Data-Constrained Language Model Pretraining: Improved Regularization and Scaling Laws
Abstract: Classical scaling laws for LLM pretraining balance model size against training dataset size under a fixed compute budget, assuming abundant data and a single pass over the corpus. As training compute grows faster than the supply of natural language data, pretraining is likely to enter a data-constrained, compute-rich regime where models train for multiple epochs over a finite dataset. We study data-constrained pretraining along two axes, regularization and scaling. For regularization, we study masked-input regularization (MIR), an auxiliary next-token prediction loss on randomly masked inputs. MIR tests whether the random masking central to diffusion LLMs can benefit autoregressive pretraining without architectural changes or inference overhead. Across 72M to 1.4B parameter models, we find that MIR added on top of strong weight decay improves validation loss over autoregressive strong-weight-decay-only models, with downstream gains at 1.4B. For scaling, we propose SoftQ, a scaling law that couples model size and data size to capture their interaction under repeated data. Classical alternatives such as the Chinchilla law use an additive form that decouples these terms, making them misspecified in the data-constrained regime. We find that SoftQ fits data-constrained experiments substantially better than these alternatives, and estimates MIR's gains as equivalent to roughly 1.3 times as much unique training data. We release our code at https://github.com/yixinw-lab/dc_pretrain.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Easy-to-Read Summary of “Data-Constrained LLM Pretraining: Improved Regularization and Scaling Laws”
What this paper is about (big picture)
The paper looks at how to train LLMs when you have lots of computer power but only a limited amount of unique text to learn from. Imagine studying for a test with just one small textbook: you can read it many times, but it’s still the same book. The authors ask: how do we keep models from just memorizing that small book, and how do we choose the right model size for the amount of text we have?
They explore two things:
- A simple training trick called masked-input regularization (MIR) that helps models learn better from limited data.
- A new “scaling law” called SoftQ that better predicts how model performance changes as you change model size and data size when data is limited.
The key questions, in simple terms
- How can we stop models from overfitting (memorizing) when they read the same small dataset multiple times?
- What rule-of-thumb (“scaling law”) should we use to pick the best model size and data size when we’re stuck with a limited amount of unique text?
How they explored these questions (methods in everyday language)
To keep things simple, think of training a model like practicing to finish sentences correctly:
- “The sky is…” → “blue.”
- “He went to the…” → “store.”
But if you reread the same small text over and over, you might memorize exact phrases rather than learn general language patterns.
Here’s what the authors did:
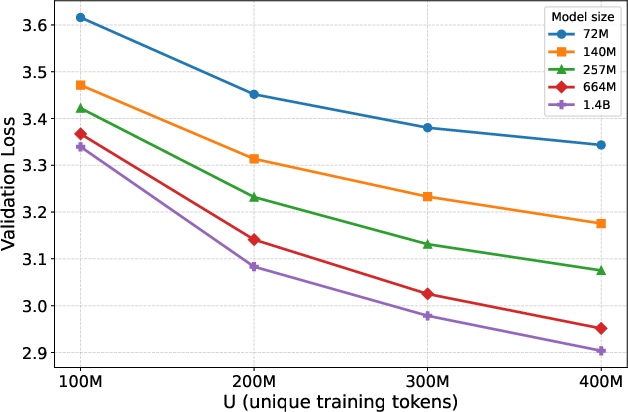
- They trained several LLMs of different sizes (from about 72 million to 1.4 billion parameters—that’s like the number of “knobs” the model can adjust).
- They used a small amount of unique training text (100–400 million tokens, where a token is roughly a word or piece of a word), and let models read it multiple times.
- They used strong “weight decay,” a common regularization trick that gently pulls the model’s internal values toward smaller numbers. Think of it like a “simplicity penalty” that discourages overly complicated memorization.
- They tested a new add-on called masked-input regularization (MIR). MIR is like covering some words with sticky notes and asking the model to still predict the next word. It’s the same model and the same next-word task—no architecture changes—just an extra “masked” version of the input as practice during training.
- They measured performance with “validation loss” (lower is better), which tells you how well the model predicts text it didn’t see during training.
- They also checked results on different kinds of data (regular web text and code-heavy text) and on downstream tasks (like reading comprehension).
- Finally, they compared different “scaling laws”—simple formulas that predict model performance based on model size and data amount. They showed that a classic formula (called Chinchilla) doesn’t work well when data is limited and introduced a new one, SoftQ, that fits better.
