- The paper presents a novel scaling law linking repetition factors to overfitting thresholds, supported by over 2,000 full-scale pretraining runs.
- It demonstrates that optimal target data repetition can be as high as 15–20 times without overfitting, thanks to the regularization effect of abundant generic data.
- The study establishes a principled framework for predicting optimal mixture configurations and target weights, transforming heuristic methods into a predictive science.
Scaling Laws for Mixture Pretraining Under Data Constraints
Introduction and Motivation
As LLMs continue to scale, effective strategies for pretraining under data-limited conditions have become paramount, especially for low-resource languages, niche domains, or highly curated datasets, where the volume of unique data is inherently capped. The standard approach in these scenarios is to combine the scarce target-domain data with abundant generic (usually English or general web) data in a pretraining mixture. This practice introduces a critical trade-off absent in single-domain training: excessive repetition of the limited domain can trigger overfitting and memorization, while under-weighting it starves the model of vital domain-specific signal. Determining the optimal repetition of the target data in such mixtures therefore becomes a central operational question in mixture pretraining.
This paper, "Scaling Laws for Mixture Pretraining Under Data Constraints" (2605.12715), presents a systematic empirical and theoretical investigation into the interplay among model scaling, target/generic data mixture ratios, and repetition factors in this data-constrained regime. Leveraging over 2,000 full-scale pretraining runs across diverse datasets (multilingual, multi-domain, and quality-filtered), the authors provide both empirical regularities and a repetition-aware scaling law that prescribes optimal mixture configurations for domain-constrained pretraining—thereby shifting mixture design from ad hoc heuristics to principled, predictable science.
Empirical Study: Repetition Dynamics in Mixture Pretraining
The study's experimental design encompasses settings where target data might be: (i) a low-resource language (e.g., German, French, Swahili data at various pool sizes), (ii) domain-specific corpora (OpenWebMath, scientific literature, Wikipedia), or (iii) highly quality-filtered subsets. For each, target data of size Dtarget is mixed into a larger generic corpus via a tunable mixture weight h, controlling the repetition factor r (number of times each target token is encountered):
r=h⋅Dtotal/Dtarget
One of the core empirical findings is that mixture pretraining can tolerate far greater repetition of target-domain data than single-source regimes, due to the regularizing effect of generic data. Repetition up to 15–20 times can be optimal—substantially higher than the 4-epoch rule commonly cited for monolithic data-constrained pretraining [muennighoff2023scaling].
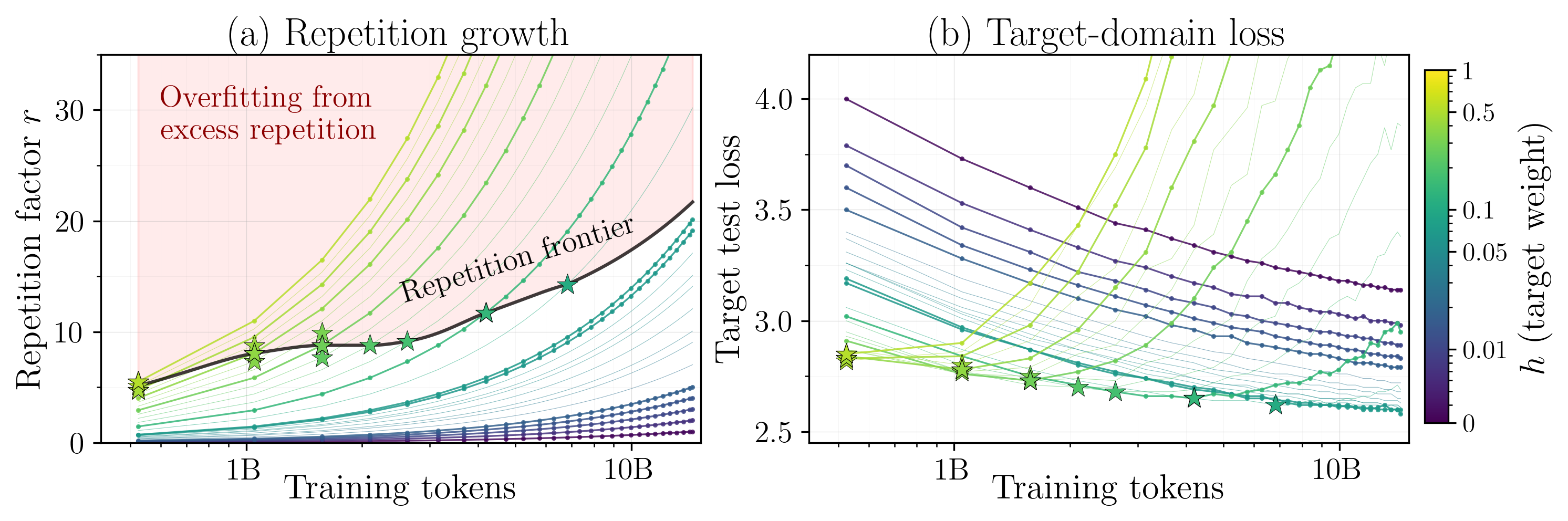
Figure 1: Repetition factor r and target loss dynamics as German data is repeated within a mixture—loss increases sharply beyond an optimal repetition frontier, with onset marked by stars.
