- The paper presents an autoregressive world action model that couples latent world prediction with UAV waypoint generation to enhance spatial reasoning.
- It employs a two-stage training framework, combining supervised grounding with action-aware GRPO for improved trajectory accuracy and spatial fidelity.
- The method outperforms traditional VLA baselines, demonstrating significant gains in both synthetic benchmarks and zero-shot real-world UAV deployments.
WorldVLN: Autoregressive World Action Model for Aerial Vision-Language Navigation
Motivation and Background
Vision-Language Navigation (VLN) lies at the intersection of spatial intelligence and embodied AI, requiring agents to interpret natural language instructions and execute navigation in complex 3D environments. Traditional Vision-Language-Action (VLA) architectures, extending Vision-LLMs (VLMs) with action heads, are effective in object recognition and instruction parsing but fundamentally limited in modeling the temporal, geometric, and causal world dynamics induced by an embodied agent’s actions. While the emergent capabilities of large-scale video generation models suggest the potential to capture spatiotemporal predictions, applying these generative priors directly to navigation exposes misalignments—primarily a gap between bidirectional full-sequence synthesis and the causal, closed-loop nature of navigation.
To address these challenges, the "WorldVLN: Autoregressive World Action Model for Aerial Vision-Language Navigation" (2605.15964) introduces an autoregressive world action model (WAM) with tailored training objectives and system architecture, directly coupling latent world state prediction with executable waypoint generation. The resulting approach demonstrates marked advancements on both synthetic benchmarks and in zero-shot real-world UAV deployment.
Core Architecture
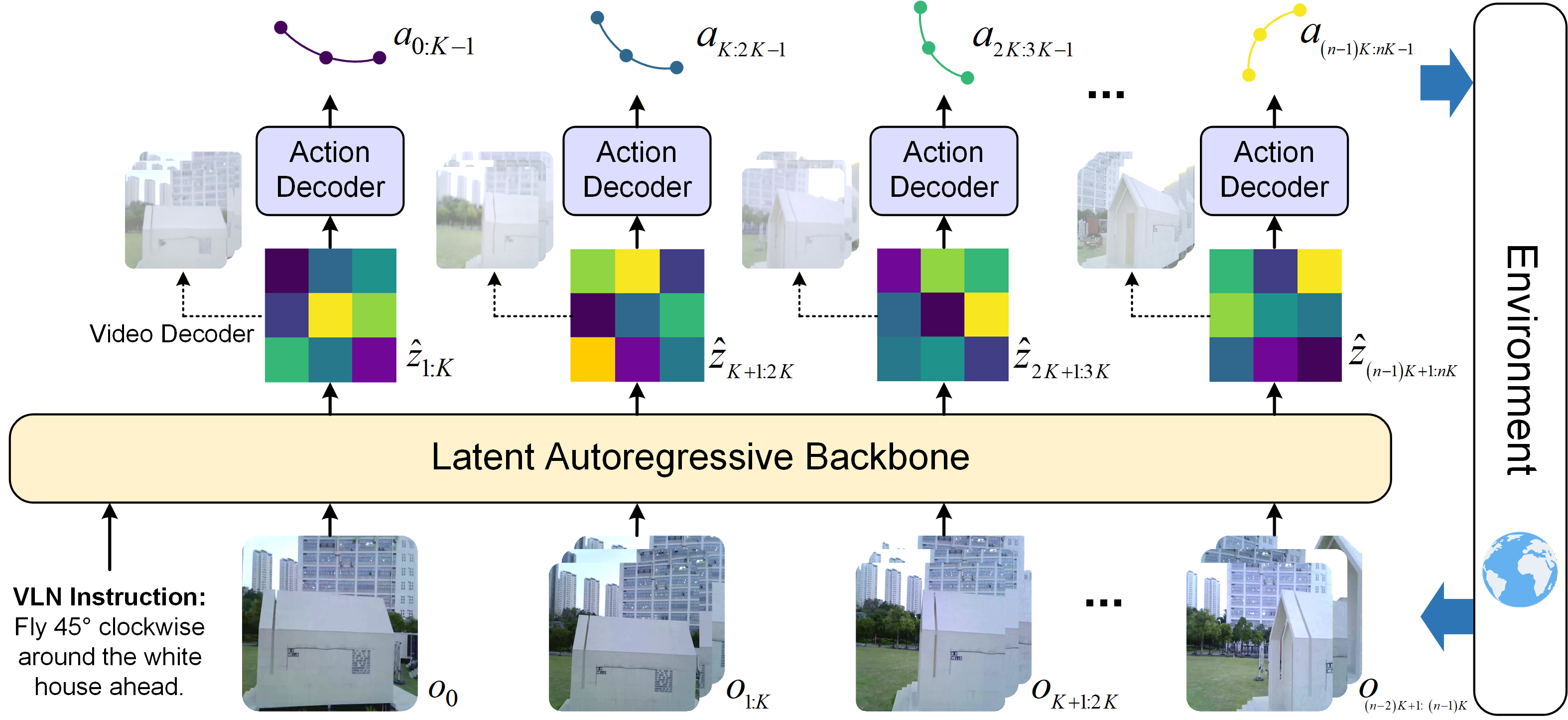
WorldVLN reframes aerial VLN as a prediction-driven world-action problem with a hierarchical, autoregressive control policy. The model comprises the following principal components:
The model eschews full-sequence bidirectional video generation in favor of causal, segment-by-segment prediction and plan refinement, yielding effective temporal memory and facilitating recovery from accumulated state estimation errors especially prevalent in UAV navigation.
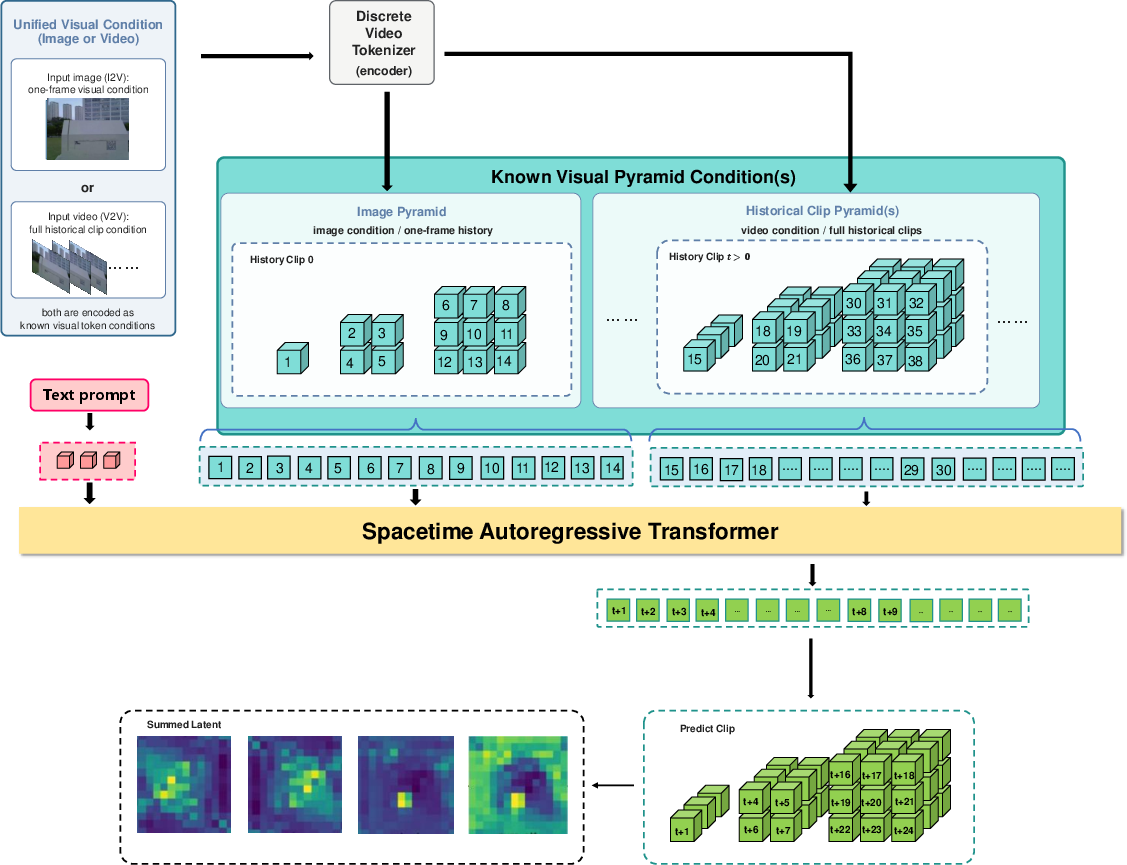
Figure 3: Latent-space spatiotemporal autoregressive world backbone modeling visual pyramid conditions to predict future clip pyramids as structured latents.
