Advancing Mathematics Research with AI-Driven Formal Proof Search
Abstract: LLMs increasingly excel at mathematical reasoning, but their unreliability limits their utility in mathematics research. A mitigation is using LLMs to generate formal proofs in languages like Lean. We perform the first large-scale evaluation of this method's ability to solve open problems. Our most capable agent autonomously resolved 9 of 353 open Erdős problems at the per-problem cost of a few hundred dollars, proved 44/492 OEIS conjectures, and is being deployed in combinatorics, optimization, graph theory, algebraic geometry, and quantum optics research. A basic agent alternating LLM-based generation with Lean-based verification replicated the Erdős successes but proved costlier on the hardest problems. These findings demonstrate the power of AI-aided formal proof search and shed light on the agent designs that enable it.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper shows how AI can help do real mathematics by writing proofs in a way that a computer can double‑check every step. The team built an AI system, called AlphaProof Nexus, that uses LLMs together with a strict proof checker called Lean. The big idea: let the AI propose many proof attempts, and let Lean accept only the ones that are 100% correct, step by step.
What questions the researchers asked
They focused on simple, practical questions:
- Can AI, guided by a proof checker, actually solve open, research‑level math problems?
- Which AI “agent” designs work best: a simple try‑and‑check loop, or a more advanced, coordinated search with extra tools?
- How much does it cost (in money and time) to get correct proofs this way?
- In what kinds of math problems does this approach help most?
How the system works (in everyday terms)
Imagine you’re solving a tough puzzle with a very strict referee:
