Scaling Behavior of Discrete Diffusion Language Models
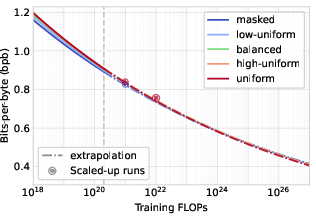
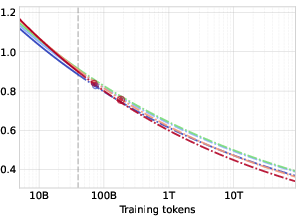
Abstract: Modern LLM pre-training consumes vast amounts of compute and training data, making the scaling behavior, or scaling laws, of different models a key distinguishing factor. Discrete diffusion LLMs (DLMs) have been proposed as an alternative to autoregressive LLMs (ALMs). However, their scaling behavior has not yet been fully explored, with prior work suggesting that they require more data and compute to match the performance of ALMs. We study the scaling behavior of DLMs on different noise types by smoothly interpolating between masked and uniform diffusion while paying close attention to crucial hyperparameters such as batch size and learning rate. Our experiments reveal that the scaling behavior of DLMs strongly depends on the noise type and is considerably different from ALMs. While all noise types converge to similar loss values in compute-bound scaling, we find that uniform diffusion requires more parameters and less data for compute-efficient training compared to masked diffusion, making them a promising candidate in data-bound settings. We scale our uniform diffusion model up to 10B parameters trained for $10{22}$ FLOPs, confirming the predicted scaling behavior and making it the largest publicly known uniform diffusion model to date.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper studies a different way to train LLMs called “discrete diffusion,” and compares it to the common “autoregressive” approach used in many chatbots today. The goal is to understand how these diffusion models behave as you make them bigger, train them longer, or change the amount of data and compute you use — this pattern is called “scaling behavior” or “scaling laws.”
Why this matters: Training huge LLMs is expensive. Knowing in advance how a model’s performance changes with more compute or data helps researchers choose the best model size, batch size, and learning rate, and avoid wasting resources.
Key Questions
The paper asks a few big, easy-to-understand questions:
- If we keep increasing compute and data, do discrete diffusion LLMs (DLMs) get better as quickly as autoregressive models (ALMs)?
- Does the kind of “noise” used during diffusion (masked vs uniform vs a mix of both) change how well these models scale?
- What are good rules-of-thumb for picking batch size and learning rate at different training scales?
- Can we predict the best balance of model size and dataset size for a given compute budget?
- Do results hold when we actually scale up to very large models (billions of parameters)?
How They Did It (Methods, in simple terms)
Think of text generation like cleaning up a messy sentence:
- Autoregressive models write one word at a time from left to right, never going back to fix earlier words.
- Diffusion models start with a fully “noisy” sentence (lots of random tokens) and repeatedly clean it up over many steps. They can change any token at any step, which lets them update earlier words and generate many tokens in parallel.
The paper compares three kinds of noise used during diffusion:
- Masked diffusion: some words are hidden (masked), and the model learns to fill them back in.
- Uniform diffusion: words are replaced with random tokens from the vocabulary; the model must detect which tokens are noise and fix them.
- Hybrid diffusion: a smooth mix between masked and uniform, controlled by how “noisy” things are.
To study scaling fairly, they:
- Reframe the math in terms of “signal-to-noise ratio” (SNR), which is a simple measure of how much real information vs noise is present. Using SNR makes the diffusion process easier to compare across noise types and matches how continuous diffusion models are often analyzed.
- Use a shared framework (called GIDD) so different diffusion types can be trained and measured in the same way.
- Run lots of experiments across different model sizes (from ~25M to ~570M parameters), batch sizes, and training lengths, carefully tuning learning rates. Then they fit scaling laws — concise rules that predict the best model size and dataset size for a given compute budget.
- Train a tokenizer and a Transformer-based model on a large web dataset, similar to how big LLMs are usually trained.
- Skip the usual “learning rate annealing” (gradually lowering the learning rate at the end) while estimating scaling laws to make experiments manageable. They later test annealing separately and show it gives a small, consistent improvement without changing the best settings.
Simple definitions to help:
- Batch size: how many tokens or sequences you process at once.
- Learning rate: how big a step the model takes when it updates its knowledge.
