Robots Need More than VLA and World Models
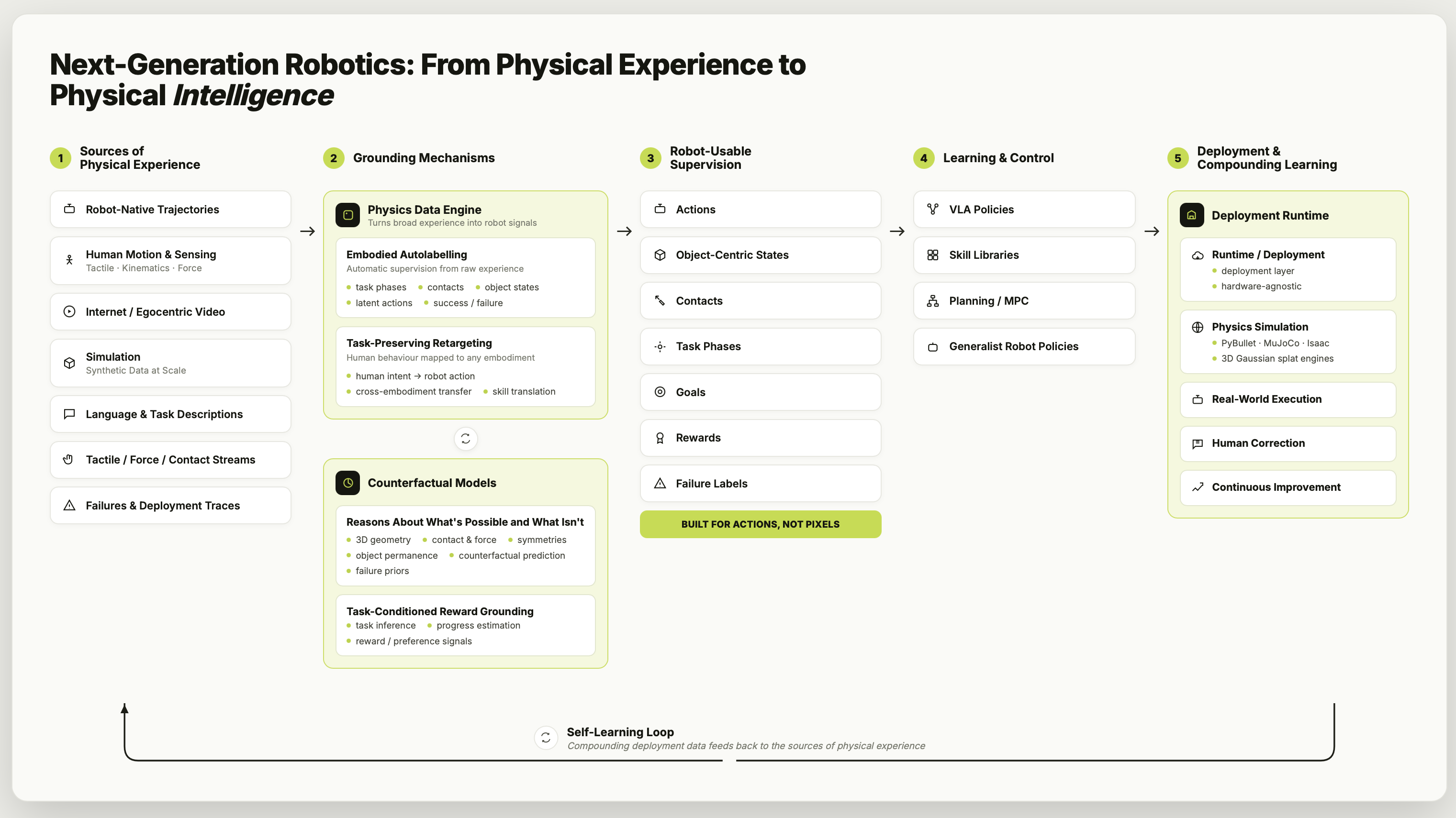
Abstract: Generalist robot intelligence is often framed as a policy-scaling problem: collect more robot demonstrations, train larger Vision-Language-Action (VLA) models, and expect broader generalisation. In this position paper, we argue that this framing is incomplete. The central bottleneck is not only policy learning, but the absence of mechanisms that convert the world's abundant unstructured behavioural data into grounded robot supervision. Human motion, internet video, simulation rollouts, and interactive demonstrations contain rich information about tasks, goals, contacts, failures, and physical constraints, yet most of this information is not directly usable by robot policies because it lacks embodiment-specific action labels, task semantics, and reward structure. We identify four missing components for the next generation of robotics: data interfaces for autolabelling unstructured behaviour, embodiment interfaces for retargeting human motion to robot actions, world-model interfaces for physics-grounded 3D reasoning, and reward interfaces for inferring task progress and success from video and language. We survey recent progress in robot foundation models, cross-embodiment datasets, learning from video, world models, and reward modelling, and propose a research agenda for building robotics systems that can learn not only from robot demonstrations, but from the broader physical world.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Plain-English Summary
This paper argues that making truly smart, general-purpose robots isn’t just about training bigger “vision-language-action” (VLA) models on more robot demos. The real blockage is that the world is full of useful videos and movements (like people doing chores, factory work, or YouTube tutorials), but robots can’t directly learn from most of it. Why? Because those videos don’t say which buttons a robot should press, how hard to push, or when a task is “good enough.” The authors explain what’s missing and outline four key pieces that would let robots turn messy real-world experience into clear instructions they can learn from.
What Questions Are They Asking?
- Why doesn’t simply collecting more robot demonstrations and scaling up VLA models give us truly general robots?
- How can robots learn from the huge amount of human and internet video that doesn’t come with robot-specific actions or rewards?
- What new tools and “interfaces” do we need so robots can understand tasks, physics, and success like humans do?
How Did They Approach It?
This is a “position and survey” paper. That means the authors:
- Review lots of recent robot-learning work (big robot datasets, generalist policies, learning from human video, simulation, and learned world models).