Key terms explained:
- Overfitting: Memorizing training data so closely that you don’t do well on new, unseen text.
- Weight decay: A “keep it simple” rule that reduces overfitting.
- Masking: Hiding some input words during training so the model must rely on more general patterns, not just the exact context.
- Scaling law: A simple math rule that helps you choose model size and data size to get the best performance.
What they found (main results)
Here are the headline results, described plainly:
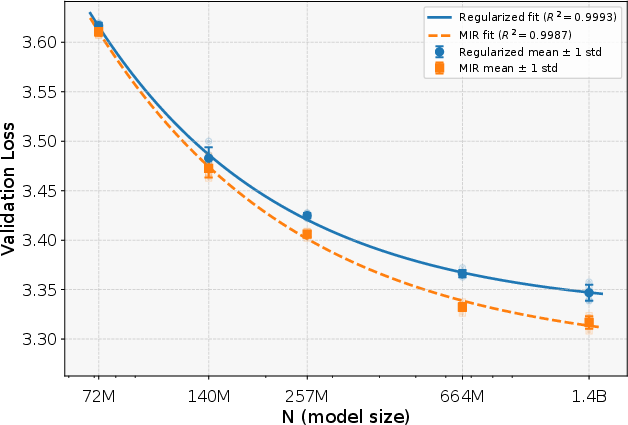
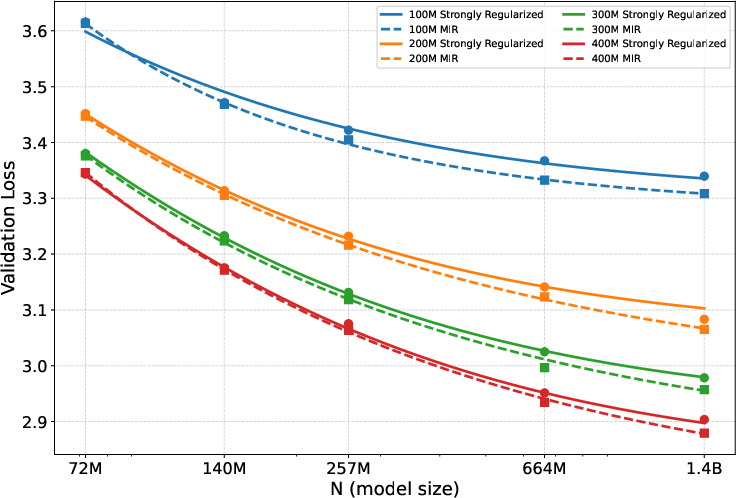
- MIR helps on top of strong regularization:
- Even when they already used strong weight decay (which is very important in this limited-data setting), adding MIR still made models better.
- The improvement in validation loss was consistent across model sizes, and it was bigger for larger models.
- MIR also helped on code data, even though they only tuned the method on natural language data.
- How does MIR help?
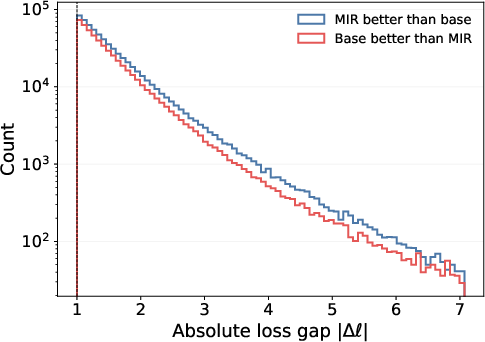
- MIR improved performance across a wide range of “hard spots” in the validation data—especially where context is messy: rare names, mixed languages, broken word chunks, punctuation, or noisy web text. In other words, MIR made the model more robust when the local context is weird or distracting.
- In downstream tests, the largest model trained with MIR scored better on most tasks, with a big jump on BoolQ (a reading comprehension task) by about 10 percentage points.
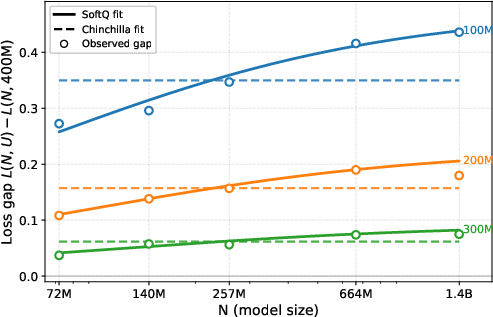
- A better scaling law for limited data (SoftQ):
- The classic Chinchilla scaling law assumes you can always get more fresh data and treats model size and data size separately. In the limited-data world, that assumption breaks: the penalty for having little unique data gets worse as your model gets bigger.
