Co-RedTeam: Orchestrated Security Discovery and Exploitation with LLM Agents
Abstract: LLMs have shown promise in assisting cybersecurity tasks, yet existing approaches struggle with automatic vulnerability discovery and exploitation due to limited interaction, weak execution grounding, and a lack of experience reuse. We propose Co-RedTeam, a security-aware multi-agent framework designed to mirror real-world red-teaming workflows by integrating security-domain knowledge, code-aware analysis, execution-grounded iterative reasoning, and long-term memory. Co-RedTeam decomposes vulnerability analysis into coordinated discovery and exploitation stages, enabling agents to plan, execute, validate, and refine actions based on real execution feedback while learning from prior trajectories. Extensive evaluations on challenging security benchmarks demonstrate that Co-RedTeam consistently outperforms strong baselines across diverse backbone models, achieving over 60% success rate in vulnerability exploitation and over 10% absolute improvement in vulnerability detection. Ablation and iteration studies further confirm the critical role of execution feedback, structured interaction, and memory for building robust and generalizable cybersecurity agents.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces Co-RedTeam, an AI “team” built from LLMs that works like human security testers (red teamers). Its goal is to automatically find security weaknesses in software and then prove they can be used by an attacker. It does this by organizing several specialized AI agents that plan attacks, test them in a safe environment, learn from what happens, and remember useful lessons for the future.
What questions are the researchers asking?
They focus on four simple questions:
- Can an organized team of AI agents find and exploit software vulnerabilities more reliably than existing methods?
- What parts of the system are most important (for example, real execution feedback, structured teamwork, or long-term memory)?
- Does learning from past experience help the AI improve over time?
- How well does the system perform on tough, realistic security tests compared to strong baselines?
How does their approach work?
Think of Co-RedTeam like a carefully coached sports team or a group of detectives. Each player has a role, they practice in a safe training field, and they keep a shared playbook of strategies that worked (or failed) before.
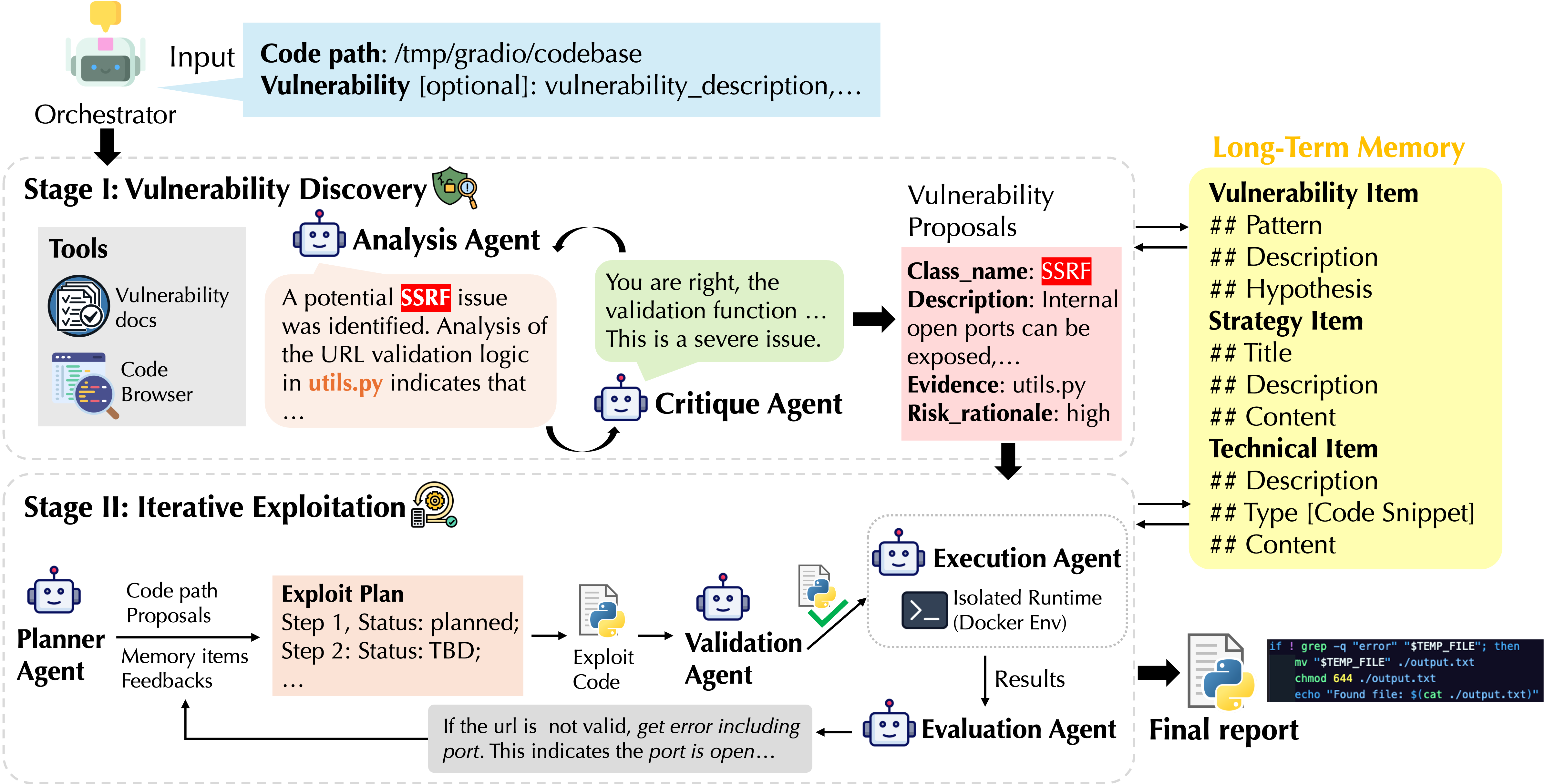
The orchestrator: the “coach”
An orchestrator coordinates everything. It:
- Sets up the right agents and tools for the job.
- Decides whether to start by searching for vulnerabilities or jump straight to exploiting a known one.
