- The paper introduces a hierarchical multi-agent architecture that decomposes complex data science workflows into specialized tasks managed by sub-agents.
- It achieves autonomous skill acquisition by synthesizing, verifying, and retaining new tools, leading to enhanced cross-task generalization and performance.
- Adaptive context compression minimizes token costs by summarizing key decisions, effectively managing long-horizon reasoning in large data science pipelines.
EvoDS: A Self-Evolving Data Science Agent with Autonomous Skill Acquisition and Context Management
Motivation
Despite the proliferation of LLM-based data science agents, current architectures remain fundamentally limited by static action spaces and inefficient handling of long-horizon contexts. Contemporary agents fail to abstract reusable skills from trial-and-error interactions, leading to repetitive exploration, suboptimal long-term performance, and vulnerability to context overflow in complex multi-stage data science pipelines. These deficiencies significantly hinder adaptability and scalability across heterogeneous and evolving task distributions.
Hierarchical Multi-Agent Architecture
EvoDS implements a hierarchical multi-agent architecture, comprising a Manager Agent orchestrating global strategy and coordination of specialized sub-agents assigned to core phases of the data science workflow (Cleaner, Featurizer, Modeler, Visualizer, Debugger). Each sub-agent maintains a scope-specific action space representing atomic, executable skills pertinent to its assigned domain. The Manager is responsible for subtask decomposition, sub-agent invocation, and dynamic context regulation via a global memory, while agents independently maintain localized context buffers. This architectural modularity localizes reasoning and compresses context growth, reducing combinatorial explosion in both action selection and context length.
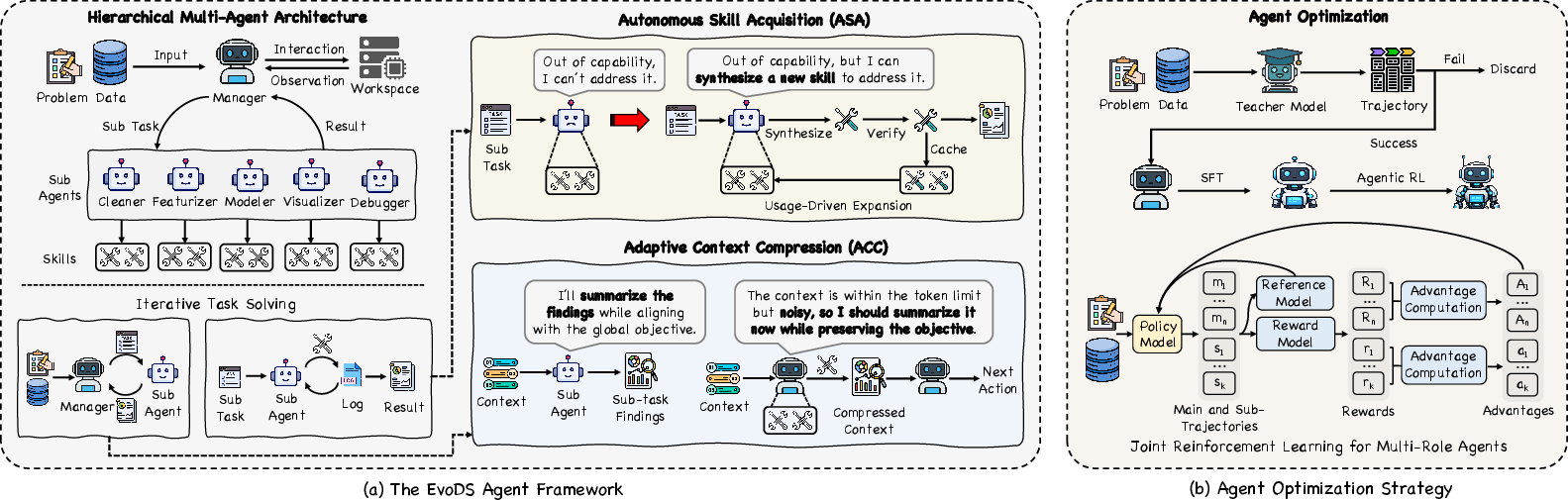
Figure 1: EvoDS employs a hierarchical multi-agent system with skill learning and adaptive context compression optimized via SFT and agentic RL.
