RynnVLA-002: A Unified Vision-Language-Action and World Model
Abstract: We introduce RynnVLA-002, a unified Vision-Language-Action (VLA) and world model. The world model leverages action and visual inputs to predict future image states, learning the underlying physics of the environment to refine action generation. Conversely, the VLA model produces subsequent actions from image observations, enhancing visual understanding and supporting the world model's image generation. The unified framework of RynnVLA-002 enables joint learning of environmental dynamics and action planning. Our experiments show that RynnVLA-002 surpasses individual VLA and world models, demonstrating their mutual enhancement. We evaluate RynnVLA-002 in both simulation and real-world robot tasks. RynnVLA-002 achieves 97.4% success rate on the LIBERO simulation benchmark without pretraining, while in real-world LeRobot experiments, its integrated world model boosts the overall success rate by 50%.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces RynnVLA-002, a single robot brain that does two things at once:
- It decides what the robot should do next (Vision–Language–Action, or VLA).
- It imagines what the world will look like after those actions (a “world model”).
Think of it like a robot that can both plan moves and mentally “play out” what will happen next, so it can make better choices.
What questions did the researchers ask?
The authors set out to answer three simple questions:
- Can we build one model that both plans actions and predicts how the world will change?
- Will this “two-in-one” model make the robot smarter than using either part alone?
- How can we make the robot’s actions both accurate and smooth, not clumsy or slow?
How did they build the system?
They combined two ideas into one unified model and taught it using the same “language” for images, words, and actions.
Two brains in one
- VLA brain: Looks at camera images and reads an instruction (like “put the block in the circle”), then decides the next actions.
- World-model brain: Uses the current image plus the robot’s action to “imagine” the next image, like a mini video of the future.
Both brains share the same backbone, so they learn from each other. When the world model gets better at predicting physics (like how objects move), the action planner improves. And when the VLA gets better at understanding scenes and goals, the world model makes more realistic future frames.
Teaching the model to “read” images, words, and actions
The model turns everything into tokens—tiny pieces like Lego bricks:
- Images → image tokens
- Text instructions → word tokens
- Robot state and actions → action tokens
Using a shared token “alphabet” helps the model connect vision, language, and actions in a unified way.
Planning several moves at a time (action chunks)
Robots work better if they can plan a few steps ahead (like 5–10 moves), not just one step at a time. But there’s a problem: if the model learns step-by-step, an early mistake can snowball into many more mistakes.
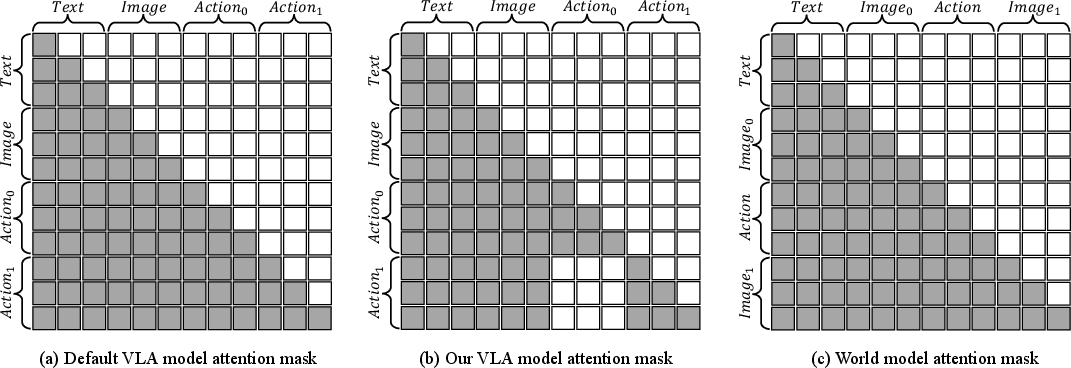
To fix this, the authors added a clever “attention mask” for discrete (step-by-step) actions. Imagine covering up your previous moves so you don’t copy your own errors—each action focuses on the images and instructions, not on earlier, possibly wrong actions. This reduces error build-up.
Making actions smooth and fast (continuous actions)
In the real world, robots need smooth, joystick-like motions, not just a list of discrete steps. The team added a small Action Transformer head that:
- Generates a whole action sequence in one shot (parallel), making it fast.