- Point out a common pain point: most data becomes useful only after it’s “grounded” (translated into a robot’s body, sensors, actions, and task goals).
- Propose four missing pieces—like adapters—that convert raw real-world behavior into robot-ready learning signals.
To make the ideas easier:
- Vision-Language-Action (VLA) model: like a robot brain that sees images, reads instructions, and outputs motor commands.
- Grounding: turning what you see or read into concrete steps a specific robot can execute (like converting “open the door” into the right arm motions and forces).
- Embodiment: each robot body is different (number of joints, grippers, size), so the same task needs different exact moves.
- World model: a robot’s “mental simulator” that predicts what will happen if it takes an action (like imagining a move before doing it).
- Reward: a score telling the robot if it’s getting closer to finishing the task (a progress bar for success).
What Did They Find and Why It Matters?
The authors say the bottleneck isn’t just “learn a better policy.” It’s that we’re missing mechanisms to turn the world’s messy, unlabeled behavior into the clear, robot-specific supervision that policies need. They highlight four missing components:
- Data interfaces for auto-labeling unstructured behavior:
- Problem: Internet videos show how objects move and which steps matter, but they don’t include robot action commands.
- Idea: Automatically extract useful signals from video, like “this frame is halfway through the task,” or “a grasp happens here,” or “the object moved from A to B.”
- Embodiment interfaces for retargeting human motion to robot actions:
- Problem: A human hand and a robot gripper are very different.
- Idea: Build translators that map “what changed in the world” (like “cup moved to shelf”) into the specific motor commands for any robot body.
- World-model interfaces for physics-grounded 3D reasoning:
- Problem: Pretty video predictions aren’t enough; robots need to respect 3D geometry, contact, friction, and forces.
- Idea: Give robots reliable internal simulators that predict real physical consequences—and know when they’re uncertain—so they can plan safely.
- Reward interfaces for inferring task progress and success from video and language:
- Problem: Robots often need a “score” to learn, but we rarely have hand-made rewards for every new task.
- Idea: Use video and language to estimate progress (like a task progress bar) and to decide when the task is done correctly.
Along the way, the paper surveys three big directions and their limits:
- Robot-native supervision (classic demos with action labels):
- Works well and has powered much of today’s progress, but is expensive, risky for hardware, and doesn’t scale like text/images on the internet.
