- The paper’s main contribution is that VLA models, when pre-trained on diverse human and robot data, intrinsically develop effective human-to-robot skill transfer.
- The methodology leverages co-training on aligned human and robot demonstrations, optimizing both high-level sub-task and low-level action predictions.
- Experimental results show significant improvements in scene, object, and task generalization, with human data yielding near parity to equivalent robot data.
Emergence of Human-to-Robot Transfer in Vision-Language-Action Models
Introduction
This paper systematically investigates the emergence of human-to-robot transfer in large-scale Vision-Language-Action (VLA) models, focusing on the conditions under which leveraging human video data enables new robotic skills. The central claim is that with sufficiently diverse VLA pre-training across tasks, scenes, and embodiments, the ability to benefit from human demonstrations emerges as an intrinsic property of the model's representational space. This phenomenon draws a strong analogy to emergent abilities in LLMs, where scaling and diversity induce qualitatively new generalization capacities. The methodology employs a co-training scheme that treats embodied human data as another robot in the mixture, using identical learning objectives, eschewing any explicit alignment step.
Methodology
Data Mixture and Collection
Data is stratified into two major sources: large-scale robot teleoperation data and embodied human video data. The pre-training set for robot data spans multiple tasks, scenes, and robot platforms, systematically increasing its diversity to probe transfer dynamics. The human dataset is collected using a minimally intrusive apparatus consisting of a head-mounted camera, as well as wrist cameras to increase hand-object interaction observability (Figure 1).

Figure 1: Three-view camera setup captures comprehensive human manipulation trajectories for downstream action and sub-task learning.
Human demonstrations are structured to mirror robot teleoperation episodes, and each is annotated with 3D hand trajectories and dense natural language sub-task descriptions. Action and sub-task spaces for human and robot data are carefully aligned through the definition of analogous 6-DoF hand and end-effector pose trajectories, facilitating effective co-training.
Model Architecture and Objectives
The primary architecture is derived from the Pi-0.5 VLA model, comprising a vision-language backbone with both discrete and continuous action heads. At fine-tuning, the model jointly optimizes for low-level action prediction (via next-token prediction and flow-matching) and high-level sub-task prediction. Both objectives are applied symmetrically to human and robot samples.
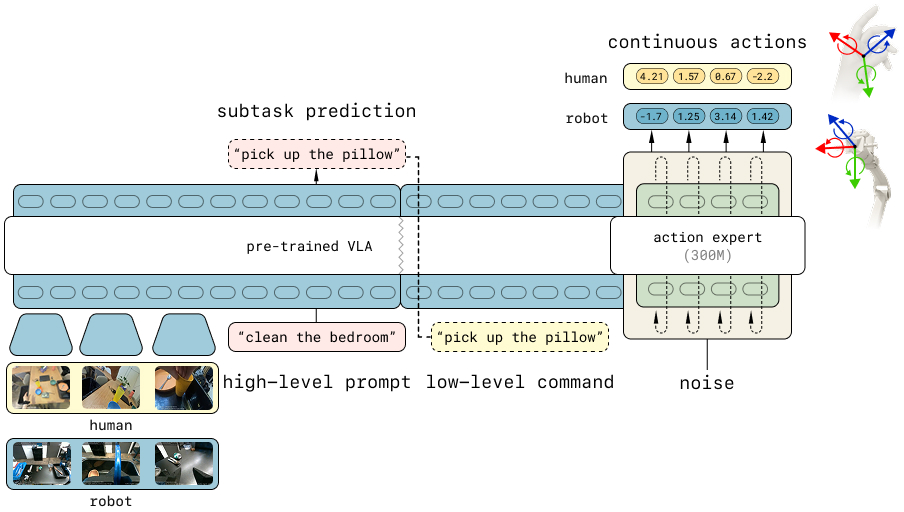
Figure 2: Pi-0.5 VLA model supports hybrid high-level and low-level objectives over both human and robot data via aligned action representations.
Benchmark Tasks
Generalization is evaluated on four axes:
- Scene transfer: Transferring to unseen environments (e.g., tiding a dresser in a never-seen apartment).
- Object transfer: Manipulating novel object categories.
- Task transfer: Acquiring new semantic tasks (e.g., egg sorting by color).
- Cross-embodiment transfer: Relative merit of human vs. off-target robot data for adaptation.
The experimental setup ensures that novel concepts are only present in human demonstrations, not in robot data, thus isolating the contribution of human-to-robot transfer.
