LEAP: Supercharging LLMs for Formal Mathematics with Agentic Frameworks
Abstract: LLMs exhibit strong informal mathematical reasoning but struggle to generate mechanically verifiable proofs in formal languages like Lean. We present LEAP, an agentic framework that enables general-purpose foundation models to achieve state-of-the-art performance on automated formal theorem proving. LEAP leverages foundation model capabilities, such as informal reasoning, instruction following, and iterative self-refinement. By decomposing complex problems into smaller units, the system bridges formal proof construction with informal blueprints through continuous interaction with the Lean compiler. To provide a rigorous evaluation beyond increasingly saturated benchmarks, we introduce Lean-IMO-Bench, a benchmark of IMO-style problems formalized in Lean, with short statements yet highly non-routine and multi-step proofs across a wide range of difficulty levels. Empirically, on the latest 2025 Putnam Competition, an annual mathematics competition for undergraduate students in North America, LEAP solves all 12 problems, matching recent breakthroughs by frontier formal mathematical models. On Lean-IMO-Bench, LEAP boosts the one-shot formal solve rate of general-purpose LLMs from below 10% to 70%, notably surpassing the 48% benchmark set by a specialized, gold-medal-caliber IMO system. Furthermore, we demonstrate LEAP's research-level utility by autonomously formalizing complex proofs for open combinatorial challenges, including a verified proof for a key subproblem in Knuth's Hamiltonian decomposition of even-order Cayley graphs.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper introduces LEAP, a system that helps AI write perfectly checkable math proofs. It takes the strong “thinking” skills of LLMs and combines them with a strict math checker called Lean. The goal is to turn smart but sometimes sloppy ideas into proofs that a computer can verify as 100% correct.
The authors also build a new test set, Lean-IMO-Bench, made of International Math Olympiad–style problems written in Lean, to fairly measure progress.
What questions the paper tries to answer
Here are the main questions the paper explores:
- Can a general-purpose AI (not specially trained for Lean) still produce rigorous, computer-checked math proofs?
- If one-shot proof writing is hard, can an “agentic” process—plan, try, get feedback, and fix—make AI much better at formal math?
- How well does this approach work on tough contest problems like Putnam and IMO-style questions?
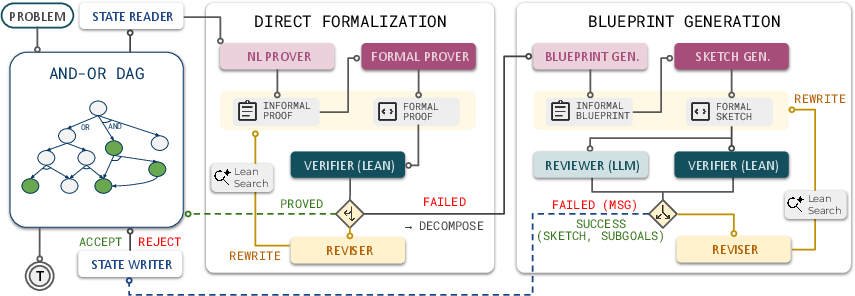
How LEAP works (in everyday terms)
Think of solving a hard math problem like building a Lego model without instructions. Doing it in one go is risky—you’ll make mistakes and need to redo pieces. LEAP instead acts like a careful builder:
- It sketches a plan first (an “informal blueprint”), explaining the key ideas and the smaller steps (lemmas) it will need.
- It turns that plan into Lean code. Lean is a proof language with a strict checker (like a super-picky math teacher) that says “yes” or “no” at every step.
- If Lean says “no,” LEAP doesn’t give up. It revises the plan, fixes errors, or breaks the problem into smaller subgoals.
