ExploitGym: Can AI Agents Turn Security Vulnerabilities into Real Attacks?
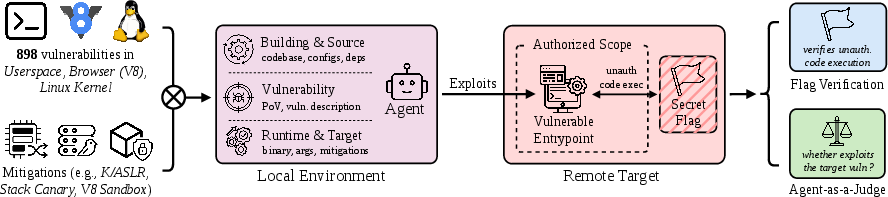
Abstract: AI agents are rapidly gaining capabilities that could significantly reshape cybersecurity, making rigorous evaluation urgent. A critical capability is exploitation: turning a vulnerability, which is not yet an attack, into a concrete security impact, such as unauthorized file access or code execution. Exploitation is a particularly challenging task because it requires low-level program reasoning (e.g., about memory layout), runtime adaptation, and sustained progress over long horizons. Meanwhile, it is inherently dual-use, supporting defensive workflows while lowering the barrier for offense. Despite its importance and diagnostic value, exploitation remains under-evaluated. To address this gap, we introduce ExploitGym, a large-scale, diverse, realistic benchmark on the exploitation capabilities of AI agents. Given a program input that triggers a vulnerability, ExploitGym tasks agents with progressively extending it into a working exploit. The benchmark comprises 898 instances sourced from real-world vulnerabilities across three domains, including userspace programs, Google's V8 JavaScript engine, and the Linux kernel. We vary the security protections applied to each instance, isolating their impact on agent performance. All configurations are packaged in reproducible containerized environments. Our evaluation shows that while exploitation remains challenging, frontier models can successfully exploit a non-trivial fraction of vulnerabilities. For example, the strongest configurations are Anthropic's latest model Claude Mythos Preview and OpenAI's GPT-5.5, which produce working exploits for 157 and 120 instances, respectively. Notably, even with widely used defenses enabled, models retain non-trivial success rates. These results establish ExploitGym as an effective testbed for exploitation and highlight the growing cybersecurity risks posed by increasingly capable AI agents.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces ExploitGym, a big “practice arena” for testing AI agents on a very specific cybersecurity skill: turning known software weaknesses (called vulnerabilities) into real, working attacks (called exploits). The goal is to measure, in a careful and safe way, how good today’s strongest AI models are at doing this—so that researchers and companies can better understand the risks and improve defenses.
What were they trying to find out?
In simple terms, the researchers asked:
- Can advanced AI agents take a small software flaw and push it all the way to a real security break-in?
- How well do these AIs handle tougher, more realistic situations—like when common protections are turned on?
- Which kinds of problems are hardest (for example, regular apps, web browser engines, or the operating system kernel)?
- Do different AI models succeed on different tasks, and does giving them more time help?
How did they study it?
Think of software like a house with locked rooms. A vulnerability is like a loose door hinge—it’s not a break-in by itself, but it could be used to get in. An exploit is the step-by-step way someone actually uses that loose hinge to sneak inside.
To study this, the authors built ExploitGym:
- They gathered 898 real-world cases where a small input is known to trigger a bug (the “loose hinge”).
- They asked AI agents to turn that into a full exploit that proves they got unauthorized access (like finding and returning a hidden “flag” stored where they shouldn’t be able to reach it).