- Uses both past and future context to keep motions smooth (less shaking).
- Generalizes better on small, real-world datasets (less overfitting).
In short:
- Discrete actions = “typing steps” one by one.
- Continuous actions = “drawing a smooth path” all at once.
- They train both, but the continuous head runs faster and is smoother in real life.
What did they find, and why does it matter?
Here are the main results and why they’re important:
- Stronger than using either part alone
- The unified model (planning + imagination) outperforms standalone VLA models and standalone world models. Each part makes the other better.
- Excellent performance in simulation without pretraining
- On the LIBERO benchmark (a popular robot testbed), the continuous-action version reached a 97.4% success rate without any large-scale pretraining. That’s impressive because many strong baselines rely on big pretrained models.
- Big gains in real-world robots
- On real robot tasks (like “put the block inside the circle” and “place the strawberries in the cup”), adding the world-model training boosted the success rate by around 50%. The model handled cluttered scenes and distractor objects better than strong baselines.
- Smoother, faster control
- The Action Transformer produced smoother motions and faster decisions by generating action chunks in parallel. This is crucial for real-time robotics.
- Evidence the two parts truly help each other
- Training with world-model data made the action planner more focused on object interactions (e.g., better grasping).
- Training with VLA data improved the world model’s future-frame predictions (fewer viewpoint inconsistencies, more realistic outcomes).
- Extra sensors help
- Using a wrist camera (a camera near the gripper) and the robot’s internal status (its joint angles, called “proprioception”) improved performance, especially in real-world tasks where precise alignment matters.
Why does this research matter?
- Smarter robots, safer choices: By imagining the future, robots can avoid mistakes and plan better.
- Less data, more generalization: The continuous-action head works well even with limited real-world data, which is often the norm in robotics.
- Faster, smoother control: Parallel action generation means robots can operate in real time with stable motions.
- A path to unified AI: This work shows how to build one foundation model that understands images, language, and actions together—useful for many future robots and devices.
In simple terms: RynnVLA-002 teaches a robot to think ahead and act wisely. It’s like giving the robot both a plan and a built-in simulator, making it better at understanding the world and getting things done.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, focused list of what remains missing, uncertain, or unexplored in the paper. Each point is phrased to be concrete and actionable for future work.
- How to use the world model for on-policy planning at inference time: no experiments on imagination-based action selection (e.g., evaluating candidate action chunks via rollout, MPC, or tree search with the learned world model).
- Multi-step prediction and closed-loop consistency of the world model are not assessed: training and evaluation are restricted to next-frame prediction; no analysis of compounding errors, free-running rollouts, or policy performance when conditioned on world-model-generated observations.
- The ratio/schedule for mixing VLA and world-model data during training is unspecified: no ablation on data mixing proportions, curriculum, or sampling strategies and their impact on mutual enhancement or negative transfer.
- Shared token vocabulary across image, text, action, and state may induce cross-modal interference: no diagnostics on embedding entanglement, token collision, or negative transfer between modalities; no comparison to separate vocabularies or modality-specific adapters.
- The proposed action attention mask removes access to prior actions, potentially harming tasks that require temporal consistency across actions: no evaluation on tasks explicitly requiring smooth, causally consistent trajectories; no exploration of hybrid masks (limited look-back, scheduled masking).
- Discrete action tokenization (256 bins per dimension) is fixed by training data ranges: no analysis of clipping/saturation, learned quantization, per-dimension adaptive binning, or alternatives (e.g., FAST, hierarchical or vector-quantized action tokens).
- Continuous Action Transformer details are under-specified: architecture size, number of action queries, layers, and attention design are not reported; no sensitivity analysis for loss weighting , action-chunk length, or architectural scale.
- The choice of fixed action chunk sizes () is heuristic: no strategy for adaptive chunk length selection based on task complexity, uncertainty, or observation feedback; no evaluation of intra-chunk replan mechanisms or chunk boundary policies.
- World model text prompt assumes actions entirely determine next state (“Generate the next frame based on the current image and the action”): no study of partial observability, exogenous disturbances, or the role of language context in predictive modeling.
- Deterministic visual generation metrics (FVD, PSNR, SSIM, LPIPS) do not capture physics or interaction fidelity: no metrics for contact events, object pose/trajectory errors, collision predictions, or multi-view physical consistency.