Main Experimental Results
Human-to-Robot Transfer Is an Emergent Property of Pre-training Diversity
Fine-tuning Pi-0.5 with both human and robot data yields substantial performance lifts on generalization tasks when the model is pre-trained on sufficiently diverse robot datasets. Scene generalization scores on the Spice and Dresser tasks nearly double, object transfer yields a 10-point improvement, and task transfer (egg sorting) accuracy jumps from 57% (random placement) to 78% after co-training.
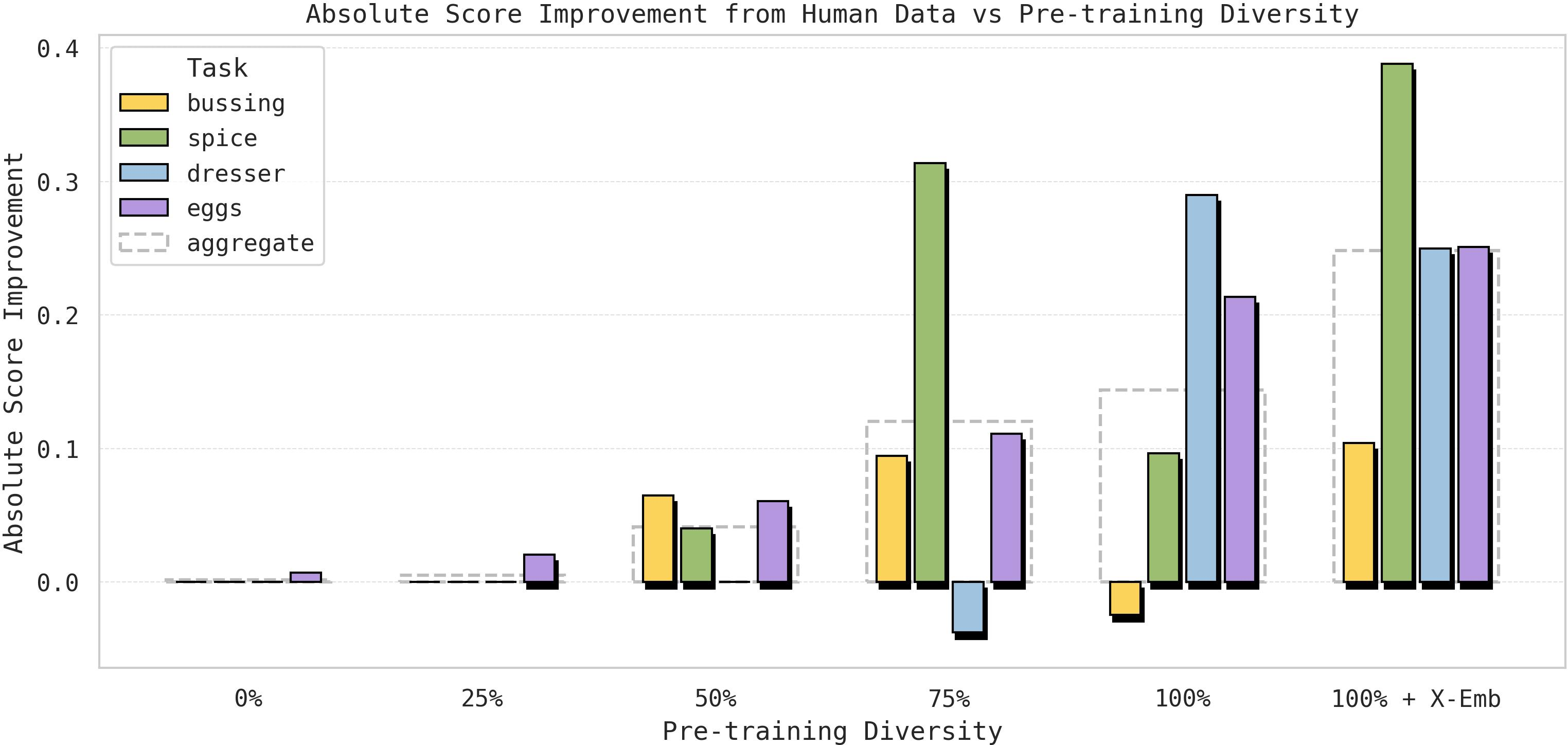
Figure 3: Incremental gain from integrating human video, as a function of robot pre-training scale, demonstrates sharp transitions in transfer emergence.
