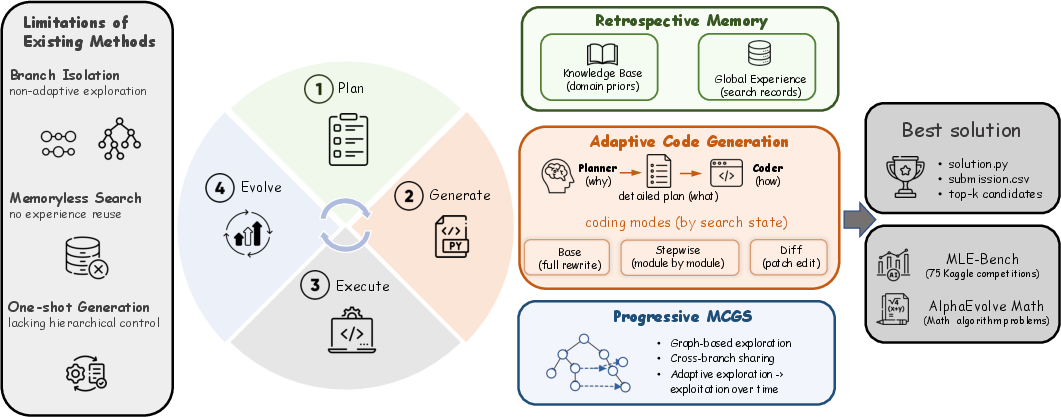
MLEvolve: A Self-Evolving Framework for Automated Machine Learning Algorithm Discovery
Abstract: LLM agents are increasingly applied to long-horizon tasks such as scientific discovery and machine learning engineering (MLE), where sustained self-evolution becomes a key capability. However, existing MLE agents suffer from inter-branch information isolation, memoryless search, and lack of hierarchical control, which together hinder long-horizon optimization. We present MLEvolve, an LLM-based self-evolving multi-agent framework for end-to-end machine learning algorithm discovery. By extending tree search to Progressive MCGS, MLEvolve enables cross-branch information flow through graph-based reference edges and gradually shifts the search from broad exploration to focused exploitation with an entropy-inspired progressive schedule. To allow the agent to evolve with accumulated experience, we introduce Retrospective Memory, which combines a cold-start domain knowledge base with a dynamic global memory for task-specific experience retrieval and reuse. For stable long-horizon iteration, we further decouple strategic planning from code generation with adaptive coding modes. Evaluation on MLE-Bench shows that MLEvolve achieves state-of-the-art performance across multiple dimensions including average medal rate and valid submission rate under a 12-hour budget (half the standard runtime). Moreover, MLEvolve also outperforms specialized algorithm discovery methods including AlphaEvolve on mathematical algorithm optimization tasks, demonstrating strong cross-domain generalization. Our code is available at https://github.com/InternScience/MLEvolve.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
MLEvolve: a simple, kid-friendly explanation
What is this paper about?
This paper introduces MLEvolve, a smart system that helps an AI learn how to build machine learning solutions by itself, step by step. Think of it like a team of helpful robots that design, write, test, and improve code to solve data problems (like the ones in Kaggle competitions). The key idea is “self-evolving”: the system gets better over time by sharing ideas across different attempts, remembering what worked, and planning changes carefully.
What questions does the paper try to answer?
Here’s what the authors wanted to fix in current AI coding systems:
- Different solution paths don’t share what they learn, so good ideas get stuck in one place.
- The system forgets past tries, so it repeats mistakes and can’t learn from experience.
- Planning and coding are tangled together, causing messy, risky changes every time.
In simple terms: How can we build an AI that explores many ideas, learns from its own attempts, and makes smart, controlled updates over many steps?
How does MLEvolve work?
Imagine a science fair team with:
- a coach who plans the next move,
- builders who write code,
- and a shared notebook where everyone writes what worked and what didn’t.