- Compute-bound: you’re limited by how much total computer work (FLOPs) you can do.
- Data-bound: you’re limited by how many training tokens (data) you have.
- FLOPs: a measure of the total number of basic math operations a training run uses.
- ELBO (a training score they measure): lower is better; it estimates how well the model fits the data.
Main Findings and Why They’re Important
- All noise types are similar when compute is the main limit. In compute-bound settings, masked, uniform, and hybrid diffusion reach roughly similar loss values at scale. This means diffusion models don’t fall behind autoregressive ones just because of the noise choice when you have plenty of compute.
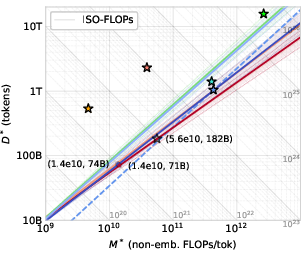
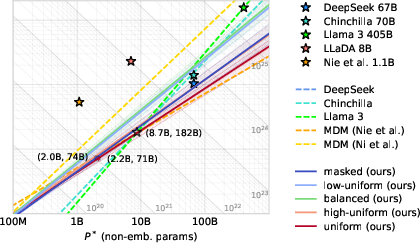
- Uniform diffusion wants bigger models and less data at compute-optimality. Compared to masked diffusion, uniform diffusion works best when you scale the number of parameters more and use fewer training tokens. That’s promising for real-world scenarios where high-quality data is limited but compute is available.
- Better “token efficiency.” Uniform diffusion tends to be more token-efficient (it needs fewer data tokens) when you aim for the best performance per unit of compute.
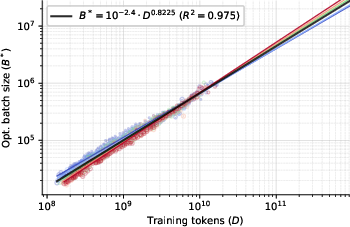
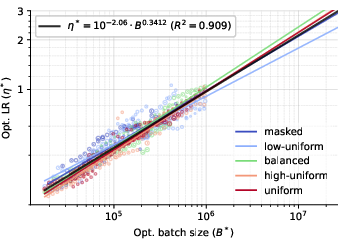
- Batch size and learning rate are predictable.
- The optimal batch size grows almost linearly with the total number of training tokens, and doesn’t depend much on model size or noise type.
- The optimal learning rate mainly depends on the (optimal) batch size and not strongly on the model size or noise type.
- These patterns make planning large training runs simpler and more reliable.
- No early saturation in batch size. Unlike some autoregressive setups where increasing batch size stops helping beyond a point (“critical batch size”), diffusion models didn’t show saturation in the tested range, suggesting you can use larger batches effectively.
- Annealing gives a small, constant boost. Lowering the learning rate at the end of training (annealing) improves loss by about 2.45% consistently but does not change what batch size or learning rate is best. So you can estimate scaling laws without annealing and add it later for a small bonus.
- Big models match predictions. They trained a uniform diffusion model with 10 billion parameters for a huge compute budget (about 1022 FLOPs). Its performance followed the predicted scaling laws closely and was competitive with trends reported for large autoregressive models. The performance gap between masked and uniform diffusion shrinks as models get bigger.
In short: Diffusion LLMs scale well. Uniform diffusion — even if harder at small scale — becomes a strong choice at large scale, especially when data is tight but compute is plentiful.
Implications and Potential Impact
- Practical training guidance: The paper offers clear, data-backed rules for choosing batch size and learning rate across scales. That helps teams plan large training runs more confidently.
- Competitive with today’s standard: Diffusion models, especially uniform diffusion, can compete with or potentially surpass autoregressive models at very large scales.
- More flexible generation: Because diffusion can update any token at any step, these models can generate multiple tokens in parallel and revise earlier mistakes — helpful for faster, more accurate text generation.
- Good for data-bound scenarios: If you can’t get more high-quality data but you have compute, uniform diffusion’s parameter-heavy scaling is a great fit.
- Open resources: The authors released code and models, which makes it easier for others to test and build on these ideas.
Overall, this work suggests diffusion-based LLMs are a promising path for the next generation of LLMs: they can scale competitively, support parallel and revisable generation, and offer practical, predictable training rules that save time and money.