- Lean is the referee. It only accepts proofs written in a precise, code‑like language. If even one step isn’t justified, Lean refuses the proof. There’s also a placeholder called
sorrythat means “I don’t know this part yet”; a finished proof must have nosorrys. - The AI is like a team of problem‑solvers that:
- Writes and edits a “proof sketch” (a Lean file with
sorrywhere the hard parts are). - Tries tactics (small steps) to fill in the gaps.
- Asks the referee (Lean) after each change: “Does this still check out?”
- Learns from error messages and keeps improving.
- Writes and edits a “proof sketch” (a Lean file with
There are a few versions of this AI team:
- Basic agent: a simple “try, check, and revise” loop. It runs many independent attempts in parallel.
- AlphaProof‑equipped agent: the basic agent plus a helper tool (AlphaProof) that’s good at solving smaller sub‑goals, like a specialist you can call in.
- Evolutionary agent: keeps a “population” of promising proof sketches, ranks them (using chess‑style Elo ratings), mixes and improves the better ones, and tries again—like natural selection for ideas.
- Full‑featured agent: combines both the helper tool and the evolutionary search. This is the strongest setup they tested.
Analogy:
- Think of writing a tricky essay with strict grammar software. You write drafts, the software flags errors, you fix them, and repeat. Now add a library of example paragraphs (AlphaProof) you can reuse, and a coach who ranks your drafts and suggests merging the best parts (evolution).
What they found and why it matters
Here are the main results, with brief reasons they’re important:
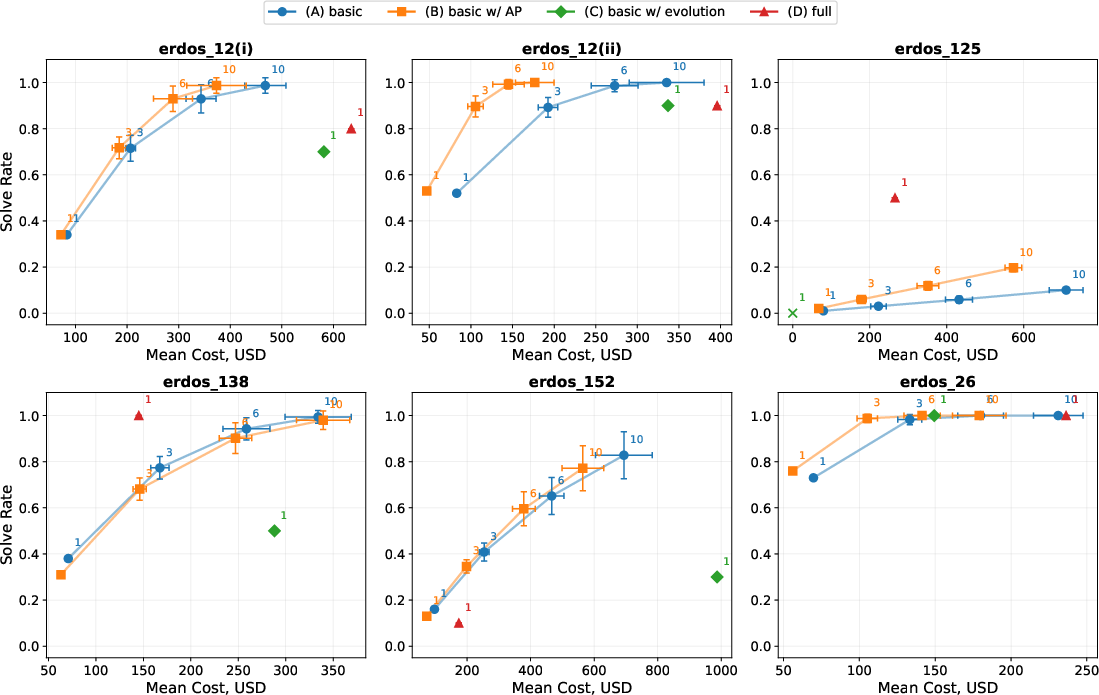
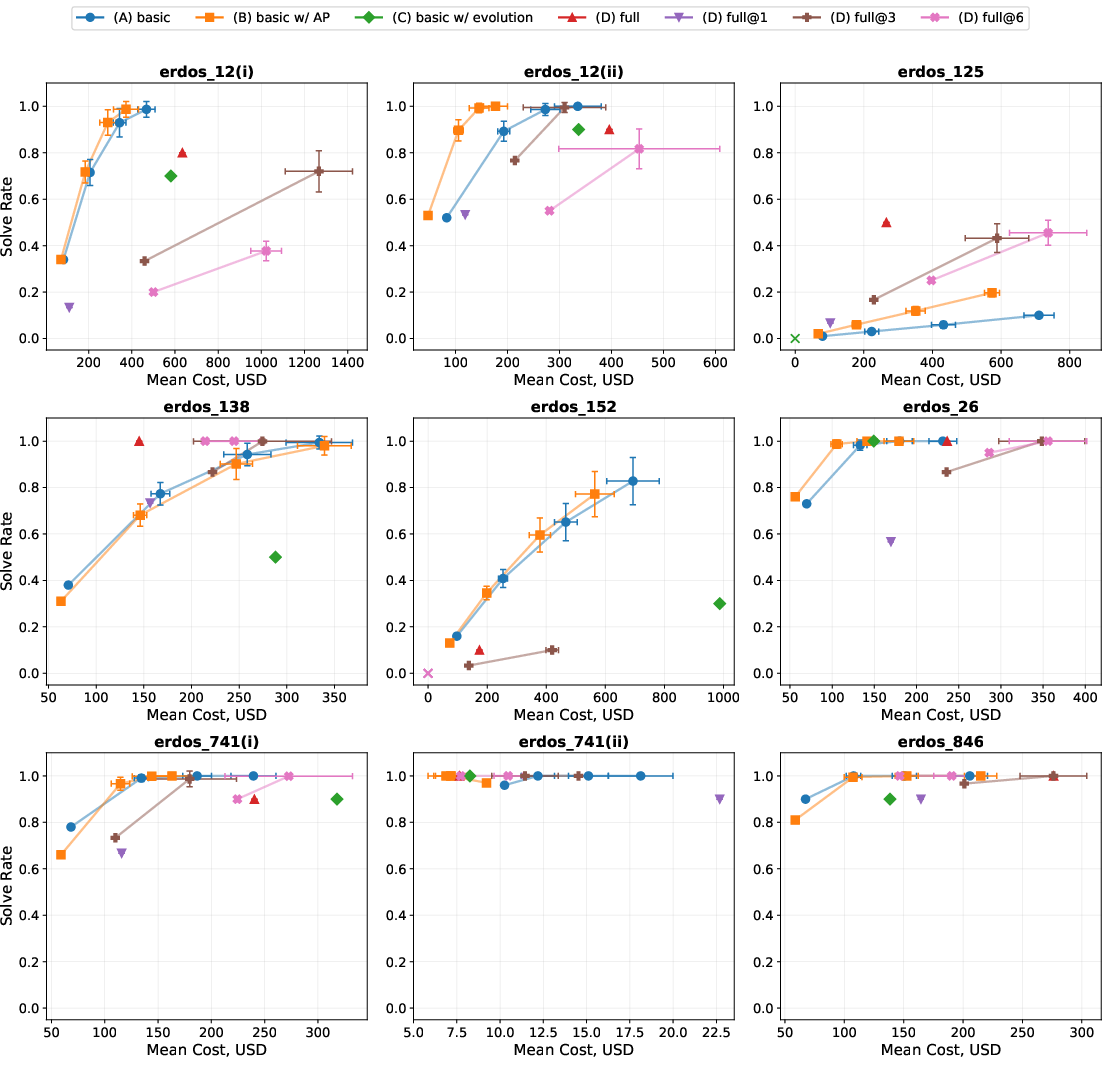
- Solved 9 out of 353 formalized Erdős problems
- These are well‑known, hard combinatorics/number theory problems. Some had been open for over 50 years.
