- The paper presents PoC-Adapt, a novel multi-agent system that uses a semantic oracle and DDQN-based adaptive policy to achieve a 25% relative improvement in reproduction success.
- The paper employs a five-stage pipeline integrating context retrieval, exploit generation, and semantic verification to mitigate LLM hallucinations and streamline exploit generation.
- The paper demonstrates significant efficiency gains by halving time-to-exploit and doubling exploit efficiency, validating its practicality on both controlled and real-world benchmarks.
Semantic-Aware Automated Vulnerability Reproduction via PoC-Adapt
Introduction and Motivation
The exponential increase in disclosed software vulnerabilities, coupled with evolving attack surfaces, has outpaced the capacity of manual vulnerability assessment and reproduction. Modern patch management, risk prioritization, and effective remediation fundamentally rely on verifiable Proof-of-Concept (PoC) exploits—yet the majority of vulnerability reports lack reproducible PoCs, impeding automated analysis and rapid defense. Recent LLM-based approaches to automated exploit generation have demonstrated potential, but remain hampered by unreliable validation (often dependent on superficial signals) and excessive resource consumption stemming from unguided trial-and-error.
PoC-Adapt addresses these deficiencies by architecting an end-to-end multi-agent system that coordinates LLM-driven agents via a semantic state-differencing oracle and a reinforcement learning-based adaptive exploitation policy. The framework targets robust, low-cost, and reliable PoC generation across diverse vulnerability types, focusing on reproducibility, practical deployment, and resilience to LLM hallucinations.
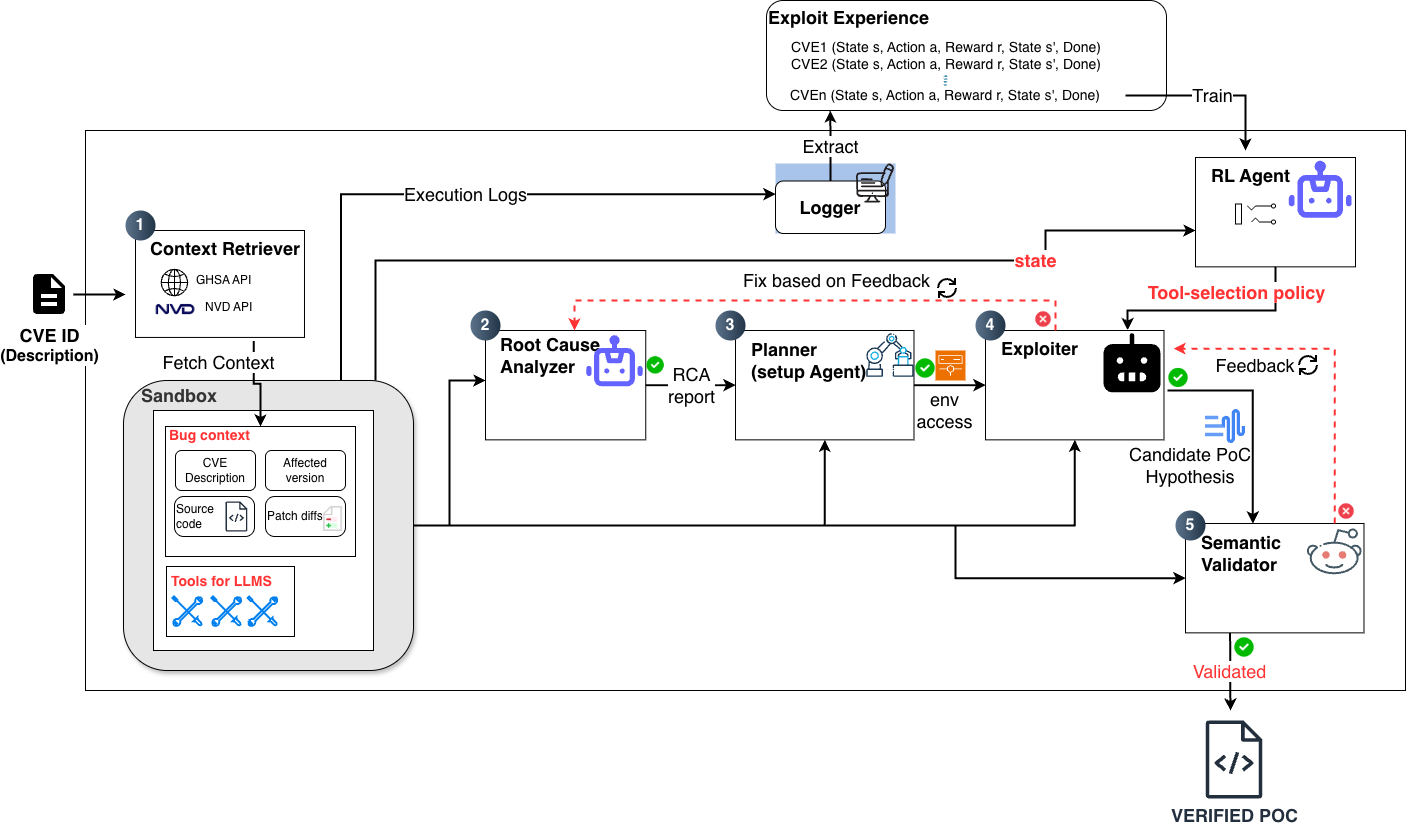
Figure 1: The overall PoC-Adapt architecture, illustrating agentized pipeline stages and data flow.