Autonomous Skill Acquisition
To circumvent coverage limitations of static toolsets, EvoDS adopts a self-evolving, experience-driven skill acquisition mechanism. When sub-agents encounter previously unseen subproblems or capability gaps, they can autonomously synthesize new skills as structured tool descriptors (name, description, executable code) using the underlying LLM. Synthesized skills undergo in-environment verification and, upon repeated utility, are promoted from a transient cache to the persistent action space of the corresponding sub-agent. Usage frequency thresholds ensure only genuinely reusable or frequently required skills are retained, penalizing the proliferation of transient or low-value tools. This dynamic expansion drives continual improvement, enabling systematic knowledge consolidation and cross-task generalization.
Adaptive Context Compression
Long-horizon reasoning and repeated interaction between agents and environments rapidly saturate context windows and exacerbate the "lost-in-the-middle" failure modes. EvoDS mitigates this by treating context management as an agentic, learnable policy rather than a passive truncation or simplistic summarization. At two abstraction levels, (1) sub-agents locally compress execution traces into task outcome-focused summaries before returning results, and (2) the Manager Agent adaptively invokes a summarization tool based on the global context state and reasoning trajectory. The context buffer is replaced with a distilled summary retaining only semantically relevant transformations, constraints, and key decisions following information bottleneck principles. Theoretical analysis establishes that this design minimizes token cost while maximizing task-relevant information, leading to scalable long-horizon operation.
Agentic Reinforcement Learning Optimization
All agents in EvoDS share a single LLM backbone, differentiating role and behavior via prompt-based context and skill subspaces. Training proceeds in two stages: supervised fine-tuning (SFT) using high-quality, teacher-generated trajectories to establish robust initial policies, followed by multi-agent RL with reward functions targeting (i) main task success, (ii) subtask completion, (iii) context efficiency, and (iv) dialog turn compactness. The RL objective jointly optimizes both Manager and sub-agents using broadcasted group-reward policy optimization (GRPO), with gradient assignment leveraging trajectory segmentation induced by adaptive context compression events. Theoretical results prove that the hierarchical decomposition yields lower tool selection error rates compared to flat architectures, by shrinking the effective action space and reducing scoring variance under fixed context.
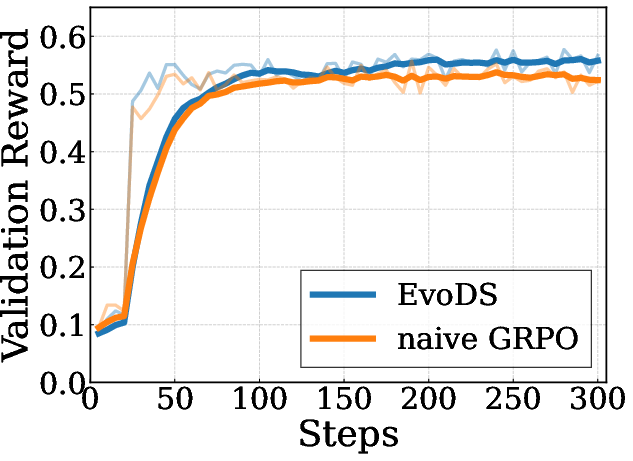
Figure 2: Joint multi-agent RL in EvoDS accelerates learning and yields superior validation rewards versus naive Manager-only GRPO optimization.
Empirical Evaluation and Numerical Analysis
EvoDS is benchmarked against both proprietary and open-source agents—including AutoGen, Code Interpreter, LAMBDA, Data Interpreter, DataMind, DeepAnalyze, LATM, and ML-Master2—across DABench, DA-Code, ScienceAgentBench, and MLE-Dojo. EvoDS achieves an average absolute improvement of 9.5% and a relative gain of 28.9% over the strongest open-source baseline, despite using a backbone (Qwen3-8B) substantially smaller than competitive data-analytic agents. Notably, EvoDS entirely eliminates out-of-token failures on tasks requiring contexts up to 25k tokens, a unique capability not seen in other open or closed models. The introduction and reutilization of synthesized skills drives an increase in cross-task generalization, with a reported skill reuse rate of 69%.