- Cost: a few hundred dollars of AI compute per problem.
- Why it matters: shows the approach can crack real research questions, not just classroom exercises.
- Proved 44 out of 492 open OEIS conjectures
- The OEIS is a huge collection of number sequences and facts about them. The team auto‑translated 492 open questions into Lean and required the AI to pass “sanity checks” first (verifying early terms).
- Why it matters: demonstrates breadth—many problems, consistent verification, and careful guarding against misunderstanding the question.
- Helped in multiple research areas
- Optimization: Found a sharper convergence guarantee for a min‑max algorithm and even discovered a better parameter schedule on its own. This is like both designing the machine and proving it works better.
- Algebraic geometry: Resolved a 15‑year‑old question about when certain sequences are “log‑concave.”
- Graph theory: Proved a variant related to reconstructing graphs and solved a conjecture from an automated system (Graffiti).
- Quantum optics: Proved existence results connected to special multi‑particle quantum states (high‑dimensional GHZ states).
- Why it matters: AI didn’t just check known results—it produced new knowledge across different fields.
- Caught and corrected misformulations
- In some Erdős problems, the exact meaning of “density” was ambiguous. The AI’s attempts exposed the mismatch, leading to corrected statements that the AI then proved.
- Why it matters: shows AI can help clean up problem statements, not only solve them.
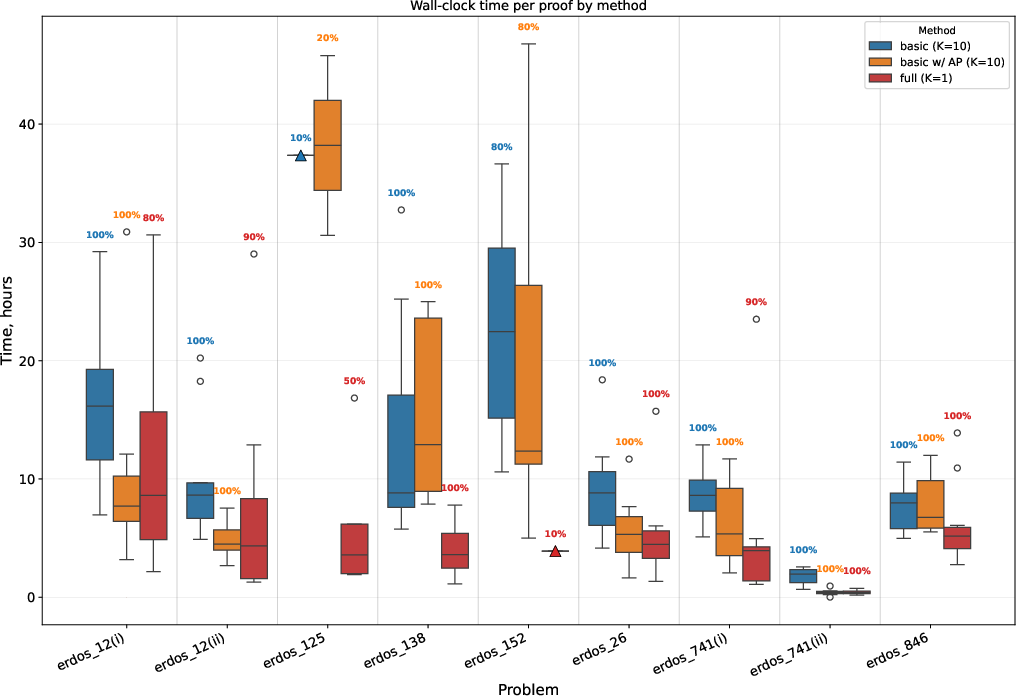
- Agent design lessons
- The simple agent often matched the advanced one but was more expensive on the hardest problems. The full‑featured agent helped most on the trickiest cases.