Framework Architecture
PoC-Adapt structures the PoC synthesis and validation pipeline into five sequential and modular stages: context retrieval, root cause analysis, environment setup, exploit generation, and semantic verification. Role-specialized LLM agents process each stage, passing structured context and feedback, and operate within tightly controlled tool access boundaries according to the principle of least privilege. The staged design supports traceable reasoning, modularity for debugging, and minimizes error propagation across pipeline boundaries.
The core architectural innovation is the Semantic Oracle, enabling the system to move beyond flag or crash-driven validation by capturing and analyzing structured pre- and post-execution system states, ensuring that exploit validation aligns with real-world impact rather than incidental or ambiguous behavioral changes. Feedback from semantic verification propagates upstream through the agent loop, allowing for focused refinement and reduced failure propagation.
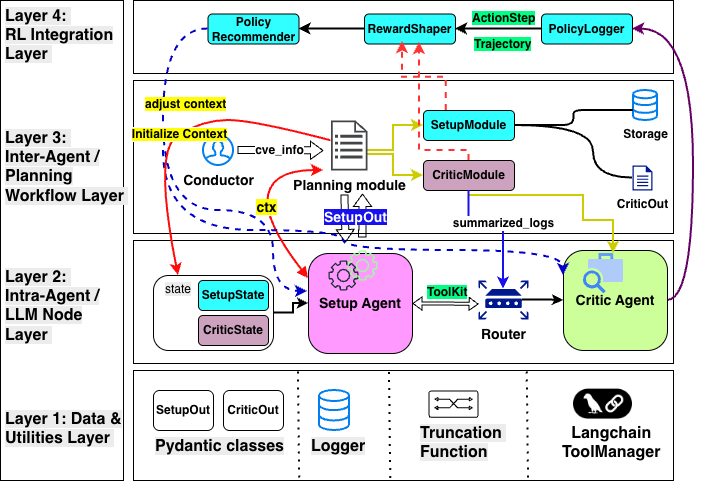
Figure 2: The self-verification mechanism enables iterative intra- and inter-agent refinement via semantic feedback.
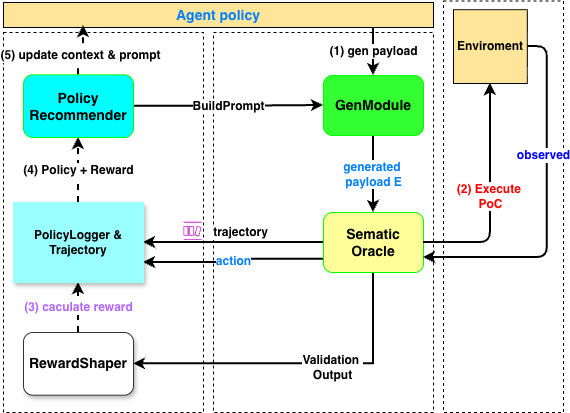
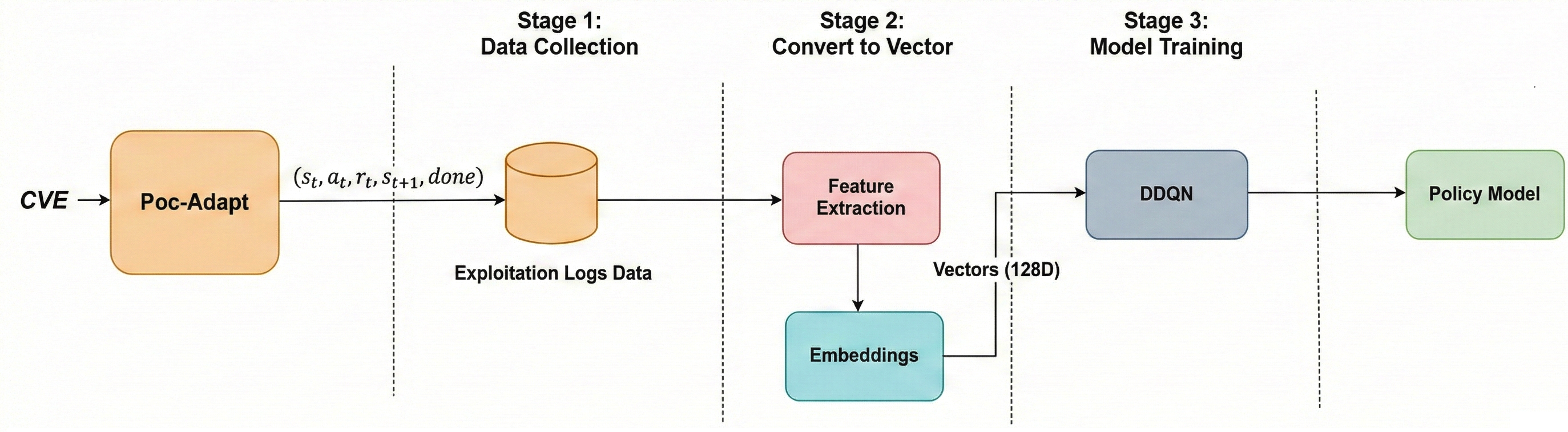
Figure 3: The adaptive policy learning mechanism integrates DDQN-guided decision making at the exploit generation stage.
The exploit generation process is further optimized by modeling agent decision-making as a Markov Decision Process (MDP), with actions and system context discretized and encoded into a low-dimensional state space. A Double Deep Q-Network (DDQN) manages exploitation policy, trained on replayed execution logs to maximize reproduction success while curbing fruitless token/compute consumption.