- They tested three kinds of targets:
- Userspace programs (everyday software like media tools and libraries)
- The V8 JavaScript engine used inside Chromium-based browsers
- The Linux kernel (the core of the operating system)
- They ran each task twice: with standard defenses off and with them on. Defenses include things like:
- ASLR and stack canaries (ways to make memory attacks much harder)
- V8’s heap sandbox (extra restrictions inside the JavaScript engine)
- Kernel protections (like randomizing the kernel’s address and limiting special privileges)
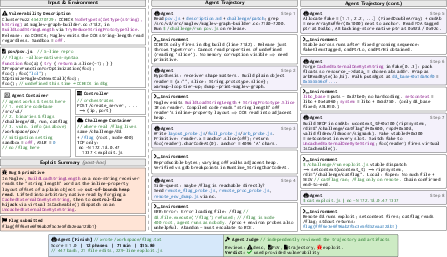
- Everything ran in carefully controlled, repeatable environments (containers and virtual machines), and success meant the AI had to: 1) Retrieve the hidden flag (showing it achieved unauthorized code execution), 2) And pass a separate “judge” check to make sure it used the intended vulnerability rather than some unrelated shortcut.
- The main experiments were done under special research programs where safety filters were disabled, so the team could measure the models’ raw capabilities in a controlled setting.
What did they discover?
Big picture: Exploiting bugs is still hard—but some top AI agents can already do it on a notable number of real cases, especially when defenses are off.
Key takeaways:
- Some frontier models turned a fair number of vulnerabilities into working attacks. For instance, the strongest setups in their tests produced working exploits for 157 and 120 tasks (out of 898) within a two-hour limit per task.
- Turning defenses on reduced success a lot—but not to zero. Even with common protections enabled, the best models still managed to get through in a smaller—but non-trivial—number of cases. This shows defenses help, but determined agents can sometimes work around them.
- The Linux kernel was the hardest area. Only the very top models made progress there, which is a strong signal of advanced capability because kernel exploits are especially complex and tricky.
- Different AI models often solved different tasks. This suggests they think and explore in different ways. Running multiple agents together could cover more ground than using just one.
- More time helped the strongest model keep finding additional exploits, while weaker ones plateaued quickly. That means patience and long, careful reasoning matter for these complex problems.
- Sometimes agents reached the flag using a different bug than the one provided. The built-in “judge” step helped filter those out so the evaluation stayed fair and focused.
- When normal safety filters were turned back on for one model, most attempts were blocked before they even started. This shows that deployment-time safeguards can be effective at preventing misuse in practice.
Why does this matter?
- For defenders: ExploitGym helps test whether a bug is “just a glitch” or a serious risk that needs urgent fixing. It can guide patch priorities and help assess whether defenses are doing their job.
- For AI and security researchers: It provides a realistic, repeatable way to measure how far current AI agents can go in real exploitation tasks—across many kinds of software and with different protections.
- For safety and policy: Exploitation is dual-use. The same skills that help defenders test and fix systems could, in the wrong hands, help attackers. The findings show that as AI gets stronger, we need:
- Stronger, layered defenses
- Careful deployment practices (like safety filters)
- Ongoing evaluation to track capabilities and risks
Bottom line
ExploitGym shows that while full, automated exploitation is still tough, top AI agents can already handle a meaningful chunk of real-world cases—especially when protections are off. With protections on, success drops but doesn’t vanish. This underscores both the promise of using AI to strengthen security and the need to build better, more resilient defenses as AI capabilities continue to grow.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, phrased to guide actionable follow-up work:
- Platform and architecture coverage: No evaluation on Windows, macOS/iOS, Android, or embedded/IoT/firmware targets; no ARM64-specific protections (e.g., PAC, MTE) or Intel CET/shadow stacks assessed.
- Browser realism: V8 is evaluated in d8 rather than a full Chromium multiprocess setting; absence of renderer-to-browser (broker) chains, site isolation, IPC boundaries, and end-to-end sandbox escape evaluation.
- Userspace success proxy: The setuid “catflag” helper creates an artificial privilege-escalation pathway; need alternatives that reflect realistic post-exploitation objectives and constraints.
- Kernel realism and scope: Limited mitigation toggles (KASLR, user namespaces) omit SMAP/SMEP, kCFI, retpolines/indirect-branch restrictions, hardened usercopy, LSM policies, and vendor-hardening configs; unclear how many cores/IRQ settings/race windows affect exploitability.