Strong regularities are observed across all experimental conditions:
Notably, mixture training with abundant generic data ensures continuous learning and sustains utility from repeated target tokens even in the high-repetition regime.
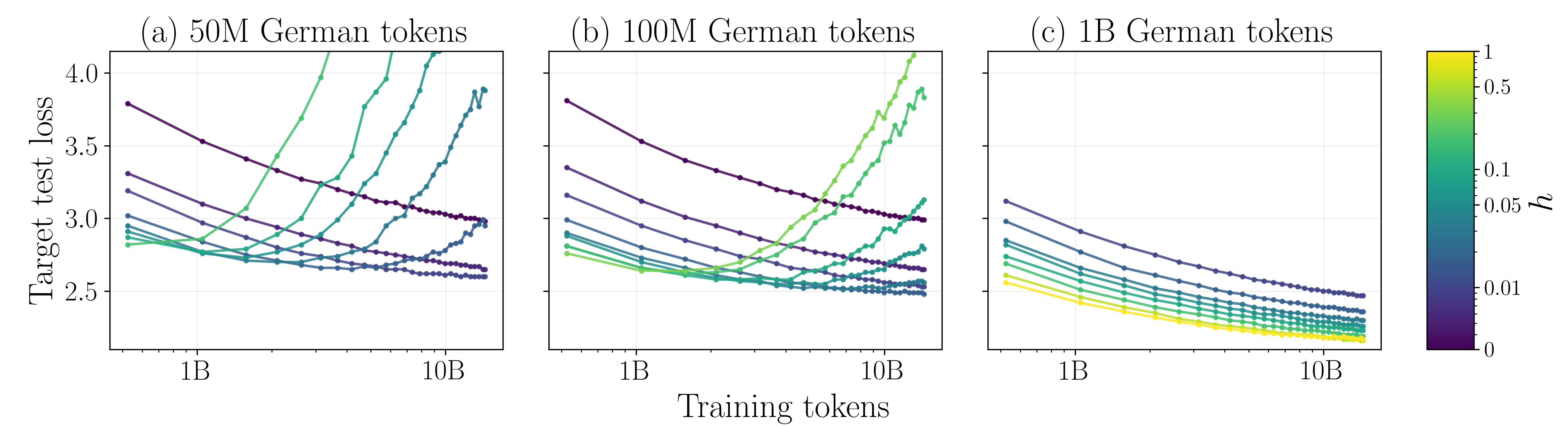
Figure 3: Validation loss curves for varying data budgets and mixture weights, showcasing the U-shaped loss dynamics as repetition increases.
Quality-Filtered Mixtures: Quantity vs. Quality
The authors extend their analysis to quality-filtered domains, where the practitioner can trade off data pool size against per-token quality by adjusting quality thresholds. The results show that while excessively narrow high-quality slices are quickly saturated by repetition, slightly broadening the filter to larger but marginally lower-quality sets almost always prolongs improvement and delivers optimal performance for most compute budgets.

Figure 4: Loss curves for inclusive quality bands. Broader filters enable higher target mixture weights without overfitting, confirming that sacrificing some per-token quality for increased diversity is preferable in data-constrained regimes.
This phenomenon exhibits clear scale dependence: with extremely large training budgets or pool sizes, pure quality regains its dominance, otherwise the repetition penalty of narrow bands outweighs the benefit of higher per-token quality.