- Moves the workflow forward as goals are met (like stopping once a vulnerability is successfully proven).
Stage I: Vulnerability Discovery (finding problems)
Two agents collaborate to search the codebase and suggest likely security issues:
- Analysis Agent: Browses code like a careful reader, and uses trusted security knowledge (from CWE and OWASP) to spot potential weaknesses. It gathers concrete evidence, such as specific files and lines of code that show the problem.
- Critique Agent: Acts like a reviewer. It checks the Analysis Agent’s ideas, asks for stronger proof if needed, and helps refine or reject weak guesses.
Outcome: A set of well-supported vulnerability candidates, each with evidence and a risk level (how serious it could be).
Stage II: Iterative Exploitation (proving the problem is real)
Finding a bug is only half the job. You must prove it can actually be used. Co-RedTeam treats exploitation like an “escape room” challenge: try a step, see what happens, learn, adjust, and try again.
- Planner: Writes a clear, step-by-step Exploit Plan with goals, actions, and statuses (planned, done, blocked). It uses the evidence from Stage I, security knowledge, and the system’s memory of past successes and failures.
- Validation Agent: Double-checks each planned action before running it, to catch mistakes and unsafe commands.
- Execution Agent: Runs the validated actions in a safe, isolated “sandbox” (like a test box using Docker) so nothing harmful touches the real system.
- Evaluation Agent: Reads the results, explains what worked or failed, and suggests what to try next.
This loop continues until the vulnerability is reproduced, or the system decides it’s not feasible.
Long-term memory: the shared playbook
Co-RedTeam saves what it learns so it gets better over time. It keeps three kinds of memory:
- Vulnerability Pattern Memory: Common bug shapes and how they show up in code.
- Strategy Memory: High-level playbook tips, like which steps tend to work best for specific vulnerability types.
- Technical Action Memory: Concrete commands and scripts that succeeded (or failed) and the fixes that helped.
When the agents face a new task, they search this memory to guide their analysis and plans, just like an experienced team reusing tested plays.
What did they find?
The researchers tested Co-RedTeam on three challenging security benchmarks:
- CyBench: Capture-the-flag style exploitation tasks.
- BountyBench: Real-world tasks for both detecting and exploiting vulnerabilities.
- CyberGym: Realistic environments that require executable proof-of-concept exploits.
Key results:
- Co-RedTeam consistently beat strong baselines across different LLMs.