- Learning from weakly grounded videos (no robot actions in the data):
- Videos can teach good visual features, reveal “latent actions” (like “grasp” or “place” without exact motor commands), and give progress signals.
- But these signals still need to be grounded into a specific robot’s body to become usable actions and rewards.
- Generating physical experience (simulation and learned world models):
- Simulators and synthetic demos can create lots of safe practice, and “world models” let robots imagine the future.
- The catch: generated experience must keep the important physical details (3D geometry, contact, materials) and handle uncertainty. Otherwise, plans learned in fake worlds won’t work on real robots.
The key takeaway: the next leap won’t come from just bigger VLAs. It will come from a pipeline that starts with broad real-world experience (human videos, simulations, language) and systematically grounds it into robot-ready actions, states, and rewards.
What Does This Mean for the Future?
If we build these four interfaces, robots could learn from the wider world, not just carefully collected robot demos. That would mean:
- Faster learning from everyday videos and human activity.
- Easier transfer of skills across different robot bodies (from small arms to humanoids).
- Safer, smarter planning using physics-aware world models that know when they might be wrong.
- More robust training at scale, because rewards and progress can be inferred instead of hand-coded.
In simple terms: to get truly helpful, general-purpose robots, we must teach them not only how to act, but also how to understand what they see, translate it into their own bodies, imagine consequences like a physicist, and judge progress like a coach. With these pieces in place, robots can learn from the world as it is—messy, unlabeled, and full of useful clues—rather than waiting for perfect robot-only datasets.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of concrete gaps that the paper identifies or implies but does not resolve, phrased to guide actionable research.
- Unified autolabeling from unstructured behavior: No standardized pipelines or benchmarks exist for automatically extracting robot-usable supervision (e.g., contact events, object states, task phases, success/failure) from raw, egocentric or third-person videos and other modalities with calibrated confidence scores and error bars.
- Which variables to extract from video: It remains unclear which latent variables (e.g., subgoals, contact intents, forces, object states, constraints) are most useful to extract from human/internet videos for downstream control, and how to prioritize and evaluate them.
- Grounding latent actions to executable control: Methods are missing for reliably mapping learned latent “action” codes from video into embodiment-conditioned, safety-constrained robot commands across diverse kinematics/dynamics while guaranteeing real-time execution and stability.
- Human-to-robot retargeting with contact and force fidelity: Robust retargeting across embodiments is unsolved when human demonstrations lack force/torque data; datasets and methods are needed to infer or inject missing contact forces, stiffness, and friction to preserve task semantics.
- Cross-embodiment alignment spaces: There is no standard way to define, learn, and evaluate morphology-agnostic latent spaces that align heterogeneous robot action/state spaces (different DOF, actuation limits, sensing suites) for both manipulation and loco-manipulation.
- Task-progress and reward inference that generalizes: Video- and language-derived progress/reward models lack calibration and robustness, often overfit to spurious correlations; methods are needed for uncertainty-aware, embodiment-agnostic rewards that transfer to novel tasks and viewpoints.
- Evaluating the quality of inferred supervision: Benchmarks and metrics are missing for (i) autolabel accuracy (e.g., contact timing/pose error), (ii) reward usefulness (policy improvement, preference alignment), and (iii) retargeting fidelity (task success under embodiment changes).
- Causal grounding vs. correlation: How to discover causal task variables and counterfactuals from video so that learned rewards/labels don’t exploit dataset artifacts remains open; practical causal evaluation protocols are lacking.
- Active data engines and deployment loops: Concrete strategies are needed for uncertainty- and value-aware data acquisition that decide when to request teleoperation, run additional robot trials, or mine new videos to correct grounding errors during deployment.
- World models with physically meaningful predictions: Learned models rarely preserve contact-rich dynamics, friction, deformables, and object permanence over long horizons; scalable 3D, object-centric, and material-aware models with verified physical fidelity are needed.
- Uncertainty- and risk-aware world models: There is no standard for calibrating, validating, and propagating epistemic/aleatoric uncertainty in learned world models into planning/MPC, including triggers for deferring to sensing or humans under high uncertainty.
- Avoiding hallucination loops in model-based control: Mechanisms to detect and prevent feedback loops where model errors cause compounding control mistakes are underdeveloped; recovery strategies and model trust metrics are required.
