- The paper demonstrates a multi-agent LLM pipeline that synthesizes KLEE-compatible FFI wrappers to overcome incomplete-code challenges in Rust CVEs.
- It leverages symbolic execution with four specialized agents, achieving an 83.9% detection rate and reducing wrapper compilation failures significantly.
- The approach outperforms traditional tools like Clippy and Miri while enabling structured graph-based analysis of memory vulnerabilities in unsafe Rust code.
Multi-Agent LLM-Orchestrated Symbolic Execution for Memory Vulnerability Detection in Incomplete Rust CVE Snippets
Introduction
The paper "Symbolic Execution Meets Multi-LLM Orchestration: Detecting Memory Vulnerabilities in Incomplete Rust CVE Snippets" (2605.00034) introduces a novel system that synergistically combines symbolic execution (KLEE) with a four-agent multi-LLM pipeline to address the challenge of automated memory-safety triage in Rust unsafe code, particularly in the context of incomplete CVE database fragments. The central innovation lies in resolving the incomplete-code barrier—Rust CVE entries typically lack struct definitions, imports, and Cargo manifests—by algorithmically synthesizing KLEE-compatible FFI wrappers via coordinated LLM agents, thus enabling deep bug detection where all formal verification tools fail due to compilation errors.
System Architecture and Pipeline
The pipeline consists of four role-specialized agents:
- Oracle/Validator (GPT-4 Turbo): Performs strategic vulnerability type identification and generates a structured analysis plan.
- Safety Checker (Claude Opus 4.5): Conducts targeted security analysis and assigns risk scores, annotating critical regions for downstream processing.
- Code Specialist (Claude Sonnet 4.5): Synthesizes Rust FFI wrappers compatible with KLEE from uncompilable CVE snippets, encoding the vulnerability semantics.
- Fast Filter (GPT-4o-mini): Optimizes KLEE parameterization based on the contextual risk profile.
These agents communicate via structured JSON artifacts to constrain context and minimize hallucinations. The pipeline orchestrates the generation of compilable KLEE-compatible wrappers, the construction of a C harness (with symbolic variables and explicit vulnerability triggers), symbolic execution, and the ingestion of output into a graph database for cross-CVE query and analysis.
(Figure 1)
Figure 1: The full pipeline: sequential agent orchestration transforms CVE Rust snippets into symbolic execution artifacts and structured vulnerability graphs.
Addressing the Incomplete-Code Barrier
The incomplete-code problem is manifest in CVE datasets as missing struct/enum definitions (90.3%), absent imports (100%), missing Cargo manifests (100%), and incomplete traits (61.3%). All formal verification tools (Kani, Prusti, Creusot, Haybale) achieve 0% applicability due to immediate compilation failure. The multi-agent pipeline sidesteps this by having the Code Specialist generate self-contained wrappers with explicit FFI (primitive types, raw pointer usage), which encode the core semantics of the vulnerability and enable LLVM bitcode generation.
Method: Harness Generation and Symbolic Exploration
For each CVE snippet, the system orchestrates wrapper generation to isolate core vulnerability regions (unsafe pointer blocks, arithmetic errors, deallocation mismanagement, etc.) into discrete FFI functions. These wrappers are compiled and linked to a C harness employing klee_make_symbolic and klee_range to enumerate and explore different vulnerability triggers. The harness explicitly exposes relevant buffer regions, indices, and value arithmetics as symbolic inputs, facilitating deep path exploration by KLEE.
Post-Processing: Graph Database Construction
KLEE outputs detailed error traces (.ptr.err, *.external.err, etc.). The raw file structure is algorithmically transformed via graph_klee.py into a property graph. Nodes correspond to CVEs, error types, symbolic test paths, and CWE categories. Edges express relationships such as HasError, TriggeredBy, ClassifiedAs, and SharedPattern. This enables cross-CVE querying, clustering, and structured export.
