- The paper introduces a graduated exploitation taxonomy (L0–L3) that refines vulnerability assessment beyond binary outcomes.
- It presents a multi-agent pipeline combining intelligence, generation, planning, exploitation, and detection to enable scalable, code-level security evaluations.
- Empirical results on 603 CVEs demonstrate robust exploitation performance and highlight the limitations of traditional risk metrics through effective knowledge reuse.
FORGE: Multi-Agent Graduated Exploitation and Detection Engineering
Abstract and Motivation
FORGE introduces an integrated, multi-agent system that bridges three historically distinct vulnerability response domains: automated proof-of-concept (PoC) exploit generation, vulnerability risk prioritization, and detection rule engineering. The traditional silos in these fields—binary exploitability reporting, prioritization disconnected from code-level exploitability, and signature generation agnostic to actual exploit behavior—have resulted in significant operational blind spots for defenders. FORGE's principal contribution is the introduction and operationalization of a four-level graduated exploitation taxonomy (L0–L3) within a unified pipeline, allowing nuanced measurement of exploitation success, structured intelligence accumulation, and exploitation-grounded detection content.
System Design and Pipeline
FORGE orchestrates five specialized agents—Intel, Generator, Planner, Exploit, and Detector—in a fixed pipeline for each assessed CVE. The system employs LLM-driven agents coordinated by an LLM-primary oracle, which is responsible for per-turn, CWE-specific, code-informed assessment of exploitation depth. Targeted application generation eliminates the dependency on original vulnerable codebases or manually curated container environments: each agent-built application embeds the vulnerable component at its affected version, instrumented to maximize evidence generation per exploitation level.
Pipeline Stages and Knowledge Stores
- Intel Agent: Aggregates structured vulnerability intelligence from multiple sources, resolving root cause, stack, and attack surface.
- Generator Agent: Produces a minimal application tailored to the CVE, with scaffolding matched to the exploitation taxonomy. Key design features include level-aware endpoint propagation and data infrastructure for evidence at L2/L3.
- Planner Agent: Produces CWE- and intelligence-informed attack plans, exploiting accumulated package/CWE-specific knowledge.
- Exploit Agent: Guided, tool-restricted exploitation with enforced reconnaissance and LLM oracle evaluation after every action, to minimize self-assessment bias and reward hacking.
- Detector Agent: Post-exploitation, generates Sigma and Snort detection rules grounded in OpenTelemetry traces, leveraging per-CWE detection rule knowledge.
The knowledge architecture accumulates over time, comprising an intelligence store with procedural cross-CVE learning, a per-CWE knowledge base, a build ‘cookbook,’ package experience memory, and a detection rule repository. This enables measurable increases in reliability and efficiency for recurring vulnerability patterns.
Graduated Exploitation Taxonomy
Instead of a binary PoC outcome, FORGE adopts a four-level taxonomy:
- L0: No exploitation evidence.
- L1: Vulnerability trigger—specific functionality is provably activated by controlled input.
- L2: Concrete impact—data exfiltration, code execution, or arbitrary file access.
- L3: Full compromise—unconstrained RCE, complete data dump, or acquired persistence.
An LLM-primary oracle, with structural caps per CWE (e.g., L2 maximum for XSS, CSRF), ensures systematic and conservative grading.
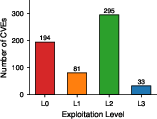
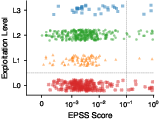
Figure 1: Correlation analysis between exploitation depth achieved and prioritization metrics such as EPSS and CVSS shows no significant predictive relationship.
Experimental Evaluation
The system was benchmarked on 603 CVEs from the CVE-GENIE dataset, spanning eight languages and 187 distinct CWE types. The key evaluation axes included end-to-end exploitation capability, correlation with industry prioritization metrics, detection rule grounding, and the quantifiable impact of knowledge reuse.
Exploitation Depth and Coverage
67.8% of CVEs reached L1+ end-to-end at an average cost of \$1.50 per CVE. Exploitation was robust across languages, with failure modes primarily in generation (e.g., build errors or package resolution), not in exploitation logic per se. After generation, 96.5% of vulnerable applications reached L1+, heavily weighted towards L2—binary success reporting would have masked these nuances.
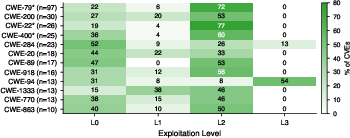
Figure 2: Distribution of exploitation depth achieved per CWE, highlighting structurally capped classes (L2 maximum) and the partition of L3 compromise for code-execution related CWEs.
Correlation with Risk Prioritization
A salient result is the empirical finding that exploitation success and depth are nearly flat across all EPSS and CVSS bands. The system demonstrated ~68% exploitability regardless of risk score threshold, and no significant rank correlation was observed between either metric and actual depth achieved. This provides large-scale evidence that metadata-driven prioritization, as implemented in industry scoring systems, is orthogonal to true code-level exploitability in controlled environments.
Detection Rule Grounding
Detection rules (Sigma and Snort) generated from traces of L2+ exploitation exhibited significantly higher span-normalized grounding (p=0.035) relative to L1-derived rules. 93.4% of generated Snort rules had zero false positives on a benign synthetic HTTP corpus, indicating high specificity for non-business-logic vulnerabilities. Increased exploitation depth improved the signal strength and evidence anchoring for detection content.
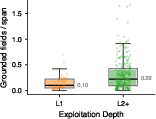
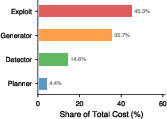
Figure 3: Comparison of detection rule grounding stratified by exploitation depth, and Agent-level cost decomposition per CVE processed.
Knowledge Reuse and Efficiency
Within-package and within-CWE knowledge transfer led to observable reductions in repeated generation/exploitation errors. Specifically, 48% of previous build- or exploitation-failure signatures were avoided on subsequent CVEs in the same package, and 95.5% for the same CWE across runs, substantiating the efficacy of the multi-tier knowledge store for longitudinal assessment at scale.
Implications and Limitations
Theoretical and Practical Impact
The introduction of graded code-level exploitation data represents a new ground truth axis for empirical security evaluation, allowing direct validation (and potential recalibration) of prioritization heuristics like EPSS. FORGE demonstrates that automatic generation and assessment can render comprehensive coverage of newly disclosed (or legacy) CVEs both technically feasible and economically viable (\$1.50 per CVE). Additionally, detection grounded in observed malicious behaviors facilitates higher-precision network and SIEM signatures, with quantifiable provenance.
The approach, while robust in code-level reachability assessment, does not model environmental defenses or complex authentication/authorization flows present in production. Pattern-level reachability provides an upper bound but not an operational risk estimate for real-world deployments. Results may not generalize to proprietary or non-open-source targets due to dataset composition. Causal impact of knowledge store reuse, while strongly suggested, remains to be measured in controlled (ablation) experiments.
Conclusion
FORGE delivers a comprehensive, multi-agent pipeline capable of bridging exploit generation, vulnerability risk quantification, and detection engineering with a single integrated framework. Its graduated taxonomy and large-scale empirical results demonstrate that most commonly used prioritization metrics are uninformative with respect to actual code-level exploitability, and that detection content quality depends strongly on exploitation depth. The knowledge-centric architecture supports efficient, cross-CVE learning and enables practical, scalable assessment for thousands of vulnerabilities. Future work will refine environment fidelity, extend to operational/production settings, and leverage graduated depth datasets as community calibration resources for risk metrics and defensive automation.