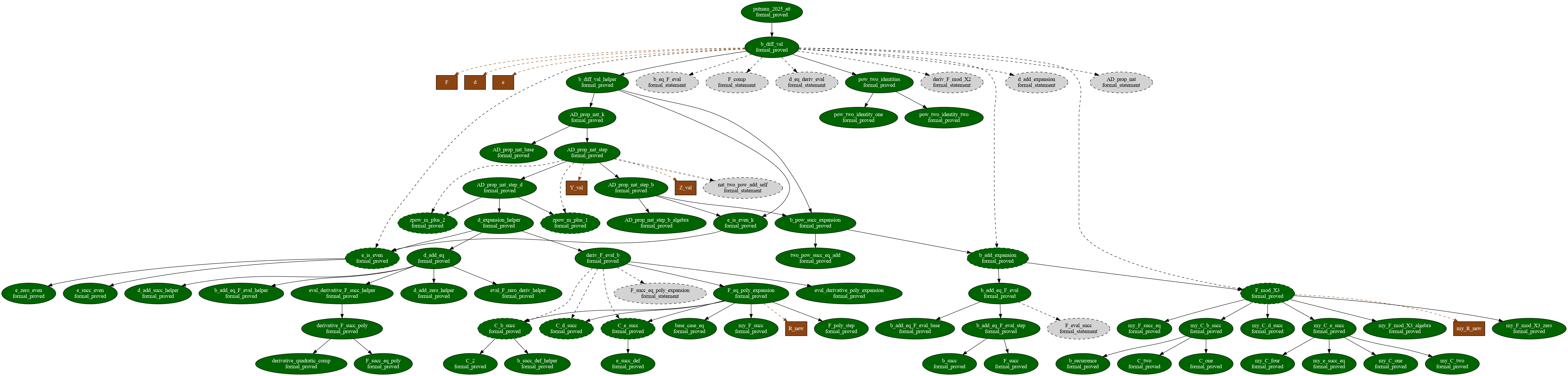
- It keeps a map of its work as a directed acyclic graph (DAG).
- Picture a dependency map where some steps must come before others.
- AND-nodes mean “we must finish all these sub-steps.”
- OR-nodes mean “there are multiple ways—any one path that works is fine.”
- This map lets LEAP reuse useful mini-results (lemmas) across different parts of the proof, saving time.
A few key ideas explained simply:
- “Formal proof” vs. “informal reasoning”: Informal reasoning is like explaining a solution in words. A formal proof is code in Lean that a computer checks with zero guesswork.
- “Agentic framework”: The AI behaves like an organized problem-solver—planning, trying, checking, and improving—instead of just answering once.
- “Compiler feedback”: When Lean rejects a proof, it tells LEAP what went wrong. LEAP uses that feedback to fix its approach.
- “LLM reviewer”: LEAP also asks the AI to judge whether a decomposition into subgoals is actually helpful (not just technically valid). This avoids wasting time on bad plans.
What the researchers found and why it matters
Main results:
- On Putnam 2025 (12 very hard undergraduate contest problems), LEAP solved all 12 in Lean. That’s a perfect score, matching top specialized systems.
- On Lean-IMO-Bench (60 IMO-style problems), LEAP greatly improved performance compared to using a general AI in one shot. In simple terms:
- General LLMs by themselves solved under 10% in one try.
- LEAP lifted that to around 70% overall, and did especially well in algebra and number theory.
- It also outperformed a strong, specialized system on this benchmark.
- LEAP wasn’t just good at contests—it helped formalize parts of research-level combinatorics, including a verified proof for a key subproblem in a challenge related to Knuth’s work on Hamiltonian decompositions, producing thousands of lines of correct Lean code.
Why this matters:
- Informal math solutions can be clever but sometimes imprecise or wrong. Formal proofs are guaranteed correct by a machine checker.
- LEAP shows that you don’t need a special Lean-only model. A general AI, guided by a smart process (plan–try–check–revise), can reach state-of-the-art results in formal math.
- This could speed up how math is verified, reduce human effort in checking long proofs, and make advanced math more reliable.
What this could change in the future
- Faster, safer math: LEAP can help verify tricky proofs that would take humans weeks or months to check carefully.