- Uncertainty is not modeled: the world model provides no calibrated uncertainty estimates; no use of probabilistic predictions or ensembles to inform robust planning and action selection.
- The mechanism of “mutual enhancement” is not probed: beyond empirical gains, there is no representational analysis (e.g., object-centric features, attention distributions, causal attribution) explaining how world-model training benefits action generation and vice versa.
- Real-world evaluation is narrow (two pick-and-place tasks, 10 trials per scenario): no tests on broader task suites, long-horizon manipulation, deformable objects, novel object categories, or cross-embodiment transfer.
- Real-world data curation removes unsuccessful trajectories and “no-operation” actions: this introduces selection bias; no ablation on including failures, corrective attempts, or counterfactual data to improve robustness.
- Wrist camera and proprioceptive state are shown as critical, but integration details are missing: no analysis of multi-view calibration, synchronization/latency, time alignment, or failure under occlusion; no exploration of additional sensing (force/tactile).
- The world model is not evaluated for multi-view consistency: observed disalignment across viewpoints suggests a need for view-consistent training objectives and metrics (e.g., cross-view pose consistency).
- No safety assessment: absence of contact/compliance modeling, collision avoidance, failure-mode taxonomy, or safety constraints; unaddressed risk mitigation for real-world deployment.
- LIBERO evaluation protocol details are incomplete: seed control, environment resets, and scene randomization are not described; no robustness tests under controlled distribution shifts (lighting, object pose, distractors).
- Fairness of comparisons is unclear: “without pretraining” claims lack compute/training budget details; baselines are pretrained and then finetuned; no standardized budget-matched comparisons or cross-validation across multiple seeds.
- Training compute and resource footprint are not reported: no information on parameter counts, GPU hours, training time, memory use, or inference latency on embedded hardware.
- The Action Transformer uses an L1 regression loss without smoothness constraints: no evaluation of alternative losses (Huber, distributional/mixture losses), jerk/acceleration regularization, or trajectory-level consistency metrics.
- The masking solution for error propagation in discrete generation is compared only to a vanilla causal mask: no comparison to scheduled sampling, curriculum decoding, beam search, or constrained decoding guided by the world model.
- Continuous vs. discrete action trade-offs are not fully quantified: the claim that discrete models need more data is not backed by scaling-law analyses; no experiments varying data size to map sample-efficiency curves for both heads.
- The image tokenizer (VQ-GAN with perceptual losses tuned to faces/salient objects) may be suboptimal for robotics: no study of robotics-specific tokenization (gripper/object-centric losses, geometry-aware tokens) and their impact on control.
- The model does not exploit the world model for retry planning or counterfactual reasoning during execution: no pipeline that uses imagined futures to decide regrasp strategies or to select among action chunks.
- History length is set to without justification: no analysis of memory depth, attention over longer histories, or hierarchical planning that leverages subgoal memory for LIBERO-Long tasks.
- Proprioceptive state is discretized but not analyzed: no comparison to continuous encoders for state, or to learned state tokenization aligned with action generation; no study of the impact on timing (e.g., gripper closure synchronization).
- No failure-mode analysis is provided: no categorization of errors (perception vs. planning vs. control), nor where the world model helps most; lack of qualitative/quantitative error taxonomy to guide improvements.
- Data and models: code is linked, but dataset availability, licenses, and pretrained weights for reproducibility are not stated; no documentation of data splits or release plan.
- Multi-embodiment and cross-robot generalization are not explored: no study on retargeting actions across robots with different kinematics or control rates; no embodiment-agnostic policy adapters.
- Integration with alternative policy heads is not examined: no comparisons to diffusion, flow-matching, or hybrid autoregressive–parallel heads under the same unified framework.
- No exploration of language complexity: prompts are simple; no evaluation under compositional, ambiguous, or multi-step language instructions; no study of instruction grounding in predictive modeling.
Practical Applications
Summary of practical applications derived from the paper
RynnVLA-002 unifies a Vision-Language-Action (VLA) policy with a world model that predicts future visual states conditioned on actions. Key innovations include: shared token vocabulary across vision, language, state, and action; a discrete action-attention masking strategy to prevent error accumulation in autoregressive chunk generation; and a compact, parallel-decoding Action Transformer head for continuous action chunks that improves generalization and speed, especially on real robots. The model demonstrates strong performance in simulation (97.4% success on LIBERO without pretraining) and boosts real-world success rates by integrating world-model training data.
