- The paper introduces RuleForge, an automated system that generates and validates web vulnerability detection rules using LLMs and iterative feedback.
- It employs a parallelized multi-candidate strategy with iterative refinement and LLM-as-a-judge scoring to enhance detection accuracy and reduce false positives.
- Operational results reveal a 336% production increase over human baselines, showcasing significant productivity gains and improved rule quality.
Automated Rule Generation for Web Vulnerability Detection: An Expert Analysis of RuleForge
System Overview and Architectural Principles
RuleForge addresses acute limitations in manual detection rule development by automating the translation of structured vulnerability descriptions (Nuclei templates) into production-ready, JSON-based detection rules for web exploitation attempts. Architecturally, the system comprises four central components: the CVE Repository, Rule Generation Engine, Validation Pipeline, and Feedback Integration loop (Figure 1). The CVE Repository automates the aggregation and scoring of vulnerability disclosures, ensuring that high-risk and organizationally-relevant CVEs are prioritized using content heuristics and live threat intelligence.
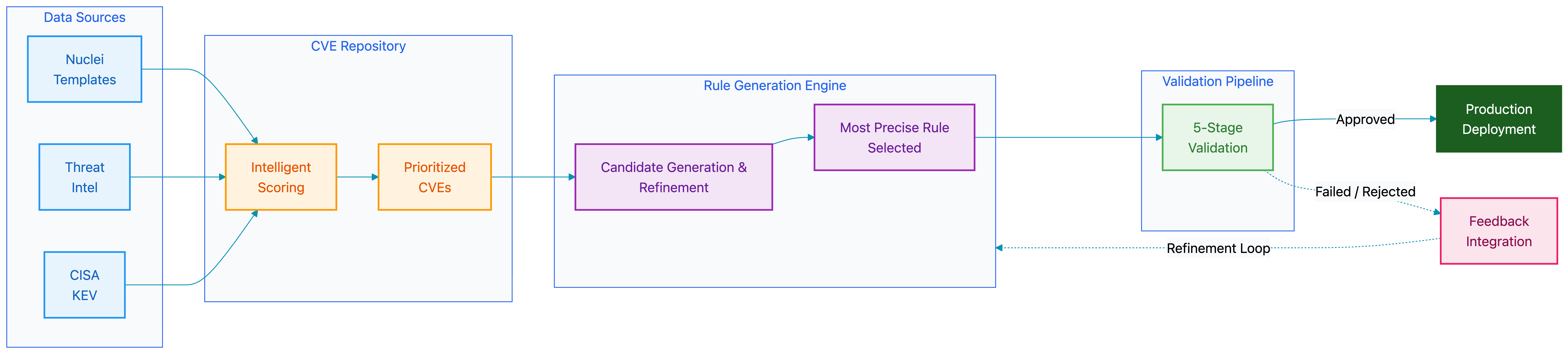
Figure 1: The RuleForge pipeline integrates CVE ingestion, rule generation via LLMs, a multi-stage validation path, and systematic feedback for iterative improvement.
RuleForge’s generation engine operates in a parallelized candidate regime (“5×5 Generation Strategy”), wherein for each target CVE, five candidates are concurrently generated with distinct LLM temperature settings; each candidate is afforded up to five refinement iterations informed by automated and human feedback mechanisms (Figure 2). This strategy significantly increases the search space and mitigates convergence on single-point failures, which are prevalent in deterministic or single-path deep learning solutions.