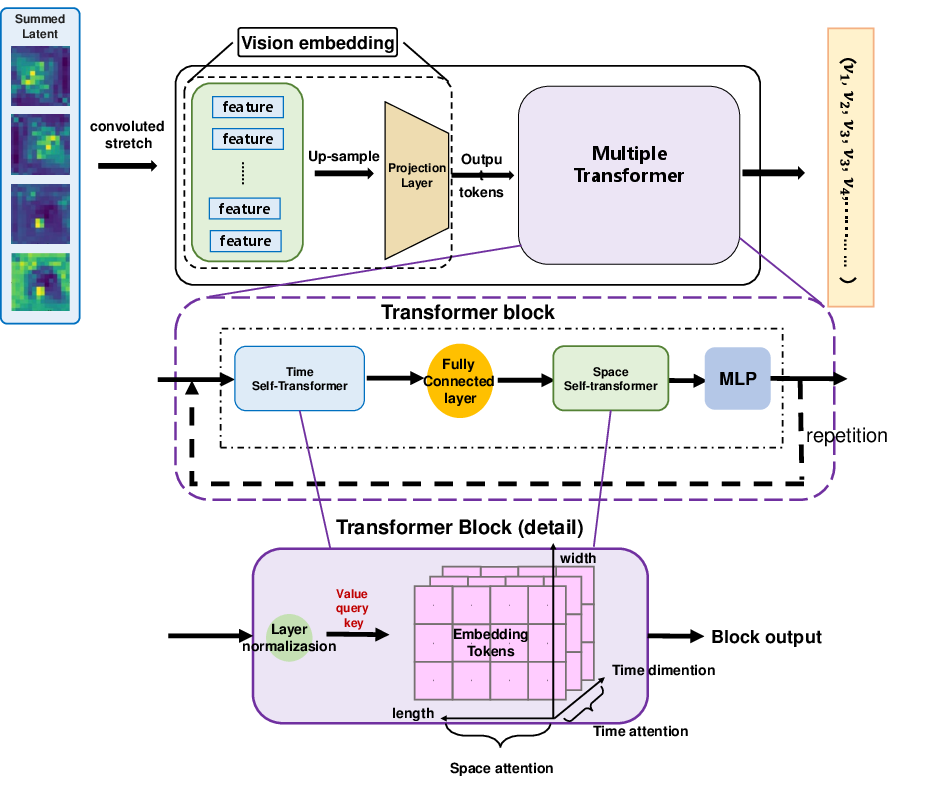
Figure 5: The action decoder translates world-model latents into UAV navigation actions via factorized temporal and spatial attention.