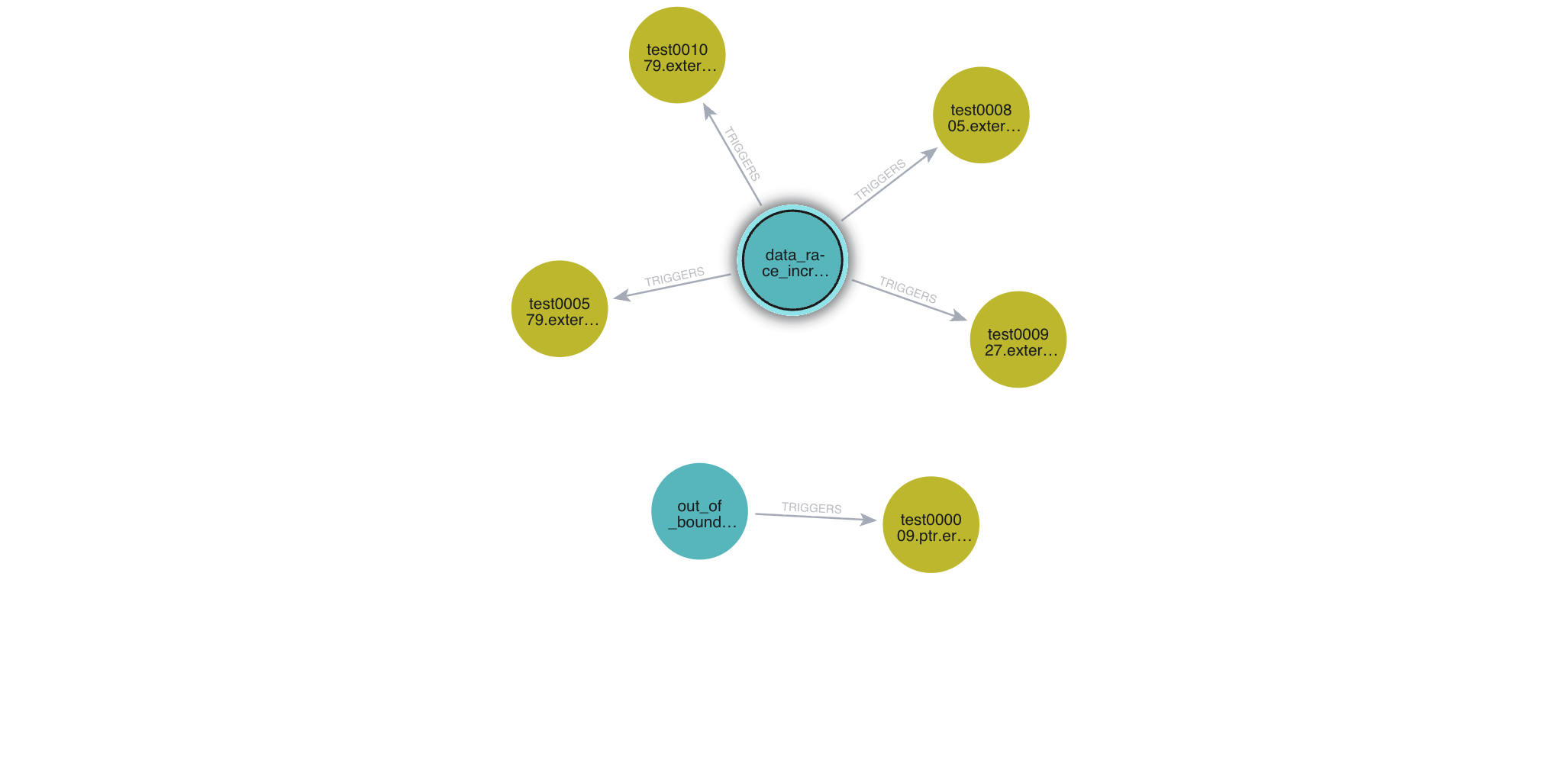 *Figure 2: Graph DB visualisation linking vulnerability functions to concrete KLEE error files and test cases for CVE-2020-35904.
*Figure 2: Graph DB visualisation linking vulnerability functions to concrete KLEE error files and test cases for CVE-2020-35904.
Empirical Evaluation
Compilation Success and Detection Rates
On 31 real-world Rust CVEs (11 CWE categories, all incomplete snippets), the pipeline achieves:
- 90.3% wrapper compilation success—all formal verification tools achieve 0%.
- 83.9% vulnerability detection rate—KLEE detected 1,206 critical errors across 26 files.
- Multi-agent vs single-agent: Reduces wrapper compilation failures from 42% to 9.7% and increases detected errors from 487 to 1,206.
Detection is highly skewed: two CVEs (CVE-2020-35904, CVE-2022-36008) account for 1,133 errors (path explosion). Pointer errors (.ptr.err) constitute the highest-confidence memory fault detection; external/panic errors (.external.err) correspond to runtime exceptions (panic, deallocation faults) and require contextual interpretation.
Clippy detects 14 warnings across 11 files (35.5% detection); Miri reports generic undefined behavior (100% but undifferentiated). The pipeline subsumes Clippy’s detection entirely and finds concrete vulnerabilities in 15 files where Clippy misses all issues. There are zero files detected exclusively by Clippy.
Multi-Agent Specialization
The four specialized agents outperform the single-agent model by focusing context, reducing hallucinated wrapper generation, and targeting high-risk code regions. Oracle-driven planning constrains the target CWE, Safety Checker surfaces semantic critical lines, Code Specialist encodes explicit vulnerability triggers, and Fast Filter allocates KLEE resources effectively.
Limitations and Error Analysis
FFI wrapper generation approximates the vulnerability semantics, not the precise exploitation path. This leads to lower detection rates for lifetime-dependent vulnerabilities (CWE-416, CWE-190). Improving context extraction and training Code Specialist on complex object lifetime semantics would further enhance detection. KLEE parameterization, LLM non-determinism, and error count interpretation are noted threats to validity. Error analysis stresses the importance of differentiating pointer from external/panic errors and examining concrete symbolic path traces.
Implications and Future Directions
Pragmatically, the pipeline offers actionable memory vulnerability triage for Rust CVEs previously inaccessible to automated analysis. Theoretical implications include advancing multi-agent LLM orchestration for code synthesis and formal analysis in incomplete contexts. Future directions involve stratified dataset expansion, richer CVE context mining, fine-tuned model specialization for complex classes, and bidirectional feedback between symbolic path error traces and wrapper generation.
Conclusion
This work introduces a formal, operational methodology for bridging the incomplete-code gap in Rust CVE memory-safety triage. The four-agent LLM pipeline, combined with symbolic execution and post-processing graph construction, offers high-confidence, actionable detection with unprecedented applicability to real-world CVE databases. The approach quantitatively and qualitatively outperforms both single-agent LLM and conventional practical/formal tools, validating the architectural advantages of coordinated role specialization and explicit context-passing in LLM-driven vulnerability detection systems.