MLEvolve turns that idea into three parts:
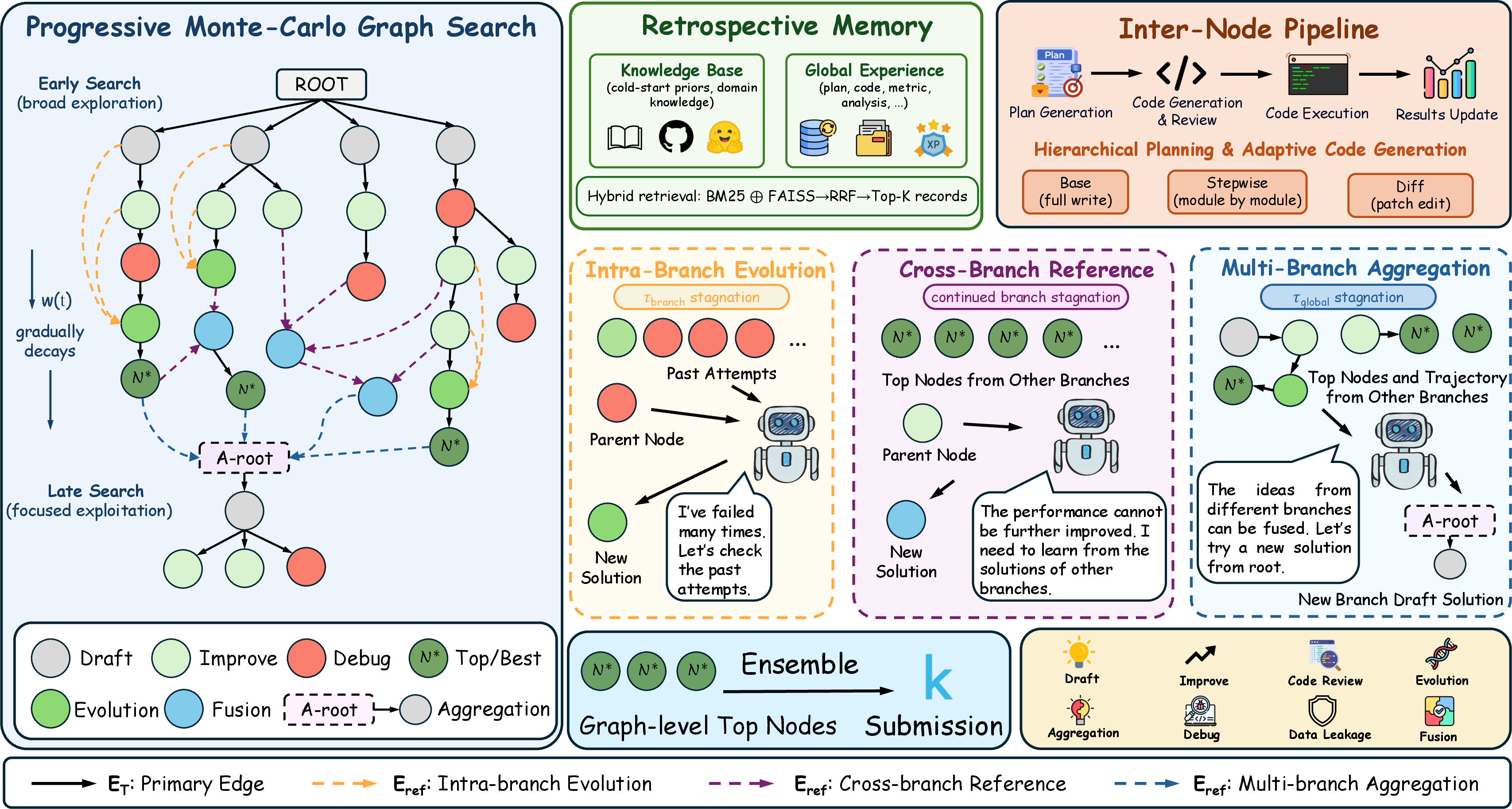
- Progressive Graph Search (explore widely, then focus)
- Normal searches follow a tree: one path splits into branches. MLEvolve uses a graph: branches can connect and share notes.
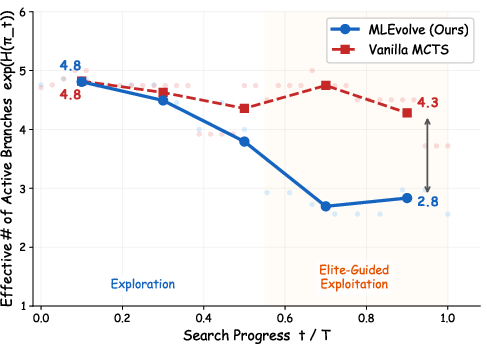
- Early on, it explores lots of ideas; later, it concentrates on the best ones (like cramming before a deadline).
- It has helpful “shortcuts”:
- Look back at your own branch’s history to avoid repeating mistakes.
- Borrow good pieces from other branches.
- Combine the best parts from multiple branches to start a stronger new branch.
- If a branch gets stuck (no improvements after several tries), the system switches strategy to shake things up.