- It reached around 60% or higher success in exploitation on some benchmarks and improved detection accuracy by 10–20 percentage points compared to baselines.
- Removing critical parts (like execution feedback, memory, or code browsing) made performance drop a lot. In particular, turning off execution feedback caused the biggest decline, showing how important “learning from real runs” is.
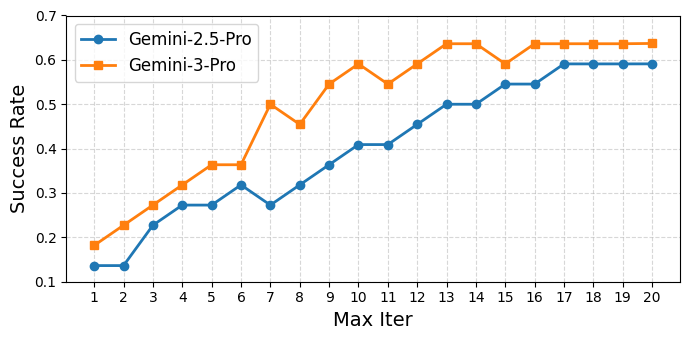
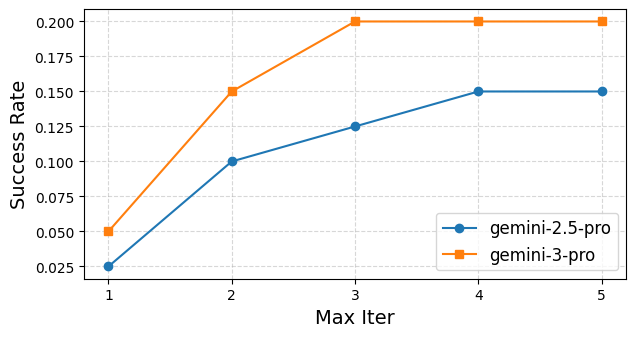
- More exploitation iterations helped up to a point, especially with stronger base models that learned faster and needed fewer tries.
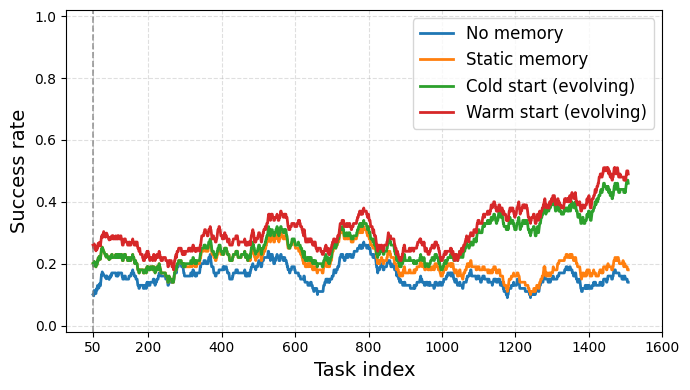
- Long-term memory made the system improve over time, especially when it started with a helpful “warm start” set of known tips and then evolved by adding new lessons.
Why this matters:
- Many existing LLM approaches struggle with multi-step, realistic security tasks because they don’t plan clearly, don’t validate actions, or don’t learn from experience.
- Co-RedTeam’s structured teamwork, safe execution loop, and shared memory address these weaknesses directly.
What’s the impact?
Co-RedTeam shows a practical path toward AI systems that can assist security teams at scale. If improved and used carefully, it could:
- Help organizations continuously test their software for real, exploitable bugs.
- Reduce the time, cost, and manual effort needed for red teaming.
- Make vulnerability analysis more reliable by grounding it in code evidence and actual execution results.
- Encourage future security tools to use multi-agent designs with memory, structured plans, and safety checks.
In simple terms: This research suggests that a well-organized AI “team,” that plans carefully, tests ideas in a safe environment, and learns from experience, can significantly improve the automated discovery and proof of software security problems.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored in the paper, framed as actionable directions for future research:
- External validity beyond benchmarks: The evaluation is confined to CyBench, BountyBench, and CyberGym; there is no evidence the framework generalizes to large, real-world enterprise codebases, multi-repo monorepos, or production CI/CD environments with complex dependency and configuration landscapes.