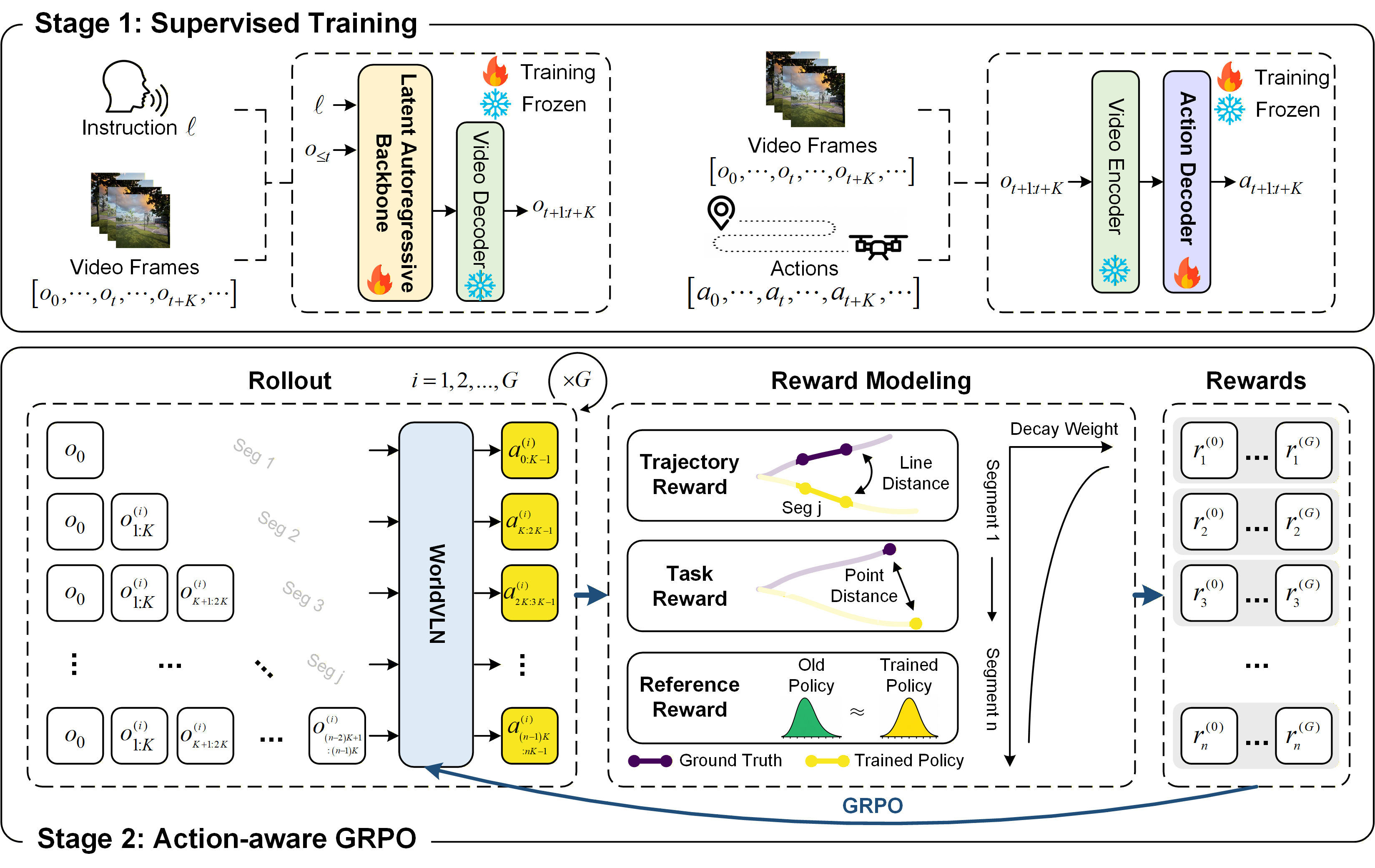
Two-Stage Training Framework
Stage 1: Supervised Grounding
Initially, the world-model backbone and action decoder are supervised using instruction-video and video-trajectory pairs, respectively. By directly optimizing for instructional consistency and trajectory accuracy in latent space, the model learns to generate latent world transitions that are directly action-decodable:
- The video backbone is fine-tuned to autoregressively predict future visual latents conditioned on both instructions and ground-truth history.
