- The paper introduces a closed-loop, chunk-wise world model that iteratively integrates visual observations with VLA policy actions.
- It leverages an action-to-control projection and latent history memory to ensure temporal and multi-view consistency in dual-arm tasks.
- Empirical results demonstrate significant improvements in success-rate alignment and perceptual fidelity compared to baseline methods.
PiL-World: Chunk-Wise World Models for Closed-Loop VLA Policy Evaluation
Motivation and Problem Statement
World models for robotic policy evaluation are generally designed for open-loop settings, where predictions are made along fixed, pre-collected trajectories that do not respond to the policy's evolving actions over time. This paradigm is misaligned with how vision-language-action (VLA) policies are deployed in the real world: these policies operate in a closed loop, observing the scene, executing action chunks, and basing subsequent actions on resulting observations. Open-loop evaluation fails to reflect crucial feedback effects, including observation shifts or compounding errors that realistically affect closed-loop execution. Addressing this gap, the paper introduces PiL-World, a chunk-wise world model explicitly tailored for closed-loop, policy-in-the-loop VLA evaluation—allowing iterative generation of future observations with feedback from the VLA agent at each execution cycle.
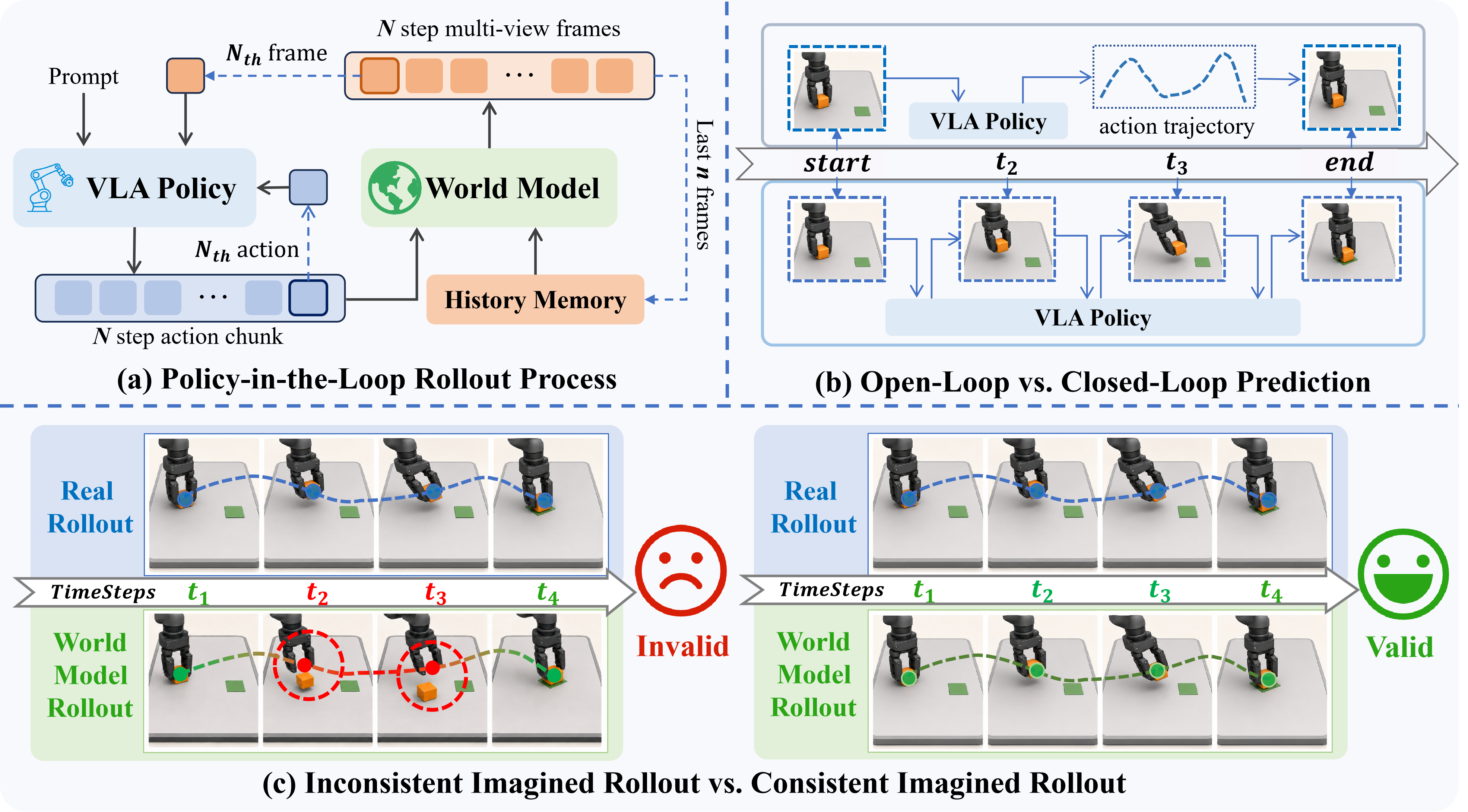
Figure 1: Closed-loop policy-in-the-loop rollout forms an alternating process between the VLA policy and the predictive world model, crucially updating the policy inputs with generated observations at every iteration.