Below are actionable, real-world applications grouped into immediate and long-term opportunities.
Immediate Applications
- Robotics (warehouse and retail) — language-driven pick-and-place with distractors
- Use case: Shelf restocking, SKU sorting, bin picking with clutter, and packing stations where text instructions (e.g., “place the blue box in bin C”) are mapped to robust action chunks.
- Tools/workflows: Deploy RynnVLA-002 as a controller in a ROS/LeRobot stack; use continuous Action Transformer for smoother, faster motions; tune chunk size (e.g., K=5–10) per task; integrate wrist camera and proprioceptive signals for robust grasping in clutter.
- Assumptions/dependencies: A wrist camera or equivalent close-up sensor, calibrated extrinsics, basic fine-tuning on target objects, safety interlocks, and real-time GPU inference.
- Manufacturing (cell-level automation and assembly assistance)
- Use case: Semi-structured tasks like component placement, fixture insertion, cable routing assistance, or “hand me the next part” workflows guided by natural language prompts.
- Tools/workflows: World-model-informed collision avoidance by predicting next-frame outcomes for candidate actions; use attention-masked discrete chunking for action sequencing where precise temporal continuity is less critical.
- Assumptions/dependencies: Reliable perception of parts, stable lighting, integration with PLC/industrial control systems, and task-specific fine-tuning for tolerances.
- E-commerce and logistics — multi-object sorting with language grounding
- Use case: Sorting items from mixed totes; distinguishing targets from distractors with wrist-camera feedback; following dynamic language instructions from WMS systems.
- Tools/workflows: Continuous Action Transformer head for parallel action generation and higher throughput; mixed training with world-model data to improve robustness.
- Assumptions/dependencies: High-throughput sensing (RGB-D recommended), domain-specific data curation (reject failed demos, remove no-op actions), and safe motion planning.
- Lab automation — general-purpose labware handling
- Use case: Moving tubes, plates, or vials between stations on benchtop arms using text prompts (“place the 96-well plate into slot B”).
- Tools/workflows: Deploy RynnVLA-002 in a lab-automation stack; leverage world-model pretraining to accelerate convergence with limited demos.
- Assumptions/dependencies: Precise gripper and fixture tolerances, controlled environment, and task-specific calibration.
- Human-in-the-loop teleoperation — predictive visualization for operators
- Use case: Operator issues a language command and preview the world-model’s predicted next-frame outcomes for candidate actions to choose safer/faster trajectories.
- Tools/workflows: UI overlay of predicted video frames; action chunk proposals generated in parallel; operator confirmation loop.
- Assumptions/dependencies: Low-latency inference pipeline, ergonomic HMI, and fallback manual override.
- Robotics research and education (academia)
- Use case: Benchmarking unified VLA+world models; studying attention masking strategies and chunk-length effects; curriculum modules on multi-modal action generation and predictive modeling.
- Tools/workflows: Use the open-source codebase; replicate LIBERO and LeRobot setups; ablation templates (wrist camera, proprioception, chunk sizes); measure FVD/PSNR/SSIM/LPIPS for world-model experiments.
- Assumptions/dependencies: Accessible GPU resources, reproducible data pipelines, and standardized evaluation protocols.
- MLOps for embodied AI — faster training and deployment
- Use case: Production pipelines combining discrete tokens (for convergence) with continuous action heads (for execution), and mixed VLA/world-model datasets.
- Tools/workflows: Training recipe that mixes cross-entropy losses for images/actions with L1 regression for continuous actions; automatic curation (remove failed/no-op trajectories); validation via both task success rates and video metrics.
- Assumptions/dependencies: Stable training infrastructure, dataset governance, and monitoring of drift across camera viewpoints.
- Policy and safety engineering — offline hazard screening
- Use case: Use the world model to predict next-frame outcomes for candidate actions to flag potential collisions or unstable grasps before execution.
- Tools/workflows: Pre-execution “what-if” checks with counterfactual action sampling; thresholds on perceptual metrics (LPIPS, SSIM) to detect high-uncertainty predictions.