Repetition-Aware Scaling Law
To formalize the empirical dynamics, the authors introduce a repetition-aware scaling law, extending the Chinchilla paradigm, but accounting for (i) saturating contributions from repeated target tokens, and (ii) the regularization effect from always-fresh generic data. The core innovation is the effective data computation:
h0
where h1 models the diminishing return from repeated target data using a saturating exponential h2, a function of the repetition factor. The final form for target-domain loss is:
h3
for fixed model size h4 (a multi-size version with explicit model scaling terms is also given). This law enables efficient mixture configuration without the need for expensive grid searches, as the optimal h5 for a given compute and pool size is found by simple minimization over h6.
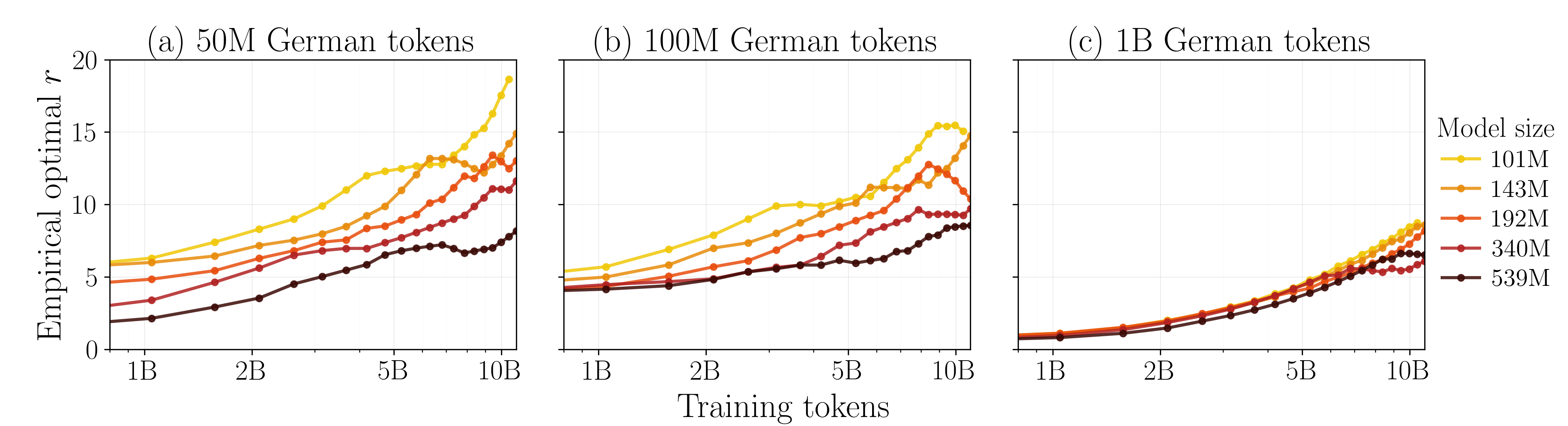
Empirically, the scaling law exhibits strong predictive power, outperforming baseline laws that either ignore repetitions or do not distinguish domain structure. For test splits across languages and domains, weighted h7 values are consistently high (e.g., 0.95 for German, 0.88 for mathematics), highlighting both regularity and transferability.