- Better collaboration: The blueprint DAG is readable and organized, making it easier for humans and AI to work together on big proof projects.
- Broader impact: The same “agentic” approach—plan, break down, verify—could improve AI reliability in other exact fields like programming, engineering, and science.
- Next steps: Improve how the system chooses which subgoals to try first, handle geometry better (a known tough area in Lean), and maybe combine general AIs with specialized proof models for even stronger performance.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored in the paper, phrased to be actionable for future work.
Method and system design
- Absence of a formal complexity analysis of LEAP’s DAG search: no theoretical bounds on runtime, branching, or convergence, and no guarantees of completeness or optimality relative to a given tactic set.
- Insufficient specification of the acyclicity and equivalence checks in the blueprint DAG: how semantic equivalence of goals/lemmas (beyond syntactic matching) is detected to prevent restating the original goal as a “new” subgoal.
- Limited characterization of the LLM-based decomposition reviewer: no details on prompts, calibration, inter-rater reliability, false-positive/false-negative rates, or how reviewer errors affect search; unclear whether the same model is used for both generation and review and whether this induces confirmation bias.
- No principled mechanism to measure or improve “lemma quality”: there is no metric for lemma usefulness, reusability, or minimality, nor any policy to avoid lemma bloat or redundant auxiliaries in the global memory.
- Search policy is a simple DFS with backtracking: unexplored alternatives include MCTS/PUCT, learned value/policy functions, beam allocation across branches, or RL for decomposition heuristics.
- Retrieval design is under-specified: LeanSearch integration lacks ablation on index size/coverage, retrieval precision-recall, and how retrieval quality interacts with decomposition depth.
- Lack of safeguards against unproductive decomposition patterns: beyond LLM review, no automated checks (e.g., proof-state complexity reduction, goal-size measures, or tactic-distance metrics) to reject decompositions that do not strictly simplify the parent goal.
- No discussion of tactic-level modularity: unclear how LEAP adapts when different tactic styles (mathlib tactics vs custom tactics) or proof search back-ends are swapped in.
- Interoperability with human blueprint tooling is not evaluated: the system is “inspired by” leanblueprint, but there is no demonstration of export/import to existing blueprint formats or collaborative workflows with humans.
Evaluation rigor and reproducibility
- Compute budget parity is unclear: LEAP uses “rollout=2” and thousands of LLM calls per problem; baselines are evaluated with different budgets (e.g., pass@128), making it hard to ascribe gains to algorithmic design vs. extra compute. Provide standardized compute/time/energy budgets across methods.
- Missing wall-clock and cost metrics on Lean-IMO-Bench: only Putnam includes LLM call counts; no end-to-end timings, GPU/CPU specs, or energy usage comparisons for any baseline.
- No variance or stability analysis: results are reported as single runs; lack of seed sweeps, run-to-run variance, or sensitivity to decoding parameters undermines claims of robustness.
- Limited failure analysis: apart from one A5 case study, there is no systematic taxonomy of failure modes (e.g., tactic failure, missing lemmas, bad decompositions, retrieval misses) or their frequencies.
- Potential training contamination is unaddressed: Gemini models may have seen Putnam-like or IMO-Bench-like problems; no data audits, decontamination procedures, or held-out splits with provenance guarantees.
- Reproducibility constraints from proprietary components: the main LLM (Gemini-3.1-Pro) is closed-source; prompts, system messages, temperature/top-p settings, and stopping criteria are not fully documented.
- Fairness of closed-source comparisons: Aristotle and other strong baselines are proprietary; evaluation settings (rollout limits, retries, tool access) may not be comparable; standardized harnesses are needed.
- Success criteria ambiguity: solve rates are binary and do not report partial progress metrics (e.g., fraction of subgoals closed, proof length vs. minimal known proof, or blueprint depth).
- No human evaluation of proof readability/maintainability: while proofs are kernel-verified, there is no assessment of code quality, tactic hygiene, or ease of human inspection/editing.