Knowledge Gaps
Below is a single, consolidated list of concrete knowledge gaps, limitations, and open questions that remain unresolved and could guide future research.
- Direct comparability of likelihood metrics: the paper’s “bpb” and ELBO-based losses are not directly comparable to ALM NLL/perplexity; establish matched tokenizers, datasets, and a calibrated bound-tightness protocol to compare DLMs vs ALMs on the same metric.
- ELBO bound tightness vs actual likelihood: quantify how the true NLL relates to the ELBO used in training and scaling law fitting, including the impact of using the unweighted ELBO surrogate on convergence, ranking of configurations, and downstream performance.
- Test-time compute and denoising steps T: systematically study how generation quality and throughput scale with the number of denoising steps, SNR schedule, and length N; identify compute–quality Pareto curves and optimal T at different model sizes.
- Parallel generation advantage: measure end-to-end inference throughput and latency (tokens/sec, wall-clock latency per sequence) of DLMs vs ALMs under realistic serving constraints (KV-cache usage, batch sizes, sequence lengths).
- Revision/self-correction capability: design and report controlled experiments quantifying DLMs’ ability to revise previously generated tokens (edit distance reduction, error correction rates) versus masked diffusion and ALMs.
- Dataset dependence of scaling coefficients: validate scaling laws across diverse corpora (quality-filtered web, code, math, multilingual) and quantify how data composition and cleanliness shift the M–D–L exponents.
- Vocabulary size effects: ablate vocabulary sizes (e.g., 32k, 65k, 131k) to quantify how token granularity affects DLM scaling behavior across noise types and whether larger vocabularies consistently benefit DLM training.
- Sequence length scaling: the main experiments use N=2048; analyze scaling of loss and optimal batch size across longer contexts (e.g., 8k–128k), including KV-caching implications for DLMs vs ALMs.
- Critical batch size for DLMs: locate and characterize the critical batch size regime (beyond 106 tokens/batch), its dependence on target loss, and its interaction with optimizer hyperparameters and precision modes.
- Robustness of the annealing “constant improvement” factor: the 2.45% gain was demonstrated on small models and extrapolated; validate across larger scales, different datasets, and schedules (cosine, linear, WSD) to confirm constancy.
- Optimizer and parameterization dependence: assess whether scaling laws and optimal hyperparameters hold under AdamW vs LaProp, μP vs CompleteP, different β2/ε values, and full-precision vs bfloat16 training.
- Architectural confounds: isolate the contribution of QK-norm, RMSNorm, attention logit soft-capping, and attention sinks to the observed scaling behavior via ablation, to ensure conclusions are attributable to the DLM objective rather than architecture stabilization tricks.
- Empirical verification of SNR invariance: beyond the theoretical reframing, test different importance sampling distributions over log-SNR and weighting schemes (including the chosen clipping range λ∈[−9,9]) to quantify training efficiency and model quality sensitivity.
- Hybrid mixing distribution design: only a=1 and discrete b values were explored; investigate continuous and learned mixing strategies (content-aware masking vs uniform), per-token/per-layer mixing, and adaptive schedules driven by validation signals.
- Anisotropic noise/diffusion forcing: quantify its impact on stability, convergence speed, scaling coefficients, and inference speed-ups for DLMs; determine optimal fraction of anisotropic samples and per-token noise distributions.
- Prior choices and latent state space: explore learned categorical priors or class-conditional priors for discrete diffusion, and evaluate their effect on ELBO tightness and scaling.
- Compute accounting and “M” proxy: verify the FLOPs-per-token proxy M=6P+12LDN for DLM training via profiling; assess sensitivity of scaling coefficients to alternative compute models (including embedding FLOPs and auxiliary operations).
- Memory and system constraints: the compute-optimal parameter-heavy scaling may be impractical under memory/network budgets; quantify training/serving memory footprints, communication overheads, and pipeline/sequence parallel efficiency for large DLMs.
- Long-horizon stability: scaling laws were validated up to 1022 FLOPs; probe whether exponents remain stable beyond this regime, whether non-power-law behavior emerges, and how irreducible loss behaves at extreme scale.
- Irreducible loss claims: directly estimate and compare the irreducible loss terms of masked vs uniform diffusion and ALMs on matched setups to substantiate the claim that DLMs have a smaller irreducible loss.