This trend is further analyzed through scaling experiments. Transfer from human videos is negligible when pre-training is narrow (0%-25% of the full mixture) but becomes pronounced at 75%-100% diversity, with maximal effect when cross-robot embodiment data is included.
Embodiment-Agnostic Representations Drive Transfer
TSNE visualizations of model activations show that initial models segregate human and robot embeddings into disjoint clusters. As pre-training diversity increases, these clusters coalesce, highlighting the development of embodiment-agnostic latent spaces.
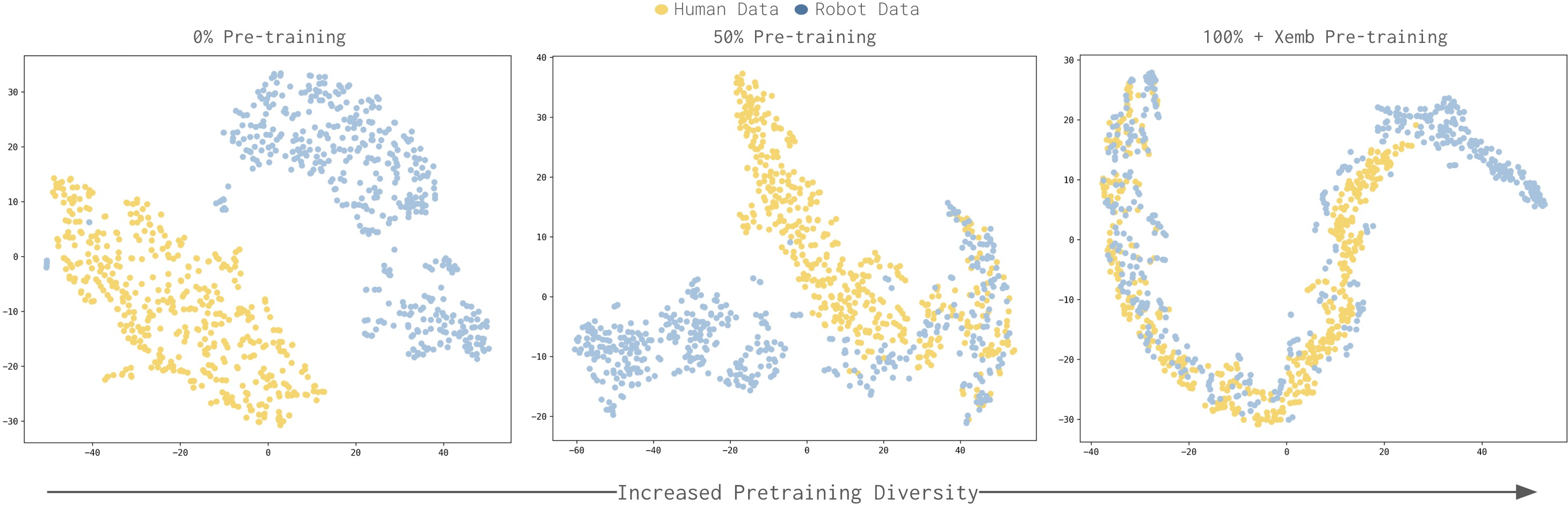
Figure 4: Increased robot data diversity during pre-training induces convergence of human and robot latent distributions, facilitating direct transfer.
Comparative Analysis: Human vs. Robot Cross-Embodiment Data
Direct comparison with additional target robot data shows that, for most tasks, human data achieves near parity with equivalent quantities of robot data. Cross-embodiment robot transfer (e.g., UR5 to ARX) exhibits similar but not superior transfer efficacy relative to human data.