- The authors propose SoftQ, a new scaling law that couples model size and data size. It fits the results much better than Chinchilla and other alternatives.
- Using SoftQ to measure MIR’s benefit: MIR’s gains are roughly equivalent to having about 1.3× more unique training data at medium budgets (200M–400M tokens). In other words, MIR makes your limited data “go further.”
Why this matters (implications)
- Training reality is changing: Compute (the ability to run long trainings) is growing faster than the amount of high-quality text on the internet. So, more and more training will happen in a “data-constrained” world.
- Practical recipe for better training: If you have limited unique data, use strong weight decay and add MIR. It’s easy to implement, requires no model changes, and makes models more robust—especially the bigger ones.
- Better planning with SoftQ: If you need to choose model size and data size wisely under limited data, SoftQ is a more accurate guide than older rules. It helps teams avoid picking a model that’s too big for the data they have.
- Data efficiency: MIR can “save” data by squeezing more learning out of what you’ve got—like turning 300M unique tokens into the equivalent of ~390M in effect, without having to collect more text.
In one sentence
When you have lots of compute but only a small amount of unique text, combining strong regularization with masked-input practice (MIR) makes LLMs learn more robustly, and a new scaling law (SoftQ) gives a better roadmap for choosing model size and data in this data-limited world.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated and concrete list of what remains uncertain or unexplored in the paper, framed to guide actionable follow-up research.
- Compute–regularization trade-off of MIR under realistic constraints:
- How MIR compares to alternative ways of spending the same extra compute (e.g., more epochs, larger batch size, longer context length, heavier weight decay, dropout, data augmentation) when compute is the binding resource rather than unique data.
- Wall-clock, throughput, and memory overheads of MIR in practice, and whether more compute-efficient implementations (e.g., mixed masked/clean tokens in a single forward pass) preserve its gains.
- Optimal MIR design and scheduling:
- Systematic ablations on the masking policy: token vs span masking, corruption distributions, mask ratios, curriculum scheduling of mask rate, and adaptive or entropy-aware masking policies.
- Tuning and stability of the auxiliary weight λ and mask-range parameters (r_min, r_max); guidelines or heuristics for robust defaults across domains and scales.
- Interaction with other regularizers and training choices:
- Joint effects and potential redundancy/synergy with dropout, stochastic depth, label smoothing, token/word dropout, Mixout, EMA, gradient noise injection, data augmentation, and sample reweighting.
- Dependence on optimizer (AdamW vs Adafactor/SGD), learning-rate schedules, weight-decay decoupling details, and per-parameter decay configurations.
- MIR dynamics and learning behavior:
- When in training MIR provides most of its gains (early vs late), whether it enables more epochs before overfitting, and whether a time-varying schedule (e.g., annealing mask ratio or λ) improves outcomes.
- Gradient-level or representation-level analyses to test the hypothesized mechanism (reduced reliance on context-specific noise) beyond a toy model.
- Train–test mismatch and inference-time behavior:
- Effects of training on masked inputs but decoding on clean sequences: impact on calibration, exposure bias, and generation quality (beyond validation loss).
- Assessment of perplexity–quality alignment and calibration metrics (e.g., ECE), especially on noisy or OOD text.
- Robustness and domain coverage:
- Generalization of MIR beyond the tested corpora and settings: multilingual text, higher-quality curated corpora, noisy vs cleaned datasets, specialized domains (biomedical, legal), and code at larger budgets.
- Long-context settings (context length > 2k): whether MIR helps with retrieval, long-range coherence, and memory, and how masking interacts with positional schemes (RoPE/ALiBi variants).
- Downstream evaluations:
- Broader and stronger downstream assessment: instruction tuning, chain-of-thought, preference-tuned models (RLHF/DPO), program synthesis benchmarks (e.g., HumanEval, MBPP), and long-form generation.
- Fine-tuning/continued-pretraining transfer: whether MIR-trained checkpoints fine-tune more efficiently or robustly than baselines.
- Memorization and privacy:
- Direct measurement of memorization (e.g., membership-inference or canary extraction) to validate the claim that MIR reduces memorization and to assess privacy implications in repeated-data settings.