- Loss–task performance alignment: report systematic correlations between ELBO improvements and downstream NLP benchmarks (perplexity, QA, reasoning, code), including cases where ELBO gains do not translate to task gains.
- Sampling algorithms for discrete diffusion: benchmark alternative samplers (e.g., self-consistency, guided sampling, dynamic SNR schedules) for discrete state spaces, measuring quality, diversity, and compute trade-offs.
- Tokenizer–noise interaction: study how tokenization granularity interacts with masked vs uniform noise (e.g., subword fragmentation rates, token replacement patterns) and whether certain vocab designs favor particular noise types.
- Generalization to code/math and multilingual tasks: evaluate whether the reduced inductive bias of uniform diffusion hinders/helps domains that benefit from strong sequential dependencies; identify domain-specific noise schedules or architectural changes.
- Safety and alignment pipeline: analyze how diffusion pretraining interfaces with alignment methods (SFT, RLHF, DPO), whether objective mismatches arise, and whether revision capabilities affect safety (e.g., ease of prompt steering or jailbreak resilience).
- Effect of log-SNR clipping: ablate λ clipping bounds and their impact on training stability, gradient variance, and final ELBO; identify principled criteria for choosing clipping ranges.
- Iso-loss hyperbola relation: provide a theoretical explanation or derivation for the observed iso-loss relation between batch size and step count, and test its validity near the irreducible loss regime.
- Comparative head-to-head with ALMs: run matched compute/data/tokenizer experiments to quantify training efficiency (wall-clock, energy), throughput, and downstream performance to support claims of competitiveness at scale.
- Practical serving considerations: evaluate real-world serving scenarios (streaming generation, partial prompts with KV-caching, mixed lengths) to verify that DLMs’ theoretical benefits translate to operational gains.
Practical Applications
Immediate Applications
The following applications can be deployed now using the paper’s open-source code, released models, and training recipes.
- Training planning and MLOps optimization for LLM pretraining
- What to do: Use the provided scaling laws and hyperparameter rules-of-thumb to plan compute/data budgets and minimize ablation cost.
- Choose noise type by regime (uniform for data-bound, masked/hybrid for small-scale experiments).
- Set batch size ≈ training tokens0.82 and learning rate ≈ batch0.34 (assuming optimal batch size).
- Use the iso-loss step/batch trade-off curve to pick batch size vs steps for fixed loss/compute.
- Omit LR annealing during pretraining to speed iteration; optionally add a 20% cooldown at the end for ≈2.45% constant-factor improvement.
- Sectors: AI labs, cloud providers, enterprise ML teams, open-source communities.
- Tools/products/workflows: “Training budget planners” and “autotune” scripts; dashboards integrating the paper’s iso-FLOP planning and iso-loss hyperbola; CI pipelines with CompleteP parameterization and LaProp defaults.
- Assumptions/dependencies: Access to large-batch hardware and mixed-precision training; scaling coefficients can vary with data composition; ELBO/NLL trends must correlate with downstream metrics on your data.
- Data-limited domain model development with uniform diffusion
- What to do: In domains with limited text data (e.g., healthcare, legal, defense, specialized scientific corpora), select uniform diffusion and allocate more parameters with fewer training tokens for compute-optimal training.
- Sectors: Healthcare, finance, legal, manufacturing, scientific R&D, government.
- Tools/products/workflows: Domain-specific DLMs initialized from the released 3B/10B uniform diffusion checkpoints; adapters/LoRA for specialization; hybrid-noise schedules to balance stability and revisability.
- Assumptions/dependencies: Requires adequate compute to support larger parameter counts; benefit size may vary with corpus quality, tokenizer fit, and multilinguality.
- Parallel and revisable text generation in products
- What to do: Build generation features that update many tokens per step and allow global revision (e.g., whole-document edits, codebase refactors, translation that retroactively improves earlier segments).
- Sectors: Productivity suites, developer tools, customer support, creative writing, localization.
- Tools/products/workflows: DLM-based inference servers with multi-token denoising steps; user-facing “refine” and “self-correct” modes; iterative drafting workflows that revise earlier outputs.
- Assumptions/dependencies: Latency depends on number of denoising steps and sampling; product teams must tune step count vs quality and integrate prompt conditioning and KV-caching.