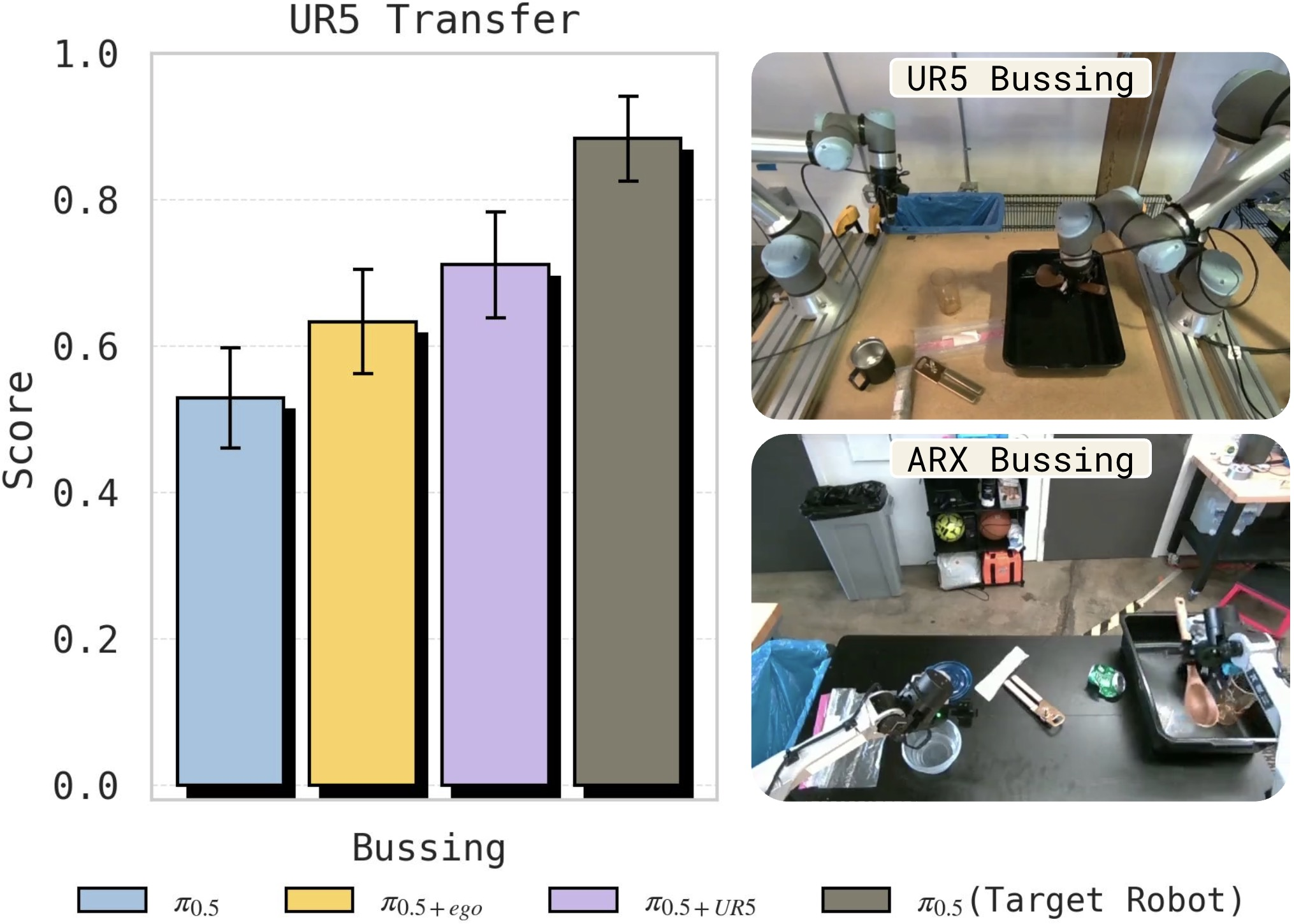
Figure 5: Human-to-ARX and UR5-to-ARX transfer yield similar lifts over baseline, but both underperform direct in-domain adaptation.
Transfer Across Hierarchical Levels
Transfer from human data impacts both high-level sub-task prediction and low-level action imitation. Ablations show that co-training at both levels yields the highest task success, while transfer at only one level leaves the overall pipeline bottlenecked by the other. This suggests deep integration at multiple abstraction layers.