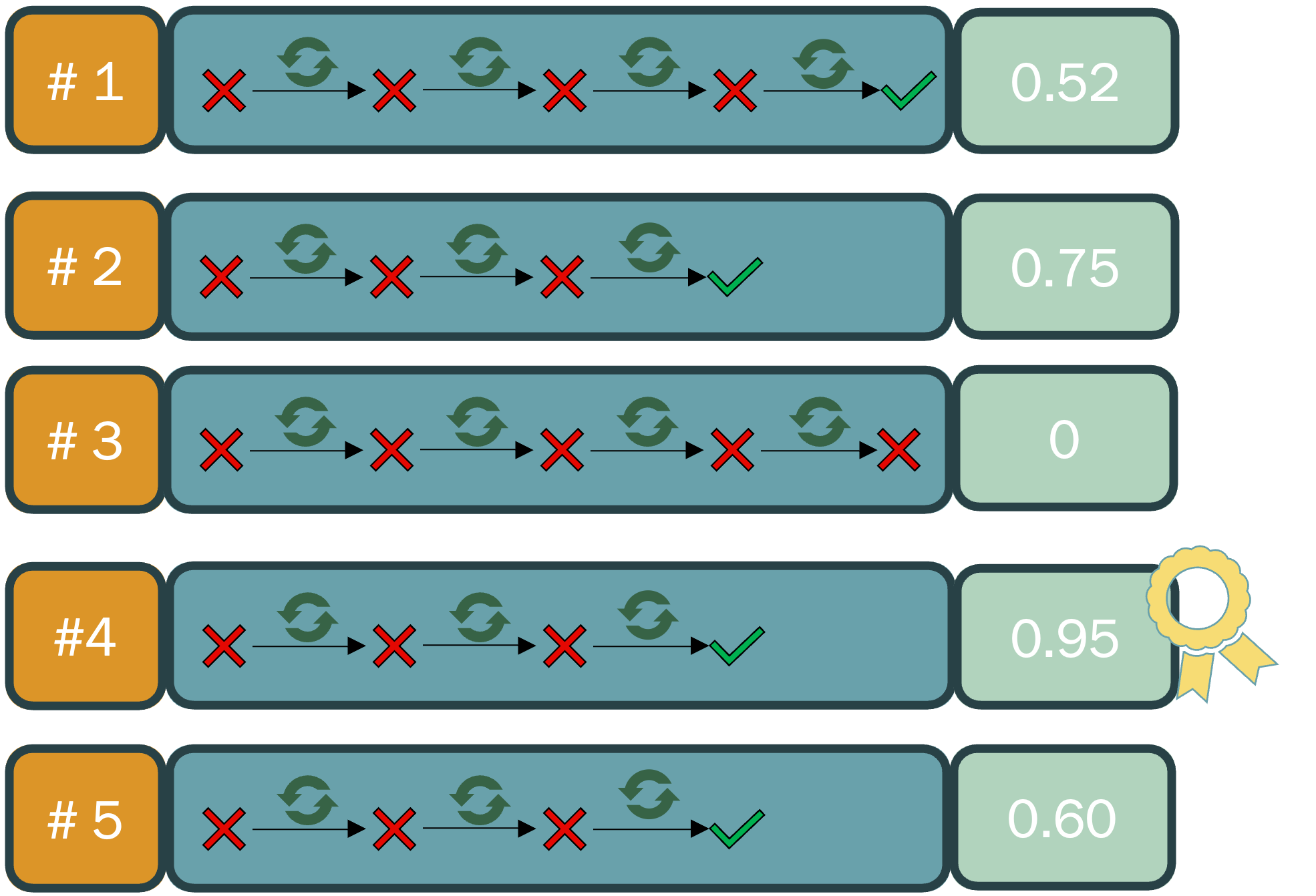
Figure 2: Five candidate rules are generated per CVE, each refined iteratively based on validation feedback, maximizing high-quality rule discovery.
The Feedback Integration component is tightly coupled to the validation pipeline, ensuring that specific rationales for failure (e.g., pattern misses, excessive generality, or overfitting) are coerced back into subsequent prompts for targeted improvement (Figure 3). This recursive learning methodology provides consistent performance gains across operational cycles.
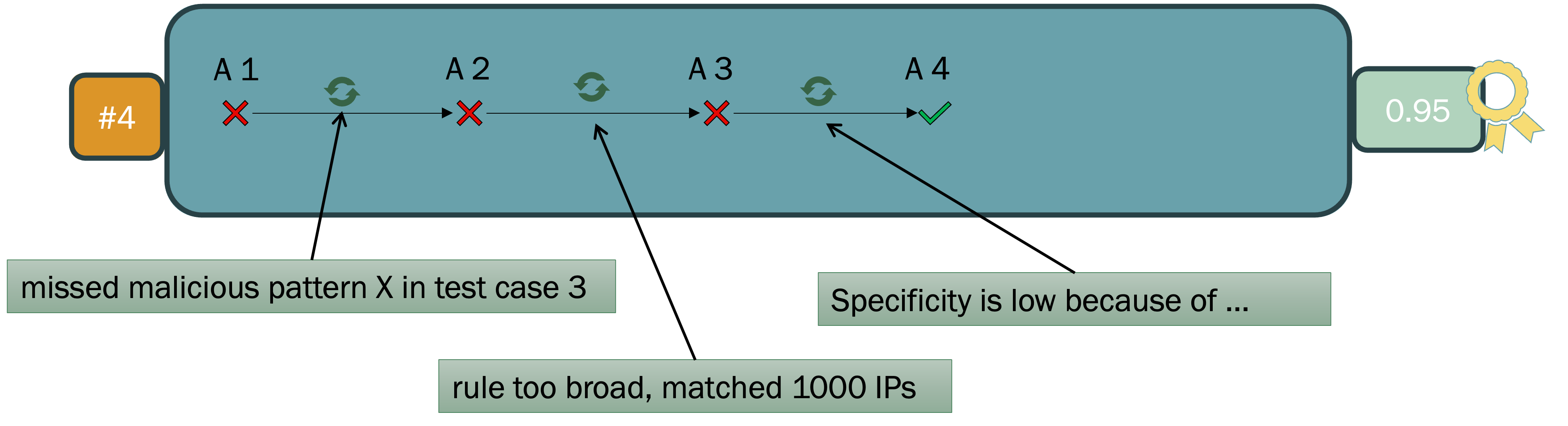
Figure 3: Fine-grained feedback about rule deficiencies directs automated refinement, yielding incremental quality improvements.