- Vulnerability class coverage: The paper does not assess capabilities on concurrency/TOCTOU bugs, race conditions, logic/authorization flaws, binary exploitation (e.g., buffer overflows, ROP), kernel-level vulnerabilities, or mobile platforms (Android/iOS), leaving the breadth of supported vulnerability types unclear.
- Environment fidelity gap: Exploitation occurs in isolated Docker containers; it is unknown how well results transfer to real deployment configurations (networking, service orchestration, secrets management, IAM, SELinux/AppArmor policies, cloud settings), or whether environment-specific nuances cause false successes or failures.
- Multiple vulnerabilities per target: The orchestrator halts after reproducing a single vulnerability, leaving unaddressed how to systematically discover, prioritize, and exploit multiple vulnerabilities within the same codebase, and how to report coverage.
- Absence of comparison with classical security tooling: There is no experimental comparison or integration with established program analysis and security tools (e.g., CodeQL, Semgrep, static taint analysis, SAST/DAST, fuzzers like AFL/LibFuzzer, dynamic instrumentation), nor a hybrid pipeline benchmark.
- Model dependence and portability: Results rely on proprietary Gemini models and embeddings; robustness across non-Gemini models (e.g., open-source LLMs), smaller models, or multimodal variants is not studied, limiting reproducibility and portability.
- Statistical rigor: The paper lacks confidence intervals, variance across runs, significance testing, and seed control; reported improvements may be sensitive to randomness or specific task ordering.
- Cost and scalability metrics: Token/compute consumption, memory footprint, throughput, and scaling behavior for thousands of repositories or continuous red-teaming scenarios are not quantified; resource-aware scheduling and parallel orchestration strategies are missing.
- Memory safety and governance: Long-term memory stores “technical action” snippets and code-derived evidence, but there is no policy for sensitive data sanitization, privacy/compliance, retention periods, access control, or preventing leakage of proprietary code or exploit techniques.
- Memory quality control: Update, pruning, conflict resolution, provenance tracking, and de-duplication for memory entries are unspecified; there is no metric for memory precision/recall, nor safeguards against accumulating misleading or stale heuristics.
- Retrieval hyperparameters: The memory and vulnerability documentation retrieval uses top-3 embeddings by default; sensitivity to k, embedding models, and retrieval strategies (re-ranking, hybrid lexical/semantic search) is not analyzed.
- Failure mode taxonomy: The paper does not provide a structured analysis of common exploitation/detection failure modes (e.g., environment mismatch, payload crafting errors, path assumptions, privilege issues), making it hard to target improvements.
- Validation agent efficacy: Criteria, coverage, and quantitative impact of the Validation agent (e.g., proportion of unsafe/invalid actions caught, reduction in wasted iterations, false rejections) are not measured, nor is its robustness to adversarial or ambiguous planner outputs.
- Critique agent scope: The ablation shows partial N/A entries, and the critique’s effect is only briefly linked to detection precision; there is no analysis of when critique helps or harms, nor how to calibrate critique strictness.
- Detection metrics and ground truth: Beyond one table on BountyBench precision/recall, detection evaluation is limited; the number of vulnerabilities per repo, labeling quality, severity calibration (e.g., CVSS), and coverage metrics (false negatives vs. false positives) are under-specified.
- Exploit success definition: ASR/“success rate” criteria (flag capture, PoC execution) are benchmark-specific and may not reflect real exploitability or business impact; mapping to standardized severity scoring and exploit reliability across environments is missing.
- Iteration budgets and hyperparameter sensitivity: Stage II iteration sensitivity is partially reported; there is no exploration of Stage I iteration limits, stopping criteria, timeouts, or adaptive budgeting policies tied to confidence or environment signals.
- Orchestrator guarantees: Scheduling, deadlock avoidance, termination criteria, and progress guarantees are heuristic; there is no formal analysis of convergence, nor mechanisms to detect and break unproductive loops reliably.
- Security and ethics safeguards: Policies for safe use, dual-use risk mitigation, release governance, authenticated access, audit trails, and compliance with vulnerability disclosure norms are not described.
- Continuous and incremental analysis: The framework does not address ongoing code changes (PRs), incremental scanning, regression tracking, or integration into DevSecOps pipelines for continuous automated red teaming.
- Cross-target transfer and contamination: Memory-driven evolution is shown on sequential tasks but the ordering/curriculum and potential cross-target leakage or task contamination effects are not controlled or quantified.