- Hybrid neural–physics simulators at real-time rates: Practical methods to fuse neural scene representations (e.g., 3D Gaussian splats) with differentiable contact/rigid/deformable physics that run in real time on robot hardware are not established.
- Sim-to-real validation of synthetic demonstrations: The field lacks ablations showing which synthetic data generation choices (trajectory perturbations, contact/dynamics fidelity, domain randomization) most influence real-world transfer, especially for contact-rich tasks.
- Scalable, auto-updating digital twins: Automated pipelines to build and maintain dynamic digital twins (geometry, articulation, materials) from onboard robot sensing, with minimal manual intervention, remain immature.
- Action tokenization for high-frequency control: There is no principled, general tokenization/compression scheme for high-rate continuous control that balances modelability with closed-loop stability and latency constraints, nor standardized metrics to compare tokenizers.
- Multimodal grounding beyond vision-language: Integrating tactile, force-torque, and audio into autolabelling, reward inference, and world models remains largely unexplored; datasets with synchronized multimodal streams and fusion methods are needed.
- Long-horizon temporal structure and options: Discovering reusable subgoals/options and stage boundaries from video, and composing them reliably in VLAs or hierarchical controllers for multi-stage tasks, lacks robust algorithms and evaluations.
- Closed-loop vs. open-loop supervision: Current video-derived labels often ignore feedback; methods are needed to produce supervision that anticipates closed-loop corrections (e.g., slip recovery, compliance adjustments) usable by feedback controllers.
- Continual learning under non-stationarity: How to update rewards/world models/retargeting maps online as environments and embodiments change, while preventing catastrophic forgetting and maintaining safety, is open.
- Diagnosing grounding failures: Tooling to localize failure sources (perception vs. autolabels vs. embodiment mapping vs. reward vs. world model) and provide actionable debugging signals to engineers is missing.
- Interfaces and APIs for the “grounding stack”: Well-defined, interoperable interfaces between data autolabelling, embodiment mapping, world models, reward models, and VLA policies—with standardized I/O formats, uncertainty representations, and latency budgets—are not yet available.
- Scaling laws and data-mixture design: The field lacks quantitative scaling studies that disentangle the contributions of robot-native, human video, synthetic, and imagined experience, and prescribe optimal mixtures under resource constraints.
- Robustness to occlusion and partial observability: Methods to produce reliable supervision (labels, rewards) when task-critical contacts are occluded or sensors fail are underdeveloped; principled use of priors and multimodal cues is needed.
- Safety and verification before execution: Formal methods to verify inferred rewards and retargeted actions for safety constraints (joint limits, contact forces, human proximity) prior to execution are missing from the proposed pipeline.
- Bias, privacy, and licensing in internet-scale videos: Governance frameworks to prevent unsafe or unethical behavior transfer, ensure consent/attribution, and audit biases in autolabels/rewards derived from public videos are not addressed.
- Compute and real-time constraints: The paper does not resolve how to run the full grounding stack (autolabelling, world-model rollouts, reward inference, VLA) under tight onboard compute and latency budgets for mobile and humanoid platforms.
Practical Applications
Summary
This position paper argues that scaling Vision-Language-Action (VLA) policies alone will not yield generalist robot intelligence. The core bottleneck is converting abundant, unstructured physical behavior (human videos, internet video, simulation, tactile streams) into grounded robot supervision. The authors outline four missing interfaces that unlock this conversion: (1) data interfaces for auto-labeling unstructured behavior, (2) embodiment interfaces for retargeting human motion to robot actions, (3) world-model interfaces for physics-grounded 3D reasoning, and (4) reward interfaces for inferring task progress and success from video/language. Surveyed advances (robot-native datasets, learning from action-free video, simulation/data generation, learned world models, uncertainty quantification) suggest concrete applications across sectors.
Below are actionable applications, grouped by deployment horizon. Each item lists sector(s), likely tools/products/workflows, and key assumptions/dependencies affecting feasibility.
Immediate Applications
These can be piloted or deployed now using existing methods, datasets, and tooling referenced in the paper.