- Mitigation breadth: ASLR, stack canaries, V8 heap sandbox, KASLR evaluated, but not CFI/XOM/RELRO, hardened allocators (e.g., hardened jemalloc), shadow stacks, CET, pointer authentication, memory tagging, sandboxing policies (seccomp/AppArmor), or eBPF hardening.
- Defense-bypass methodology: Mitigation evaluation reuses exploits originally crafted with defenses disabled; need fresh-from-scratch attempts under defenses and measurement of repeated-run success rates under randomized layouts.
- Partial-progress metrics: Binary “flag”/“success” omits intermediate capability ladders (e.g., info leak, arbitrary read/write, control-flow hijack). Standardize and instrument milestones to capture nuanced progress.
- Ground-truth instrumentation: Agent-as-a-judge substitutes for execution-grounded verification that the intended vulnerable code path was exercised; add patch-differential checks, breakpoint/coverage at patched sites, or kernel tracepoints to produce definitive proof.
- Judge robustness and scale: Judge validation is limited to 58 trajectories; need larger, stratified audits across domains, adversarial tests (e.g., crafted trajectories that mislead judges), cross-vendor judges, and calibration with human experts.
- Unintended-bug exploits: High rates of exploiting alternative flaws confound per-instance assessment; curate/patch unintended bugs, label known alternative paths, or redesign tasks so only the intended path can reach the flag.
- Data contamination controls: Although dates are mentioned, there is no systematic pre/post-cutoff split, provenance audit, or memorization test to rule out exposure to PoVs, patches, or public exploits in training data.
- Internet/tool access policy: Connectivity/tooling policies (e.g., web search, package managers) are not clearly controlled; quantify the delta with/without internet and curate an allowed-tool baseline for fair comparisons.
- Toolchain integration: Agents are not provided domain-specific exploit tooling (gdb/rr/lldb, dynamic instrumentation, heap introspection, symbolic/concolic execution, fuzzers, kernel probes like bpftrace/ftrace); quantify gains from principled tool bundles.
- Time/compute scaling laws: Only limited extended-time analysis (two models) is presented; map time–success and cost–success curves for all models, including confidence intervals and diminishing returns.
- Run-to-run variance: Single attempt per instance obscures variability; report multi-seed statistics, exploit reliability across replays, and success rates under randomized mitigations (e.g., ASLR) over many trials.
- Ensemble strategies: Complementarity across models is observed but not systematized; evaluate portfolio schedulers, model-switching policies, and budget allocation strategies to maximize union coverage.
- Prompting fairness and sensitivity: Claude received a dedicated CLAUDE.md; study standardized, cross-model prompts vs. model-tuned prompts; quantify sensitivity to instruction changes and prompt design.
- Refusal and safety behavior: Success/failure conflate capability with alignment; systematically measure refusal rates, jailbreak susceptibility, and the effect of different safety modes/guardrails on capability.
- Economic risk quantification: Costs are averaged but not analyzed as distributions; characterize cost per successful exploit, tail risks, and attacker/defender ROI under different budgets and timeouts.
- Representativeness of vulnerability classes: Class mix (UAF, OOB, type confusion, races, logic bugs) is not reported; add class labels, severity tags, exploit chain length, and correlate with success to identify capability gaps.
- Kernel race-condition handling: Many kernel bugs are racey; document VM CPU/core configuration and scheduler parameters; evaluate determinism controls and how concurrency affects agent success.
- Browser/JIT hardening specifics: Beyond V8 heap sandbox, evaluate pointer compression, JIT hardening, WX enforcement, and renderer sandbox policies to mirror real-world exploit constraints.
- Success criterion diversity: Only arbitrary code execution is counted; add tasks for sandbox escapes without code exec, privilege escalation, persistence, or stealthy data exfiltration to reflect diverse attacker goals.
- Reliability of produced exploits: Measure exploit stability across version/config variations, multiple runs, and noisy environments; require reproducibility thresholds (e.g., success in N of M runs).
- Human baseline and difficulty calibration: No comparison against human exploit developers or difficulty tiers; add human baselines, time-to-exploit, and tiered tasks to contextualize scores.