- Retrospective Memory (learn from experience)
- Cold-start library: a small, curated “starter kit” of model choices and tips for common task types (like image or text problems). This reduces silly early mistakes.
- Global memory: after each run, the system stores what it tried, what happened, and why. Before planning or debugging, it searches this memory to reuse helpful lessons (using both keyword search and meaning-based search).
- It retrieves different things for different needs:
- Planning: fetches past successes and failures to guide the next plan.
- Debugging: looks up similar error messages and how they were fixed.
- Hierarchical Planning and Adaptive Code Generation (change the right thing, the right way)
- Planner vs coder: the planner decides what to change and why; the coder figures out how to change the code.
- Three coding modes:
- Base: write everything from scratch (good at the start).
- Stepwise: build module by module (like assembling a robot arm, then the sensor, then the controller).
- Diff: make small, precise edits (like fixing a bug or tweaking a setting). This keeps working code stable.
In short: MLEvolve searches smarter (with a graph), remembers better (with memory), and edits more carefully (with planning and diffed changes).
What did the experiments show, and why does it matter?
The authors tested MLEvolve on two kinds of challenges:
- MLE-Bench (75 real-world Kaggle-style tasks)
- These tasks range from easy to hard and measure how often a system gets “medal-level” results.
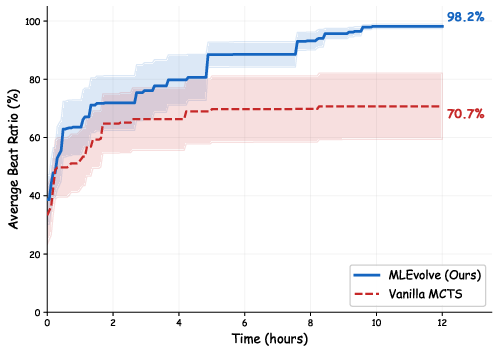
- With only 12 hours per task (half the typical time), MLEvolve:
- earned a medal on about 65% of tasks,
- got gold on about 35%,
- and made valid submissions 100% of the time.
- It beat many strong systems, even ones with more time.
Why it matters: It shows MLEvolve can build solid end-to-end solutions quickly and reliably, not just toy demos.
- Mathematical algorithm discovery (15 tough math optimization problems)
- These are different from ML pipelines, but still require trying, testing, and improving ideas.
- MLEvolve got the best result on 11 out of 15 problems compared to specialized math-discovery systems.
Why it matters: The approach isn’t limited to one domain; the “self-evolving” strategy works in other tough, open-ended problems too.
Extra investigations:
- Removing any one part (graph search, memory, or adaptive coding) made results worse. The graph search gave the biggest boost.
- Over time, MLEvolve naturally shifted from exploring many ideas to focusing on the best few (exactly what we want).
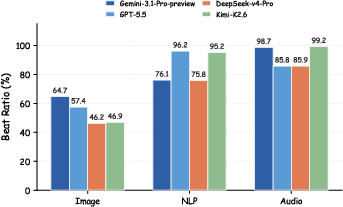
- It worked well with different LLMs (so it’s not tied to a single AI model).
- Performance kept improving late into the time budget, while simpler methods plateaued early.
Why is this important?
If AI can reliably plan, write, test, and improve code over many steps—while learning from its own attempts—it can:
- Save experts a lot of trial-and-error time.
- Produce strong solutions faster, even under tight time limits.
- Tackle broader scientific and engineering problems (not just standard ML tasks).
Bottom line
MLEvolve is like a disciplined, curious, and organized team of AI helpers:
- It explores widely, then zeroes in on what works.
- It keeps a memory of lessons learned, so it doesn’t repeat mistakes.
- It plans before coding and makes careful, controlled edits.
Because of these habits, it wins more often, wastes less time, and generalizes to new kinds of challenges. This could push forward automated machine learning, help with scientific discovery, and make long, complex AI projects more achievable.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues that future work could address, grouped for clarity.
- Method design and theory
- Lack of theoretical analysis of Progressive MCGS: no guarantees on convergence, regret, or sample complexity when mixing UCT with elite sampling via a time-dependent soft switch w(t); unclear conditions under which reference edges and the elite policy improve (or hurt) asymptotic performance.
- Credit assignment with reference edges: reference edges are excluded from backpropagation; no alternative credit-sharing or off-policy value attribution is explored, leaving open whether learning weights for references (or propagating partial credit) would yield better performance.