- Fairness of AR vs dLLM comparisons:
- Full hyperparameter re-optimization for dLLMs beyond weight decay (learning rate, schedules, augmentations) and matched early-stopping criteria to ensure apples-to-apples comparisons.
- Evaluation parity: use of comparable likelihood proxies or generation-based metrics to mitigate the ELBO vs NLL comparability gap.
- Scale and scope limitations:
- Validation of MIR and SoftQ beyond 1.4B parameters and 400M unique tokens, including larger models, larger unique-data budgets, and different tokenizers/vocabularies.
- Sensitivity to architecture choices (e.g., MoE, depth–width allocations, normalization schemes, activation functions).
- Data quality and deduplication:
- How MIR’s gains vary with corpus cleanliness/deduplication levels; whether improvements are larger on noisier datasets and how this interacts with data filtering strategies.
- Repetition-aware modeling:
- An explicit treatment of the number of epochs and repetition patterns in the scaling law (rather than hiding them inside the envelope L*(N,U)), to predict performance as a function of (N, U, N_E) and quantify diminishing returns with repetition.
- SoftQ theory and identifiability:
- A deeper theoretical grounding for SoftQ (beyond heuristic coupling), connections to the skill-learning/expressivity literature, and interpretation of the bottleneck sharpness parameter ρ.
- Parameter identifiability, stability under resampling or different grids, and sensitivity to the chosen loss fitting objective (e.g., Huber on log-loss residuals).
- Uncertainty and sensitivity of data-efficiency estimates:
- Confidence intervals for the “~1.3× unique data” estimate; robustness to alternative fitting objectives, different grid splits, and different held-out regimes.
- Sensitivity to the chosen scaling law—while SoftQ fits best here, how much the equivalence factor varies under other plausible laws or under small data/model shifts.
- External validity of SoftQ:
- Predictive performance on additional, diverse datasets and training recipes (other tokenizers, context lengths, optimizers), including out-of-domain extrapolation to larger U and N than seen in this work.
- Compute-conditional predictions (e.g., if compute, not U, is fixed), to see whether SoftQ remains competitive or needs adaptation.
- Hyperparameter-search reliance:
- The envelope L*(N,U) is approximated via per-cell hyperparameter searches; development of hyperparameter-transfer or meta-optimization recipes that approximate L* with less search cost, and quantification of the performance gap to true L*.
- Code-specific and structure-aware masking:
- For code, exploration of syntax/AST-aware masking, identifier-aware schemes, and span-level corruption to test whether structure-aware MIR yields larger gains than random token masking.
- Tokenization and vocabulary effects:
- Whether MIR’s benefits depend on subword segmentation, byte-level tokenization, or vocabulary size; and whether masking at higher-level units (morphemes, words) changes outcomes.
- Safety and societal impacts:
- Effects of MIR and repeated-data regimes on generation safety, bias, and toxicity; whether masking interacts with safety fine-tuning or reduces harmful memorization of sensitive content.
- Reproducibility and variability:
- Expanded multi-seed analyses for the full N×U grid (not only select MIR vs baseline runs), including variance decomposition across seeds, data shuffles, and masking RNG, to bound uncertainty in fitted laws and reported gains.
Practical Applications
Immediate Applications
Below are concrete ways practitioners can use the paper’s findings today. Each item lists sectors, what to do, likely tools/workflows, and key assumptions or dependencies.
- Deploy masked-input regularization (MIR) in data-constrained pretraining
- Sectors: software, finance, healthcare, legal, education, government, defense
- What to do: Add an auxiliary masked-input next-token prediction loss to standard autoregressive (AR) pretraining when unique training data is small and compute is available. Keep the same decoder-only architecture and inference.
- Tools/workflows:
- Implement MIR in common training stacks (e.g., PyTorch + Hugging Face Transformers/DeepSpeed). For each batch, compute a second forward pass on randomly masked inputs and add λ·L(NTP(ẋ)) to the clean L(NTP(x)) objective.
- Use uniform masking ratios r ∼ Unif(r_min, r_max) per sequence; tune λ and r-range lightly after you tune weight decay, epochs, and LR.
- Track unique-token budgets and epochs in training logs (MLOps) to ensure the “data-constrained, compute-rich” assumption holds.
