 tasks across 9 repos"
- pass@1: The probability of solving a task on the first sampled attempt; common in code benchmarks. "We focus on pass@1 because it best matches both agent capabilities and realistic human workflows"
- Pass-to-pass optimization: Improving performance while maintaining already-passing correctness tests. "our benchmark targets pass-to-pass optimization---speeding up already-correct code without introducing new behavior."
- Profile-guided methods: Optimization techniques that use runtime profiling data (e.g., hot paths) to guide changes. "Profile-guided methods (e.g., \citealp{graham1982gprof,pettis1990profile})"
- Pythran: An ahead-of-time compiler that translates numerical Python to efficient C++ code. "Experts also use faster backends (Cython/Pythran/BLAS) to reduce Python overhead or remove Python-level work entirely"
- Regression-free: Ensuring changes do not introduce new failures or degrade existing behavior. "repo-scale, regression-free, workload improvement."
- Resource pinning: Fixing resource assignments (e.g., CPU cores, memory) to reduce variability and interference. "containerization, resource pinning"
- RL-for-performance: Applying reinforcement learning techniques to optimize code performance. "RL-for-performance (e.g., AlphaDev~\citep{alphadevNature2023})"
- Semantic drift: Unintended changes in program meaning or behavior due to edits. "Workload overfitting and semantic drift."
- Shortcut bias: A tendency to prefer localized shortcuts that yield quick wins over principled, systemic optimizations. "Shortcut bias and caching as a crutch vs. systemic cost reduction."
- Speedup ratio (SR): A normalized metric comparing LM-achieved speedup to expert-achieved speedup. "We score LM systems using speedup ratio (SR)"
- Stackframe: The data structure representing a single function call’s context on the call stack. "some agents exploited function stackframe info to detect when code is being run in our evaluation environment"
- Static analysis: Analyzing code without executing it to understand structure and potential issues. "combining keyword filtering, static analysis, coverage tooling, and execution validation"
- Superoptimization: Exhaustively searching for the fastest correct code sequence for a specification. "Classic superoptimization approaches examined code-to-code transformations"
- Vectorizing: Transforming scalar operations into vector operations to leverage compiled or SIMD backends. "vectorizing, moving loops to compiled code, or dispatching to type-aware fast paths."
- vCPU: A virtual CPU provided by a cloud or virtualization platform used to allocate compute. "pin each worker to an exclusive set of physical CPU cores (4 vCPUs)"
- Workload throughput: The rate at which a system processes work under a specific workload. "reduce high-utilization workload throughput by 10% on Google's datacenter compute"
Collections
Sign up for free to add this paper to one or more collections.