- Reward shaping is coarse (-1/1/2) and task-agnostic: the framework does not examine sensitivity to reward granularity, metric scaling, or delayed rewards (e.g., validation improvements only after several dependent changes).
- Entropy-inspired scheduling is heuristic: the functional form of w(t), its coupling to observed entropy H(π_t), and any closed-loop control (e.g., target entropy tracking) are not derived or tuned systematically.
- Stagnation thresholds (τ_branch, τ_global) are fixed and hand-set: no adaptive criterion, statistical test, or learning-based trigger for mode switching (e.g., intra-branch, cross-branch, aggregation) is provided.
- Retrospective memory and retrieval
- Memory scope and persistence are ambiguous: it is unclear whether the “global memory” is per-task or cross-task, and how knowledge is reused across different datasets/domains while avoiding negative transfer.
- Memory growth and maintenance are unspecified: no retention, deduplication, decay, or summarization policy is detailed for long runs, risking retrieval noise, index bloat, and degraded precision at scale.
- Embedding and retrieval models are not described: the choice of encoder, update cadence for FAISS indices, and retrieval latency/cost under large memory sizes are not characterized.
- No robustness evaluation for retrieval: the system does not quantify susceptibility to spurious matches, polysemy, or domain shift; ablations do not measure performance with noisy or conflicting memory entries.
- No explicit reflection/compression: while avoiding extra LLM calls reduces cost, the paper does not test whether lightweight, periodic consolidation (e.g., clustering or distilled “lessons learned”) could improve memory quality without heavy reflection.
- Hierarchical planning and code generation
- Mode-selection policy is under-specified: criteria for switching among Base/Stepwise/Diff modes are not formalized; no learned policy or uncertainty-aware selection is explored.
- Code fusion mechanics are opaque: for cross-branch reference and multi-branch aggregation, concrete strategies to reconcile conflicting APIs, dependencies, or design patterns are not detailed, nor are failure modes quantified.
- Stability vs. innovation trade-off: the framework does not analyze when diff-based refinement impedes necessary larger refactors or architectural changes, and how to detect when a “reset” is beneficial.
- Graph search operators and scaling
- Reference set sizing and selection are heuristic: top-N and k-nearest choices are not justified or tuned; no study on how N, k, and reference edge density affect performance, memory, or runtime.
- Graph size and complexity are unreported: the paper does not provide statistics on node/edge counts, branching factor, or indexing overhead as the search progresses.
- Cycles and redundancy: safeguards for cyclic references, redundant branches, or degenerate “copy-and-tweak” loops are not discussed.
- Evaluation methodology and fairness
- Limited apples-to-apples comparisons: baselines use different backbones, budgets (often 24 h vs. 12 h), and hardware; results may conflate framework benefits with model/budget advantages.
- Statistical significance is not established: beyond ±SEM for MLE-Bench, no hypothesis tests or effect-size analyses are reported; AlphaEvolve results lack multi-seed reporting.
- Benchmark coverage: ablations are on MLE-Bench Lite (22 tasks) rather than the full 75; cross-domain tests cover only 15 AlphaEvolve tasks; generalization to other scientific/engineering domains remains untested.
- Metric diversity: emphasis on medal rate and gold rate; no granular analysis of time-to-first-valid, failure/retry distributions, or error-resolution efficiency across tasks.
- Leakage and safety checks are unevaluated: the Data Leakage Agent’s precision/recall, false-positive cost, and efficacy against subtle leakage are not quantified.
- Efficiency, cost, and reproducibility
- Compute and cost footprint are high: 21 vCPUs, 234 GB RAM, an H200 GPU, and a strong proprietary LLM are required; token counts, API costs, and energy usage are not reported.
- Sensitivity to LLM backbone/version drift: while a small multi-model test is shown, large-scale results depend on proprietary preview models; reproducibility across model updates and open-weight backbones is uncertain.
- Hyperparameter sensitivity is underexplored: schedules (c(t), w(t)), thresholds (τ_branch, τ_global), elite set size K, and retrieval fusion α are not systematically tuned or stress-tested.
- Determinism and seeding: with temperature 1.0 and multi-agent stochasticity, reproducibility guarantees are unclear; no guidance is offered for controlled re-runs.
- Reliability and safety of agentic coding
- Execution sandboxing and security: the paper does not detail isolation, file/network permissions, or mitigation against harmful code generations and supply-chain risks.
- Failure modes of automated debugging: no breakdown of error types, fix success rates, or cases that trigger repeated “oscillation” between debugging and regeneration.