- Tool-chain extensibility: There is no exploration of plugin APIs or formal interfaces for adding specialized tools (e.g., symbolic execution, decompilers, protocol fuzzers), nor agent specialization for different stacks (web frameworks, microservices, serverless, IaC/Terraform).
- Multi-host attack chains: The system targets single codebases/environments; pivoting, lateral movement, multi-service orchestration, and chained exploits across distributed systems and networks remain unaddressed.
- Human-in-the-loop options: The paper does not study how minimal expert guidance (seed hints, environment tweaks, plan checkpoints) affects reliability, nor mechanisms for interactive oversight, override, or corrective feedback.
- Reproducibility and release: Full implementation details (Appendices referenced but not provided here), code availability, environment recipes, benchmark task IDs, and standardized run scripts are needed for independent replication.
Glossary
- Ablation studies: Controlled experiments that remove or vary components to measure their impact on performance. "We further conduct ablation studies to verify the importance of key design components"
- Agentic system: A system design where LLMs act as autonomous agents that use tools and interact with environments. "adopts agentic system designs that structure LLMs as autonomous agents"
- ASR: Attack Success Rate; a metric indicating the percentage of successful exploitation attempts. "achieves 63.7\% ASR on CyBench"
- Attack surface: The set of points in a system where an attacker could try to enter or extract data. "scans the codebase to understand the technology stack and attack surface"
- BountyBench: A benchmark suite targeting real-world offensive and defensive cybersecurity tasks. "including CyBench~\citep{zhang2024cybench}, BountyBench~\citep{zhang2025bountybench}, and CyberGym~\citep{wang2025cybergym}"
- Capture The Flag (CTF): A competitive cybersecurity challenge format where participants exploit systems to capture “flags.” "Cybench \citep{zhang2024cybench} is a CTF-based cybersecurity benchmark"
- Chain-of-thought prompting: A prompting technique that elicits step-by-step reasoning from LLMs. "with chain-of-thought prompting further improving performance in vulnerability discovery and repair"
- Closed-loop process: An iterative plan–execute–evaluate cycle that uses feedback to refine actions. "Stage II operates as a tightly coupled, closed-loop process coordinated by the orchestrator"
- Common Weakness Enumeration (CWE): A standardized catalog of software vulnerability types. "Common Weakness Enumeration (CWE)~\citep{mitreCWE}"
- Cross-Site Scripting (XSS): A web vulnerability allowing injection of malicious scripts into trusted sites. "(e.g., Cross-Site Scripting exploitation strategies across distinct web frameworks)"
- CyBench: A CTF-derived benchmark for evaluating cybersecurity capabilities of agents. "including CyBench~\citep{zhang2024cybench}, BountyBench~\citep{zhang2025bountybench}, and CyberGym~\citep{wang2025cybergym}"
- CyberGym: A large-scale benchmark emphasizing reproduction of vulnerabilities via executable exploits. "including CyBench~\citep{zhang2024cybench}, BountyBench~\citep{zhang2025bountybench}, and CyberGym~\citep{wang2025cybergym}"
- Docker-based environment: A containerized runtime used to safely execute and test exploits in isolation. "within an isolated Docker-based environment"
- Embedding-based similarity search: Retrieving related items by comparing vector embeddings of text. "Memory retrieval is performed via embedding-based similarity search"
- Execution-grounded: Based on real run-time behavior and feedback rather than purely static reasoning. "execution-grounded iterative reasoning"
- Exploit Plan: A structured, stepwise plan detailing actions to reproduce and validate a vulnerability. "maintains an explicit Exploit Plan that decomposes exploitation into a sequence of concrete, inspectable steps"
- Insecure deserialization: Unsafe deserialization of untrusted data that can lead to code execution or logic compromise. "injection flaws, improper access control, and insecure deserialization"
- One-day vulnerabilities: Recently disclosed vulnerabilities with public details that attackers can exploit before widespread patching. "coordinated exploitation of real-world one-day vulnerabilities~\citep{fang2024llm}"
- Orchestrator: The central controller that coordinates agents, tools, and workflow in the multi-agent system. "At the core of lies the orchestrator, which addresses these challenges"