Candidate Rule Validation and LLM-as-a-Judge Framework
The multi-stage Candidate Rule Validation Pipeline enforces stringent rule quality prior to deployment (Figure 4). Each stage—synthetic testing, LLM-based sensitivity/specificity scoring, large-scale IP validation against web traffic, and manual security engineer review—constitutes a rejection filter, thereby minimizing both Type I (false positive) and Type II (false negative) errors.
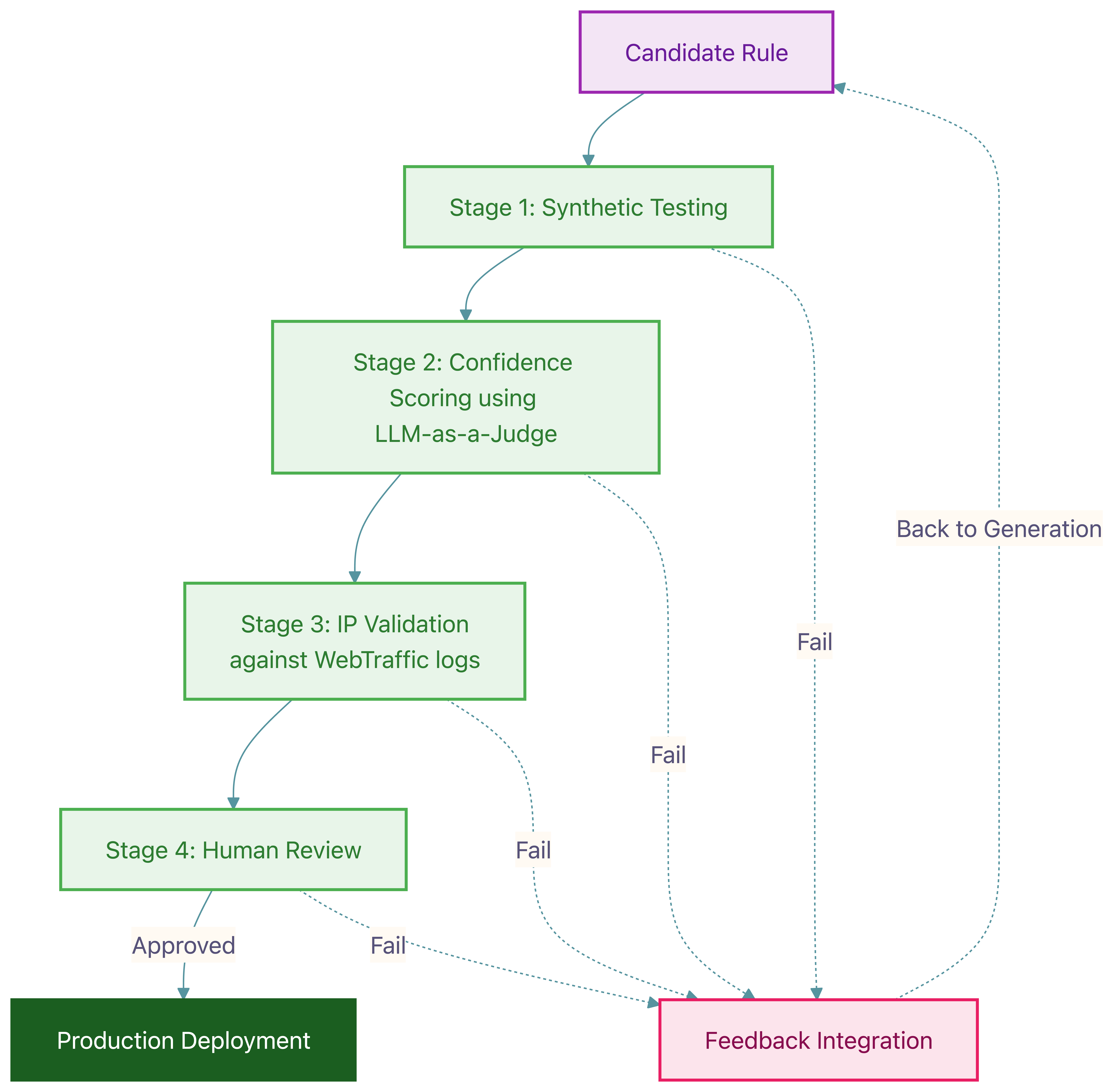
Figure 4: Rules sequentially face synthetic, LLM-based, and real-traffic validation, with failure feedback closing the refinement loop.