- Knowledge base (KB) construction and ethics
- KB provenance and licensing: the process for curating/synthesizing models and guidelines from open sources/competitions is not specified; potential license conflicts or Kaggle policy implications are unaddressed.
- KB impact quantification: no ablation on KB size/quality, coverage across modalities, or risk of inadvertently encoding benchmark-specific solutions (data contamination).
- Open research directions
- Learning mode and operator policies: can the system learn when to explore, reference, aggregate, or refactor via reinforcement/meta-learning instead of fixed heuristics?
- Differentiable or learned credit assignment on graphs: explore GNN-based value backup or learned edge weights to propagate credit through reference edges.
- Continual and cross-task memory: develop scalable, cross-task memory with selective transfer and safeguards against negative transfer, including task/task-cluster conditioning.
- Resource-aware scheduling: jointly optimize exploration/exploitation and compute allocation under strict wall-clock, token, and energy constraints.
- Human-in-the-loop and interpretability: integrate minimal expert feedback, provide interpretable rationales for plan/code edits, and measure human trust/calibration impacts.
Practical Applications
Immediate Applications
The following applications can be deployed now using the MLEvolve framework and its released code, with standard LLM and compute resources.
- Industry (Software/Data Science): Rapid end-to-end ML pipeline prototyping and baselining
- What: Auto-generate, debug, and iteratively improve tabular/NLP/image ML pipelines for internal analytics, forecasting, and classification tasks.
- Sectors: Software, retail, marketing, operations, finance.
- Tools/Workflows: “MLEvolve Workbench” integrated into Jupyter/VS Code; CI job that spins up pipelines against a dataset, evaluates, and posts leaderboard-style metrics.
- Dependencies/Assumptions: Access to a capable LLM (e.g., Gemini-/GPT-class), a sandboxed execution environment, clear evaluation metrics, and curated domain KB entries for target tasks.
- MLOps: Continuous model improvement and regression triage
- What: Use Progressive MCGS to explore “diff” edits when performance drifts; rank candidate improvements; auto-run A/B tests offline before promotion.
- Sectors: Software, e-commerce, fintech.
- Tools/Workflows: Nightly “model refresh” jobs that leverage Retrospective Memory to avoid repeating past failures; PR-like diff reviews for model updates.
- Dependencies/Assumptions: Versioned data/model artifacts, offline evaluation pipelines, human-in-the-loop approval.
- Software Engineering: Automated code debugging for ML pipelines
- What: The Debug Agent retrieves similar past errors and applies minimal diffs to fix import issues, dependency mismatches, or shape/type bugs.
- Sectors: Software, education, startups.
- Tools/Workflows: CI/CD bot that proposes patch diffs for failing ML jobs; code-review gate using the Code Review Agent.
- Dependencies/Assumptions: Reliable error logging, unit tests, and policy for safe automated patches.
- Enterprise Analytics: Knowledge reuse across teams/projects
- What: Retrospective Memory stores successful/failed runs; hybrid retrieval avoids “forgetting” and accelerates new projects with similar characteristics.
- Sectors: Enterprise BI, consulting, supply chain.
- Tools/Workflows: Central FAISS-backed memory service; RRF retrieval API for agents; tagging and governance dashboards.
- Dependencies/Assumptions: Metadata standards for tasks/runs, data access controls, PII governance.
- Education: ML lab assistant and teaching aid
- What: Guided, stepwise pipeline construction with explanations; students see planner rationale and diff-based changes.
- Sectors: Higher education, MOOCs, bootcamps.
- Tools/Workflows: Classroom notebook extension that demonstrates exploration vs. exploitation and memory-driven planning.
- Dependencies/Assumptions: Academic compute sandbox, curated domain KB for course datasets.
- Competitive Data Science/Kaggle: Submission factory and strategy refinement
- What: Iteratively synthesize strategies from multiple strong solutions via cross-branch reference and aggregation; reduce time to leaderboard.
- Sectors: DS competitions, hackathons.
- Tools/Workflows: “Elite set” exploration mode to concentrate late-stage compute on top candidates.
- Dependencies/Assumptions: Clear scoring API, acceptance of automated submission cadence.
- Research (Algorithmic Optimization): Combinatorial/mathematical heuristic discovery
- What: Apply to packing, autocorrelation, or ratio optimization tasks; generalize AlphaEvolve-like workflows.
- Sectors: Operations research, logistics, telecom.
- Tools/Workflows: “Algorithm R&D Workbench” that proposes heuristics, evaluates, and aggregates cross-branch insights.