- Impact: Improves validation loss consistently from 72M–1.4B parameters in limited data settings; at 1.4B the paper reports downstream boosts (e.g., +10.2 points on BoolQ, +2.2 on SciQ). SoftQ-based analysis suggests MIR ≈ 1.3× more unique data at 200M–400M-token budgets.
- Assumptions/dependencies:
- Compute is not the bottleneck (MIR adds a second forward pass).
- Unique data are limited; effects shown up to 400M unique tokens and 1.4B parameters.
- Strong weight decay has already been tuned (see next item).
- Tune and increase weight decay for repeated-epoch pretraining
- Sectors: software, finance, healthcare, legal, education
- What to do: Substantially increase weight decay beyond “standard” values (e.g., >0.1) and co-tune with epochs and learning rate to prevent overfitting in multi-epoch training on small corpora.
- Tools/workflows:
- Integrate weight-decay grid search into hyperparameter sweeps per (model size, unique data) cell; pair with early stopping on validation loss.
- Apply the same strong weight decay to AR and masked-diffusion variants if you compare them.
- Impact: Large weight decay alone closes much of the AR vs. diffusion gap reported elsewhere and stabilizes multi-epoch training.
- Assumptions/dependencies:
- Results validated for decoder-only AR and masked diffusion models in the 72M–1.4B range; re-tune for other architectures/optimizers.
- Use SoftQ scaling law to plan training in data-constrained regimes
- Sectors: software, finance, healthcare, defense, government, labs (academia/industry)
- What to do: Fit the SoftQ law (five parameters) to your validation-loss grid across model sizes and unique-data budgets to forecast performance, pick model sizes, and decide when to acquire more data vs. scale parameters/epochs.
- Tools/workflows:
- Collect a small grid of (N, U, L) points using your data and recipe; fit SoftQ with a Huber-loss objective on log-loss residuals (as in the paper).
- Use the fitted law for what-if analyses: “How much more unique data equals MIR?” “At what N does more epochs stop helping?” “Should we buy data or rent GPUs?”
- Impact: Better in-sample and out-of-sample fit than Chinchilla, Quanta, and Muennighoff in the paper and an independent dataset; captures the observed “fan-out” where the benefit of more unique data grows with model size.
- Assumptions/dependencies:
- Fit is recipe- and data-distribution-specific; re-fit when changing domains, tokenization, or optimizers.
- Applies when repeated data (multi-epoch) is used and data—not compute—is the binding constraint.
- Improve small-/mid-scale domain models where proprietary data are scarce
- Sectors: finance (research notes, filings), healthcare (EHR notes, guidelines), legal (briefs, memos), software (internal code), education (course materials)
- What to do: For orgs with limited domain text, adopt strong weight decay + MIR during pretraining/further pretraining on proprietary corpora to improve generalization without changing inference behavior.
- Tools/workflows:
- For internal code models (Stack-like data), reuse DCLM-tuned MIR hyperparameters as a starting point; expect gains across model sizes.
- Add privacy audits: MIR can reduce reliance on context-specific artifacts and may reduce memorization risk, but formal privacy guarantees are not established.
- Impact: Higher data efficiency reduces pressure to scrape larger corpora; can raise downstream task accuracy with the same unique data budget.
- Assumptions/dependencies:
- Domain shift can affect gains; validate on internal benchmarks.
- Regulatory and privacy constraints still apply; MIR is a training regularizer, not a privacy mechanism.
- Benchmark and academic study design under fixed-data budgets
- Sectors: academia, evaluation organizations, open-source communities
- What to do: Use the paper’s compute-rich, data-constrained protocol for method comparisons; report unique-token budgets, number of epochs, and regularization settings. Fit SoftQ to summarize results.
- Tools/workflows:
- Adopt fixed U (e.g., 100M/200M/400M) benchmark suites; compare methods by best validation loss with unrestricted epochs and tuned weight decay.
- Publish fitted SoftQ parameters alongside raw curves for reproducibility and planning.
- Impact: Fairer comparisons when data is the binding resource; clearer guidance for low-resource settings and low compute labs.
- Assumptions/dependencies:
- Requires careful hyperparameter tuning per (N, U) cell; consider sharing tuned configs to lower entry barriers.
- MLOps enhancements for data-constrained training
- Sectors: software/ML platforms
- What to do: Extend training pipelines to log and enforce unique-token counts, epoch counts, repeated-data ratios, and regularization settings; provide MIR “on/off” and scheduler toggles.