PiL-World: Model Architecture and Pipeline
PiL-World models the dynamics of VLA policy rollouts in a closed loop, integrating several architectural innovations:
- Chunk-wise Rollout Pipeline: At each round, a frozen VLA policy issues an action chunk conditioned on the current visual observation, proprioceptive state, and instruction. PiL-World projects this action chunk into visual control signals and predicts a stride-aligned sequence of multi-view observations. The terminal generated observation—after K prediction steps—is then passed back to the policy for the next action chunk, iterating this process.
- Action-to-Control Projection: Since the VLA policy produces absolute joint-space commands, PiL-World employs a deterministic geometric projection that encodes these commands into visually-aligned gripper markers within the head camera frame—enabling the video backbone to directly condition on actionable scene changes.
- Latent History Memory: To maintain temporal consistency across rollouts, PiL-World incorporates a latent history buffer encoding recent multi-view frames. This context is crucial for preventing compounding drift and cross-view inconsistencies, providing the necessary preceding trajectory for credible video generation.
- Bidirectional Success/Failure Training: The world model is not only trained on successful demonstrations but also includes failed teleoperated executions. This dual exposure enables more robust modeling of both goal-reaching and non-goal-reaching behaviors, preventing overfitting to ideal outcomes.
Figure 2: The PiL-World framework integrates (a) closed-loop policy rollouts, (b) action-to-visual control projection, (c) fine-tuning on both successful/failed executions, and (d) latent history memory for temporal consistency.
Experimental Setup and Evaluation Metrics
PiL-World is evaluated on three real dual-arm manipulation tasks: Sort Cubes, Stack Bowls, and Stack Blocks. Each task is segmented into subtasks, with real and imagined rollouts initialized from identical states and instructions using a fixed VLA policy. Training is two-staged: (i) pretraining on RealSource World for general dual-arm robot-environment dynamics, and (ii) fine-tuning on target-task demonstration and teleoperation failures.
Three principal metrics are applied:
- Absolute Success-Rate Gap (∣ΔSR∣): Measures the difference between real and imagined rollout success rates for each task, quantifying high-level behavior matching.
- Hallucination-Free Ratio (HFR): Reports the fraction of rollout frames before the first obvious hallucination, judged by humans, reflecting long-horizon credibility.
- Multi-view LPIPS: Captures perceptual similarity between predicted and ground-truth frames under ground-truth action conditions. This metric provides localized prediction fidelity over different camera views.
Quantitative and Qualitative Results
Policy alignment and hallucination resistance: PiL-World attains a significant reduction in real-imagined success agreement gap—from 63.2% (Ctrl-World) to 12.0% on average. HFR is increased considerably, especially in less contact-sensitive tasks, indicating that imagined rollouts remain visually and physically plausible for longer horizons.