- OSS-Fuzz: A continuous fuzzing service for open-source projects aimed at uncovering bugs and vulnerabilities. "OSS-Fuzz~\citep{ossfuzz}"
- OWASP Top 10: A widely used list summarizing the most critical web application security risks. "the OWASP Top 10~\citep{owaspTop10}"
- Payload: Crafted input designed to trigger or exploit a vulnerability. "adjusting file paths, switching payloads, or trying alternative commands"
- Proof-of-concept (PoC): A minimal, working demonstration that a vulnerability can be exploited. "executable proof-of-concept (PoC) exploits"
- Red teaming: Proactive, adversarial testing to identify and exploit vulnerabilities in systems. "Red teaming plays a foundational role in modern cybersecurity"
- Sandboxed interfaces: Restricted execution environments/tools that contain potential harm during testing. "sandboxed interfaces such as run-bash and run-python within an isolated Docker environment"
- Sanitization: The process of cleaning or encoding inputs to prevent security issues like injection. "validation or sanitization mechanisms may be insufficient"
- Sensitive sinks: Code locations where tainted/untrusted input can cause harmful effects if not validated. "reach sensitive sinks"
- Server-Side Request Forgery (SSRF): An attack that tricks a server into making unintended requests to internal or external resources. "a working command for testing SSRF reachability"
- Strategy Memory: A memory layer storing high-level, reusable exploitation strategies. "Strategy Memory captures high-level exploitation strategies"
- Technical Action Memory: A memory layer storing concrete commands, scripts, and tool invocations with outcomes. "Technical Action Memory records concrete, low-level actions"
- Vulnerability Pattern Memory: A memory layer storing abstract schemas and cues of confirmed vulnerabilities. "Vulnerability Pattern Memory captures confirmed vulnerability schemas"
Practical Applications
Practical Applications of the Proposed Security-Aware Multi-Agent Framework (Co-RedTeam)
Below are actionable, real-world applications derived from the paper’s core contributions: orchestrated multi-agent red-teaming, execution-grounded iterative reasoning, code-aware analysis, and layered long-term memory. Each item names sectors, potential tools/products/workflows, and key assumptions/dependencies.
Immediate Applications
- Continuous autonomous code auditing in CI/CD — sectors: software, cloud/SaaS, finance, e-commerce, telecom
- What: Integrate Co-RedTeam as a gated CI job to scan changed modules, generate evidence-backed vulnerability hypotheses (Stage I), and attempt exploit reproduction in sandbox (Stage II).
- Tools/products/workflows: GitHub Actions/GitLab CI plugin; Docker-based exploit runner; CWE/OWASP-aware Analysis+Critique agents; ticketing integration (Jira/ServiceNow) with PoC artifacts and risk ratings.
- Assumptions/dependencies: Reliable build/test environments; repository access; controlled sandbox; permissioned testing; LLM access and budget.
- Exploit reproduction and triage co-pilot for AppSec teams — sectors: MSSP, enterprise security, bug bounty programs
- What: Automatically reproduce reported vulnerabilities and attach validated PoCs to tickets; prioritize by risk and exploitability.
- Tools/products/workflows: Planner/Validation/Execution/Evaluation loop; “Exploit Plan” viewer; memory-backed “known exploit patterns” retrieval; SIEM/issue-tracker connectors.
- Assumptions/dependencies: Accurate environment mirroring; strict network isolation; legal authorization to test targets.
- Enhanced SAST/DAST augmentation — sectors: software, cloud/SaaS, healthcare, finance
- What: Use code-aware discovery to turn static findings into evidence chains; attempt dynamic validation to reduce false positives.
- Tools/products/workflows: SAST/DAST vendor plugin; code-browsing + security-document retrieval tools; exploit harness generator.
- Assumptions/dependencies: Access to code and deployable artifacts; toolchain compatibility; compliance constraints (HIPAA/PCI-DSS).
- Secure SDLC “shift-left” developer assistant — sectors: all software-producing orgs; education
- What: Developer-initiated scans on feature branches with immediate feedback, exploitability hints, and remediation suggestions linked to CWE/OWASP.
- Tools/products/workflows: IDE extension; pre-commit hooks; “Evidence chain” summaries; suggested test cases and sanitization patterns from memory.