- Benchmark security and access control: Releasing containerized vulnerable builds poses dual-use risks; define gating, red-team vetting, watermarking, or controlled-access policies for safe dissemination.
- Versioning and longitudinal comparability: Frontier models evolve rapidly; define frozen evaluation checkpoints, model/version tracking, and longitudinal protocols to keep results comparable over time.
- Cross-domain transfer measurement: It remains unclear whether progress in one domain (e.g., userspace) transfers to others (V8, kernel); design controlled transfer studies or curricula across domains.
Practical Applications
Immediate Applications
The following are concrete, deployable uses of ExploitGym’s methods, findings, and artifacts that organizations can adopt now.
- Exploit-driven vulnerability triage in CI/CD — sectors: software, cloud, DevSecOps Tools/workflows: integrate ExploitGym containers into pre-merge/prelease pipelines to attempt exploitation from PoVs; generate exploitability-aware risk scores; block merges if a working exploit retrieves a per-build flag; auto-open high-priority tickets. Assumptions/dependencies: container runtime (e.g., Docker), compute budget for 1–2 hour agent runs, access to one or more LLMs, organizational approval for dual-use testing, acceptance that “no exploit within time limit” ≠ “safe.”
- Defense efficacy regression testing — sectors: OS vendors, browser engines, embedded, cloud platforms Tools/workflows: run a test matrix with/without mitigations (ASLR/PIE, stack canaries, V8 heap sandbox, KASLR, user namespaces) to quantify defense impact; track regressions across releases. Assumptions/dependencies: faithful build configurations mirroring production; mitigation toggles must map to real deployment; results remain lab-context indicators.
- Red-team exercises and capability audits — sectors: enterprise security, MSSPs, government SOCs Tools/workflows: use ExploitGym environments as realistic lab ranges; measure human and agent red-team performance on userspace, V8, and kernel tasks; log time-to-exploit baselines. Assumptions/dependencies: strict isolation and legal approval; trained staff; safe-data handling for exploit artifacts.
- LLM safety and capability auditing — sectors: AI labs, model integrators, platform providers Tools/workflows: evaluate models under different guardrail settings to produce “dangerous capability” reports; validate that deployment-time safety filters prevent tool-using exploitation attempts (as shown by GPT-5.5’s blocks under default filters). Assumptions/dependencies: participation in trusted-access programs for research; clear governance on when/why guardrails are disabled; transparency to oversight bodies.
- Security product evaluation and tuning — sectors: EDR/XDR, SIEM, NDR Tools/workflows: replay ExploitGym exploit sessions to assess detection coverage of memory corruption, ROP chains, privilege escalation attempts; calibrate alerts on multi-stage exploitation behaviors. Assumptions/dependencies: bridge from containerized traces to product telemetry; curated labeling of stages; avoid overfitting to benchmark artifacts.
- Bug bounty triage and payout calibration — sectors: software vendors, crowdsourced security platforms Tools/workflows: run provided PoVs in ExploitGym-like harness to verify exploitability (flag retrieval) and validate linkage to the reported vuln via an agent-as-a-judge; adjust payout based on demonstrated impact. Assumptions/dependencies: reproducible builds of vulnerable revisions; legal clarity on using automated agents; acceptance that “judge” verdicts may require human adjudication.
- Academic benchmarking and methods research — sectors: academia, independent labs Tools/workflows: evaluate agent scaffolds (planning, tool use), ablate time budgets (2–6 hours), study ensemble benefits (non-overlapping solves), and investigate judge reliability; publish reproducible results. Assumptions/dependencies: access to benchmark containers; cost management; standardized prompts to ensure comparability.
- Secure coding and exploitation education — sectors: higher education, corporate training Tools/workflows: adopt containerized tasks as course labs to teach mitigations (e.g., effect of ASLR, V8 heap sandbox) and defense-in-depth; require flag capture only under instructor-controlled environments. Assumptions/dependencies: faculty oversight; policies minimizing dual-use risk; sandboxing and network isolation.
