- The paper presents SV-VLA, which decouples heavy macro-planning and lightweight verification to balance efficiency and robustness in VLA systems.
- It employs an L1 norm based discrepancy measure to trigger replanning, significantly enhancing action reliability in dynamic environments.
- Experimental results demonstrate improvements up to 90.9% success and a 2.17× speed-up on LIBERO benchmarks compared to traditional methods.
Open-Loop Planning, Closed-Loop Verification: Analysis of Speculative Verification for VLA
Introduction
Vision-Language-Action (VLA) models, which integrate vision, language, and robotics for direct tokenized action sequence generation, have demonstrated significant enhancement in embodied manipulation. However, the major bottleneck remains high inference latency due to the substantial computational cost of closed-loop, high-frequency action selection with large vision-LLMs (LVLMs). Existing approaches such as action chunking and speculative decoding attempt to mitigate this latency by planning actions over horizons and leveraging lighter draft policies, yet are susceptible to stale observation-induced errors due to open-loop execution. This paper introduces Speculative Verification for VLA (SV-VLA), a framework that combines long-horizon open-loop macro-planning with lightweight, high-frequency closed-loop online verification. The approach achieves a balance between computational efficiency and control robustness by leveraging cheap verifiers for local validation and triggering expensive replanning only when warranted.
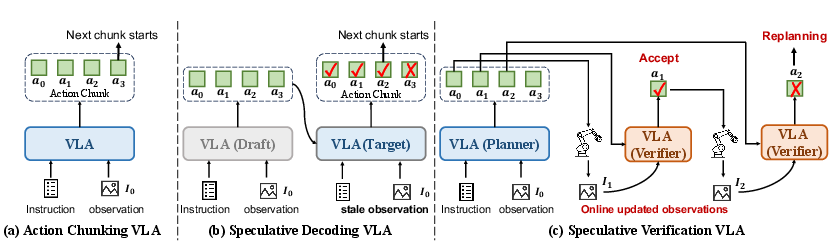
Figure 1: Comparison of action chunking, speculative decoding, and SV-VLA highlighting the trade-off between efficiency, adaptability, and robustness.
Methodology and Architectural Design
Macro-Planning with Open-Loop Chunking
The core of SV-VLA is the decoupling of high-capacity macro-planning and verification. At the start of each planning boundary, the heavy VLA model produces a macro action chunk of length K and a contextual planning feature. These action sequences are speculative and assume environmental dynamics will align with the model’s prediction based on the initial observation. This sharply amortizes VLA inference over K steps, but also exacerbates divergence risk in dynamic or stochastic settings.
Closed-Loop Lightweight Verification
During chunk execution, a lightweight verifier runs at every control step, accepting as input both the current observation (via a ViT-Tiny backbone) and the frozen planning context from the heavy VLA. The fused representation is used for reference action prediction. By comparing the reference and planned actions under an L1 norm and applying a normalized threshold τ, the system detects plan-environment divergence and triggers replanning—invoking the heavy VLA—if the deviation exceeds τ. This approach allows SV-VLA to re-enter the high-accuracy planning regime precisely when the open-loop plan becomes unreliable.
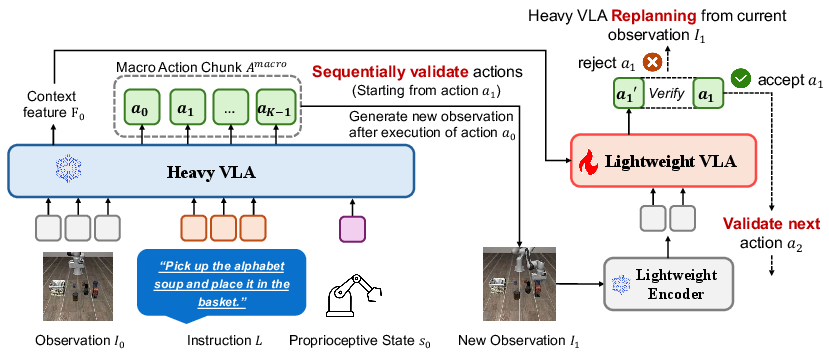
Figure 2: SV-VLA architecture. Chunk-level macro-planning is interleaved with frequent lightweight verification and deviation-based replanning.
This hierarchical design yields bounded inference cost: in the best case, it closely matches the efficiency of large-chunk open-loop chunking; in the worst case, it degenerates to step-wise heavy-model invocation.