- Smaller, cheaper models and a stand‑alone proof tool couldn’t solve these hard problems alone.
- Why it matters: as LLMs improve, even simple try‑and‑check loops become powerful, but coordination and tools still help with the toughest work.
How exactly the research ran (light on jargon)
- Input: A Lean file describing the problem and placing
sorrywhere proofs are missing. The file marked which parts the AI was allowed to change. - Loop: The AI proposed edits, Lean checked them, and the AI used Lean’s feedback to try again. Sometimes it called the AlphaProof helper to fill sub‑goals.
- Evolution: In the advanced mode, the system kept many candidate sketches, compared them (like matches), and used ratings to guide which to continue developing.
- Stopping: If the final Lean file had no
sorryand compiled cleanly, the proof was accepted.
What this means for the future
- Reliable AI math: By insisting on machine‑checked proofs, the system avoids “hand‑wavy” or misleading arguments. This builds trust: if Lean accepts it, every step is justified.
- Human‑AI teamwork: Mathematicians can use these agents to explore ideas faster, find subtle mistakes, and focus on the hardest gaps rather than re‑checking everything.
- Limits today: The method works best in areas where the Lean library is strong and problems split into manageable pieces. Many problems remain out of reach, and results can vary from run to run.
- Trend: As AI models get better, simple “try‑and‑check” loops become surprisingly strong. But for the hardest problems, smarter coordination and helper tools still make a difference.
In short, this paper shows a practical, trustworthy way for AI to contribute to real mathematics: generate many ideas, let a strict proof checker filter them, and steadily turn guesswork into guaranteed truth.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list captures what remains uncertain, missing, or unexplored in the paper, phrased to guide concrete future work:
- Formalization fidelity at scale remains unresolved: beyond ad hoc expert checks (Erdős) and “test lemmas” (OEIS), there is no systematic, automated protocol to certify that a Lean statement faithfully matches a natural-language conjecture, especially when definitions (e.g., “density”) are ambiguous.
- Autoformalization verification is shallow: checking only initial sequence terms in OEIS is insufficient to guarantee correctness of definitions and conjecture statements; a stronger suite of semantic tests and cross-formalizations is needed.
- Validator guarantees are unspecified: the criteria by which the validator deems that the problem statement is “not changed unsafely” are not formalized, audited, or open-sourced; there is no formal proof that EVOLVE-BLOCK/EVOLVE-VALUE restrictions prevent statement drift or hidden weakening/strengthening of hypotheses.
- Misformalization detection is opportunistic: reliance on the agent to “discover” inconsistent interpretations (e.g., upper vs natural density) is fragile; automated ambiguity detection, definition disambiguation, and NL–formal alignment methods are not developed.
- Hallucinated-lemma failure mode persists: the agent invents non-existent lemmas and defers core difficulty into helper lemmas with single sorrys; there is no automated citation checking, cross-library validation, or retrieval-based grounding to prevent or flag such hallucinations.
- Binary fitness undermines evolution: ranking partial sketches via LLM critics is a heuristic with unknown correlation to eventual solvability; no ablation quantifies critic accuracy, calibration, or bias, nor compares against compiler-derived progress signals (e.g., open-goal complexity, proof-state distances).
- Elo-based sampling lacks validation: there is no evidence that Elo over LLM-ranked sketches improves search efficacy vs simpler heuristics or UCB on compiler-grounded rewards; the sensitivity of performance to rater quality, match format, and rating parameters is unmeasured.