- Assumptions/dependencies: IDE integration; developer permissions; privacy-safe model usage.
- Container and image hardening checks — sectors: cloud/SaaS, DevOps platforms
- What: Scan Dockerfiles/k8s manifests; identify misconfigurations; generate exploitation steps to prove impact (e.g., privilege escalation, SSRF in sidecars).
- Tools/products/workflows: Orchestrator-triggered Stage I/II on infrastructure-as-code; strategy/technical-action memory for known misconfigs.
- Assumptions/dependencies: Access to IaC repositories; controlled clusters or local kind/minikube; policy alignment.
- Security due diligence for M&A and third-party risk — sectors: finance, enterprise, private equity
- What: Rapid assessment of vendor/source-code security posture with evidence-backed findings and exploit reproduction where feasible.
- Tools/products/workflows: Time-boxed orchestrations; standardized reports mapped to CWE/OWASP/NIST; prioritized remediation plan.
- Assumptions/dependencies: Contractual access; scope and rules-of-engagement; reproducible build/test.
- Targeted red-teaming for web/CMS ecosystems — sectors: media, SMB websites, e-commerce
- What: Automated checks for typical CMS/plugin vulnerabilities with PoC payloads and mitigation guidance.
- Tools/products/workflows: Pattern memory for common CMS issues; exploit runner in isolated containers; WordPress/Drupal/Joomla profiles.
- Assumptions/dependencies: Non-production mirrors; CMS-specific knowledge base; permissioned scanning.
- SOC-ready exploit intelligence enrichment — sectors: enterprise SOC, MDR/MSSP
- What: Convert suspected exposures into validated exploitability signals to inform detection engineering and prioritization.
- Tools/products/workflows: Memory-backed mapping of exploit steps to ATT&CK; exportable detection artifacts (YARA/KQL/Sigma).
- Assumptions/dependencies: SIEM/SOAR integration; data handling policies; safe labs to validate.
- Curriculum and lab automation for cybersecurity education — sectors: academia, workforce training
- What: Auto-generate hands-on labs, PoCs, and step-by-step exploit plans; evaluate student submissions.
- Tools/products/workflows: “Exploit Plan” scaffolds; Dockerized targets; benchmark-aligned tasks (CyBench, BountyBench, CyberGym).
- Assumptions/dependencies: Lab infrastructure; isolated environments; alignment with course objectives.
- Open-source maintainer helper — sectors: open-source software
- What: Scheduled scans on repositories; evidence-backed PRs suggesting fixes; reproducible PoC repro steps.
- Tools/products/workflows: GitHub app; structured findings (files/lines, sinks/sources); automated PR templates with tests.
- Assumptions/dependencies: Maintainer opt-in; CI capacity; contributor license and policy alignment.
Long-Term Applications
- Autonomous, continuous enterprise red-teaming at scale — sectors: large enterprises, cloud providers, government
- What: Always-on agents crawling fleets of services, synthesizing discoveries across systems, and continuously validating exploitability.
- Tools/products/workflows: Fleet-level orchestrator; service inventory integration; dynamic target profiling; enterprise memory graph.
- Assumptions/dependencies: Strong guardrails; fine-grained access controls; robust cost and risk governance; attack surface mapping.
- Closed-loop “find–fix–verify” DevSecOps — sectors: software, regulated industries
- What: Extend from exploit validation to patch generation, secure refactoring, and automatic re-validation before merge.
- Tools/products/workflows: Code-repair agent; formal/symbolic validators; policy-as-code gates; regression exploit suites.
- Assumptions/dependencies: Reliable patch synthesis; verification or formal guarantees; change management approvals.
- Hybridization with fuzzing and symbolic execution — sectors: software, embedded/firmware, robotics
- What: Use agentic planning to seed fuzzers and interpret crashes; employ symex for path constraints; iterate with memory-guided hypotheses.
- Tools/products/workflows: Fuzzer/symex adapters; crash triage automation; priority queues informed by strategy memory.
- Assumptions/dependencies: Tool interoperability; compute-intensive workflows; specialized harnesses.
- Sector-specialized agent bundles (OT/ICS, automotive, medical devices) — sectors: energy, manufacturing, automotive, healthcare
- What: Domain-tailored analysis/exploitation strategies for proprietary protocols, real-time systems, and safety-critical stacks.