- Tools/workflows:
- Add dataset fingerprinting to track U and avoid silent changes in data budgets.
- Add automated sweeps over weight decay and MIR λ; schedule more masked batches if validation overfitting indicators rise.
- Impact: Operationalizes the paper’s recipe at scale; reduces wasted compute from misspecified recipes.
- Assumptions/dependencies:
- Requires data cataloging and MLOps integration; minor training-time overhead for masking.
Long-Term Applications
These applications will benefit from further research, scaling, broader validation, or ecosystem support.
- Data–compute portfolio optimization and ROI calculators (SoftQ-driven)
- Sectors: enterprise AI, cloud providers, regulators
- What it could be: Productized planners that ingest budgets for compute and data acquisition/licensing and recommend optimal (N, epochs, U) under data-constrained assumptions; quantify “data-equivalent” value of new training tricks (e.g., MIR, augmentation).
- Dependencies/assumptions:
- Robust SoftQ fits across diverse architectures (MoE, long-context, multi-modal) and optimizers.
- Interfaces to procurement and legal/licensing systems for data cost modeling.
- Privacy- and safety-aware regularization for repeated data
- Sectors: healthcare, finance, government, consumer AI
- What it could be: Combine MIR with memorization audits, differential privacy, or selective masking policies (e.g., heavier masking over sensitive spans) to reduce leakage under multi-epoch training.
- Dependencies/assumptions:
- Need empirical and theoretical evidence that MIR reduces memorization risks in practice; integrate with privacy accounting.
- Adaptive masking curricula and automated regularization controllers
- Sectors: software tooling, research labs
- What it could be: Controllers that adjust mask ratios, λ, and weight decay online based on overfitting signals (loss gap between train/val, calibration, or token-level difficulty distributions).
- Dependencies/assumptions:
- Requires reliable online diagnostics; more research on convergence, stability, and compute overhead.
- Domain- and language-specific small models for low-resource settings
- Sectors: public sector, NGOs, education, cultural preservation
- What it could be: Robust small LMs trained on limited corpora in under-resourced languages or specialized domains using strong weight decay + MIR, guided by SoftQ to choose (N, U).
- Dependencies/assumptions:
- Broader validation beyond English/web and code (shown here) to diverse scripts, morphology, and orthographies.
- Local compute availability for increased training passes.
- Training-policy standards and reporting requirements
- Sectors: policy/regulatory bodies, standards organizations
- What it could be: Guidelines mandating disclosure of unique-token budgets, number of epochs, repetition ratios, and regularization settings for transparency, safety, and sustainability assessments.
- Dependencies/assumptions:
- Community consensus on metrics; alignment with ongoing AI policy frameworks and environmental reporting.
- Sustainability and cost optimization under limited new data
- Sectors: energy, cloud computing, enterprise AI
- What it could be: Use SoftQ to reduce “wasted” scaling runs by forecasting diminishing returns; weigh MIR-like regularizers (more compute per step) against data acquisition and curation costs to minimize total carbon/cost footprint.
- Dependencies/assumptions:
- High-quality lifecycle cost and energy models; validation at larger scales and with modern accelerator stacks.
- Cross-architecture generalization of SoftQ and MIR
- Sectors: multi-modal AI, speech, robotics
- What it could be: Extend the coupled law and masking-auxiliary losses to vision-language, speech, and action models where unique domain data are scarce; e.g., masked-sensor inputs for policy learning under limited demonstrations.
- Dependencies/assumptions:
- Architectural and task adaptations; empirical confirmation that coupling and MIR-like objectives hold across modalities.
- Tooling in training frameworks: “Regularization-as-a-feature”
- Sectors: ML platforms, open-source ecosystems
- What it could be: First-class MIR modules with schedulers, token-level diagnostics, and SoftQ fit utilities in frameworks; AutoML components that propose (weight decay, λ, mask ranges) given U, N, and target loss.
- Dependencies/assumptions:
- Community uptake; benchmark suites to validate out-of-the-box defaults across datasets.
- Data acquisition strategy design with synthetic data interplay
- Sectors: industry R&D, data vendors
- What it could be: Use SoftQ to compare MIR gains vs. various synthetic data generation schemes (e.g., paraphrasing, distillation) for fixed budgets; select blends that maximize unique “skill” coverage per cost.
- Dependencies/assumptions:
- Reliable estimates of “unique information” in synthetic data; guardrails against compounding biases.