- Subgoal selection and AlphaProof scheduling are unoptimized: the paper does not analyze when to invoke AlphaProof, how to prioritize subgoals, or how these choices affect success and cost; principled scheduling strategies are an open problem.
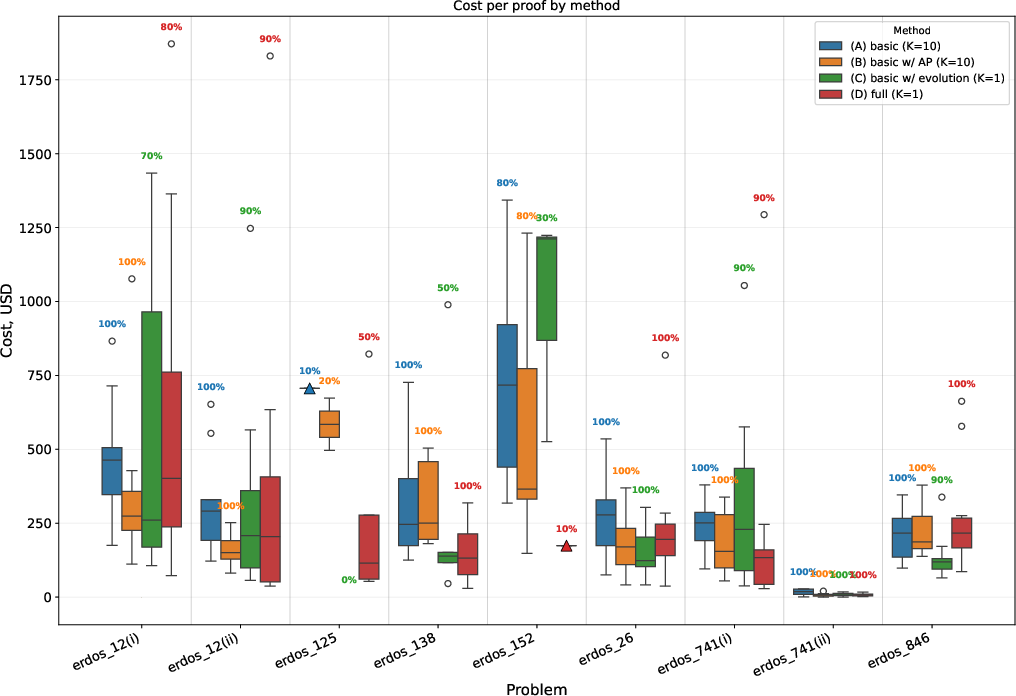
- High cost variance is unmanaged: stopping rules, adaptive budget allocation across problems, and dynamic early-exit criteria are not explored; solve probability as a function of episodes and budget is not modeled to enable compute triage.
- Limited statistical confidence for expensive agents: agents (C/D) are evaluated with few runs and reported without variance; robust estimates, confidence intervals, and power analyses for solve rates and costs are missing.
- Cost reporting is inconsistent: some plots exclude AlphaProof cost, and energy/emissions are not reported; reproducibility across hardware/pricing regimes and holistic cost models (inference + tool calls + search overhead) are absent.
- Domain coverage is narrow and library-dependent: successes cluster in areas with mature mathlib support (combinatorics, number theory, convex optimization); scalability to areas requiring substantial new theory (e.g., analysis, topology, PDEs) is untested.
- Library-building capability is underexplored: the agent can add helper lemmas/definitions but there is no mechanism or evaluation for constructing coherent new theory layers (definitions, APIs, reuse) needed for hard problems.
- Cross–proof-assistant generality is unknown: all work is in Lean 4; portability to Coq/Isabelle/HOL Light and strategies for library translation and interop are unaddressed.
- Basic vs full-featured agent gap is not characterized: the surprising strength of the basic loop is noted but not explained; ablations on prompt design, compiler feedback granularity, tool-calling frequency, and memory/context usage are needed to map when complexity helps.
- No controlled comparisons to other SOTA formal agents: head-to-head evaluations against systems like Aristotle, Seed-Prover, Kimina, Goedel-Prover, or Numina on the same open-problem suite are missing.