LLM-as-a-Judge Confidence Validation
A central innovation is the LLM-as-a-judge model for confidence scoring, which supplements rule-based validation with discriminative and interpretable quality estimation. The key aspects of this approach are:
- Sensitivity scoring estimates the risk of missed malicious traffic (false negatives).
- Specificity scoring assesses the risk of excessive benign matches (false positives).
Crucially, iterative prompt design consultations with domain experts led the authors to adopt negative-phrasing for evaluation prompts, e.g., “What is the probability the rule fails to flag some malicious requests?” This method yields stronger calibration and discrimination than generic self-confidence estimates—a critical nuance given current findings on LLM overconfidence and sycophancy.
Quantitative evaluation on 100 generation examples reports AUROC of 0.75 and ECE of 0.17 for the LLM-as-a-judge system (Figure 5), demonstrating its efficacy over random scoring and establishing practical utility as an automated filter in high-throughput production pipelines.
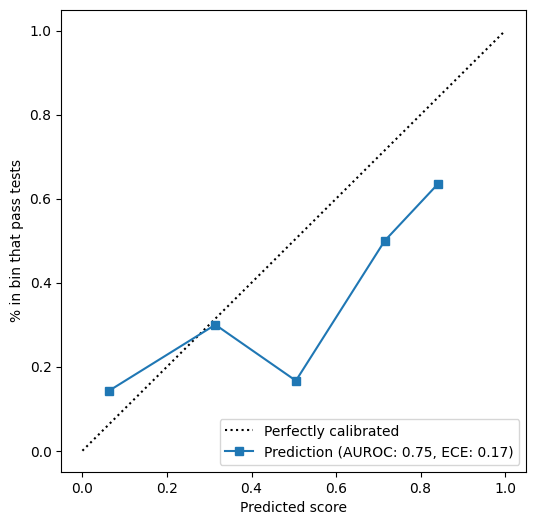
Figure 5: Reliability analysis shows robust calibration and discriminative capability for the LLM-as-a-judge scoring system.
The system not only decreases false positive rates by 67% and non-matching rules by 71% in production, but its integration as an early-stage filter significantly reduces computational cost and false positive propagation in downstream validation (Figure 6).
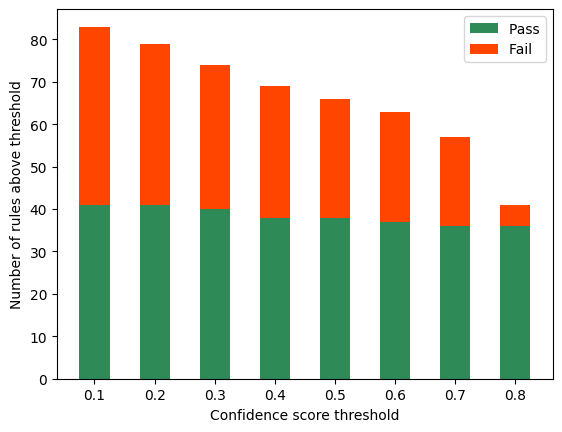
Figure 6: A rising confidence threshold filters out poorly performing rules while preserving top candidates.
Operational Outcomes and Productivity Implications
Deployment results over a four-month interval quantify strong operational gains. RuleForge’s automated production rate for valid CVE rules increased by 336% relative to human baseline, and by 419% over its earlier performance, while manual output saw a marginal increase (Figure 7). These gains are attributed not only to generative capacity but, critically, to the system's quality-retaining validation loop, which avoids the common pitfall of efficiency trade-offs in automated security tooling.