- Risk management and governance for repeated data regimes
- Sectors: compliance, risk offices
- What it could be: Governance frameworks recognizing that data—not compute—is often the scarce resource; controls on repetition counts, overfitting indicators, and regularization knobs with escalation workflows.
- Dependencies/assumptions:
- Organizational processes and audit trails; agreed-upon thresholds for “repetition risk.”
Notes on feasibility and boundaries across applications:
- Scope validated in the paper: decoder-only AR models, 72M–1.4B parameters, 100M–400M unique tokens, natural language and code datasets; additional domains and larger scales require re-validation.
- MIR adds training compute (two forward passes per batch) but preserves inference behavior and architecture.
- SoftQ must be re-fit when recipes, optimizers, tokenizers, or data distributions change; its “data-equivalence” estimates depend on fit quality.
- Strong weight decay is a key dependency; failing to re-tune it can obscure MIR benefits or comparisons with other objectives.
Glossary
- AdamW: An optimizer that decouples weight decay from the gradient-based update used in Adam. "AdamW optimizer is used for all experiments."
- AIC: Akaike Information Criterion; a model selection metric based on goodness of fit with a penalty for the number of parameters. "AIC: "
- any-order prediction: A diffusion-style training property where tokens can be predicted in arbitrary order rather than left-to-right. "any-order prediction, dense denoising supervision, and implicit Monte Carlo augmentation."
- autoregressive (AR): A modeling approach that predicts each token conditioned on all previous tokens in sequence order. "Autoregressive models predict tokens from left to right."
- Bernoulli random variable: A binary random variable that takes value 1 with probability p and 0 otherwise. "a Bernoulli random variable to decide whether to mask the token or not"
- Chinchilla scaling law: An additive scaling law relating loss to model size and data that assumes separable parameter and data contributions. "The Chinchilla scaling law decomposes loss into irreducible entropy, finite-parameter error, and finite-data error:"
- compute-optimal scaling laws: Laws that choose model and data sizes to minimize loss under a fixed compute budget. "Classical compute-optimal scaling laws \citep{kaplan2020scaling,hoffmann2022training} model evaluation loss as a function of model size and training-token budget."
- context-specific noise model: A theoretical setup where parts of the input context enable memorization that harms generalization. "We provide intuition for how masking improves validation loss by analyzing a toy context-specific noise model in Appendix \ref{sec:theory}."
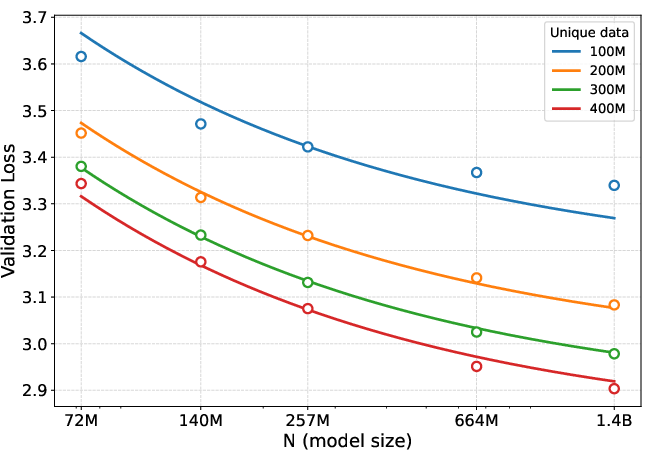
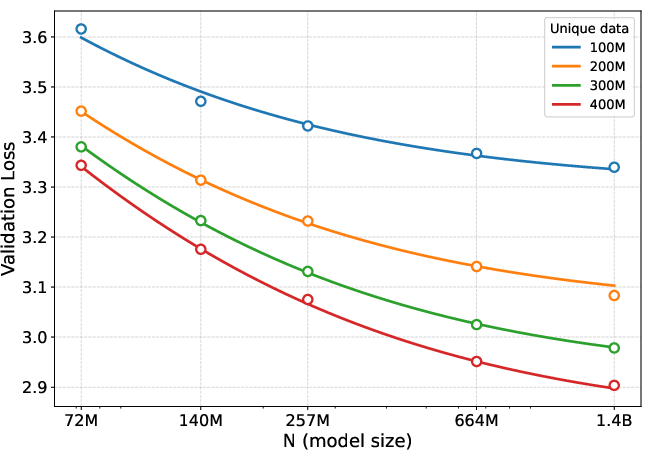
- DataComp-LM (DCLM): A large-scale natural language dataset used for pretraining and evaluation. "On DataComp-LM (DCLM) dataset \citep{dclm24} with unique training tokens, MIR improves validation loss"
- data-constrained, compute-rich pretraining: A regime where unique data is limited but compute is plentiful, enabling many epochs and larger models. "In data-constrained, compute-rich pretraining, the unique-token budget is fixed or bounded, and is unbounded."