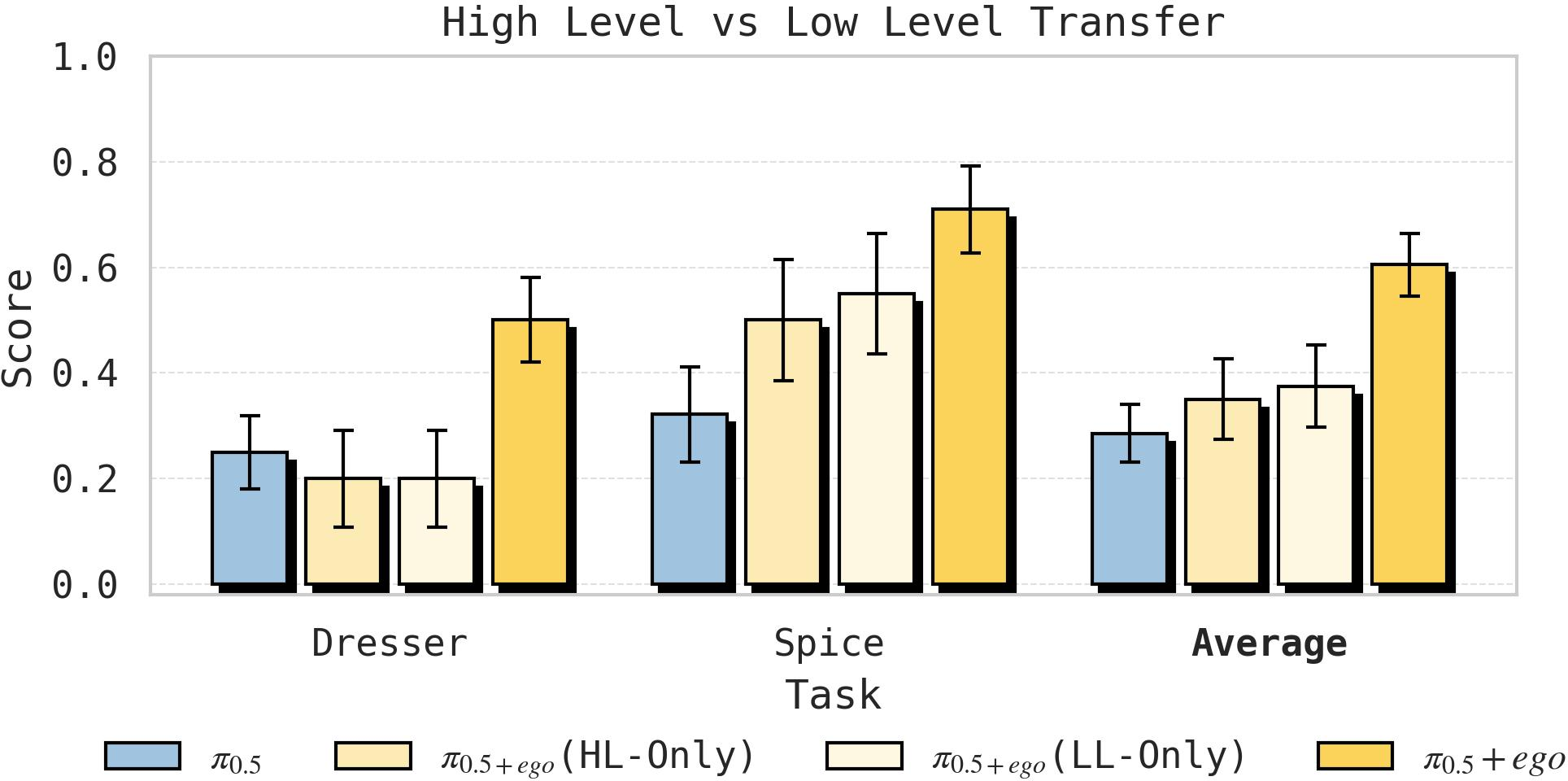
Figure 6: Both high-level and low-level policy modules benefit from human data, with the best generalization achieved via joint co-training.
The Role of Auxiliary Sensing (Wrist Cameras)
Task-dependent ablations reveal that wrist-mounted cameras on humans provide additional observability, especially for tasks requiring fine manipulation or occlusion robustness (e.g., Dresser, Bussing). In other tasks, global context afforded by head-mounted cameras is sufficient.