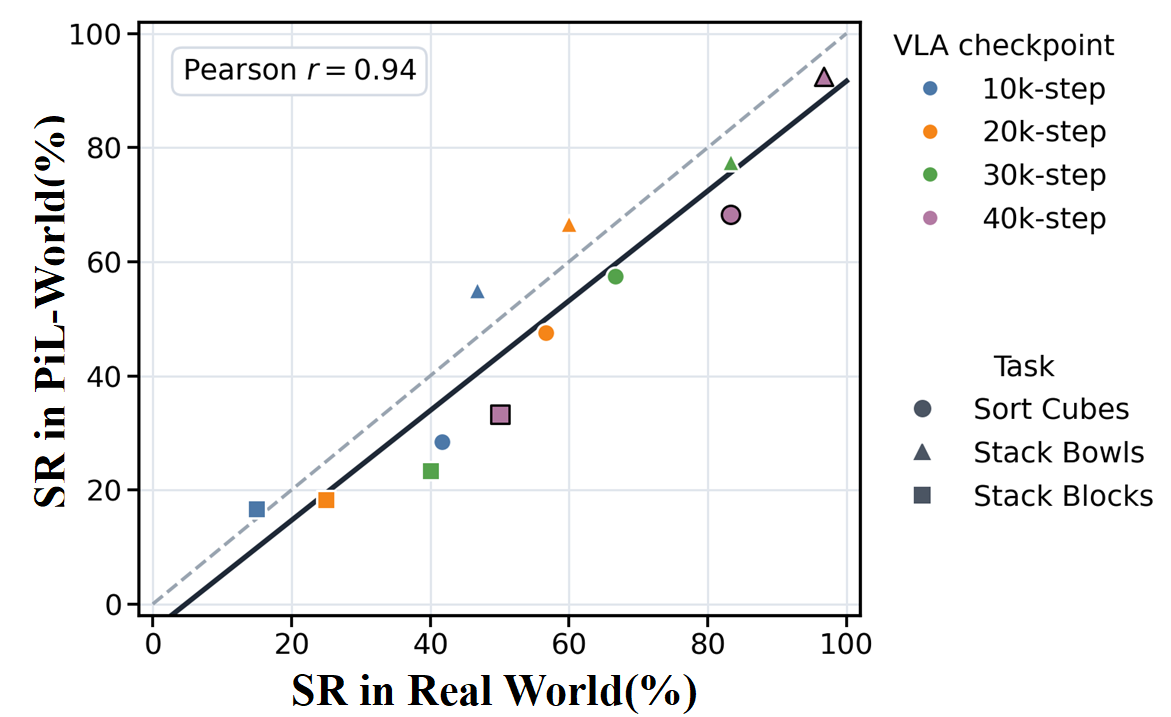
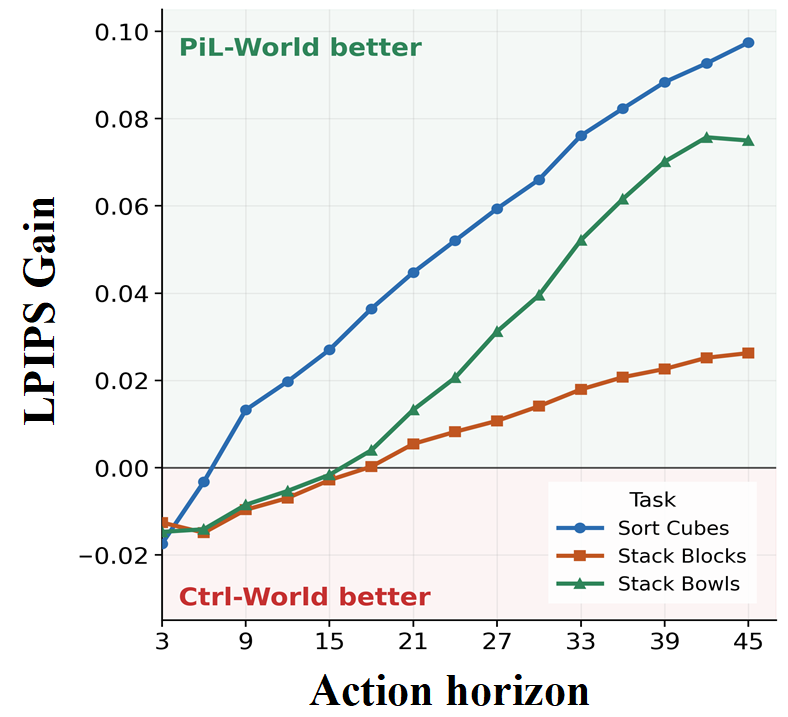
Figure 3: (Left) Success agreement trends for PiL-World across diverse VLA policy checkpoints and tasks. (Right) Action-horizon LPIPS gain highlights the cumulative perceptual advantage of PiL-World over Ctrl-World, growing with rollout length.
In single-step perceptual evaluation, PiL-World consistently yields lower LPIPS across multi-view predictions, with dominant head-view improvement due to the action-to-visual projection mechanism. Ablation removing latent memory results in substantial performance degradation (LPIPS rising from 0.0965 to 0.3146 on Sort Cubes), demonstrating the necessity of temporal context for robust visual dynamics modeling.