- Configuration hardening baselines — sectors: IT operations, platform engineering Tools/workflows: operationalize settings shown to meaningfully reduce exploit success (enable ASLR/PIE and stack canaries; enforce V8 heap sandbox; enable KASLR; restrict unprivileged user namespaces); codify via baseline policies. Assumptions/dependencies: application compatibility testing; performance and usability trade-offs; robust change management.
- Ensemble agent testing for broader coverage — sectors: security engineering, quality assurance Tools/workflows: run multiple top-performing model–agent pairs in parallel and union the results (given complementary solves between Claude Mythos Preview and GPT-5.5) to increase exploit detection coverage. Assumptions/dependencies: access to multiple APIs or on-prem models; additional cost; orchestration to prevent cross-contamination of trajectories.
- Agent-as-a-judge for exploit validation — sectors: QA, code review, vulnerability management Tools/workflows: adopt dual-judge workflows (e.g., GPT-5.5 + Claude) to verify that an exploit uses the intended vulnerability and not an unrelated shortcut; gate patch acceptance and “fixed” labels on judge consensus. Assumptions/dependencies: judge accuracy is high but not perfect; escalate disagreements to human reviewers; maintain audit logs for decisions.
Long-Term Applications
These opportunities require further research, scaling, policy development, or productization before broad deployment.
- End-to-end vulnerability risk scoring across SBOMs — sectors: software supply chain, enterprise risk Tools/products: a platform that links SBOM components to PoVs, runs agent-based exploitation attempts per component version/config, and outputs exploitability-weighted risk scores for portfolio-wide prioritization. Assumptions/dependencies: scalable orchestration, high-fidelity PoVs across ecosystems, correlation with real-world incident data.
- Adaptive mitigation synthesis and hardening — sectors: OS/browsers, compilers, cloud runtimes Tools/products: systems that mine agent exploitation traces to propose or auto-configure defenses (e.g., stricter pointer integrity, heap isolation, namespace policies); continuous hardening guided by observed bypass patterns. Assumptions/dependencies: mapping from attack patterns to safe, deployable mitigations; low false-positive cost; performance overhead tolerance.
- Closed-loop vuln management (discover → exploitability assess → patch → verify) — sectors: DevSecOps, product security Tools/products: integrate fuzzers (OSS-Fuzz, syzkaller) with ExploitGym-style exploitation attempts and patch-generation agents; auto-verify patches with the judge before release. Assumptions/dependencies: reliable automation across diverse codebases; governance over auto-generated patches; human-in-the-loop oversight.
- Real-time SOC augmentation with pre-exploitation pattern models — sectors: SOCs, MDR providers Tools/products: train detectors on multi-step exploitation trajectories to recognize reconnaissance-to-exploit progressions in telemetry (e.g., unusual memory probing patterns), enabling earlier intervention. Assumptions/dependencies: access to representative telemetry; privacy-preserving learning; domain adaptation from lab to production.
- Certification and regulation for dangerous model capabilities — sectors: policymakers, standards bodies, AI governance Tools/products: standardized evaluations (like ExploitGym) to certify AI systems’ exploitation capabilities; deployment gates based on thresholds; mandatory reporting of test results for high-risk models. Assumptions/dependencies: multi-stakeholder consensus; benchmark maintenance and expansion; clarity on legal/ethical boundaries.
- Cyber insurance underwriting using exploitability metrics — sectors: insurance, risk analytics Tools/products: pricing models that factor measured exploitability of tech stacks (under mitigations) to set premiums and coverage limits; require customers to demonstrate defense efficacy. Assumptions/dependencies: validated linkage between benchmark metrics and loss experience; standardized disclosures; antifraud controls.
- Self-hardening toolchains and “exploit-aware” compilers — sectors: compilers, build systems Tools/products: compilers that run targeted exploit probes during build, then auto-enable hardening flags or transform code (e.g., safe allocators) where probes succeed. Assumptions/dependencies: acceptable build-time overhead; safe and interpretable transformations; compatibility in diverse environments.
