- The paper introduces an evolvable LLM-driven agent framework that integrates autonomous skill evolution with hierarchical sub-agent delegation.
- It employs a modular, dual-loop system combining real-time execution with offline analytics for continuous skill enhancement.
- Experimental evaluations show notable gains with GPT5.2, while also emphasizing compatibility challenges with models like GPT4.1 and Qwen.
EvoAgent: Evolvable LLM Agent Architecture with Skill Learning and Multi-Agent Delegation
Motivation and Contributions
The paper "EvoAgent: An Evolvable Agent Framework with Skill Learning and Multi-Agent Delegation" (2604.20133) introduces an LLM-driven agent architecture that fuses autonomous skill learning with hierarchical sub-agent delegation. The motivation arises from the rising task complexity in professional and enterprise environments, where agents must move beyond statically authored toolchains to systems capable of structured, adaptive, and evolvable competencies. The framework leverages a systems engineering paradigm termed Harness Engineering, prioritizing external control layers for model constraint, observability, and adaptation—thereby shifting the focus from model-centric to harness-centric reliability.
Key technical contributions comprise: (1) structured, multi-file skill units with evolvable metadata and dynamic invocation, (2) a user-centered closed-loop mechanism for persistent skill self-evolution based on real-world feedback (removing explicit label dependency), (3) hierarchical main/sub-agent delegation for complex multi-stage task decomposition, and (4) a three-layer memory architecture for long-term context and knowledge accumulation.
System Architecture and Methodology
The architecture is explicitly modular and layered, separated into API entry, orchestration, runtime, tool/session, and persistence layers.

Figure 1: The EvoAgent System Architecture demonstrates the hierarchical integration of API handling, orchestrator logic, runtime execution, resource interfaces, and data persistence.
A formal MDP-based framework models the agent-environment interaction. The state includes dialogue history, skill base, user profile, and memory compression status, supporting Markovian transitions driven by skill selection, tool use, and context updating. Each skill is a multi-component package (name, description, triggers, instruction, references, metadata), where metadata supports both prioritization and longitudinal evaluation.