- The action decoder, initialized with video decoder and visual odometry priors, is trained to map latent transitions to expert actions.
Stage 2: Action-Aware GRPO
Standard imitation distillation proves brittle due to covariate shift and inability to optimize action consequences. WorldVLN introduces Action-Aware Group Relative Policy Optimization (GRPO):
Empirical Evaluation
Quantitative Benchmarks
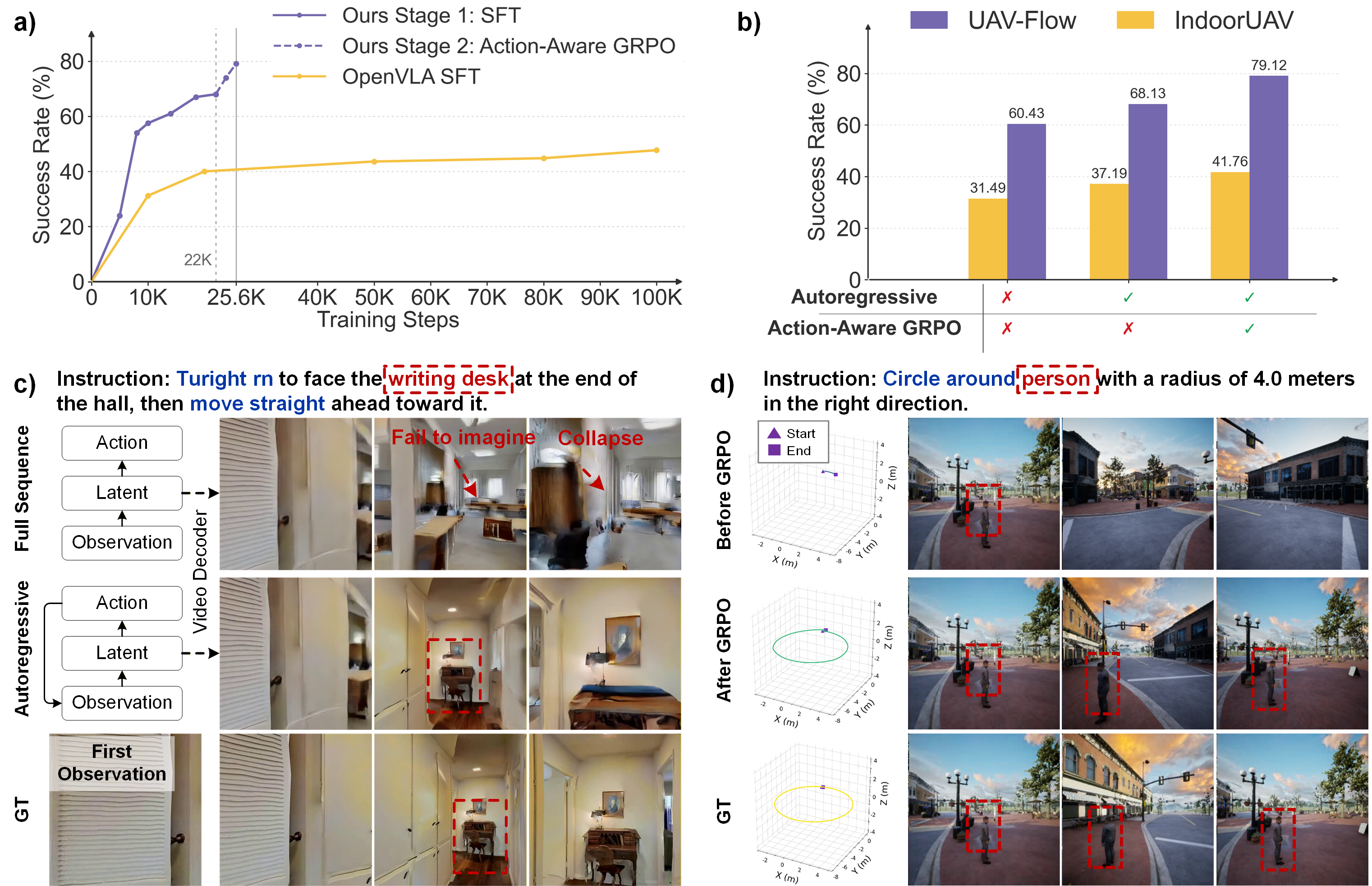
WorldVLN's performance is evaluated on UAV-Flow (outdoor) and IndoorUAV-VLA (indoor), benchmarks that measure fine-grained language-conditioned UAV control.