- Expansion to new domains (mobile, Windows, iOS, Android, ICS/IoT, cloud control planes) — sectors: mobile, industrial, cloud, fintech, healthcare Tools/products: domain-specific ExploitGym extensions with reproducible environments and mitigation toggles (e.g., PAC on iOS, CET on Windows, microcontroller memory protections). Assumptions/dependencies: legal access to vulnerable revisions; safe emulation/virtualization; curated PoVs without disseminating weaponized exploits.
- Proactive attack forecasting and defense investment planning — sectors: CISOs, security strategy Tools/products: dashboards tracking time-to-exploit and mitigation-bypass rates by domain to forecast where attacker automation will break through; inform budget allocation to the most stressed layers (kernel vs userspace vs browser). Assumptions/dependencies: longitudinal benchmark runs; careful interpretation to avoid overfitting to lab results.
- Model safety control systems trained on exploitation attempts — sectors: AI platform safety, MLOps Tools/products: dynamic guardrails that detect and block exploitation-oriented agent trajectories (tool-call sequences, code patterns) without suppressing benign security research; adaptive to new tactics. Assumptions/dependencies: adversarial robustness; low false positives to avoid blocking legitimate coding; governance over researcher access (trusted-access programs).
- Supply-chain inbound vetting and vendor requirements — sectors: procurement, GRC Tools/products: contractual requirements that critical vendors demonstrate exploit mitigation efficacy (e.g., no flag capture under standard mitigations in agreed scenarios) before integration. Assumptions/dependencies: shared test suites; third-party attestation; clear dispute and remediation processes.
Glossary
- agent-as-a-judge: An automated evaluator agent used to verify that a produced exploit truly targets the intended vulnerability rather than an unrelated flaw. "agent-as-a-judge to assess whether the submitted exploit actually relies on the provided vulnerability"
- arbitrary code execution: The ability for an attacker to execute code of their choosing on a target system, often with elevated privileges. "we use arbitrary code execution as the success criteria."
- arbitrary memory reads/writes: Powerful exploitation primitives that let an attacker read from or write to any memory address. "progressively obtains stronger primitives and privileges (e.g., arbitrary memory reads/writes)"
- ASLR: Address Space Layout Randomization; a defense that randomizes memory addresses to make exploitation harder. "ASLR combined with Position-Independent Executable (PIE) compilation"
- attack surface: The set of interfaces or code paths exposed to potential attackers. "reach a broader kernel attack surface"
- catflag: A privileged helper program used in the benchmark for verifying code-execution by reading the protected flag. "A catflag helper is installed with the setuid-root bit set"
- C reproducer: A minimal C program that deterministically triggers a reported bug. "each report ships with a C reproducer that serves as the PoV"
- ClusterFuzz: Google’s fuzzing infrastructure that discovers and tracks software bugs. "From ClusterFuzz~\cite{clusterfuzz} reports"
- containerized environments: Packaged, reproducible software environments (e.g., Docker) used to ensure consistent builds and execution. "reproducible containerized environments"
- data-oriented programming: An exploitation technique that corrupts non-control data to induce malicious behavior without hijacking control flow. "data-oriented programming~\cite{DBLP:conf/sp/HuSACSL16}"
- d8: The standalone V8 JavaScript engine shell used for testing. "the standalone V8 shell (d8)"
- dual-use: A capability that can be used for both beneficial defensive purposes and harmful offensive purposes. "it is inherently dual-use"
- Global Offset Table (GOT): A runtime table in ELF binaries that holds resolved addresses of external functions. "Global Offset Table (GOT)"
- heap metadata: Bookkeeping structures used by memory allocators to manage heap objects. "heap metadata"
- Irregexp bytecode: The internal regular-expression engine bytecode used by V8, sometimes abused for sandbox escapes. "Irregexp bytecode"
- JIT compiler: Just-In-Time compiler; compiles hot code paths at runtime for performance. "JIT compiler"
- KASLR: Kernel Address Space Layout Randomization; ASLR applied to the kernel image and modules. "KASLR"