Qualitative analysis reinforces these numerical results: PiL-World produces rollouts closely matching real scene evolution, preserving manipulation progression and cross-view consistency. By contrast, existing baselines frequently show rapid degradation, with object drift, incoherent arm motion, or hallucinated contacts.
Task Diversity and Action Representation
Tasks are selected to span object reordering (Sort Cubes), nesting (Stack Bowls), and high-precision contact stacking (Stack Blocks). Subtask segmentation allows systematic measurement of VLA policy performance and world-model fidelity at granular checkpoints. The visual action projection pipeline translates abstract policy commands into explicit, marker-based control frames, efficiently bridging the semantic-kinematic gap typical in embodied video prediction.

Figure 4: Visual examples of task setups and subtask breakdowns for each dual-arm manipulation task.
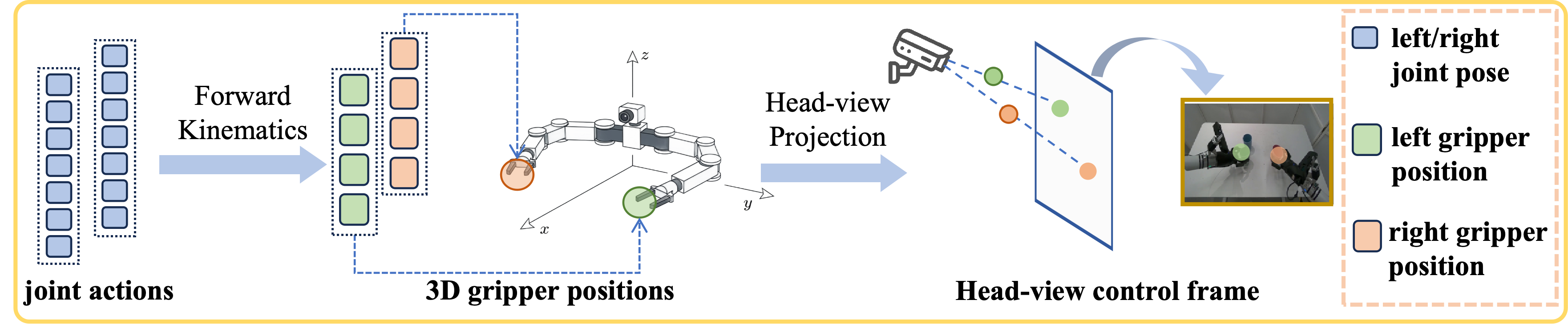
Figure 5: The action-to-control projection pipeline mapping policy commands to visually observable, head-view-aligned markers that inform the world model’s conditional generation.
Broader Implications, Limitations, and Future Directions
The findings demonstrate PiL-World’s suitability as an in-silico closed-loop evaluation layer before costly real-robot deployment of VLA policies. Its ability to tightly preserve the correlation between imagined and real-world success rates unlocks efficient model selection, checkpoint evaluation, and policy debugging under realistic interaction feedback. The chunk-wise architecture, coupled with latent temporal conditioning and visual action constraints, offers a foundation that could be extended to more complex policy hierarchies, longer rollouts, or multi-task settings.
Current limitations include evaluation on a narrow set of dual-arm manipulation tasks and modest generalization to broader domains or platforms. Contact-rich scenarios remain a failure point due to error compounding after small mismatches, especially under occlusion or limited proprioceptive feedback. Human annotation is still essential for hallucination detection and success rate scoring.

Figure 6: Qualitative multi-view action-conditioned predictions on RealSource World scenarios, illustrating perceptual similarity and temporal coherence across views.
Potential future work includes unsupervised hallucination detection, automatic rollout alignment metrics, scaling to more skills and robots, and integration of self-reflective policy adaptation loops leveraging PiL-World rollouts. Moreover, coupling such world models with hierarchical planners or instructable agents could accelerate progress toward autonomous, sample-efficient robot learning.
Conclusion
PiL-World advances the landscape of closed-loop policy evaluation for VLA robotics by introducing a chunk-wise, temporally-conditioned world model that aligns with the real deployment interface of contemporary VLA agents. Empirical evidence demonstrates strong correspondence between imagined and real outcomes, surpassing previous models on multiple axes of long-horizon coherence and action consistency. These results advocate for world-model–driven evaluation as a critical component of scalable VLA policy development and deployment.