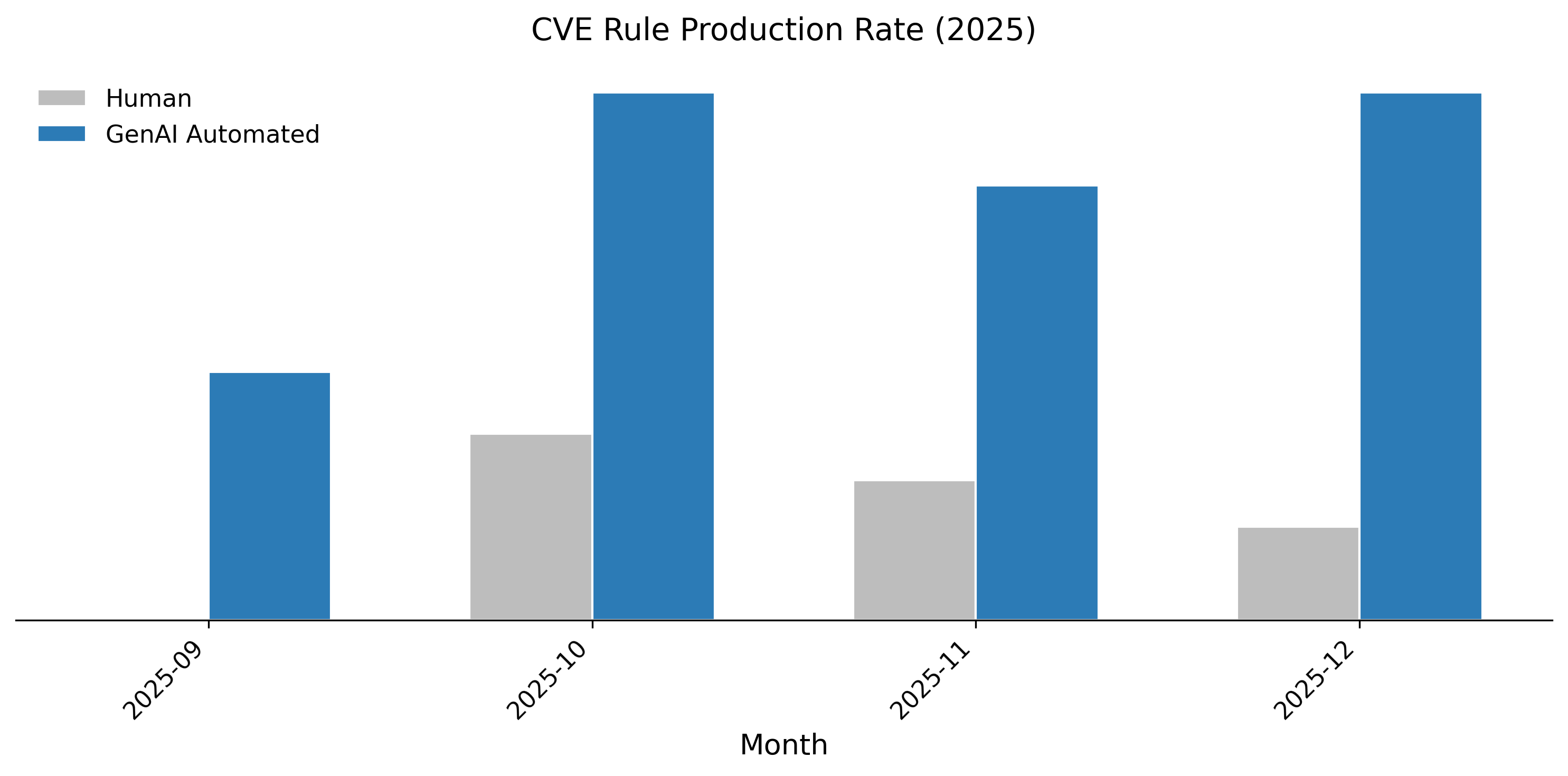
Figure 7: RuleForge automation sharply outpaces human performance in rule generation throughput.
Generalization: Toward Unstructured Data and Agentic Workflows
RuleForge extends beyond structured Nuclei input by enabling rule generation from unstructured data (e.g., blog posts, NVD free-form descriptions). Modified prompt regimes and refusal protocols ensure that rule hallucination is minimal, and empirical analysis yields a 40% total and 50% conditional (generated-only) success rate for rules sourced from such inputs. Failure analysis highlights improved early detection of unfit candidates as a promising research direction.