- Natural-language pipeline comparisons are absent: the paper motivates formal verification vs NL proofs but lacks controlled studies comparing yield, review effort, and error rates across formal and deformalized pipelines on matched tasks.
- Training data contamination is unassessed: there is no audit ensuring that LLMs were not exposed to targets or partial solutions; procedures for leakage detection and documentation are needed for claims of novelty.
- Novelty validation is ad hoc: beyond spot checks, there is no systematic bibliographic/citation audit to confirm that machine-found proofs and parameter schedules are genuinely new.
- Partial-progress metrics are unused: evaluation treats success as binary compilation; there is no metricization of incremental progress (e.g., goal reduction, tactic success rates) to analyze search dynamics or guide evolution.
- Compute–performance scaling laws are unmodeled: the relationship between episodes, subagent count, context length, and solve probability is not quantified; such models would enable principled budget allocation.
- Human-in-the-loop strategies are unspecified: while collaboration anecdotes are positive, there is no protocol or measurement for when and how to inject human guidance, feedback, or constraints to maximize solve rate per unit effort.
- Safety and robustness to adversarial inputs are untested: the system’s behavior under malformed sketches, adversarial EVOLVE markers, or tricky dependent type scenarios is not evaluated; formal guarantees of soundness under all allowed transformations are absent.
- Parameter-search generality is unclear: the optimization example evolves a learning-rate schedule, but there is no framework or benchmarks for broader “algorithm discovery” (e.g., updates, regularizers, data-dependent schedules) and validation of out-of-distribution robustness.
- Problem triage and selection remain manual: the agent expended compute exploring many intractable instances; automated difficulty prediction and triage policies are not developed.
- Reproducibility is constrained by proprietary models/tools: reliance on Gemini (and AlphaProof on TPUs) limits independent replication; open-source equivalents, prompts, and execution traces sufficient for reproducibility are not provided.
- Proof interpretability and summarization are informal: natural-language summaries are produced but not validated for faithfulness or utility; aligning formal proof structure with trustworthy explanations is an open task.
- Generalization beyond 3000-episode cap is unexplored: the effect of larger budgets, curriculum over problems, or progressive library augmentation on long-horizon proofs is unknown.
- Integration with retrieval and citation infrastructure is missing: the agent does not leverage formal literature retrieval to ground claims or reuse known lemmas, which could reduce hallucinations and improve efficiency.
- Benchmark representativeness is uncertain: focusing on the Formal Conjectures subset and OEIS autoformalizations may introduce selection bias; broader, community-curated benchmarks with standardized verification are needed.
Practical Applications
Overview
Below we extract practical applications from the paper’s findings, methods, and innovations around AI-driven formal proof search (AlphaProof Nexus), and organize them into actionable use cases for industry, academia, policy, and daily life. Each item specifies sectors, potential tools/products/workflows, and assumptions/dependencies that may affect feasibility.
Immediate Applications
- Boldly reliable assistants for research mathematicians
- Sectors: academia; scientific publishing; research tooling
- Tools/products/workflows: a Lean-native “proof copilot” that iterates on EVOLVE-BLOCK/EVOLVE-VALUE regions; proof-attempt triage views that surface unresolved subgoals; automatic “misformalization linting” that flags ambiguous or incorrect formal statements; GitHub-style repositories of machine-checkable artifacts alongside papers
- Assumptions/dependencies: coverage of required areas in mathlib; access to capable LLMs and Lean infrastructure; expert validation for problem statement fidelity and for results outside library coverage
- OEIS and math knowledge-base curation with verification bots
- Sectors: academia; digital libraries; education
- Tools/products/workflows: an OEIS “formalization-and-test-lemma” gate that autoformalizes candidate conjectures, verifies initial terms, and attempts proofs/disproofs before acceptance; dashboards ranking sketches by Elo-style plausibility to prioritize human curation
- Assumptions/dependencies: robust autoformalization quality; curator oversight; stable APIs and governance alignment with OEIS and similar repositories
- Proof-guided algorithm design and parameter schedule search
- Sectors: software, ML/AI, operations research, optimization