Key features of PoC-Adapt’s system-level design include:
Experimental Validation
Evaluation Settings and Metrics
Experiments evaluate PoC-Adapt on two benchmarks: FL-Bench-100 (100 curated vulnerabilities for controlled benchmarking) and GHSA-Real80 (80 real-world vulnerabilities from GitHub). Comparative baselines include FaultLine and a random policy agent. Performance metrics encompass reproduction success rate (SR), time-to-exploit (TTE), exploit efficiency (EE), token/monetary cost, and adaptive policy performance.
Numerical Results and Claims
- SR on FL-Bench-100: 15% with PoC-Adapt vs. 12% with FaultLine—25% relative improvement.
- TTE: Halved (16.33 vs. 35.92 steps, PoC-Adapt vs. FaultLine).
- Exploit Efficiency: Doubled for PoC-Adapt (0.025 vs. 0.011).
- GHSA-Real80 (real-world cases): 12/80 vulnerabilities reproduced (15% SR) at \$0.42 average cost per exploit; failures concentrated in environment reproduction.
- Adaptive Policy: DDQN policy increases SR by 16.7% relative to non-adaptive pipeline, reduces TTE by half, and increases action efficiency by 5x relative to random baselines.
- LLM Backend Robustness: Gemini-2.5-Pro yields best SR; DeepSeek-V3 cuts cost/latency but reduces SR; Qwen-3 provides a trade-off, confirming system flexibility.
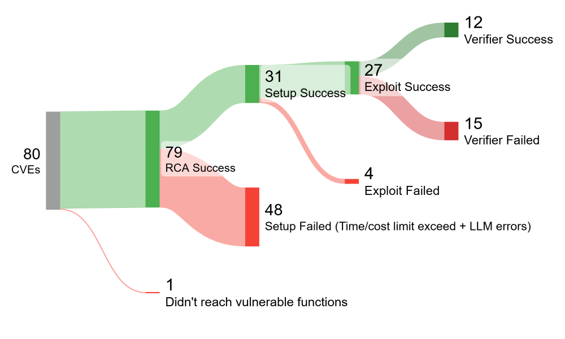
Figure 5: Stage-wise analysis highlighting failure rates and points of fragility, especially within the environment reproduction phase.