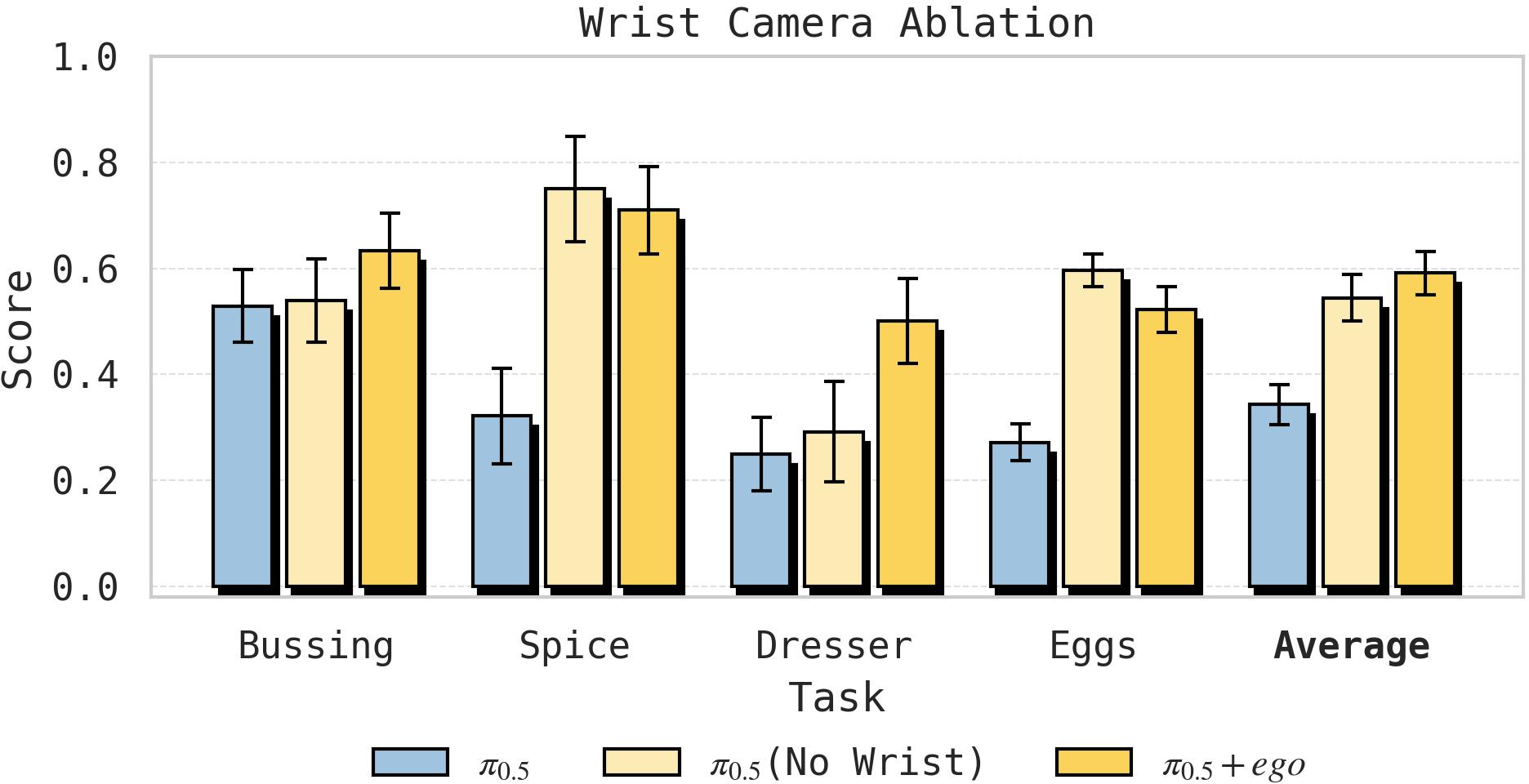
Figure 7: Wrist camera streams improve transfer only for tasks that demand fine, end-effector-centric visual feedback.
Theoretical and Practical Implications
The findings empirically establish that sufficient scale and heterogeneity in pre-training is a prerequisite for embodiment-agnostic skill transfer in VLAs. This parallels emergent phenomena in LLMs, providing a concrete roadmap for scaling generalist robot policies. From a practical perspective, the research argues against manually engineered human-robot alignment procedures, suggesting that model capacity and data coverage are the primary limiting factors. Embodied human video is validated as a competitive alternative to direct robot data for target adaptation, provided robust sensory alignment and annotation.
Future Directions
Continued scaling in demonstration diversity—across environments, skills, and embodiments—is expected to yield further gains. The integration of massive, passively collected embodied human data is likely to augment open-world generalization and task compositionality. Sensory apparatus design for unobtrusive, high-fidelity human data acquisition (e.g., minimal wrist cameras) is a relevant engineering direction.
Conclusion
This study rigorously characterizes the emergence of human-to-robot transfer in VLA models, attributing it to a critical mass of compositional training diversity. It demonstrates that with appropriate pre-training, VLAs benefit substantially from direct human demonstrations, enabling policy generalization to novel tasks, scenes, and semantic variations not covered by robot data alone. The implications position embodied human video as a first-class data source for scalable generalist robot learning, obviating ad hoc domain alignment and further eroding the boundary between human and machine embodiment in embodied AI systems.