Benchmark design and scope
- Geometry remains a persistent failure mode: the paper retains geometry but does not explore integrating domain-specific geometry frameworks (e.g., synthetic geometry solvers, coordinate-geometry automation) to address it.
- Dataset formalization focuses on statements, not theory-building: generalization to problems requiring new definitions, large algebraic structures, or theorems not present in mathlib remains untested.
- Lack of longitudinal robustness testing against mathlib evolution: no evaluation of how proofs degrade across mathlib versions or how to auto-repair proofs after library updates.
- No multilingual or multi-PA generalization: transfer to Coq, Isabelle, or HOL Light is not studied; portability of the blueprint+DAG approach across proof assistants is an open question.
- Limited coverage beyond olympiad-style problems: performance on research-level theorems involving deep theories (analysis, algebraic geometry, category theory) is unknown.
Case studies and real-world utility
- “Autonomous formalization” of complex combinatorics relies on existing informal proofs: the extent of autonomy vs. reliance on provided proof sketches is unclear; quantify human input, seeding lemmas, and intervention rates.
- No quantitative cost/benefit analysis for large formalizations (e.g., the 5,000-line subproblem): how much compute/time was required, how easily could humans have achieved the same, and what is the net productivity gain?
- Scalability to multi-paper projects is untested: coordinating many interdependent blueprints, cross-lemma reuse at project scale, and refactoring across hundreds of nodes require dedicated evaluation.
Safety, reliability, and maintenance
- Risk of brittle reliance on compiler feedback: adversarial or misleading error messages could steer the agent; no safeguards or sanity checks against exploitative prompt/code patterns.
- No mechanism for formal regression testing: once a proof is found, there is no continuous integration strategy or test suite to detect regressions when lemmas/tactics/versions change.
- Lack of provenance and version tracking at the lemma level: the system does not record which prompts, retrieval results, or reviewer decisions produced a lemma, complicating auditability.
Extensions and unanswered design questions
- Hybridization with specialized provers is only hypothesized: no experiments combining a general LLM planner with a specialized Lean step-synthesizer; unclear where the handoff should occur and how to arbitrate between them.
- Learning to decompose: decomposition policies are not learned; investigating supervised or RL-trained decomposition heuristics on historical proof corpora is open.
- Better progress signals: beyond compiler yes/no and reviewer judgments, richer continuous progress metrics (goal size, proof-state similarity, dependency reduction) could guide search more effectively.
- Memory management at scale: strategies for pruning, caching, and prioritizing lemmas in a large global DAG are unspecified; policies are needed to avoid memory blow-up and maintain retrieval precision.
- Measuring and improving generalization across math domains: current results show domain skew (e.g., geometry); systematic cross-domain adaptation, curriculum scheduling, or modular tool-chains remain unexplored.
Practical Applications
Below is an overview of practical, real-world applications enabled by the paper’s findings, methods, and innovations. The applications are grouped by deployment horizon and, where helpful, mapped to sectors with concrete tool/workflow ideas and feasibility notes.
Immediate Applications
These can be piloted or deployed now using existing proof assistants (Lean 4) and general-purpose LLMs within the LEAP-style agentic workflow.
Academia and Research
- Autonomous formalization assistant for mathematicians
- What: Convert informal arguments (preprints, lecture notes, olympiad solutions) into Lean proofs via blueprint-driven decomposition with compiler-checked steps and LLM review.
- Tools/Products: “Blueprint Studio” (Lean plugin) that maintains an AND-OR proof DAG; “LLM Reviewer” panel to vet decompositions; auto-generated Lean proof sketches from informal blueprints.
- Dependencies/Assumptions: Availability of Lean 4 environment and mathlib coverage for the topic; compute budget for iterative LLM calls; author consent for autoformalization.
- Reproducible proof artifacts in publishing and peer review
- What: Submit machine-checkable Lean appendices with papers; reviewers inspect the blueprint DAG and verified lemmas instead of only prose.