Skill matching employs a three-stage pipeline—keyword, embedding-based, and LLM-centric intent matching—balancing efficiency and recall. Sessions proceed via dual loops: the deterministic, low-latency online execution, and an asynchronous, analytic offline loop responsible for evolutionary skill and memory augmentation. The offline loop performs session reviews, extracts new skills, and evaluates existing ones for maturity across fine-grained stages.
Experimental Evaluation
Capability Amplification
Integrating EvoAgent with GPT5.2 yields quantifiable improvement, particularly in professional foreign trade scenarios with complex, multi-turn tasks. Evaluations utilize both surface-level and deep LLM-as-Judge metrics, focusing on professionalism, accuracy, completeness, practicality, and language quality.
Numerical Results: For the principal dimensions, EvoAgent delivers a +2.059 improvement in professionalism (from 2.703 to 4.762), +1.331 in accuracy, and nearly a 28% gain in total average score (3.547 to 4.541).
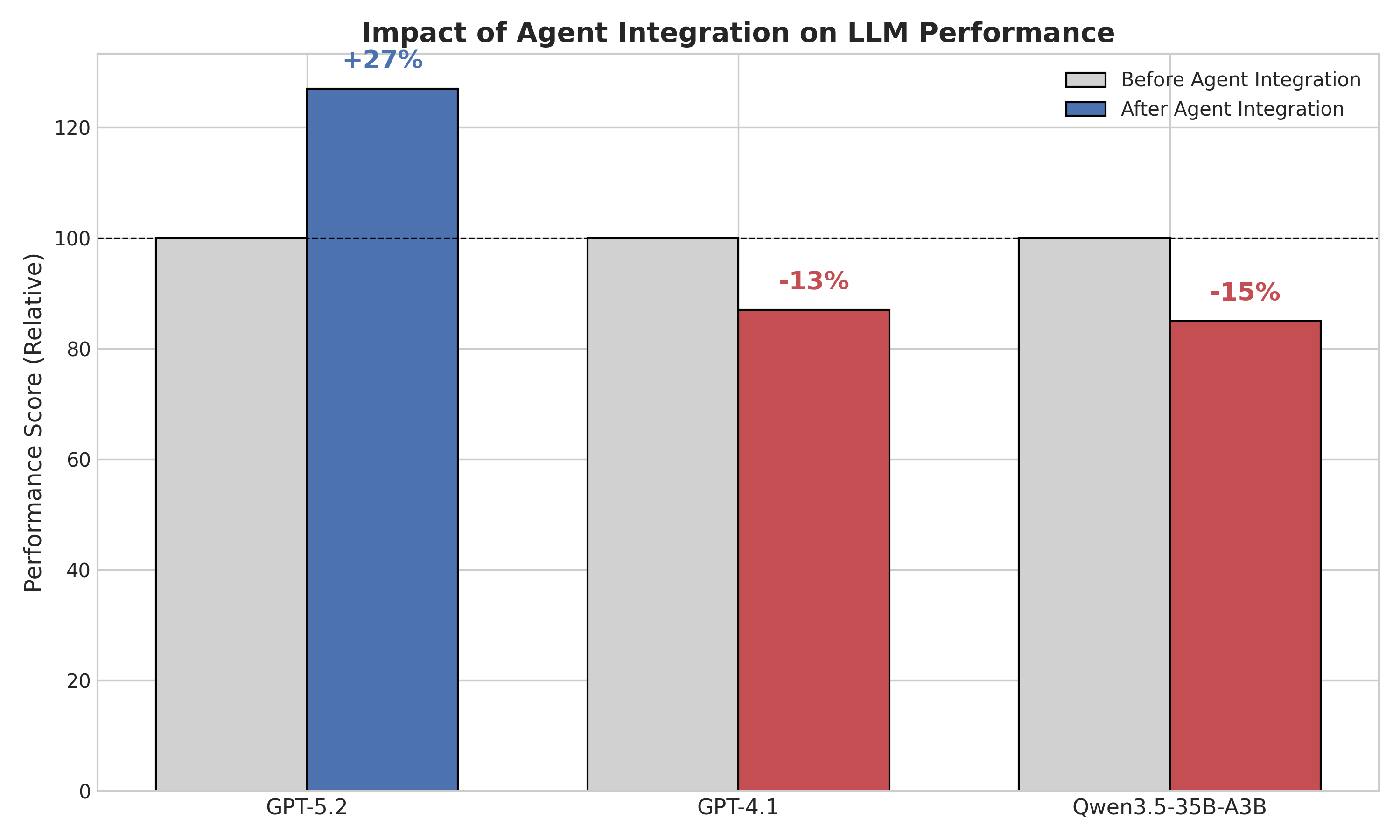
Figure 2: Bar plot showing performance improvements for GPT5.2 with EvoAgent (blue), and the impact of integration on GPT4.1 and Qwen (red), compared to their uninfluenced baselines (grey).
Model Transferability and Architectural Synergy
Model ablation experiments reveal a strong dependence between agent framework efficacy and backbone model characteristics. When EvoAgent is applied atop GPT4.1 or Qwen, performance does not universally improve: GPT4.1 shows a 13% drop in overall scores, Qwen by 15%. The findings highlight a non-trivial interaction term between agent implementation and model proficiency, formalized as
Model_capability=γ1⋅Model_Inference_Capability+γ2⋅Agent_Implementation_Compatibility
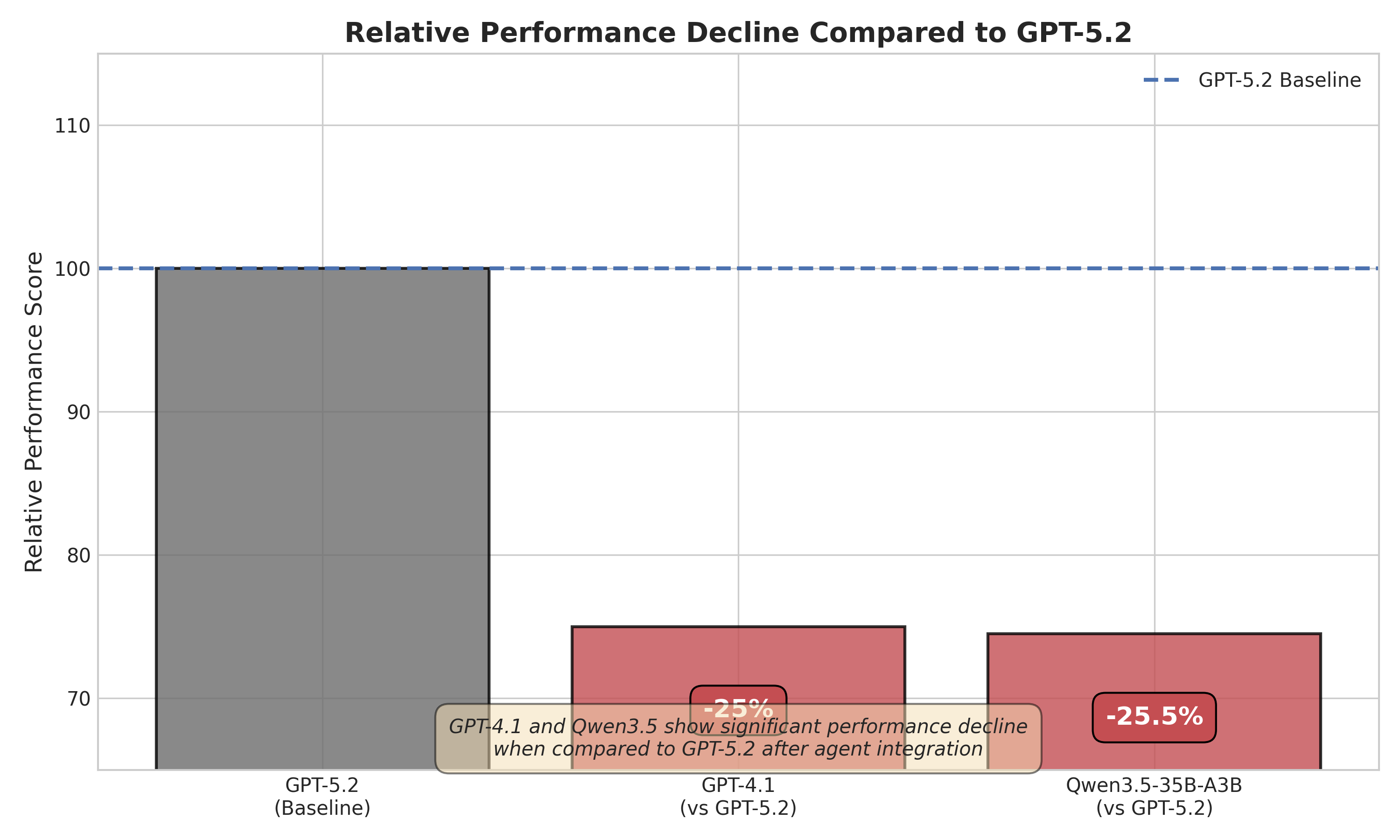
Figure 3: Relative performance of different model backbones post EvoAgent integration, normalized against the GPT5.2 setting.
Key interpretation: EvoAgent's workflow constraints, prompt engineering, and context management require underlying models with robust reasoning and tool-use stability. When such alignment is lacking (as in less capable models or those with poor instruction adherence), the agent's structuring overhead becomes a performance bottleneck rather than an enabler.
Practical Constraints and Systemic Implications
Empirical evaluation under operational load demonstrates support for long-horizon tasks: up to 420 turns and six compression events without failures. Token compression preserves core semantic information while pruning detail, with average response latency growing as dialogues elongate (12s for initial turns, 24s after 120+ turns). Key functional capabilities include product analysis/generation, multivariate inquiry handling, and domain-specific knowledge QA, all subject to skill extensibility and API-driven integration.