- KV-cache–friendly prompting and partial conditioning
- What to do: Use the paper’s training setup (masked prompt-to-completion attention, partial noise-free prefixes) to enable fast prompt-conditioned inference with caching.
- Sectors: Chatbots, search assistants, coding copilots, customer service.
- Tools/products/workflows: Inference serving pipelines that reuse prompt KV states; hybrid conditioning for long contexts.
- Assumptions/dependencies: Requires implementation of the paper’s attention masking and training augmentations; memory budget must accommodate larger models for uniform diffusion.
- High-throughput cluster utilization via large effective batch sizes
- What to do: Increase batch sizes toward ≈106 tokens without hitting the ALM-like critical batch size saturation; schedule training to maximize accelerator throughput.
- Sectors: Cloud/edge training providers, hyperscalers, enterprise clusters.
- Tools/products/workflows: Batch-size scaling policies tied to token budgets; parallelism strategies (DP/TP/PP) tuned for high-B regimes; memory-planned training layouts.
- Assumptions/dependencies: Hardware must support very large batches; stability benefits rely on CompleteP and LaProp defaults in the paper.
- SNR-based hybrid diffusion for controllable noise and revisability
- What to do: Adopt the SNR-parameterized hybrid mixing distribution to smoothly interpolate between masked and uniform noise during training and to enable token revision at inference.
- Sectors: Software, education, content creation, code generation.
- Tools/products/workflows: Training knobs (the b shift) to target “low-uniform,” “balanced,” or “high-uniform” regimes; per-product tuning for stability vs revisability.
- Assumptions/dependencies: Requires minor implementation effort (SNR reparameterization and derivative) and validation against your datasets.
- Diffusion forcing for flexible quality/speed trade-offs at inference
- What to do: Use per-token noise sampling to control anisotropic denoising, accelerating inference or targeting specific portions of a sequence for refinement.
- Sectors: Real-time assistants, streaming content generation, code tools.
- Tools/products/workflows: Inference modes that adjust noise levels dynamically across positions; UIs exposing “fast draft vs thorough revise.”
- Assumptions/dependencies: Gains depend on task and sampling strategy; careful testing of quality/latency trade-offs is needed.
- Research and education using unified GIDD-in-SNR
- What to do: Use the simplified, schedule-invariant ELBO and SNR framing to teach discrete diffusion and run standardized ablations across noise types.
- Sectors: Academia, training institutes, research labs.
- Tools/products/workflows: Coursework and reproducible labs with the released code; benchmark suites comparing masked, uniform, and hybrid setups.
- Assumptions/dependencies: Compute availability for students; focus is on ELBO/log-likelihood transferability to downstream tasks.
- Tokenization efficiency improvements with large-vocab BPE (131k)
- What to do: Adopt the released tokenizer to reduce sequence lengths and improve training and inference efficiency on web-scale data.
- Sectors: Multilingual NLP, web content processing, information retrieval.
- Tools/products/workflows: Retokenize corpora; reindex caches and datasets for fewer tokens per sample.
- Assumptions/dependencies: Compatibility with existing pipelines and multilingual coverage; retokenization costs.
Long-Term Applications
These applications require additional scaling, engineering, or validation beyond the paper’s current scope.
- Next-generation foundation models that rival or surpass ALMs at scale
- Vision: Train large uniform/hybrid DLMs leveraging the paper’s compute-optimal, parameter-heavy scaling and potentially smaller irreducible loss, closing or exceeding ALM performance.
- Sectors: Cross-industry (general AI), cloud services, platform vendors.
- Tools/products/workflows: Training runs at ≥1023–1024 FLOPs; improved sampling algorithms; pretraining+cooldown curricula with high-quality data phases.
- Assumptions/dependencies: Substantial compute; downstream parity with ALMs must be demonstrated across tasks and safety evaluations.
- Low-latency, long-output generation via parallel decoding
- Vision: Achieve latency largely independent of output length by holding denoising steps small relative to sequence length and refining in parallel.
- Sectors: Mobile assistants, edge robotics, real-time translation, gaming.
- Tools/products/workflows: Hardware-aware schedulers; custom kernels optimized for batched denoising updates; adaptive step controllers.
- Assumptions/dependencies: Requires algorithmic advances for fast sampling and hardware support; careful tuning to maintain quality.