Key results:
- On UAV-Flow-Sim, WorldVLN achieves 79.12% (fixed instructions) and 78.02% (open-vocab) success rate—over $12$ percentage points above the strongest VLA baselines.
- On IndoorUAV-VLA, WorldVLN attains 41.76% success rate, outperforming the next-best method by $14.6$ points. Gains are even more pronounced on complex, multi-step settings.
These advances are consistent across both settings, with especially significant improvements on tasks demanding precise spatial composition and robust multi-step control.
Qualitative and Ablative Analyses
Figure 7: Qualitative case analysis highlighting superior spatial reasoning and action accuracy compared to VLA models in outdoor and indoor scenarios.
Zero-Shot Real-World UAV Transfer
WorldVLN policies, trained exclusively in simulation, demonstrate successful zero-shot transfer to a real UAV platform in both indoor and outdoor conditions. The system requires only egocentric RGB observations and delivers executable waypoint commands, with low-level stabilization managed by standard PX4 controllers.
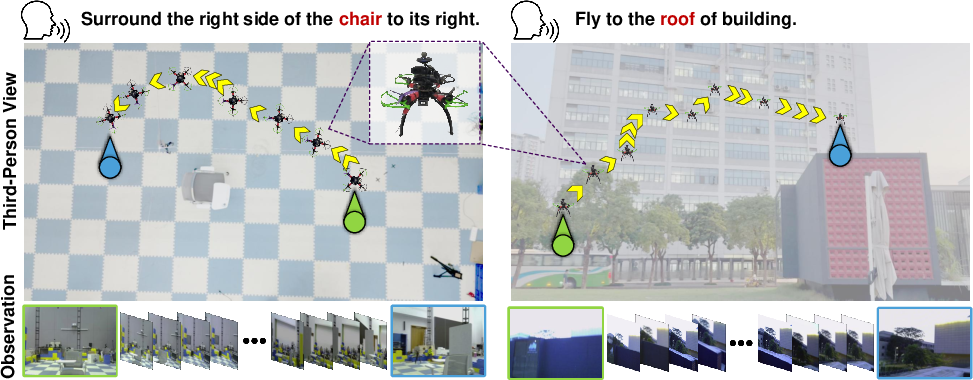
Figure 4: Real-world UAV deployment of WorldVLN—sim-to-real transfer of language-guided navigation in challenging environments.