- Application: Auto-labeling pipelines that turn human/robot videos into robot-usable supervision (progress, success, task phases)
- Sectors: manufacturing, logistics, household robotics, education; academia
- Tools/Workflows: video-language reward models and progress estimators (
PROGRESSOR,Adapt2Reward,ReWiND,TimeRewarder, SARM-like stage models); phase segmentation from existing CCTV/egocentric streams; integrate with robot training loops - Assumptions/Dependencies: sufficient video quality/coverage; minimal seed labels for calibration; robustness to embodiment/viewpoint shifts; privacy/compliance for video data
- Application: Representation pretraining from human/internet video to reduce robot data collection
- Sectors: robotics startups, labs; education
- Tools/Workflows: frozen visual backbones (
R3M,VIP,MVP,VC-1) plugged into imitation/RL for new tasks; quick adaptation on small real-robot datasets (e.g.,BridgeData V2,DROID,Open X-Embodiment) - Assumptions/Dependencies: domain shift handling; coverage of target objects/tasks in pretraining data; compute for pretraining/fine-tuning
- Application: Latent-action tokenization as an intermediate supervision signal from video
- Sectors: software tooling for robot learning; academia
- Tools/Workflows: learn discrete latent action codes from video (
LAPA,UniVLA-style) and map to robot-specific controllers with limited labeled data; use as auxiliary targets in VLA pretraining - Assumptions/Dependencies: effective embodiment decoders; moderate amount of paired robot data per embodiment for grounding; consistency across viewpoints
- Application: Synthetic demonstration generation to multiply scarce seeds
- Sectors: manufacturing, service robotics; academia
- Tools/Workflows: demonstration synthesis from few seeds (
MimicGen), large-scale simulated environments (RoboCasa,RoboCasa365,ManiSkill,RLBench) to train imitation/VLA policies; task variation at scale - Assumptions/Dependencies: sim physics adequate for contact/friction; distribution randomization; sim-to-real validation; curated object assets
- Application: Real-to-sim-to-real digital twins for safe policy evaluation and iteration
- Sectors: warehousing, healthcare facilities, retail, labs; policy/safety
- Tools/Workflows: scene reconstruction with 3D Gaussian Splatting; platforms like
RL-GSBridge,Real-is-Sim,RoboGSimto evaluate and stress-test policies before deployment; domain randomization and online adaptation - Assumptions/Dependencies: accurate reconstruction of geometry/appearance; update cadence for dynamic scenes; bridging domain gaps; safety monitors on real robots
- Application: Uncertainty-aware world models to gate actions and detect policy failure
- Sectors: safety-critical robotics (healthcare, autonomous mobile robots), compliance; academia
- Tools/Workflows: learned world models with calibrated uncertainty for planning/monitoring; latent uncertainty quantification (as in works cited by the paper) to veto high-risk actions; runtime anomaly detection for VLA manipulation
- Assumptions/Dependencies: calibration of uncertainty; coverage of operational distribution; conservative fallbacks and human-in-the-loop
- Application: Cross-embodiment data pooling and fine-tuning for new robots
- Sectors: integrators, platform vendors; education
- Tools/Workflows: pretrain VLA policies on pooled datasets (
Open X-Embodiment,RT-X,Octo) and adapt to new sensor/action spaces; action tokenization/FAST-like compression for efficient training - Assumptions/Dependencies: consistent schemas across datasets; action/observation remapping; minimal robot-specific calibration data
- Application: Teleoperation and portable demonstrations to harvest high-quality, contact-rich skills
- Sectors: contract manufacturing, field service; academia
- Tools/Workflows: low-cost teleop rigs (
ALOHA) plus sequence-level IL (e.g., diffusion policies); portable demos (HuMI-style) for whole-body skills where teleop is difficult; multimodal datasets (RH20T) for force/tactile grounding - Assumptions/Dependencies: capable teleop hardware; synchronization of multi-sensor streams; task diversity; annotating success/phase where needed
- Application: Process analytics from passive videos (phase mining, success/failure, dwell times)
- Sectors: operations/industrial engineering; policy/compliance
- Tools/Workflows: task-phase segmentation and progress estimation from weakly labeled video; dashboards for continuous improvement and training needs
- Assumptions/Dependencies: definable task taxonomies; acceptance of video analytics by workforce; privacy and governance
- Application: Curriculum and benchmarking in simulation for reproducible research and skill pretraining
- Sectors: academia, education; platform vendors
- Tools/Workflows: adopt
Meta-World,CALVIN,LIBERO,RLBench,ManiSkillfor multi-task and language-conditioned training; standardized evaluation protocols; bridges to real-robot validation - Assumptions/Dependencies: benchmarks reflect real constraints; sim-to-real pathways; community consensus on metrics
Long-Term Applications
These require further research, scaling, integration, or standardization across the proposed four interfaces.