Furthermore, the scaling law accurately predicts the optimal repetition factors and the corresponding target mixture weights required to maximize target-domain performance:
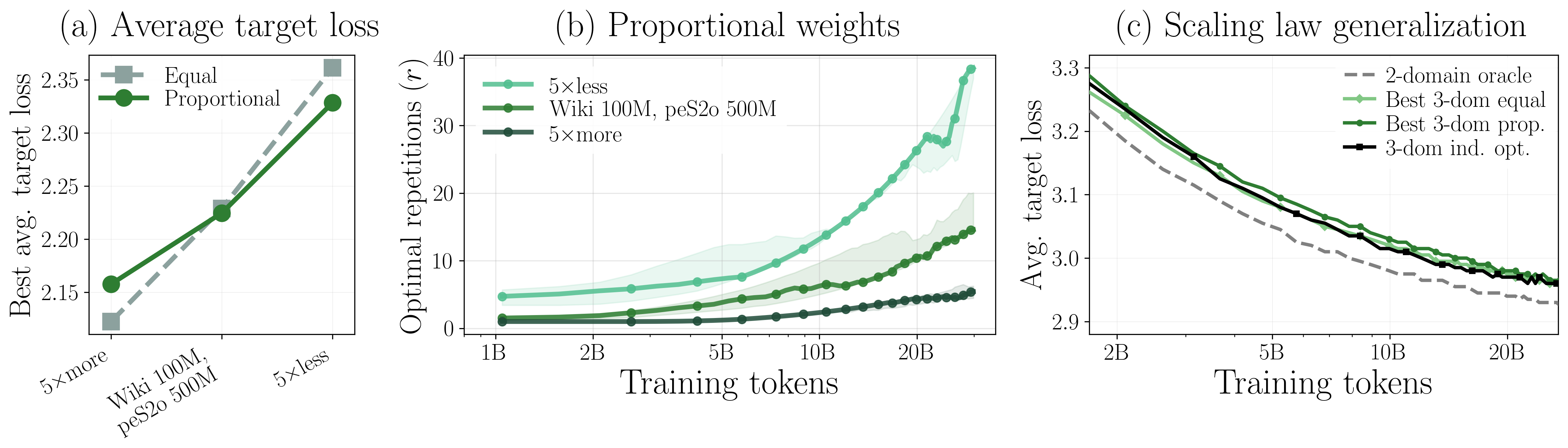
Figure 5: Predicted versus empirical optimal repetition h8—the scaling law closely tracks the empirical optimum across training budgets.
Extension to Multi-Domain Constrained Mixtures
The framework is generalized to mixtures with multiple constrained domains, e.g., jointly limited Wikipedia and scientific paper corpora mixed with generic data. The experiments demonstrate:
- Proportional weighting by pool size is favored in extremely data-limited scenarios, while equal weighting may suffice when all domains have large pool sizes.
- Optimal h9 per domain is robust to moderate misspecification; the performance landscape is broad, so approximate knowledge yields near-optimal results.
- The two-domain scaling law extrapolates: independently optimizing repetition for each constrained domain via the scaling law consistently outperforms naive grid search over proportional mixture weights.
(Figure 5, panel c)
Figure 5: Independently predicted optimal repetitions for multiple domains deliver better performance than grid-searched proportional weighting.
Practical and Theoretical Implications
From a practical standpoint, this work eliminates the need for practitioners to empirically sweep mixture ratios for every possible training budget, target domain, or model scale under severe data constraints. By fitting the scaling law at small scales, one can predict optimal configurations for larger deployments, aiding project planning in the presence of low-resource domains.
Theoretically, the results clarify why mixture training allows much higher repetitions than single-source data-constrained training, attributing this not to implicit model regularization, but the explicit presence of a never-repeating generic domain. This directly impacts the effective planning of mixtures for new LLMs, especially in languages or domains with limited resources, and provides a framework for thinking about domain mixture design under explicit compute and data pool constraints.
Furthermore, the scale dependence of the quality-vs.-quantity crossover in quality-filtered experiments formalizes the practical lore that, for a given budget, the optimal filtering threshold is dictated by the expected saturation point of the available data—a process now amenable to principled prediction.
Future Directions
The scaling law’s predictive validity in the 100M–800M parameter regime has been demonstrated, but as LLMs scale to tens or hundreds of billions of parameters, further empirical confirmation will be necessary to evaluate its extrapolation. Additionally, potential interactions with training dynamics (e.g., optimizer choice, scheduling, architecture variants) and extensions to more complex mixture compositions (beyond two or a few domains) warrant investigation.
Integrating synthetic data or data augmentation/rephrasing—emerging as alternative solutions for data constraints—could in principle be modeled within this framework as effective increases in r0, but only if their impact on target loss is isomorphic to additional unique data.
Conclusion
This paper provides a comprehensive exploration of mixture pretraining under realistic data constraints, establishing empirical and theoretical foundations for optimal mixture design. The central finding is that, in mixtures with abundant generic data, optimal repetition of constrained target sets is much higher than previously assumed, and can be precisely predicted via a simple scaling law that accounts for diminishing utility from repeated exposure and the unbounded regularization of generic data. This framework equips researchers and engineers with robust, evidence-backed recipes for pretraining LLMs in low-resource domains—transforming mixture configuration from art to science.