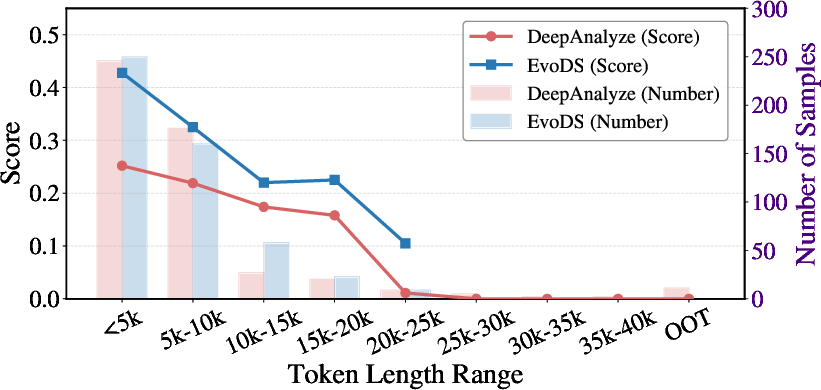
Figure 3: EvoDS maintains robust accuracy across increasing context token lengths, outperforming DeepAnalyze and abating out-of-token failures (OOT).
Ablation studies confirm that each module—hierarchical decomposition, skill acquisition, and context compression—contributes significant independent gains. Context management is critical, as disabling it (w/o acc) triggers sharp increases in out-of-token failures and degraded performance particularly on MLE-Dojo and ScienceAgentBench. RL-based skill generalization is measurable: "w/ reuse" settings using previously synthesized skills from held-out sets yield 2.9–9.3% accuracy improvements.
Qualitative Case Studies and Limitations
Detailed case analyses show that EvoDS can autonomously recognize the absence of a suitable predefined skill, synthesize a tool such as imbalanced_binary_classification, and deploy it efficiently to subsequent tasks with similar imbalance characteristics. Errors remain in open-ended domains such as quantitative finance, where the agent's reasoning is limited by the underlying LLM's world knowledge and domain-specific abstraction.

Figure 4: EvoDS demonstrates skill synthesis for new tasks, successful tool reuse in related tasks, and a typical failure due to lacking deep domain expertise.
Theoretical Implications
From an information-theoretic perspective, the action of the Manager Agent is shown to approximate an information bottleneck optimization. This formalizes the tradeoff between compressing the context for computational efficiency (entropy/token cost) and preserving predictive information relevant to successful task completion (mutual information with solution outcome). In the limit, the optimal summary distribution adheres to the exponentiated Kullback–Leibler divergence between the predictive distributions conditioned on full versus compressed context.
Future Directions
The work identifies pathways for further improvements. Integrating richer external knowledge sources, enhancing domain-specialization via fine-tuned adapters, and extending context regulation policies to manage interleaved machine learning and scientific discovery tasks are viable avenues. The demonstrated modularity positions EvoDS as a template for deploying scalable, continual-updating autonomous data science agents in both production and research pipelines.
Conclusion
EvoDS demonstrates that hierarchical multi-agent architectures, fully autonomous skill acquisition, and agentic, adaptive context compression are critical to closing the gap between current LLM-based data science agents and robust, scalable autonomous reasoning systems. Extensive benchmarking and analysis indicate substantial gains over state-of-the-art baselines in both performance and operational reliability. The integration of lifelong skill learning and rigorous context management provides a strong foundation for future systems that require dynamic adaptation and persistent experience accumulation in open-ended environments.

Figure 5: EvoDS decomposes data science problems into subtasks, invokes specialized tools, and adaptively adapts its execution strategy, with clear evidence of cross-task skill reuse.