Nonetheless, the authors note several explicit limitations. Context compression remains lossy and non-adaptive; skill orchestration is limited to single-skill invocation, without true parallelization; user profile updates lack semantic granularity and cross-user generalization; system-level features like cost tracking, monitoring, and enterprise authentication are outside the framework’s current scope. The most significant theoretical limitation is the absence of real-time coevolution between execution and skill evolution (evolution is only triggered post-session), restricting adaptation to delayed feedback pathways rather than immediate context shift.
Theoretical and Future Directions
This work provides a clear formalization of agent self-evolution as an MDP, and establishes a framework that makes agent capacity an emergent function of both model skill and architectural synergy. Practically, it anchors the Harness Engineering paradigm—emphasizing engineered constraints, observability, and feedback—as central to building robust, scalable, and continuously improving agent systems. The implication is that, as model capabilities plateau, structured harnesses become the locus of control for reliability, adaptability, and organizational knowledge retention.
Future research must address synchronous online evolution, multi-skill orchestration, more advanced compression and memory pruning schemes, and broader applicability beyond foreign trade. The findings indicate that maximizing agent performance is not a property of model choice or skill design in isolation, but a function of interaction between harness, task domain, and foundational model properties.
Conclusion
EvoAgent establishes a rigorous agent framework fusing evolvable skill units, user-driven learning, and hierarchical delegation under a Harness-centric architectural paradigm. While empirical results affirm significant capability amplification when system-model synergy is high (notably with GPT5.2), performance is contingent on fine-grained compatibility across stack layers. The dual-loop design for continuous skill and profile evolution, albeit limited to offline adaptation, exemplifies a mature approach for domain agents targeting professional applications, with direct future impact on agent reliability, self-improvement efficiency, and enterprise deployment scalability.