- Dependencies/Assumptions: Deterministic evaluators, clear objective functions, bounded compute.
- SMBs and Daily Life: Low-code forecasting/classification assistants
- What: Generate baselines for sales forecasting, churn prediction, or simple NLP classification with diff-based refinements.
- Sectors: Small businesses, NGOs.
- Tools/Workflows: Web UI where users upload CSVs and pick metrics; the agent proposes and iterates pipelines.
- Dependencies/Assumptions: Clean data upload paths, privacy policies, cost controls for LLM/API usage.
- Policy and Compliance: Auditable ML development trails
- What: Use hierarchical planning and memory logs to create traceable development histories for internal audit/model cards.
- Sectors: Regulated industries (healthcare, finance).
- Tools/Workflows: Exportable planning trees/graphs and diff logs; “explain changes” reports.
- Dependencies/Assumptions: Secure logging, retention policies, governance frameworks.
- Cross-LLM Deployments: Model-agnostic agent workflows
- What: Swap backbones (Gemini, GPT, DeepSeek, etc.) while keeping the same agent pipeline for robustness and cost-performance tuning.
- Sectors: Platform teams, ML platforms.
- Tools/Workflows: “LLM switchboard” that routes planner vs. coder calls to different models based on domain or cost.
- Dependencies/Assumptions: API availability, latency budgets, prompt compatibility.
Long-Term Applications
These applications require further research, integration effort, domain adaptation, or scale-up beyond current benchmarks.
- AI for Science: Automated experimental design and lab automation
- What: Extend Retrospective Memory and Progressive MCGS to plan experiments, fuse cross-branch protocols, and refine assays.
- Sectors: Materials science, chemistry, biology.
- Tools/Workflows: “Autonomous Experiment Planner” interfacing with ELNs/LIMS and lab robots.
- Dependencies/Assumptions: High-fidelity simulators/assays, device APIs, rigorous safety gates and human oversight.
- Healthcare: Self-evolving clinical modeling pipelines (research-to-clinic)
- What: Draft and iteratively refine EHR or imaging models; auto-generate model cards and audit trails.
- Sectors: Health systems, medtech.
- Tools/Workflows: Sandboxed, de-identified research environments; diffs + provenance for regulatory review.
- Dependencies/Assumptions: HIPAA/GDPR compliance, bias mitigation, clinical validation, governing committees.
- Finance: Strategy and risk model discovery with auditability
- What: Explore and compose cross-branch trading/risk heuristics with strict backtesting and compliance gating.
- Sectors: Banking, asset management, insurance.
- Tools/Workflows: “Agentic Backtester” with progressive exploitation, scenario stress-testing, and guardrails.
- Dependencies/Assumptions: Market microstructure modeling, strict reproducibility, regulatory approval.
- Robotics and Control: Policy/algorithm co-design in simulation
- What: Use hierarchical planning and diff edits to evolve controllers and perception stacks; aggregate strong branches.
- Sectors: Warehouse robotics, autonomous systems.
- Tools/Workflows: Sim-to-real pipelines with safety verifiers; multi-agent policy search with MCGS.
- Dependencies/Assumptions: Realistic simulators, domain randomization, robust transfer methods.
- Energy and Utilities: Scheduling and dispatch optimization
- What: Discover heuristics for unit commitment, demand response, or grid reconfiguration via algorithmic search.
- Sectors: Energy, smart grids, logistics.
- Tools/Workflows: “Operations Research Agent” integrating with grid simulators and historical datasets.
- Dependencies/Assumptions: Accurate system models, latency/real-time constraints, human-in-the-loop oversight.
- Software 2.0: Autonomous codebase evolution at scale
- What: Planner-coder decoupling + diff mode for large monorepos; cross-branch knowledge flow to reuse patterns across services.
- Sectors: Large-scale software platforms.
- Tools/Workflows: Org-wide Retrospective Memory; staged rollouts; formal checks.
- Dependencies/Assumptions: Static analysis, formal verification, strong testing suites, rollback strategies.
- Compiler/HPC Optimization: Self-evolving performance tuning
- What: Discover code transformations, kernel parameters, and scheduling heuristics with MCGS and memory of past speedups.
- Sectors: HPC, chip design, cloud providers.
- Tools/Workflows: “Auto-Optimize” pipelines tied to profilers and benchmark suites.
- Dependencies/Assumptions: Deterministic performance metrics, hardware access, safety bounds.