- Iterative self-revision and deliberation for safety-critical applications
- Vision: Build deliberation loops where the model globally revises outputs to reduce factual errors and improve consistency.
- Sectors: Healthcare (clinical summarization/checks), finance (reporting/compliance), legal (contract drafting), public policy (briefs).
- Tools/products/workflows: Multi-pass refinement pipelines with constraints and verification steps; integration with retrieval and tool-use.
- Assumptions/dependencies: Rigorous evaluation frameworks for safety/robustness; governance to manage residual risks.
- Multimodal discrete diffusion for text+code+structured data
- Vision: Extend SNR-parameterized GIDD to code ASTs, speech tokens, tabular tokens, and robotic action sequences, exploiting revisability across modalities.
- Sectors: Robotics, software engineering, media, analytics.
- Tools/products/workflows: Unified tokenizers and vocabularies; cross-modal denoising schedules; joint training recipes.
- Assumptions/dependencies: Data availability and tokenization standards; new benchmarks; significant engineering and modeling research.
- Personalized assistants from small private datasets
- Vision: Leverage the data-efficiency of uniform diffusion to build personalized models with limited user data while scaling parameters compute-optimally.
- Sectors: Consumer productivity, enterprise knowledge workers, education.
- Tools/products/workflows: Privacy-preserving fine-tuning with adapters; on-device or federated training; policy-driven data use.
- Assumptions/dependencies: Privacy guarantees, device capabilities, and user consent; validation of personalization quality.
- Automated training controllers embedded in ML frameworks
- Vision: “Autopilot” controllers that set batch size, learning rate, and annealing strategy from token budgets and desired loss, using the paper’s scaling relations and iso-loss curves.
- Sectors: MLOps platforms, AutoML, cloud training services.
- Tools/products/workflows: Plugins for PyTorch/JAX frameworks; dashboard integration with cluster schedulers; feedback loops from live training signals.
- Assumptions/dependencies: Robustness across datasets/domains; continual recalibration as models and data evolve.
- Compute and data policy guidance for institutions and regulators
- Vision: Use parameter-heavy, token-efficient scaling guidance to inform investments (compute vs dataset acquisition) and environmental reporting.
- Sectors: Government, NGOs, research consortia, standards bodies.
- Tools/products/workflows: Policy calculators for FLOPs vs token plans; LCA (life-cycle analysis) adaptations for DLMs vs ALMs.
- Assumptions/dependencies: Empirical validation across diverse datasets; consensus on metrics beyond ELBO (downstream performance, safety).
- Energy-efficient pretraining pathways
- Vision: If fewer tokens suffice under compute-optimal DLM scaling, total energy per model could drop despite larger parameter counts, with the right hardware and scheduling.
- Sectors: Energy-conscious AI, green computing initiatives.
- Tools/products/workflows: Co-design with hardware vendors; scheduling to minimize idle energy and maximize batch efficiency.
- Assumptions/dependencies: Net energy depends on model size, step count, and hardware efficiency; requires rigorous end-to-end measurement.
Glossary
- Adam’s β2 parameter: The second-moment decay hyperparameter in Adam/Adam-like optimizers that affects gradient variance estimation and interacts with batch size. "Another hyperparameter that is known to have optimal values depending on the batch size is Adam's parameter."
- Anisotropic noise: Noise levels that vary across tokens in a sequence rather than being globally shared, allowing per-token noise sampling. "Diffusion Forcing \citep{chen2024diffusion} proposes to sample noise levels independent for each tokens, resulting in anisotropic noise."
- Attention logit soft-capping: A stabilization technique that limits the magnitude of attention logits to prevent extreme values during training. "In the same spirit, we also employ attention logit soft-capping \citep{gemma2024gemma2}."
- Attention sinks: Bias mechanisms added to attention to stabilize training and mitigate issues like outlier features. "Finally, we add attention sinks in the form of attention biases \citep{sun2024massive} to further stabilize training and prevent outlier features \citep{sun2024massive, he2024understanding}."
- Autoregressive LLMs (ALMs): Models that generate sequences token-by-token in a fixed order using previous outputs as context. "Discrete diffusion LLMs (DLMs) have been proposed as an alternative to autoregressive LLMs (ALMs)."