- Tools/products/workflows: Vertical memory packs; hardware-in-the-loop labs; model-based system profiles.
- Assumptions/dependencies: Access to testbeds/digital twins; stringent safety and legal controls; vendor cooperation.
- Regulatory assurance and compliance validation dashboards — sectors: finance, healthcare, public sector
- What: Evidence-backed attestations linking discovered issues to standards (e.g., ISO 27001, SOC 2, PCI-DSS, NIS2); risk trend analytics.
- Tools/products/workflows: Compliance mapping engine; control coverage metrics; automated evidence packages for audits.
- Assumptions/dependencies: Acceptance by auditors; standardized evidence schemas; governance alignment.
- Federated or consortium memory sharing — sectors: industry alliances, ISAC/ISAO communities
- What: Privacy-preserving sharing of vulnerability patterns and strategies across organizations to accelerate collective defense.
- Tools/products/workflows: Federated retrieval with differential privacy; de-identified pattern exchanges; trust frameworks.
- Assumptions/dependencies: Legal agreements; privacy tech; anti-poisoning safeguards; standard ontologies.
- AI red-team as a managed service (RaaS) — sectors: SMBs, enterprises without large security staff
- What: Subscription offering that schedules scans, reproduces exploits, and advises remediation with measurable KPIs.
- Tools/products/workflows: Multi-tenant orchestrator; tenant-isolated sandboxes; SLA-backed reporting; cost controls.
- Assumptions/dependencies: Clear scope-of-work and ROE; data residency controls; liability coverage.
- Secure-by-construction design advisor — sectors: software, systems engineering
- What: Early-stage architecture critiques linking potential weakness patterns to design alternatives; “pre-exploit” threat modeling with executable validations against prototypes.
- Tools/products/workflows: Architecture parsers; STRIDE/LINDDUN mappings; prototype harness generator.
- Assumptions/dependencies: Access to design artifacts; ability to spin up minimal viable prototypes; organizational adoption.
- National/sector-scale cyber exercises and readiness testing — sectors: government, critical infrastructure, finance
- What: Large-scale simulated campaigns using agentic adversaries to test organizational and sector resilience with measurable exploit realism.
- Tools/products/workflows: Scenario engines; ATT&CK-aligned playbooks; red/blue exercise orchestration; lessons-learned memory updates.
- Assumptions/dependencies: Policy authorization; cross-entity coordination; strong safety boundaries.
- Cross-repo refactoring and remediation at scale — sectors: open-source ecosystems, large code estates
- What: Identify recurring vulnerability motifs; propose consistent, organization-wide refactors; auto-generate migration PRs with tests.
- Tools/products/workflows: Pattern memory mining; code-mod generators; CI-driven validation across monorepos.
- Assumptions/dependencies: CI capacity; code ownership and review bandwidth; change risk management.
- Multimodal and infra-aware exploit reasoning — sectors: robotics, smart homes, IoT
- What: Extend beyond code to configs, network topologies, firmware images, logs, and protocol captures for holistic exploit planning.
- Tools/products/workflows: Multimodal retrieval; protocol decoders; firmware unpack/analysis workflows; digital twin integration.
- Assumptions/dependencies: Data availability and labeling; specialized parsers; high-fidelity testbeds.
Notes on feasibility and risks across applications:
- Model capability and cost: Performance depends on high-quality LLMs and may vary with model families; cost/latency controls are needed.
- Environment fidelity: Successful exploit reproduction requires realistic, isolated environments (Docker/k8s, digital twins).
- Governance and legality: All offensive testing must be permissioned; strict ROE, network isolation, and logging are essential.
- Safety and alignment: Validation agents and policy guardrails should prevent unsafe actions; human-in-the-loop review for high-impact steps.
- Data protection: Sensitive code and configs must be handled under organizational and regulatory constraints.
- Reliability: Expect residual false positives/negatives; keep human oversight for triage and remediation decisions.
These applications leverage the paper’s demonstrated strengths—execution-grounded iteration, structured multi-agent roles, and layered memory—to deliver immediate value in today’s AppSec pipelines while setting a roadmap for scalable, autonomous, and standards-aligned cybersecurity operations.
Collections
Sign up for free to add this paper to one or more collections.