- Supply Chain and Transportation: Heuristic search for routing/scheduling
- What: Evolve composite heuristics by aggregating cross-branch strategies for VRP, packing, or timetabling.
- Sectors: Logistics, manufacturing.
- Tools/Workflows: Digital twins for evaluation; elite-set exploitation for late-stage refinement.
- Dependencies/Assumptions: High-fidelity simulators, changing constraints and SLAs, explainability for planners.
- Drug Discovery and Materials: Algorithmic pipelines for design cycles
- What: Iteratively refine docking/scoring/training stages; reuse cross-project memory; compose multi-branch insights.
- Sectors: Pharma, materials engineering.
- Tools/Workflows: “Design-Build-Test-Learn” agent with memory retrieval and lab data integration.
- Dependencies/Assumptions: Data access/IP, assay noise modeling, regulatory guardrails.
- Governance and Policy Tech: Dynamic compliance and monitoring agents
- What: Auto-generate and update model cards, data lineage, and change logs; run conformance checks before deployment.
- Sectors: Government, regulated industry.
- Tools/Workflows: “Compliance Copilot” integrating with policy engines and audit systems.
- Dependencies/Assumptions: Standardized reporting schemas, provable reproducibility, acceptance by regulators.
- Cross-Organizational Knowledge Networks: Federated Retrospective Memory
- What: Privacy-preserving aggregation of learnings across organizations to accelerate ML development without sharing raw data.
- Sectors: Healthcare consortia, financial alliances.
- Tools/Workflows: Federated retrieval with reciprocal rank fusion over hashed/embodied summaries.
- Dependencies/Assumptions: Privacy-preserving retrieval, legal agreements, standardization of records.
- Safety-Critical Systems: Verified agentic changes with formal methods
- What: Combine diff mode with formal verification to guarantee safe modifications in avionics, automotive, or medical software.
- Sectors: Aerospace, automotive, medical devices.
- Tools/Workflows: “Verified Diff Agent” that checks changes against temporal logic/contract specs.
- Dependencies/Assumptions: Formal specs available, model-checking toolchains, certification pathways.
- Organizational R&D: Self-evolving research assistants
- What: Agents that accumulate cross-project experience to propose experiments, reuse analyses, and maintain living knowledge graphs.
- Sectors: Corporate labs, academia.
- Tools/Workflows: Research graph with reference edges linking hypotheses, code, and outcomes; progressive scheduling of effort.
- Dependencies/Assumptions: Knowledge curation, incentives for sharing, IP management.
- Citizen Data Science Platforms: Guided AutoML with guardrails
- What: Platformized version allowing non-experts to specify objectives and iterate safely with transparent diffs and rationale.
- Sectors: Public sector, NGOs, education.
- Tools/Workflows: Wizard-driven setup; human override on deployment; explainability-by-design.
- Dependencies/Assumptions: Strong UX, transparent scoring, budget control and content moderation.
- Multi-Agent Ecosystems: Cross-branch collaboration at scale
- What: Teams of specialized agents coordinating via reference edges and elite sets to tackle large, multi-stage problems.
- Sectors: Complex systems engineering, cross-disciplinary science.
- Tools/Workflows: Agent orchestration platforms with scheduling policies guided by entropy-aware exploration.
- Dependencies/Assumptions: Robust coordination protocols, failure isolation, monitoring and observability.
Notes on Feasibility (Common Assumptions/Dependencies)
- Model quality and cost: Results depend on access to strong LLMs; costs scale with search horizon.
- Compute and sandboxing: Requires reliable, isolated execution environments with resource quotas and logging.
- Metrics and oracles: Clear, deterministic evaluation metrics are crucial for stable credit assignment and search.
- Knowledge curation: Domain KBs and memory stores must be curated/governed to avoid leakage and bias.
- Human oversight: Especially in regulated or safety-critical contexts, human review remains essential.
- Security and privacy: Strict data governance and audit trails are needed for production contexts.
Glossary
- Backpropagation: In search algorithms like MCTS/MCGS, the step that propagates the obtained reward from a newly evaluated node back up to its ancestors to update their value estimates. Example: "Backpropagation. After simulation, the reward is propagated to the root only along primary edges ."
- Branch-level stagnation: A condition detecting lack of progress within a search branch after several steps, used to trigger specialized operators (e.g., reflections or cross-branch references). Example: "Branch-level stagnation: triggered when a branch produces $\tau_{\text{branch}$ consecutive expansions without improving its best metric."