- Tools/Products: Journal submission checkers that run Lean CI; arXiv/binder-like proof runners; DAG visualizers embedded in PDFs/web.
- Dependencies/Assumptions: Editorial policies accepting formal artifacts; stable Lean toolchain in CI.
- Benchmarking and evaluation for formal reasoning systems
- What: Use Lean-IMO-Bench as a rigorous, diverse testbed for automated formal provers; track progress beyond saturated datasets.
- Tools/Products: Hosted leaderboard with standardized Lean environments; problem category dashboards (algebra/NT/comb/geometry).
- Dependencies/Assumptions: Public dataset and reproducible runs; agreed evaluation protocols (e.g., rollout budgets, Pass@K).
Software and Systems Engineering
- Proof-augmented CI for critical libraries and algorithms
- What: Introduce proof obligations (pre/post-conditions, invariants) and use a LEAP-style agent to decompose and discharge them in Lean; store lemmas for reuse across modules.
- Tools/Products: “Proof DAG Cache” for CI/CD; IDE assistant to propose lemmas from specs; retrieval-augmented lemma reuse (LeanSearch).
- Dependencies/Assumptions: Specs expressed in a Lean-friendly logic; glue code connecting specifications (in comments or DSL) to Lean statements; initial proof culture within teams.
- Formal bug triage and patch validation
- What: Translate bug reports and fixes into formal claims (e.g., counterexamples, invariants restored), generate proof sketches, and verify patches with the compiler-in-the-loop loop.
- Tools/Products: “Spec-to-Lean” translators; regression property libraries; PR bots that attach proof status badges.
- Dependencies/Assumptions: Partial formalization of module interfaces; developer buy-in to maintain specs.
Cryptography and Web3/Finance
- Smart contract invariant checking (pilot scale)
- What: Prove safety properties (e.g., no reentrancy, conservation of assets) for small to medium contracts by decomposing invariants and leveraging lemma memoization.
- Tools/Products: Contract-to-Lean semantics adapters; “Invariant Blueprint” assistant to propose helpful lemmas before full proofs; proof certificates attached to deployments.
- Dependencies/Assumptions: Formal semantics of the target VM/language in Lean (or reliable bridges); manageable contract complexity; gas/latency not affected at runtime.
Education and Upskilling
- Interactive proof tutoring with guaranteed correctness
- What: Students write informal solutions; the system generates a Lean blueprint, highlights missing steps, and compiles toward a verified solution.
- Tools/Products: LMS integrations (Canvas/Moodle) with Lean sandboxes; per-step feedback from compiler errors; problem sets based on Lean-IMO-Bench.
- Dependencies/Assumptions: Classroom internet access and Lean playgrounds; curated curricula mapping to mathlib primitives; teacher dashboards.
- Automated grading for proof-based courses
- What: Use formal proof sketches as ground truth; accept equivalent student proofs if they compile and respect dependency structure.
- Tools/Products: Rubrics tied to blueprint nodes; plagiarism detection via DAG shape comparison rather than code string matching.
- Dependencies/Assumptions: Problem statements pre-formalized; tolerance for multiple proof paths.
Scientific and Engineering Workflows
- Constraint/optimization proof scaffolding
- What: Provide verified proofs of feasibility/optimality conditions (KKT assumptions, convexity lemmas) around computational pipelines.
- Tools/Products: “Assumption Audit” that enumerates subgoals needed to justify solver claims; library of standard convex analysis lemmas.
- Dependencies/Assumptions: Sufficient formal libraries for optimization; engineers willing to state assumptions explicitly.
Knowledge Management
- Proof knowledge bases with shared lemma reuse
- What: Build an organizational repository of reusable lemmas and blueprints; the DAG memoizes common subproblems across projects.
- Tools/Products: “Lemma Registry” with discovery and citation; cross-project retrieval integrated into LEAP-like agents.