- decoder-only transformer: A transformer architecture that uses only the decoder stack for autoregressive generation. "For a standard dense decoder-only transformer trained with next-token prediction, the training compute is approximately"
- dense denoising supervision: A training signal where many tokens are corrupted and predicted, providing rich supervision across positions. "any-order prediction, dense denoising supervision, and implicit Monte Carlo augmentation."
- effective data size: A transformed count of training tokens that accounts for diminishing returns from repeated data. "replacing raw data and parameter counts with effective model size and effective data size that saturate under repeated data and excess parameters."
- effective model size: A transformed parameter count that reflects diminishing returns when capacity exceeds available data. "replacing raw data and parameter counts with effective model size and effective data size that saturate under repeated data and excess parameters."
- fan-out (empirical fan-out): The widening loss gap across data budgets as model size increases, evidencing model–data coupling. "the empirical fan-out: the penalty from limited unique data grows with model size."
- Huber loss: A robust loss function that is quadratic near zero and linear for large residuals, used for fitting. "Huber loss with threshold on log-loss residuals."
- implicit Monte Carlo augmentation: Stochastic corruption during training that effectively augments data without explicit new samples. "any-order prediction, dense denoising supervision, and implicit Monte Carlo augmentation."
- MAE: Mean Absolute Error; an average of absolute prediction errors used to assess fit. "We report RMSE and MAE on the raw validation-loss scale"
- masked diffusion LLM (dLLM): A diffusion-based LLM that learns to predict randomly masked tokens using denoising steps. "masked diffusion LLMs (dLLMs)"
- masked-input regularization (MIR): An auxiliary training objective adding next-token prediction on randomly masked inputs to regularize AR training. "masked-input regularization (MIR), an auxiliary next-token prediction loss on randomly masked inputs."
- Muennighoff-style law: A scaling formulation that augments Chinchilla with effective resources and additional decay parameters. "Muennighoff-style \citep{niklas2023} laws"
- negative evidence lower bound: A variational objective whose negative can upper-bound the negative log-likelihood; used to evaluate diffusion LMs. "negative evidence lower bound (an upper bound on the negative log-likelihood)"
- negative log-likelihood: The standard probabilistic training or evaluation loss for generative models, equivalent to cross-entropy. "while AR loss is exact negative log-likelihood"
- next-token prediction (NTP): The objective of predicting the next token in sequence given previous tokens. "standard next-token prediction loss"
- parameter-limited regime: A regime where model capacity is the bottleneck, leading to diminished gains from extra data. "parameter-limited and data-limited regimes"
- perplexity: An exponentiated cross-entropy metric assessing how well a model predicts text. "Lambada (perplexity)"
- Quanta scaling law: A coupled scaling law derived from a skill-learning model that mixes parameter and data effects via a power-law form. "yields the Quanta scaling law:"
- RMSE: Root Mean Squared Error; the square root of average squared errors used to evaluate model fit. "We report RMSE and MAE on the raw validation-loss scale"
- skill-learning view of scaling laws: A perspective modeling learning as acquiring discrete skills with power-law frequency, informing coupled scaling. "motivated by the skill-learning view of scaling laws"
- soft bottleneck: A smooth minimum-like combination that couples two limiting factors (model size and data) in a single law. "through a soft bottleneck"
- SoftQ scaling law: A five-parameter coupled scaling law that smoothly blends parameter- and data-limited regimes and fits data-constrained settings. "We propose the SoftQ scaling law"
- Stack-V2: A code-heavy corpus used to test transfer of pretraining methods beyond natural language. "Stack-V2 dataset \citep{stackv224}"
- validation-loss envelope: The best-achievable validation loss over hyperparameters for a given model and data size. "define the optimized validation-loss envelope"
- weight decay: L2-style regularization applied via parameter decay during optimization to reduce overfitting. "large weight decay is critical for preventing overfitting."
Collections
Sign up for free to add this paper to one or more collections.