- Cold-start initialization: Using a static knowledge base to bootstrap solution generation when the agent lacks task-specific experience. Example: "combining a static domain knowledge base for cold-start initialization with a dynamic global memory that automatically accumulates and retrieves historical experience during search;"
- Credit assignment: The problem of attributing success or failure to particular decisions or actions during learning or search; stable reward design improves this process. Example: "This structure distinguishes failed runs, feasible but non-improving attempts, and actual improvements, yielding stable credit assignment during MCGS."
- Cross-branch reference: An expansion operator that incorporates information from strong solutions in other branches to guide the current branch’s improvement. Example: "(3) Cross-branch reference ($R = \mathcal{R}_{\text{cross}(N)$)."
- Diff mode: A code-generation strategy that applies targeted, minimal edits (diffs) to an existing codebase instead of rewriting it entirely. Example: "Diff mode: Targeted diff edits on the existing code."
- Elite-Guided exploitation: A selection strategy that prioritizes top-performing nodes globally (the “elite set”) to intensify search on promising solutions. Example: "In the Elite-Guided exploitation mode, the system bypasses local tree traversal and selects from an elite set of top- globally best-performing nodes, weighted by inverse rank:"
- FAISS: A library (Facebook AI Similarity Search) for efficient vector similarity search and clustering, often used for semantic retrieval. Example: "via a combination of lexical keyword matching and FAISS~\citep{johnson2019faiss}-based semantic search"
- Hierarchical Planning with Adaptive Code Generation: A design that separates strategic planning from implementation and dynamically chooses between generation modes (full, stepwise, diff) based on the search state. Example: "Hierarchical Planning with Adaptive Code Generation decouples strategic planning from code implementation and selects among different coding modes according to the search state."
- Intra-branch evolution: An operator that references recent nodes within the same branch to reflect on what worked or failed and guide more informed refinements. Example: "(2) Intra-branch evolution ($R = \mathcal{R}_{\text{hist}(v_t, k)$)."
- Monte Carlo Graph Search (MCGS): A graph-structured extension of MCTS that allows cross-branch information flow and reuse via reference edges during search. Example: "The MCGS process follows the classical MCTS loop of selection, expansion, simulation, and backpropagation, with a progressive exploration schedule in the selection phase and graph-based expansion types."
- Monte Carlo Tree Search (MCTS): A simulation-based search algorithm that balances exploration and exploitation by iteratively building a search tree through selection, expansion, simulation, and backpropagation. Example: "Progressive MCGS extends MCTS with graph-based cross-branch information flow and a progressive exploration schedule."
- Multi-branch aggregation: An operator that synthesizes insights from multiple strong branches to create a new branch starting point, fostering solution composition. Example: "(4) Multi-branch aggregation ($R = \mathcal{R}_{\text{agg}$)."
- Planner-Coder Decoupling: Separating high-level decision-making (what to change) from low-level implementation (how to change it) to improve control and stability in iterative coding. Example: "We decouple strategic planning from code generation to separate global reasoning from local implementation."
- Reciprocal Rank Fusion (RRF): A method to combine multiple ranked retrieval lists by fusing their reciprocal ranks, improving robustness of search results. Example: "fused through Reciprocal Rank Fusion (RRF):"
- Reference edges: Graph edges that link a node to non-parent nodes whose information it incorporates; used for knowledge transfer without affecting backpropagation. Example: "Reference edges $E_{\text{ref}$: $(r,v) \in E_{\text{ref}$ denotes that additionally incorporates information from node beyond its parent node."
- Retrospective Memory: A memory mechanism that pairs a domain knowledge base with a dynamic store of experiences to retrieve and reuse task-specific knowledge during search. Example: "we introduce Retrospective Memory, which combines a cold-start domain knowledge base with a dynamic global memory for task-specific experience retrieval and reuse."
- Shannon entropy: An information-theoretic measure of uncertainty or dispersion in a probability distribution; here, used to quantify how spread out branch selection is. Example: "Within a local time window, the branch selection frequencies form an empirical distribution , whose Shannon entropy quantifies the dispersion of search effort."
- Stage-aware retrieval: Memory retrieval that adapts to the current workflow stage (e.g., planning vs. debugging) using stage-specific queries and filters. Example: "Agents retrieve memory records with stage-specific queries and filters:"
- UCT criterion: The Upper Confidence bound applied to Trees selection rule that balances exploration and exploitation during node selection in MCTS. Example: "identify a node for expansion using the UCT criterion:"
Collections
Sign up for free to add this paper to one or more collections.