- Assumptions/dependencies: Well-calibrated predictive metrics, conservative safety margins, and a human override policy.
- Daily life (hobbyist/home robotics)
- Use case: Home tasks on low-cost arms (e.g., place objects into containers) using natural language commands; improved reliability via wrist-camera input.
- Tools/workflows: Lightweight deployment with Action Transformer head for parallel chunk generation; per-home fine-tuning on common household objects.
- Assumptions/dependencies: Sufficient local compute (desktop GPU/embedded accelerator), sensor calibration, and object datasets.
Long-Term Applications
- General-purpose household assistants
- Use case: Broad, open-ended multi-step tasks (tidying, organizing, setting tables) with natural language and robust world-model foresight.
- Tools/workflows: Scale joint training with diverse, unstructured home data; expand cross-embodiment capabilities across mobile bases and manipulators; integrate multi-view RGB-D and tactile sensing.
- Assumptions/dependencies: Large-scale learning across homes, robust domain transfer, privacy-preserving data collection, and strong safety guarantees.
- Assistive healthcare and eldercare
- Use case: Safe object handover, feeding assistance, medication placement, and mobility aid where foresight and physical understanding are critical.
- Tools/workflows: World-model-based counterfactual planning for safety; certified runtime monitors; task-specific Action Transformer modules for gentle, continuous motions.
- Assumptions/dependencies: Clinical validation, regulatory compliance (FDA/CE), human factors engineering, and robust perception under occlusions.
- Agriculture and field robotics
- Use case: Selective picking (fruits/vegetables), sorting, and gentle handling with language guidance and physics-informed predictions.
- Tools/workflows: Domain-specific world-model pretraining on outdoor videos, cross-weather adaptation, tactile integration, multi-modal sensor fusion.
- Assumptions/dependencies: Hardware ruggedization, long-tail visual variability, and seasonal retraining.
- Energy, utilities, and industrial inspection/maintenance
- Use case: Manipulation tasks around valves, meters, and panels; predictive hazard analysis for confined spaces; counterfactual checks to avoid unsafe contacts.
- Tools/workflows: Digital twin integration where world models serve as fast surrogate simulators; language-driven checklists; offline validation of policies in “imagined” scenarios.
- Assumptions/dependencies: High-fidelity plant models, strict safety certification, and specialized manipulators.
- Cross-embodiment, cross-platform robot foundation models
- Use case: Train once, deploy on many arms and grippers with minimal fine-tuning, supported by a unified token vocabulary and world-model pretraining.
- Tools/workflows: Action canonicalization across embodiments; adapters for kinematics; expanded continuous action spaces; multi-robot datasets.
- Assumptions/dependencies: Broad, high-quality cross-embodiment data, standardization of interfaces, and robust alignment across sensors.
- Large-scale, self-supervised world-model pretraining from web-scale videos
- Use case: Use the world model as a general physics-informed prior to accelerate downstream manipulation learning in low-data regimes.
- Tools/workflows: Massive video curation, action-conditioned pretext tasks (when actions unavailable, infer latent dynamics), curriculum learning from easy to hard dynamics.
- Assumptions/dependencies: Significant compute, scalable tokenizers, and domain adaptation from human video to robot embodiments.
- Digital twins as certification substrates
- Use case: Formal pre-deployment testing of robot policies using world models inside digital twins to quantify risk, performance, and recovery behaviors.
- Tools/workflows: Policy selection via rollouts in synthetic environments; world-model metrics as acceptance criteria; standards around predictive fidelity.
- Assumptions/dependencies: Agreement between world-model predictions and real-world outcomes; industry standards for validation.
- Regulatory frameworks for embodied AI
- Use case: Policies that require internal predictive safety checks (world-model “imagination”) before executing high-risk actions; audit trails for counterfactual evaluations.
- Tools/workflows: Compliance toolkits that log predicted frames, action chunks, and uncertainty; human-in-the-loop escalation.
- Assumptions/dependencies: Cross-industry consensus on metrics (e.g., FVD/LPIPS thresholds), legal mandates, and secure logging.
- Multi-agent coordination and task-level planning
- Use case: Teams of robots coordinate via shared world-model predictions (e.g., avoiding interference, planning joint grasps).
- Tools/workflows: Shared predictive state, language-based role assignment, hierarchical chunking strategies across agents.