- Bootstrapping: A resampling-based statistical method used to estimate confidence intervals for fitted parameters. "()-confidence intervals based on standard bootstrapping are given as subscripts."
- BPE tokenizer: Byte Pair Encoding tokenizer that builds a subword vocabulary by iterative pair merges for efficient tokenization. "we train a BPE tokenizer \citep{gage1994bpe, sennrich2015neural} with a vocabulary size of (131,072) tokens on a 256 GB subset of the data."
- Categorical distribution: A probability distribution over discrete categories; in discrete diffusion, transitions and marginals are categorical. "In this case, the transitions and marginals of the Markov chain are categorical distribution."
- CompleteP: A parameterization scheme enabling stable learning-rate transfer across model width and depth. "To aid with scaling, we utilize CompleteP \citep{dey2025completeP} for stable learning rate transfer across model width and depth."
- Compute-bound scaling: A regime where training performance is constrained primarily by available compute rather than data. "While all noise types converge to similar loss values in compute-bound scaling, we find that uniform diffusion requires more parameters and less data for compute-efficient training compared to masked diffusion, making them a promising candidate in data-bound settings."
- Compute-optimal Pareto frontier: The set of hyperparameter choices that minimizes loss for a given compute budget, trading off batch size, learning rate, and model size. "it is therefore still necessary to sweep the learning rate for each model and batch size in order to find the compute-optimal Pareto frontier."
- Critical batch size: The batch-size threshold after which increasing the batch yields diminishing returns and reduced compute efficiency. "The critical batch size refers to the phenomenon where scaling the batch size past a certain critical point yields diminishing returns and becomes compute-inefficient."
- Diffusion Forcing: A method that samples independent noise levels per token to stabilize rollouts and speed up inference in diffusion models. "Diffusion Forcing \citep{chen2024diffusion} proposes to sample noise levels independent for each tokens, resulting in anisotropic noise."
- Discrete diffusion LLMs (DLMs): LLMs that generate sequences via iterative denoising on discrete states rather than autoregressive next-token prediction. "Discrete diffusion LLMs (DLMs) have been proposed as an alternative to autoregressive LLMs (ALMs)."
- Evidence Lower Bound (ELBO): A tractable optimization objective that lower-bounds the log-likelihood; maximizing it improves model likelihood. "To derive the ELBO of the proposed diffusion process, we frame it as an instance of generalized interpolating discrete diffusion (GIDD; \citealp{von2025generalized}) and reparameterize the GIDD ELBO in terms of SNR."
- Floating-point operations (FLOPs): A measure of computational cost counting floating-point arithmetic operations used during training. "We scale our uniform diffusion model up to 10B parameters trained for FLOPs, confirming the predicted scaling behavior and making it the largest publicly known uniform diffusion model to date."
- Generalized Interpolating Discrete Diffusion (GIDD): A unified framework for discrete diffusion that interpolates between data and a mixing distribution via a schedule. "We adopt generalized interpolating discrete diffusion (GIDD; \citealp{von2025generalized}), a class of discrete diffusion models \citep{austin2021d3pm} that provides a unified perspective of many existing approaches such as masked diffusion \citep{ou2025your, sahoo2024simple, shi2024simplified} or uniform diffusion \citep{schiff2024simple, sahoo2025diffusion}."
- Hybrid-noise diffusion: Diffusion processes that combine masking and uniform noise to enable token revision with smaller likelihood gaps. "or hybrid-noise diffusion \citep{von2025generalized}."
- Importance sampling: A variance-reduction technique where samples are reweighted according to a chosen proposal distribution. "The GIDD ELBO (Eq.~\ref{eq:gidd_elbo}) can be expressed as an importance sampling procedure over log-SNRs and the forward noising process ."
- Inductive bias: Structural assumptions embedded in a model or training objective that guide learning and generalization. "Put differently, going from autoregression to masking to uniform diffusion imposes progressively less structure on the generative process and therefore provides less inductive bias, suggesting that a more expressive model is required to learn the task effectively."
- Iso-FLOP profiles: Curves or fits that compare models at equal compute to derive scaling behavior while controlling for total FLOPs. "To fit the scaling laws, we adopt the approach based on iso-FLOP profiles from \citet{hoffmann2022training} (Approach 2)..."