- Application: End-to-end grounding-centric robot stack (data, embodiment, world model, reward) for generalist robots
- Sectors: household robotics, logistics, retail, hospitality, labs
- Tools/Workflows: unified “physical data engine” for auto-labeling, embodiment retargeting modules, 3D physics-grounded world models, and deployment reward loops feeding a VLA policy layer
- Assumptions/Dependencies: standardized interfaces and ontologies; reliable closed-loop learning under safety constraints; cross-vendor interoperability
- Application: Internet-scale video-to-robot skill transfer
- Sectors: consumer/service robots; software
- Tools/Workflows: large latent-action vocabularies learned from in-the-wild video; embodiment decoders for many robot morphologies; continual self-supervised grounding with sparse real labels
- Assumptions/Dependencies: scalable retargeting across embodiments; dataset licensing/privacy; robust handling of occlusions/contacts missing in videos
- Application: Universal interactive learned simulators for planning, training, and evaluation
- Sectors: platform vendors, autonomy stacks; academia
- Tools/Workflows:
UniSim/Genie-like learned simulators combining video prediction with action-conditioned dynamics; plug-in physics priors; policy training entirely in learned environments before real deployment - Assumptions/Dependencies: faithful 3D geometry and contact dynamics; uncertainty-calibrated predictions; safety wrappers for sim-to-real gaps
- Application: World-model co-processors embedded in robot OS
- Sectors: embedded systems, robotics platforms
- Tools/Workflows: on-device 3D object-centric/point-cloud world models (
ParticleFormer,PointWorld, object-centric models) for MPC, counterfactual reasoning, and failure prediction - Assumptions/Dependencies: real-time performance on edge hardware; tight sensor fusion (RGB-D, force, tactile); online adaptation
- Application: Skill marketplaces using standardized latent actions and reward models
- Sectors: software platforms, integrators, OEMs
- Tools/Workflows: publish/subscribe of skills as embodiment-agnostic latent programs with accompanying reward/progress functions; auto-compilation to specific robots
- Assumptions/Dependencies: community standards for latent action spaces; verification/certification pipelines; IP/licensing models
- Application: Self-improving deployment loops (autonomous task discovery, self-labeling, and safe self-training)
- Sectors: all deployed robotics (factories, warehouses, homes)
- Tools/Workflows: robots log interaction, infer phases/rewards from onboard VLMs, generate synthetic counterfactuals with world models, and fine-tune policies under safety monitors
- Assumptions/Dependencies: reliable failure detection; uncertainty-aware planning; governance and audit trails
- Application: Whole-body humanoid generalists with 3D world-model guidance
- Sectors: manufacturing, logistics, services
- Tools/Workflows: dual-system VLA action heads plus physics-grounded world models (as hinted by
GR00T N1,Gemini Robotics,Helix); humanoid-aligned state encodings and cross-embodiment controllers (e.g.,LeVERB,WholeBodyVLA,HEX) - Assumptions/Dependencies: safe whole-body control; contact-rich data; robust locomotion-manipulation coordination; real-time inference
- Application: Healthcare and surgical robotics learning from expert videos
- Sectors: healthcare
- Tools/Workflows: latent-action and reward inference from surgical video; sim/digital twin validation; world-model uncertainty gating; gradual autonomy with human supervision
- Assumptions/Dependencies: stringent regulation; privacy and consent; extremely high reliability and interpretability; haptics/force sensing
- Application: Construction, energy, and agriculture robots trained from expert egocentric videos
- Sectors: construction, energy (inspection/maintenance), agriculture
- Tools/Workflows: body-worn camera capture for task semantics; embodiment retargeting to manipulators/mobile platforms; site-scale 3D world models for planning (Gaussian splats + physics)
- Assumptions/Dependencies: ruggedization; outdoor perception robustness; variable materials and deformables; safety and union/workforce acceptance
- Application: Policy and standards for data, safety, and privacy in grounding-centric robotics
- Sectors: policy/regulation, industry consortia
- Tools/Workflows: standards for cross-embodiment datasets (
Open X-Embodiment-style schemas), evaluation protocols for sim-to-real validity, requirements for uncertainty calibration and safety monitors, privacy guidelines for video-based learning - Assumptions/Dependencies: multi-stakeholder alignment; testbeds and public benchmarks; certification bodies
- Application: Consumer “show-and-tell” teaching tools
- Sectors: daily life, consumer robotics, education
- Tools/Workflows: smartphone capture of a user performing a task; auto-inferred phases/rewards; latent action program compiled to the home robot; world-model previews for user approval
- Assumptions/Dependencies: easy capture and calibration; robust embodiment retargeting; intuitive UI and safeguards; on-device or private-cloud processing
Cross-cutting Dependencies to Monitor
- High-fidelity sensing (RGB-D, force/torque, tactile, audio) to bridge visual gaps in contact-rich tasks.