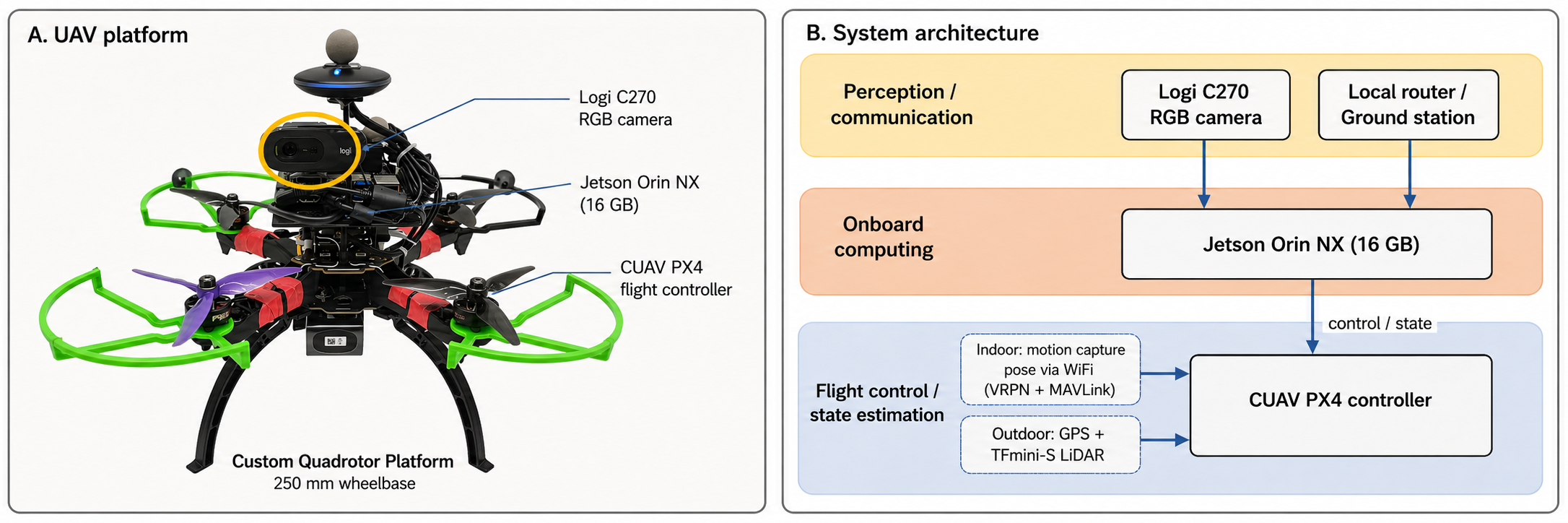
Figure 9: Real-world UAV platform and system architecture for closed-loop visual-language control.
These empirical results substantiate the model’s robustness and generalization capability, particularly critical for aerial robotics applications.
Practical and Theoretical Implications
The WorldVLN formulation demonstrates substantial progress in embodied AI and spatial reasoning:
- From Reactive to Predictive Embodied Agents: By centering navigation on latent world prediction and consequence-aware decision-making, WAMs overcome the limitations of purely reactive language-to-action mappings.
- Autoregressive Design for Geometric Consistency: Segment-wise, autoregressive updating curtails compounding state prediction error—a key challenge in aerial navigation domains with substantial egocentric displacement.
- Policy Optimization for Embodied Rollouts: Action-aware GRPO exemplifies a substantial methodological advance by closing the gap between visual plausibility and goal-directed action utility within the world-modeling paradigm.
On a theoretical front, explicit latent modeling of world transitions, tightly coupled with instruction and perceptual context, aligns with cognitive neuroscience evidence for predictive representations in spatial navigation.
Future Directions
The principal limitations identified involve model scalability for long-horizon VLN, compression for onboard inference, and robustness under adverse real-world conditions. Key directions include:
- Long-Horizon and Large-Scale Navigation: Extending the latent autoregressive capacity for complex, multi-stage instruction following.
- Model Compression and Edge Deployment: Developing more efficient architectures suitable for fully onboard, real-time UAV operation.
- Robustness and Safety: Augmenting training with domain randomization, uncertainty estimation, or auxiliary real-world datasets to enhance transfer and fail-safes.
Conclusion
WorldVLN introduces a principled advancement in aerial VLN by coupling an autoregressive world-model backbone with action-aware policy optimization, achieving strong gains over VLA methods in both simulation and zero-shot real-world deployment. The approach highlights the effectiveness of closed-loop, consequence-aware prediction in embodied AI and paves the way toward more capable, generalizable, and robust spatial intelligence systems. Further exploration of long-horizon, large-scale navigation and deployment under practical constraints will define subsequent progress in this domain.