- Dependencies/Assumptions: Naming conventions; metadata for lemma scope and generality; access controls.
Long-Term Applications
These require further research, scaling, domain formalization, or broader ecosystem adoption.
Large-Scale Formalization and Scientific Infrastructure
- At-scale autoformalization of textbooks and research corpora
- What: Convert vast swaths of mathematics, CS theory, and parts of physics into machine-checkable repositories, enabling search and recombination of proofs.
- Tools/Products: Literature-to-Lean pipelines; cross-paper lemma linking; “Proof Wikipedia” with verified dependencies.
- Dependencies/Assumptions: Extensive domain libraries (geometry remains challenging); robust OCR/semantic parsing; community governance.
- Formal peer review as standard practice
- What: Journals mandate mechanically checkable artifacts for key results; automated checks during submission.
- Tools/Products: Publisher-integrated proof runners; artifact policies; long-term archiving of Lean environments.
- Dependencies/Assumptions: Cultural shift; funding for tooling and compute; standardized formats.
Safety-Critical and Cyber-Physical Systems
- End-to-end verified stacks (compilers → kernels → control laws)
- Sectors: Robotics, automotive (ISO 26262), avionics (DO-178C), medical devices (IEC 62304), industrial automation.
- What: Use LEAP-like decomposition to manage large proof DAGs across layers: compiler correctness, scheduler properties, controller safety, plant invariants.
- Tools/Products: Cross-prover bridges (Lean↔Coq↔Isabelle↔SMT); contract-based design pipelines; “Proof-Carrying Build” artifacts attached to firmware/software releases.
- Dependencies/Assumptions: High-fidelity formal models of hardware/physics; regulatory acceptance of formal evidence; scalable heuristics for massive DAGs.
- Runtime assurance with offline proof guarantees
- What: Combine offline proofs of safety envelopes with runtime monitors; prove that violations trigger safe shutdown logic.
- Tools/Products: Proof-backed monitors; signed proof certificates deployed with systems.
- Dependencies/Assumptions: Certified monitor synthesis; integration with real-time OS constraints.
Finance and Policy/Regulation
- Proof-carrying transactions and protocols
- What: Financial primitives (AMMs, lending) require machine-checkable invariants before mainnet listing; exchanges accept “proof bundles.”
- Tools/Products: Protocol verification pipelines; on-chain verification metadata; auditor dashboards consuming proof DAGs.
- Dependencies/Assumptions: Industry standards; formal VM specs; gas-efficient verification strategies (often off-chain with on-chain commitments).
- Machine-checkable regulatory compliance
- What: Formalize parts of compliance (risk bounds, fairness constraints, privacy guarantees) and submit proof artifacts to regulators.
- Tools/Products: Compliance DSL-to-Lean translators; regulator-run verifiers; continuous compliance CI.
- Dependencies/Assumptions: Regulators adopt formal artifacts; sector-specific libraries (e.g., credit risk, privacy math) in Lean.
Software Engineering at Scale
- “Proof Copilot” for mainstream development
- What: IDE-native assistant that takes specs/tests and emits verified proofs or counterexamples; manages lemma reuse across repos.
- Tools/Products: Multi-prover backend with LEAP-style heuristics; code-to-spec mining; automatic strengthening of lemmas.
- Dependencies/Assumptions: Developer workflows embracing formal specs; improved mapping from code to logic; cost-effective inference.
- Verified ML systems and AI safety artifacts
- What: Proofs of convergence, robustness bounds, and safety constraints for ML components and agent policies.
- Tools/Products: Libraries for probability/measure theory in Lean; tools connecting empirical tests with formal claims.
- Dependencies/Assumptions: Mature formal libraries for modern ML; scalable decomposition heuristics for stochastic proofs.
Education and Public Benefit
- Mass-personalized, correctness-guaranteed STEM tutoring
- What: Adaptive curricula where every exercise has a machine-checkable solution path; scaffolded hints derived from blueprint DAGs.