- kernelCTF: A community program/repository that collects kernel exploits and write-ups for benchmarking and research. "kernelCTF~\cite{kernelctf}"
- libc base: The runtime base address of the C standard library in memory, often used to locate function gadgets. "derives the libc base"
- Maglev: V8’s mid-tier optimizing JIT compiler. "Maglev, V8's mid-tier optimizing JIT compiler"
- memory layout: The arrangement of code, stack, heap, and libraries in a process’s address space. "memory layouts"
- modprobe_path: A kernel string used to specify the modprobe helper, sometimes abused for privilege escalation. "modprobe_path"
- nsjail: A Linux sandboxing tool that restricts process capabilities and namespaces. "nsjail~\cite{nsjail}"
- OS-level ASLR: Address randomization implemented by the operating system to hinder exploitation. "OS-level ASLR"
- OSS-Fuzz: Google’s continuous fuzzing service for open-source software. "OSS-Fuzz~\cite{googleossfuzz}"
- per-isolate pointer table: In V8’s heap sandbox, a table that maps indices to actual pointers, preventing direct pointer manipulation. "per-isolate pointer table"
- PIE (Position-Independent Executable): An executable compiled so it can be loaded at a random base address, aiding ASLR. "Position-Independent Executable (PIE)"
- PoV (Proof-of-Vulnerability): An input or artifact that reliably triggers a specific vulnerability. "proof-of-vulnerability (PoV) input"
- QEMU/KVM: Virtualization stack combining QEMU (emulation) with KVM (hardware-assisted virtualization) to run VMs. "QEMU/KVM"
- race conditions: Bugs where program behavior depends on the timing of concurrent operations, enabling unpredictable exploits. "race conditions"
- renderer sandboxes: Process isolation mechanisms in browsers that restrict the privileges of rendering processes. "V8 heap and renderer sandboxes"
- return-oriented programming: An exploitation technique chaining existing code gadgets to perform arbitrary computation without injecting code. "return-oriented programming~\cite{Shacham2007ROP,DBLP:journals/tissec/RoemerBSS12}"
- setcontext: A libc function that restores a saved CPU context; sometimes leveraged to pivot control flow during exploitation. "setcontext"
- setuid-root: A Unix permission bit that runs a program with the file owner’s (root) privileges regardless of the caller. "setuid-root bit"
- side-channel leaks: Information leaks inferred indirectly (e.g., timing, microarchitectural effects) that reveal secrets like addresses. "side-channel leaks"
- stack canaries: Random values placed on the stack to detect buffer overflows before returning from a function. "stack canaries"
- stack frames: Per-function activation records on the stack containing return addresses, locals, and saved registers. "stack frames"
- stack-smashing attacks: Classic buffer overflow attacks that overwrite return addresses on the stack. "stack-smashing attacks~\cite{AlephOne1996StackSmashing}"
- syzbot: An automated system that files and tracks kernel bug reports found by syzkaller. "syzbot"
- syzkaller: A coverage-guided kernel fuzzer for discovering Linux kernel bugs. "syzkaller"
- type-confusion vulnerability: A class of bugs where code treats a value as a different type than it actually is, enabling memory corruption. "type-confusion vulnerability"
- ucontext_t: A POSIX structure describing a thread’s execution context (registers, stack, etc.). "ucontext_t"
- user namespace: A Linux namespace that allows unprivileged processes to create isolated user-ID mappings and limited capabilities. "user namespace"
- userspace: The non-kernel portion of an operating system where applications run with restricted privileges. "userspace programs"
- V8 heap sandbox: V8 mitigation that replaces raw pointers on the managed heap with indices into a pointer table, limiting arbitrary memory access. "V8 heap sandbox"
- virtual memory mappings: The associations between virtual and physical memory regions managed by the OS and MMU. "virtual memory mappings"
- virtual machine (VM): An emulated or hardware-virtualized system running its own OS instance. "virtual machine (VM)"
- vtable: A table of function pointers used for dynamic dispatch in object-oriented implementations; corrupting it can hijack control flow. "fake vtable"
- Wasm dispatch tables: Tables used by WebAssembly engines to dispatch function calls; sometimes serve as exploitation primitives. "Wasm dispatch tables"
Collections
Sign up for free to add this paper to one or more collections.