- Iso-loss curves: Curves of hyperparameter settings that achieve a fixed target loss, used to study trade-offs among batch size and steps. "we additionally observe a tight relationship between batch size and step count along iso-loss curves."
- Itakura–Saito divergence: A point-wise divergence measure used in the GIDD ELBO to compare distributions. "with denoting the (point-wise) Itakura-Saito divergence..."
- KV-caching: Caching key–value tensors from attention for prompt tokens to accelerate inference on completions. "Attention from prompt queries to completion keys is masked in order to enable KV-caching of the prompt during inference."
- LaProp: An Adam variant that improves stability across ranges of optimizer hyperparameters by reparameterizing updates. "Following \citet{hafner2023mastering}, we use LaProp \citep{ziyin2020laprop} over Adam for its improved stability on a wider range of and values."
- Learning rate annealing: Gradually reducing the learning rate toward the end of training to improve final loss. "we omit learning rate annealing and analyze the scaling behavior without it."
- Log-SNR: The logarithm of the signal-to-noise ratio parameterizing diffusion schedules; relates to signal strength via a sigmoid. "First, we define the log-SNR as , which connects it to the signal strength via the sigmoid relation ..."
- Masked Diffusion Models (MDMs): Discrete diffusion models that progressively mask tokens and train the model to reconstruct them. "Within DLMs, masked diffusion models (MDMs) \citep{austin2021d3pm, ou2025your, sahoo2024simple, shi2024simplified} have emerged as the predominant DLM archetype next to alternative diffusion processes such as uniform diffusion..."
- Markov chain: A stochastic process with transitions depending only on the current state; used to define forward noising. "which is a Markov chain that gradually adds noise to the latent variable ..."
- Mixing distribution: The time-varying distribution that injects noise in discrete diffusion by interpolating with the data distribution. "For our scaling experiments, we consider a mixing distribution that smoothly transitions from masked to uniform diffusion..."
- Negative ELBO (NELBO): The negative of the evidence lower bound; used as an upper bound on negative log-likelihood in diffusion. "Under the condition that and are differentiable in time, the diffusion negative ELBO (NELBO) of GIDD is given by..."
- Non-embedding FLOPs-per-token: Compute per token excluding embedding operations; used to measure model expressivity in scaling fits. "The scaling laws describe the compute-optimal model size (in non-embedding FLOPs-per-token), training set size (in terms of tokens) and training loss (in terms of ELBO) as a function of training compute ..."
- QK-norm: Normalization applied to query and key vectors in attention to stabilize training and improve scaling. "as well as to both keys and queries, following QK-norm \citep{naseer2021intriguing, dehghani2023scaling}."
- RMSNorm: Root Mean Square Layer Normalization that normalizes activations without centering, improving stability. "we add RMSNorm \citep{zhang2019root} layers without bias before each attention and MLP block..."
- Scaling laws: Empirical power-law relationships describing how performance scales with compute, data, and model size. "Scaling laws have become an important ingredient of large-scale neural network training, particularly in the context of training LLMs."
- Signal-to-noise ratio (SNR): The ratio quantifying signal strength relative to noise; used to parameterize diffusion schedules. "This stems from the insight that the notion of time in diffusion models is spurious and serves only as a proxy for the signal-to-noise ratio (SNR)..."
- Squared ReLU: An activation function where ReLU outputs are squared, recommended for MLP blocks in some Transformer variants. "We use Squared ReLU for MLP activations, as recommended by \citet{so2021searching}."
- Uniform diffusion: A discrete diffusion process that replaces tokens with random vocabulary tokens, removing structure from the generative process. "uniform diffusion replaces tokens with random other tokens from the vocabulary until, eventually, every token in the sequence is completely random."
- WSD schedule: A warmup–stable–decay learning-rate schedule used to anneal the LR over a final fraction of training. "we anneal the learning rate to $0$ over the last 20\% of training following the WSD schedule \citep{hu2024minicpm, hagele2024scaling}."
- μP (muP): A parameterization approach for neural networks enabling learning-rate transfer across widths; CompleteP extends it. "We adopt CompleteP \citep{dey2025completeP}, a variant of P \citep{yang2022tensor} that parameterizes the model such that optimal learning rates transfer both across width and depth."
Collections
Sign up for free to add this paper to one or more collections.