- Tools/products/workflows: “proof-guided hyperparameter schedulers” for convex–concave min-max and related optimization; IDE plugins that expose EVOLVE-VALUE knobs and co-search proofs and schedules; CI checks that accept only parameterizations with certified convergence rates
- Assumptions/dependencies: problem classes must admit formal models amenable to Lean; initial focus on convex/structured settings; compute budget for search and verification
- Formal verification for safety-critical software and smart contracts
- Sectors: software, aerospace/automotive, medical devices, blockchain/fintech
- Tools/products/workflows: AlphaProof Nexus-style agents adapted to Coq/Isabelle/Dafny/F*/SMT ecosystems; CI/CD “verification gates” that block merges unless key invariants compile; on-chain verification helpers for smart contracts with machine-checked properties
- Assumptions/dependencies: high-quality formal specs; domain library maturity (protocol, concurrency, numeric); developer training; mapping Lean-centric patterns to target provers
- Graph analytics utilities grounded in proven properties
- Sectors: data platforms, network science, cybersecurity
- Tools/products/workflows: libraries implementing reconstruction or uniqueness guarantees for specific graph families; quality-control tooling for de-duplicating or repairing graph datasets by deck-consistency checks
- Assumptions/dependencies: translation of theoretical guarantees to practical graph regimes (noise, missingness); benchmark datasets and evaluation harnesses
- Quantum optics design assistants for state construction and no-go checks
- Sectors: quantum technologies, photonics
- Tools/products/workflows: “tensor-algebraic design” assistants that propose GHZ-style constructions or certify impossibility over chosen alphabets; lab workflows that bind formal feasibility certificates to experimental designs
- Assumptions/dependencies: accurate abstraction from experimental constraints to formal models; integration with optical simulation stacks; human-in-the-loop validation
- Education: compiler-checked tutoring and auto-grading
- Sectors: education (secondary, undergraduate, graduate)
- Tools/products/workflows: Lean-based courseware where students submit sketches and receive compiler feedback plus AI-suggested lemma decompositions; auto-grading using sorry-free proofs; formative feedback via rater subagents’ clarity/novelty rankings
- Assumptions/dependencies: curriculum alignment; student onboarding to proof assistants; classroom compute provisioning
- “Hallucination guards” for math-heavy LLM outputs
- Sectors: software tooling, knowledge work, journalism
- Tools/products/workflows: sidecar services that translate LLM-produced proofs/derivations into formal sketches and attempt compilation; red-flagging invented lemmas and unverifiable steps before publication or internal use
- Assumptions/dependencies: scope limited to domains with available formal libraries; latency and cost budgets for interactive use
- Publishing and funding workflows with machine-checkable artifacts
- Sectors: academic publishing; research funding agencies
- Tools/products/workflows: submission badges for Lean artifacts; reproducibility checks that recompile proofs; triage queues that sort submissions by proof status and rater-based plausibility
- Assumptions/dependencies: community and policy buy-in; infrastructure for artifact archiving and long-term maintenance
Long-Term Applications
- General AI co-mathematician for end-to-end discovery
- Sectors: academia; interdisciplinary science
- Tools/products/workflows: fully integrated autoformalization → conjecture → proof/disproof loops across broad math areas; agents that produce both formal proofs and human-readable summaries
- Assumptions/dependencies: major advances in autoformalization reliability; expanded libraries; better search/sample efficiency; governance on attribution and credit
- Proof-guided controller synthesis and safety certificates
- Sectors: robotics, autonomous vehicles, industrial automation
- Tools/products/workflows: synthesis of controllers with machine-checked stability/safety proofs; automatic discovery of barrier/lyapunov certificates; CI checks for mission profiles
- Assumptions/dependencies: expressive formal models for dynamics and uncertainty; computable certificates for realistic systems; integration with control stacks and simulators
- Energy and infrastructure optimization with certified guarantees
- Sectors: energy grids, logistics, telecom
- Tools/products/workflows: optimization modules whose scheduling and dispatch algorithms ship with formal performance or feasibility guarantees; robust power-flow solvers with certified convergence regions
- Assumptions/dependencies: accurate formal models of constraints and contingencies; scalable verification for large instances
- Enterprise-grade Verification-as-a-Service
- Sectors: finance, healthcare, aerospace, cloud services