- Tools/Products: Mobile apps with Lean backends; teacher co-pilots for assignment generation.
- Dependencies/Assumptions: Easier installation/hosting of Lean; content coverage across K–12/undergrad; accessibility support.
- National/organizational training in formal methods
- What: Upskilling programs to mainstream formal verification across industry and government.
- Tools/Products: Bootcamps powered by auto-grading and DAG analytics; certification tracks tied to proof portfolios.
- Dependencies/Assumptions: Policy incentives; curricular standards; scalable cloud environments.
Cross-Cutting Technical Advancements
- Hybrid provers: foundation LLMs + specialized ATPs
- What: Combine LEAP’s blueprinting and reviewer heuristics with specialized step generators (e.g., tactic synthesis), improving speed and robustness.
- Tools/Products: Unified orchestration layer; shared memory of lemmas; learning-to-prioritize subgoals at scale.
- Dependencies/Assumptions: Interoperability across models; data-sharing for tactic learning; governance of closed/open components.
- Domain-specific formal geometry and beyond
- What: Rich geometry libraries and automated tactics to close the current gap in olympiad-level geometry and other under-served areas.
- Tools/Products: New axiomatizations and tactic sets; translation layers from dynamic geometry software.
- Dependencies/Assumptions: Community investment; careful design to avoid brittleness.
Notes on feasibility and constraints common across applications:
- Compute and latency: Iterative, compiler-in-the-loop workflows can be costly; batching, caching (lemma memoization), and prioritization heuristics are critical.
- Library coverage: Success depends on high-quality domain libraries; geometry remains harder than algebra/NT/comb.
- Human-in-the-loop: LLM reviewers help prune unproductive branches; expert oversight remains valuable for ambiguous or novel domains.
- Toolchain stability: Reproducibility requires pinned Lean versions and hermetic CI environments.
- Data/privacy: Formalizing proprietary systems needs secure, on-prem deployments and careful IP handling.
In sum, the paper’s agentic, blueprint-driven, verification-guided approach unlocks immediately useful assistants for formal math and software proofs, while charting a path toward industrial-scale, machine-checkable assurance across safety-critical systems, finance, and scientific publishing.
Glossary
- agentic framework: A multi-step LLM system that plans, acts, and adapts using tools and feedback. "an agentic framework that enables general-purpose foundation models to achieve state-of-the-art performance on automated formal theorem proving."
- AND node: In an AND-OR proof graph, a node that is satisfied only when all its child subgoals are proven. "it is added as an AND node, and the proposed lemmas are added as child OR nodes."
- AND-OR DAG: A directed acyclic graph where OR nodes represent alternative strategies and AND nodes represent required subgoals, structuring proof search. "represented as an OR node in the AND-OR DAG."
- anticipatory lemma planning: Proposing auxiliary lemmas that aren’t immediately needed but may be reused later to speed proof search. "Through anticipatory lemma planning, the agent may also propose auxiliary lemma statements that are not immediately required but could be useful later"
- Automated Theorem Proving (ATP): The use of automated methods and provers to produce formal, machine-checkable proofs. "These make them ideal for agentic ATP frameworks"
- backtracking: A search strategy that undoes choices to explore alternative branches when progress stalls. "Currently, LEAP uses a simple DFS over the DAG with backtracking."
- blueprint (Lean Blueprint): A human-readable proof roadmap linked to Lean code that outlines lemmas and dependencies. "use the Lean Blueprint tool"
- Cayley graph: A graph built from a group and a set of generators; vertices are group elements and edges correspond to generator actions. "the directed Cayley graph "
- Coq: An interactive theorem prover based on the Calculus of Inductive Constructions. "Isabelle \citep{nipkow2002isabelle}, Coq \citep{huet1997coq}, HOL Light \citep{harrison2009hol}"
- compiler feedback: Diagnostic information from the Lean compiler (e.g., type errors) used to iteratively repair proofs. "iteratively correcting errors via compiler feedback."