- Efficient action tokenization/compression for high-rate control within VLA architectures.
- Domain randomization and online adaptation for sim-to-real robustness; continuous digital-twin updates.
- Data rights, privacy, and licensing for human/internet video; provenance tracking in training pipelines.
- Compute and energy budgets for training/inference; edge acceleration for world models and VLA control.
- Safety layers: calibrated uncertainty, runtime monitors, fail-safes, and human-in-the-loop oversight.
Glossary
- 3D Gaussian Splatting: A neural scene representation technique that models scenes as collections of 3D Gaussians for photorealistic, efficient rendering and reconstruction. Example: "use 3D Gaussian Splatting and related reconstruction methods"
- Action-conditioned: Describes models or predictions that take explicit action inputs to forecast future states or observations. Example: "action-conditioned world models for imagined robot experience"
- Action tokenisation: Compressing continuous, high-frequency control signals into discrete or compact tokens for efficient modeling by sequence models. Example: "action-tokenisation methods address a complementary bottleneck"
- Affordance-aware: Accounting for what actions are possible with objects in a scene when planning or selecting skills. Example: "affordance-aware skill selection"
- Affordances: The actionable possibilities offered by objects or environments to an agent, given its capabilities. Example: "robot affordances"
- Autolabelling: Automatically generating labels (e.g., actions, events, rewards) from raw, unstructured data such as videos. Example: "autolabelling unstructured behaviour"
- Autoregressive dynamics model: A model that predicts the next state or observation based on past states/observations in a sequential, step-by-step fashion. Example: "an autoregressive dynamics model"
- Bimanual manipulation: Coordinated control and use of two robot arms/hands to perform tasks. Example: "a diffusion-transformer architecture for bimanual manipulation"
- Chain-of-thought reasoning: Structured, step-by-step intermediate reasoning used by a model to improve decision quality or disambiguate tasks. Example: "structured chain-of-thought reasoning"
- Counterfactual: Hypothetical alternative outcomes or trajectories used for reasoning or data augmentation without physically executing them. Example: "counterfactual interaction data"
- Cross-embodiment: Methods or datasets that span multiple robot morphologies or bodies, enabling transfer across different embodiments. Example: "cross-embodiment datasets"
- Digital twin: A high-fidelity virtual replica of a real-world system used for simulation, planning, or evaluation. Example: "digital-twin simulation environments"
- Diffusion models: Generative models that learn to denoise data from noise, enabling synthesis of complex distributions, including action sequences. Example: "showing that diffusion models can represent multimodal action distributions"
- Domain randomisation: Training over randomised simulator parameters (visual/dynamics) so policies generalise to real-world variability. Example: "Domain randomisation is one of the dominant strategies"
- Egocentric: First-person, agent-perspective sensory data, often from head- or body-mounted cameras. Example: "egocentric human videos"
- End effector: The terminal part of a robot arm (e.g., gripper, hand) that interacts with the environment. Example: "end-effector poses"
- Flow matching: A training paradigm for generative models that learns continuous-time flows mapping simple to complex distributions. Example: "using a flow-matching architecture"
- Force-torque measurement: Sensing that records forces and torques at robot joints or end effectors for contact-rich tasks. Example: "force-torque measurements"
- Gaussian process: A nonparametric Bayesian model used for probabilistic regression and dynamics modeling with uncertainty estimates. Example: "Gaussian-process dynamics models"
- Graph networks: Neural architectures operating on graph-structured data to model interactions among entities (e.g., objects). Example: "graph networks can simulate complex physical systems"