- Assumptions/dependencies: Reliable inter-robot communications, synchronized clocks, and standardized action interfaces.
- Sim-to-real transfer pipelines powered by world models
- Use case: Bridge domain gaps by training policies in synthetic environments and using world-model pretraining to adapt to real camera and physics idiosyncrasies.
- Tools/workflows: Joint training with synthetic and real trajectories; uncertainty-aware policy refinement; progressive chunk-length tuning.
- Assumptions/dependencies: Well-matched simulators, realistic texture/physics modeling, and continuous calibration between sim and real sensors.
Glossary
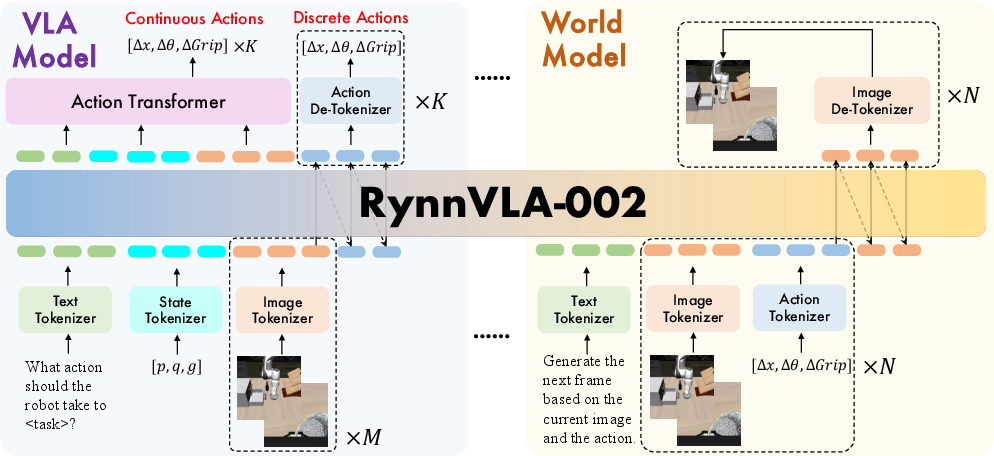
- Action attention masking: A customized attention design that prevents current action tokens from attending to previously generated actions to reduce error accumulation. "we proposed an action attention masking strategy that selectively masks prior actions during the generation of current actions."
- Action chunking: Generating multiple future actions in one step to execute as a chunk for efficiency and stability. "We set the action chunk size for the longer LIBERO-Long and LIBERO-Spatial tasks"
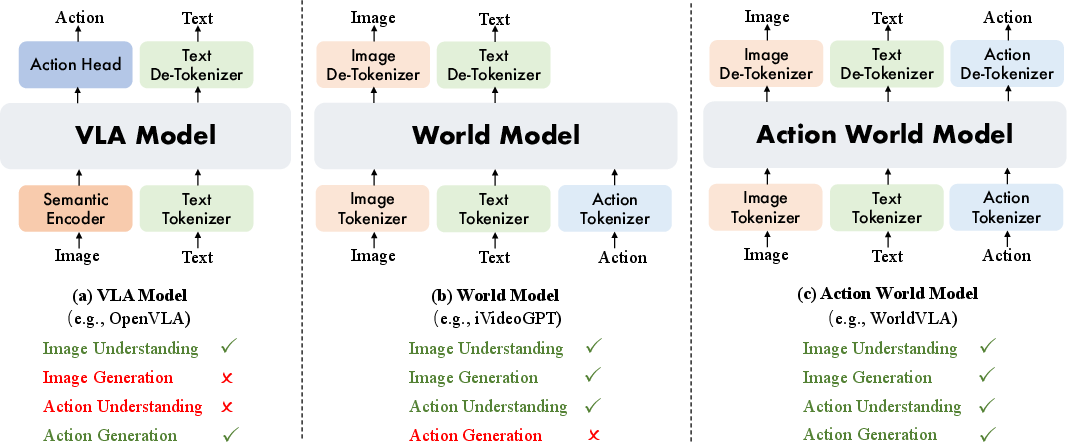
- Action head: An output module attached to a multimodal model that maps internal representations to action commands. "with either an action head or additional action expert module to generate actions."