An agentic workflow prototype leverages DSPy’s ReAct framework, allowing an adaptive agent to select specialized rule generators, escalate to human review, or terminate processing for inapplicable vulnerabilities. The system's modularity readily supports additional event types (e.g., ProcessEvent, DnsEvent), promoting extensibility without necessitating large-scale prompt or model retraining.
Empirical Claims and Contrasts
- The pipeline's LLM-as-a-judge achieves AUROC of 0.75 and ECE of 0.17, reflecting well-calibrated confidence estimates in real-world settings.
- Absence of generic calibration: traditional LLM confidence self-reporting correlates poorly with actual rule quality (Figure 8), reinforcing the importance of expert-driven evaluation phrasing and targeted feedback incorporation.
- The multi-candidate, multi-refinement strategy demonstrates statistically significant improvement in rule quality and coverage compared to static or single-shot rule generation.
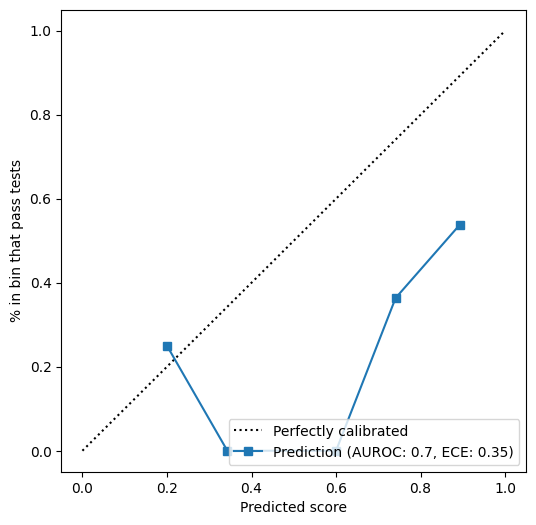
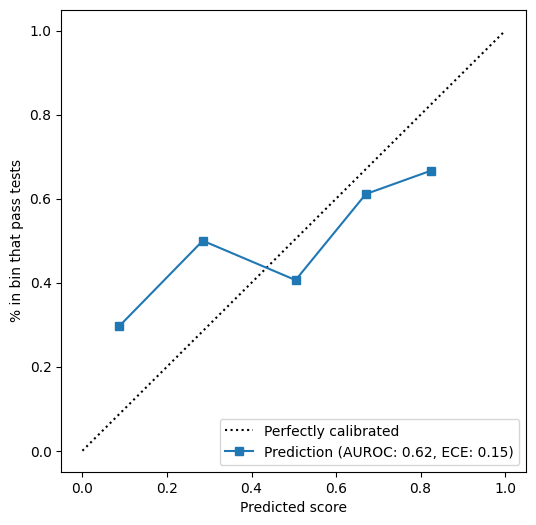
Figure 8: Generic confidence assessments lack useful discrimination, emphasizing the value of specificity and expert-driven prompt engineering.
Implications, Limitations, and Future Research
RuleForge substantiates that combining LLM-based generation with a discriminative, interpretable, and iterative validation-feedback pipeline can scale rule development for emerging web vulnerabilities without compromising performance or trust. The system’s explicit design for human-in-the-loop review—combined with an evidentiary validation pipeline—addresses the endemic skepticism toward full automation in operational cybersecurity environments.
Limitations include dependency on Nuclei template coverage (mitigated by ongoing unstructured data extension), and possible model family bias in LLM-based scoring (addressable through evaluator diversification).
Looking forward, anticipated research avenues include:
- Adaptive prompt and evaluator selection for heterogeneous event types
- Expansion of multi-modal event support (process, DNS, cloud trails)
- Advanced detection of unsuited vulnerabilities and early abandonment
- Integration of external threat intelligence for closure on false negative edge cases
Conclusion
RuleForge provides a compelling demonstration of LLM-centric automation for web vulnerability detection rules, delivering measurable productivity increases, lower manual burden, and empirically validated rule quality. Its contributions are both operational—directly impacting security engineering workflows inside AWS—and theoretical, exemplifying best practices in prompt engineering, iterative learning, and system modularity for AI-augmented cybersecurity systems. RuleForge’s architecture, evaluation pipeline, and extensibility suggest viable future trajectories toward generalized, agentic platforms for automated threat mitigation, setting technical benchmarks for further research and industrial adoption.
Reference:
"RuleForge: Automated Generation and Validation for Web Vulnerability Detection at Scale" (2604.01977)