Training Procedure
The macro-planner remains frozen post-pretraining, while only the lightweight verifier is trained. The verifier is optimized with an L1 regression loss over the target action under both updated observation and static planning context. This design choice ensures compatibility with existing VLA backbones—such as OpenVLA-OFT—while maintaining minimal additional inference overhead.
Experimental Results and Empirical Evaluation
Experiments on the LIBERO benchmark demonstrate the efficacy of SV-VLA across three major task suites: LIBERO-Goal, LIBERO-Object, and LIBERO-Spatial. The baseline with short chunks (K=8) provides strong robustness but at the highest inference cost, while naive long-chunk open-loop execution (K=64) results in a drastic drop in success rates due to uncorrected compounded errors.
SV-VLA, with the same chunk length (K=64), recovers much of the robustness lost by long-horizon chunking—improving average success from 79.5% to 90.9%—while maintaining a 2.17× speed-up over the K=8 baseline. Notably, in the LIBERO-Object suite, SV-VLA achieves 95.3% success, a substantial improvement over 77.2% from open-loop chunking. SV-VLA also outperforms speculative decoding baselines; for example, on LIBERO-Goal, SV-VLA reaches 94.4% success while speculative decoding achieves only 74.4% at much lower acceleration.
Qualitative results illustrate SV-VLA’s rapid failure detection and recovery capabilities: upon detecting a failed grasp during execution, the system aborts the macro chunk and replans, successfully recovering the task. Open-loop baselines, lacking such mechanisms, fail to adapt.
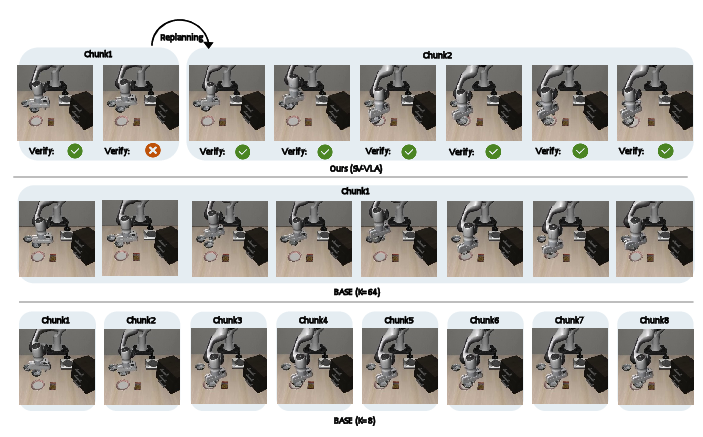
Figure 3: Qualitative comparison for object manipulation. SV-VLA successively replans on error detection while open-loop execution fails to recover.
Ablation studies reveal that removal of either the planning context or up-to-date observation sharply degrades performance. The deviation-based replanning mechanism is critical; without it, success drops to near-chance levels (15.5%). The threshold τ directly governs the efficiency-robustness trade-off.
Implications and Future Directions
The SV-VLA paradigm demonstrates that speculative verification is a powerful architectural motif for VLA-based control, as it allows practical deployment of large, sample-efficient models in real-world, latency-constrained settings. The significant empirical gains indicate that hierarchical decoupling of inference and verification, with minimal online learning budget for adaptation, is both feasible and effective for embodied AI.
Practical implications are immediate for robotics systems that necessitate both high semantic competence and real-time response, such as multi-step household manipulation or mobile robot navigation. The approach is architecturally compatible with any pretrained VLA, provided a suitable lightweight verification head can be integrated.
Theoretically, SV-VLA highlights the fundamental design incompatibility between open-loop speculative decoding (as in NLP) and embodied control, and proposes a solution that acknowledges the non-parallelizability of embodied environment transitions.
Looking forward, promising directions include:
- Adaptive or learned thresholding for deviation triggers;
- Direct local corrections by the verifier, reducing frequency of heavy replanning;
- Extension to hierarchical chunking and multi-modal verification;
- Hardware-aware scheduling for real-time guarantees;
- Generalization to richer closed-loop feedback, such as tactile or proprioceptive signals.
Conclusion
SV-VLA provides a systematic solution to the control-efficiency dilemma in VLA-driven robotic manipulation. By combining open-loop macro-planning with closed-loop lightweight verification, it robustly maintains execution reliability while amortizing expensive VLA inference. The system’s design facilitates practical, scalable embodied intelligence and sets the foundation for subsequent research exploiting speculative verification for adaptive robotic policy execution (2604.02965).