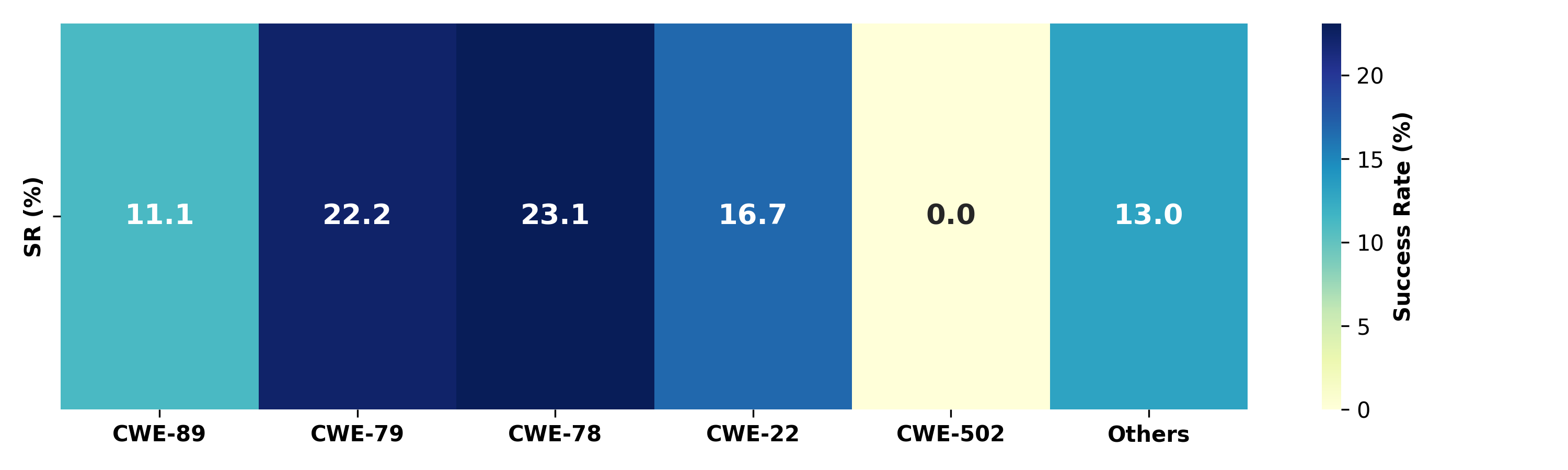
Figure 6: Success rate breakdown by CWE on GHSA-Real80, illustrating highest SR for direct-impact vulnerability classes.
Analysis and Discussion
Strong numerical gains in SR and EE validate the effect of semantic state-differencing and RL-driven exploration. The adaptive exploitation policy particularly excels at minimizing action redundancy and sharply constraining the search space. Critically, the semantic oracle demonstrably diverts the system from typical LLM hallucination failure modes by enforcing observable, meaningful state transitions. Failure analysis emphasizes continuing challenges in automated environment setup, especially under heterogeneity of real-world OSS and infrastructural complexity.
The PoC-Adapt framework exposes several unresolved challenges:
- Environment Setup Bottleneck: Operational failures trace primarily to the Planner stage due to configuration-induced complexity.
- Oracle Sensitivity Limitations: Subtle vulnerabilities (e.g., deserialization) or medium-severity issues are less reliably captured due to limited semantic impact or ambiguous state manifestation.
- Dependence on LLM Capability: Model substitution reveals meaningful performance degradation in lower-tier LLMs.
- Replay Buffer Limitations: RL policy efficacy correlates with exploit trajectory diversity; coverage remains bounded by trajectory dataset scale and class distribution.
Practical implications include reduced operational costs, higher verification fidelity, and modularity for integration into CI/CD workflows. Theoretical implications highlight reinforcement learning’s role in taming LLM actuation entropy via policy learning, suggesting broad applicability for similar agentic, tool-using systems.
Future Directions
Future avenues include automating more robust environment setup via subtask decomposition and guided dependency resolution, extending semantic verification with RAG and multimodal agents for richer state observation, integration with UI-driven tools to cover broader exploit modalities, and fine-tuning LLMs on security-specific corpora to mitigate cost and privacy constraints.
Conclusion
PoC-Adapt advances the paradigm of automated PoC exploit generation by fusing multi-agent LLM pipelines with semantic runtime oracles and adaptive policy learning. Empirical results demonstrate improved reliability (25% relative SR gain over SOTA), resource efficiency, and robustness to LLM backend changes. The RL-driven adaptive policy systematizes exploit navigation, reducing wasteful exploration and establishing a foundation for scalable, economically viable vulnerability reproduction. Remaining bottlenecks in environment reproduction and subtle impact detection motivate continued research. Collectively, PoC-Adapt offers a substantial step towards reliable, automated, and semantically verifiable exploit generation that can underpin future vulnerability management at scale.