- Hamiltonian Neural Networks: Models that learn a system’s Hamiltonian and use Hamilton’s equations to enforce energy-consistent dynamics. Example: "Hamiltonian Neural Networks learn a Hamiltonian function"
- Imitation learning: Learning policies by mimicking expert demonstrations rather than relying solely on trial-and-error. Example: "imitation learning"
- Inverse reinforcement learning: Inferring reward functions from observed behavior, often across different embodiments. Example: "cross-embodiment inverse reinforcement learning"
- Lagrangian Neural Networks: Models that parameterise a system’s Lagrangian and derive equations of motion via the Euler–Lagrange equations. Example: "Lagrangian Neural Networks parameterise a Lagrangian"
- Latent actions: Action-like abstract codes inferred from observations (e.g., video) that can later be mapped to executable robot commands. Example: "learning unified latent actions"
- Latent dynamics: Compact hidden-state models that predict how the environment evolves, often learned from pixels. Example: "learning compact latent dynamics from pixels"
- Loco-manipulation: Integrated control of locomotion and manipulation, typically for whole-body robots. Example: "loco-manipulation"
- Model-based control: Control strategies that use explicit models of system dynamics for planning and action selection. Example: "for model-based control"
- Model-based reinforcement learning: RL methods that leverage learned or known dynamics models for planning or data-efficient policy improvement. Example: "model-based reinforcement learning"
- Model predictive control: An optimization-based control method that plans over a receding horizon using a predictive model. Example: "model-predictive control"
- Neural scene representation: Learned 3D scene models (e.g., radiance fields, Gaussians) used for rendering, simulation, or planning. Example: "a combination of a neural scene representation with physical simulation"
- Object-centric world models: World models that explicitly represent and predict dynamics of individual objects and their interactions. Example: "Object-centric world models"
- Proprioceptive: Internal sensing of a robot’s own state (e.g., joint angles, velocities) used for control. Example: "proprioceptive states"
- Real-to-sim-to-real: Pipelines that reconstruct real scenes into simulation, train or refine in sim, then deploy back to the real world. Example: "a 3D-Gaussian-Splatting-based real-to-sim-to-real reinforcement-learning framework"
- Reinforcement learning: Learning control policies via trial-and-error interaction guided by rewards. Example: "reinforcement learning"
- Retargeting: Mapping human motions or demonstrations to robot-specific action spaces while preserving task semantics. Example: "retargeting human motion to robot actions"
- State-space models: Sequence models (often linear-time SSMs) designed for efficient long-context reasoning and control. Example: "state-space-model architectures"
- Symplectic structure: A geometric property of Hamiltonian systems preserved by specific integrators/models for stable long-horizon physics. Example: "enforce Hamiltonian or symplectic structure"
- Teleoperation: Human-operated remote control of robots, often used to collect demonstrations. Example: "low-cost teleoperation systems"
- Time-contrastive learning: A self-supervised approach that learns representations by contrasting temporally nearby vs. distant frames. Example: "using time-contrastive learning"
- Uncertainty quantification: Estimating the confidence or calibration of model predictions to support safe planning and control. Example: "uncertainty quantification for a world model"
- Video-LLMs: Multimodal models that jointly process video and text for understanding tasks, progress, or rewards. Example: "video-LLMs"
- Vision-Language-Action (VLA): Models that map visual inputs and language instructions to robot actions. Example: "vision-language-action models"
- VQ-VAE: Vector-quantised variational autoencoder that discretises latent spaces for learning compact codebooks. Example: "VQ-VAE-style objective"
- World models: Learned predictive models of environment dynamics used for imagination, planning, or policy learning. Example: "world models"
Collections
Sign up for free to add this paper to one or more collections.