- Action queries: Learnable query embeddings used by a transformer to output an entire action sequence in parallel. "utilizes learnable action queries to output an entire action chunk in parallel."
- Autoregressive model: A sequence model that generates outputs token-by-token, conditioning each step on previous outputs. "in autoregressive models where subsequent actions are conditioned on preceding ones"
- Bidirectional attention: An attention mechanism allowing tokens to attend to both past and future positions, not just the causal past. "the Action Transformer's parallel decoding and bidirectional attention mechanism reduce the number of decoding steps"
- BPE tokenizer: Byte-Pair Encoding tokenizer that segments text into subword units for efficient vocabulary coverage. "The text tokenizer is a trained BPE tokenizer."
- Causal attention mask: A lower-triangular attention mask that restricts each token to attend only to previous positions. "under the default causal attention mask"
- Codebook: The discrete set of latent codes used by vector-quantized models to represent data. "the codebook size is 8192."
- Conditional flow matching: A training objective for flow-based generative models that matches conditional probability flows. "leverage conditional flow matching"
- Compression ratio: The factor by which an encoder reduces spatial or latent dimensionality. "The compression ratio of the image tokenizer is 16"
- Cross-embodiment data: Data collected across different robot bodies or embodiments to improve generalization. "leveraging large-scale multimodal web and cross-embodiment data"
- Cross-entropy loss: A standard classification loss used to train models on discrete token targets. " refers to the cross-entropy loss of discrete action tokens."
- Discrete tokens: Symbolic tokens representing actions or images after discretization. "producing actions as discrete tokens."
- Domain transfer: The ability of a model to generalize across different domains or environments. "though challenges remain in visual fidelity, domain transfer, and computational efficiency."
- Error propagation: Accumulation of mistakes in sequence generation when later outputs depend on earlier errors. "error propagation becomes a critical issue"
- Fréchet Video Distance (FVD): A metric measuring distributional similarity between sets of videos. "Fréchet Video Distance (FVD), Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index (SSIM), and Learned Perceptual Image Patch Similarity (LPIPS)."
- L1 regression loss: The mean absolute error used as a regression objective for continuous outputs. "We use L1 regression loss to supervise the Action Transformer."
- Learned Perceptual Image Patch Similarity (LPIPS): A perceptual similarity metric based on deep features comparing image patches. "Learned Perceptual Image Patch Similarity (LPIPS)."
- Multimodal LLMs (MLLMs): LLMs extended to handle multiple modalities such as vision and text. "Multimodal LLMs (MLLMs) contribute robust capabilities in perception and decision making"
- Parallel decoding: Generating multiple outputs simultaneously rather than sequentially to accelerate inference. "the Action Transformer's parallel decoding and bidirectional attention mechanism reduce the number of decoding steps"
- Peak Signal-to-Noise Ratio (PSNR): A signal fidelity metric measuring the ratio of peak signal to noise in reconstructions. "Peak Signal-to-Noise Ratio (PSNR)"
- Perceptual losses: Loss terms based on high-level visual features that improve the fidelity of generated images. "with additional perceptual losses to specific image regions, e.g., faces and salient objects"
- Proprioceptive state: Internal sensory readings of a robot (e.g., joint positions, gripper state) used for control. "a proprioceptive state "
- Structural Similarity Index (SSIM): A perceptual metric evaluating structural similarity between images. "Structural Similarity Index (SSIM)"
- Vision-Language-Action (VLA): Models that map visual and language inputs to robotic actions. "The Vision-Language-Action (VLA) model has emerged as a promising paradigm"
- Vision-LLM (VLM): Models that jointly process vision and language for perception and understanding. "Vision-LLM (VLM)-based VLA models"
- VQ-GAN: A generative model using vector quantization and adversarial training to encode images into discrete codes. "The image tokenizer is a VQ-GAN model"
- World model: A predictive model that forecasts future observations conditioned on current images and actions. "World models directly address these limitations by learning to forecast future observations conditioned on current images and actions"
- Wrist camera: A camera mounted near the robot’s gripper providing close-up visual feedback during manipulation. "the front camera shows a failed grasp while the wrist camera shows a successful one."
- Zero-shot deployment: Executing a trained policy on new platforms without task-specific fine-tuning. "enabling direct zero-shot deployment across robot platforms"
Collections
Sign up for free to add this paper to one or more collections.