- DFS: Depth-first search; a strategy that explores one branch of the search tree/graph as far as possible before backtracking. "a simple DFS over the DAG with backtracking."
- directed acyclic graph (DAG): A directed graph with no cycles, often used to represent dependencies. "visualized as a directed acyclic graph (DAG)"
- Formal Proof Translation: The task of converting a correct informal (natural-language) proof into verified Lean code. "Formal Proof Translation"
- formal theorem proving: Constructing machine-checkable proofs in a formal system, typically via a proof assistant. "automated formal theorem proving."
- formal verification: Mathematically proving correctness with a machine-checked proof. "eventually necessitating a decade-long formal verification effort"
- Hamiltonian decomposition: Partitioning all edges/arcs of a graph into disjoint Hamiltonian cycles. "Knuth's Hamiltonian decomposition of even-order Cayley graphs."
- HOL Light: A lightweight interactive theorem prover for higher-order logic. "Isabelle \citep{nipkow2002isabelle}, Coq \citep{huet1997coq}, HOL Light \citep{harrison2009hol}"
- Isabelle: A generic interactive theorem prover supporting multiple logics. "Isabelle \citep{nipkow2002isabelle}, Coq \citep{huet1997coq}, HOL Light \citep{harrison2009hol}"
- Lean: An interactive theorem prover and programming language used for formal mathematics. "in formal languages like Lean."
- Lean 4: The current major version of Lean with a new compiler/runtime and improved language features. "Lean 4 code"
- Lean compiler: Lean’s type checker/verifier that ensures formal proofs are correct. "continuous interaction with the Lean compiler."
- Lean-IMO-Bench: A benchmark of IMO-style problems formalized in Lean to evaluate formal proving ability. "we introduce Lean-IMO-Bench"
- LeanSearch: A retrieval tool to fetch relevant Lean theorems/lemmas during proof generation. "LeanSearch\citep{leansearch} retrieval."
- lemma memoization: Storing and reusing intermediate lemma statements across branches to reduce redundant work. "Second, lemma memoization: intermediate lemma statements are stored as shared proof nodes"
- monotone refinement: A property of the proof plan where decomposition adds structure without invalidating established dependencies. "First, monotone refinement: once a goal is decomposed into supporting subgoals, subsequent search can focus on expanding and resolving these descendants"
- Natural Language Proof: Evaluating or producing proofs written in ordinary language rather than a formal proof assistant. "Natural Language Proof"
- OR node: In an AND-OR proof graph, a node that can be satisfied by any one of several alternative strategies or proofs. "represented as an OR node in the AND-OR DAG."
- Pass@128: A sampling-based metric: success if any of 128 independently sampled attempts solves the problem. "Under a Pass@128 setting"
- proof obligation: A specific statement that must be proved to advance or complete the overall proof. "where each node represents a proof obligation."
- proof sketch (Lean sketch): A partially formal outline that proves the main goal assuming stated lemmas, which may be left as holes. "then translates the blueprint into a Lean proof sketch."
- rollout: One end-to-end search run or attempt under a fixed compute/time budget. "we bounded each Hilbert rollout to a 7-day time limit."
- sorry placeholders: Lean’s special holes indicating unfinished parts of a proof. "sorry placeholders are permitted only in the newly proposed lemma statements."
- sorry-free: Having no ‘sorry’ holes; a complete, fully verified Lean proof segment. "the main theorem body is sorry-free"
- subgoal: A secondary goal introduced by decomposition that, once proved, helps establish the parent goal. "A goal is any theorem or lemma statement to be proved; decomposition introduces subgoals."
- verification-guided proof search: Using the formal verifier (and often LLM heuristics) to direct which branches to accept, refine, or abandon. "verification-guided proof search, which uses compiler feedback and LLM-based review to accept, revise, decompose, or abandon candidate branches."
Collections
Sign up for free to add this paper to one or more collections.