- Tools/products/workflows: managed services that translate specs to formal models and return machine-checked proofs/counterexamples; auditor dashboards with proof lineage and Elo-like plausibility audits
- Assumptions/dependencies: standardization of specification languages; confidentiality-preserving workflows; talent and tooling for long-tail domains
- Cryptography and protocol-security co-design with proofs
- Sectors: cybersecurity, web3, secure systems
- Tools/products/workflows: agents that propose protocol variants and attempt game-based or UC-style security proofs in Coq/EasyCrypt/F*; automatic counterexample search for side conditions
- Assumptions/dependencies: deep domain libraries; efficient mechanization of asymptotic and probabilistic reasoning; community validation
- Formal knowledge graphs of mathematics for compositional reasoning
- Sectors: academia; AI for science
- Tools/products/workflows: a graph of formal theorems/lemmas across papers enabling agents to plan multi-paper proofs; search tools that locate reusable lemmas via semantic and formal matching
- Assumptions/dependencies: large-scale curation; deduplication across formalizations; licensing and interoperability across libraries
- Hybrid conjecture–proof ecosystems that self-update repositories
- Sectors: digital libraries (e.g., OEIS), publishing
- Tools/products/workflows: systems that autonomously conjecture, attempt proofs, and propose repository updates, with human review focused on edge cases; provenance trails linking data, conjectures, and proofs
- Assumptions/dependencies: governance for automated contributions; defenses against spurious or trivial conjectures; compute scheduling
- Scientific design assistants bridging symbolic proofs and experiments
- Sectors: materials, chemistry, physics, quantum tech
- Tools/products/workflows: agents that convert target properties into formal constraints, search for constructible designs with proofs of feasibility or no-go theorems, and export experimental parameters
- Assumptions/dependencies: faithful abstraction from physical constraints; uncertainty modeling and approximate reasoning with certified bounds
- Education at scale: proof-centered curricula and assessment
- Sectors: education policy, EdTech
- Tools/products/workflows: standardized, machine-checkable assessments; adaptive curricula that use agents’ rater feedback to personalize practice; teacher copilots for designing graded exercises with formal solutions
- Assumptions/dependencies: teacher training; equitable access; alignment with learning standards
- Policy and regulatory standards for machine-checkable claims
- Sectors: public policy, standards bodies
- Tools/products/workflows: procurement and safety regulations that accept or require machine-checked proofs for critical systems and algorithms; audit logs of proof attempts and residual sorrys
- Assumptions/dependencies: consensus on acceptable proof assistants; certification pathways; legal frameworks for responsibility and liability
- Verified ML training guarantees and safety properties
- Sectors: AI/ML, safety-critical AI
- Tools/products/workflows: proof-guided training pipelines for specific classes (e.g., convex, min-max, certified robustness modules) with convergence and safety certificates; “proof-enabled” hyperparameter tuning
- Assumptions/dependencies: tractable formal models for targeted ML regimes; methods for nonconvex settings; efficient approximate certificates where exact ones are infeasible
Notes on feasibility across applications
- Cost/variance: stochastic search yields variable costs; budgets must account for failed attempts on hard instances.
- Library coverage: success depends on mature formal libraries; domains with sparse libraries will need upfront investment.
- Human oversight: essential for guarding against misformalizations and aligning formal statements with original intent.
- Model access: results currently rely on frontier LLMs; open, cost-effective alternatives would broaden adoption.
- Security and governance: provenance, attribution, and responsible disclosure policies are needed as agents contribute to research corpora.
Glossary
- Abelian group: A group in which the operation is commutative; commonly arises in additive combinatorics and harmonic analysis. "The functions of interest map elements of an Abelian group to the complex numbers."
- Additive combinatorics: A branch of mathematics studying combinatorial properties of addition-related structures in groups and integers. "Additive Combinatorics."
- Algebraic geometry: The study of geometric properties of solutions to polynomial equations. "and is being deployed in combinatorics, optimization, graph theory, algebraic geometry, and quantum optics research."
- AlphaProof: A system for Lean theorem proving, leveraging reinforcement learning as a specialized proof tool. "The prover then decomposed that goal into three simpler lemmas, and called {AlphaProof} again"
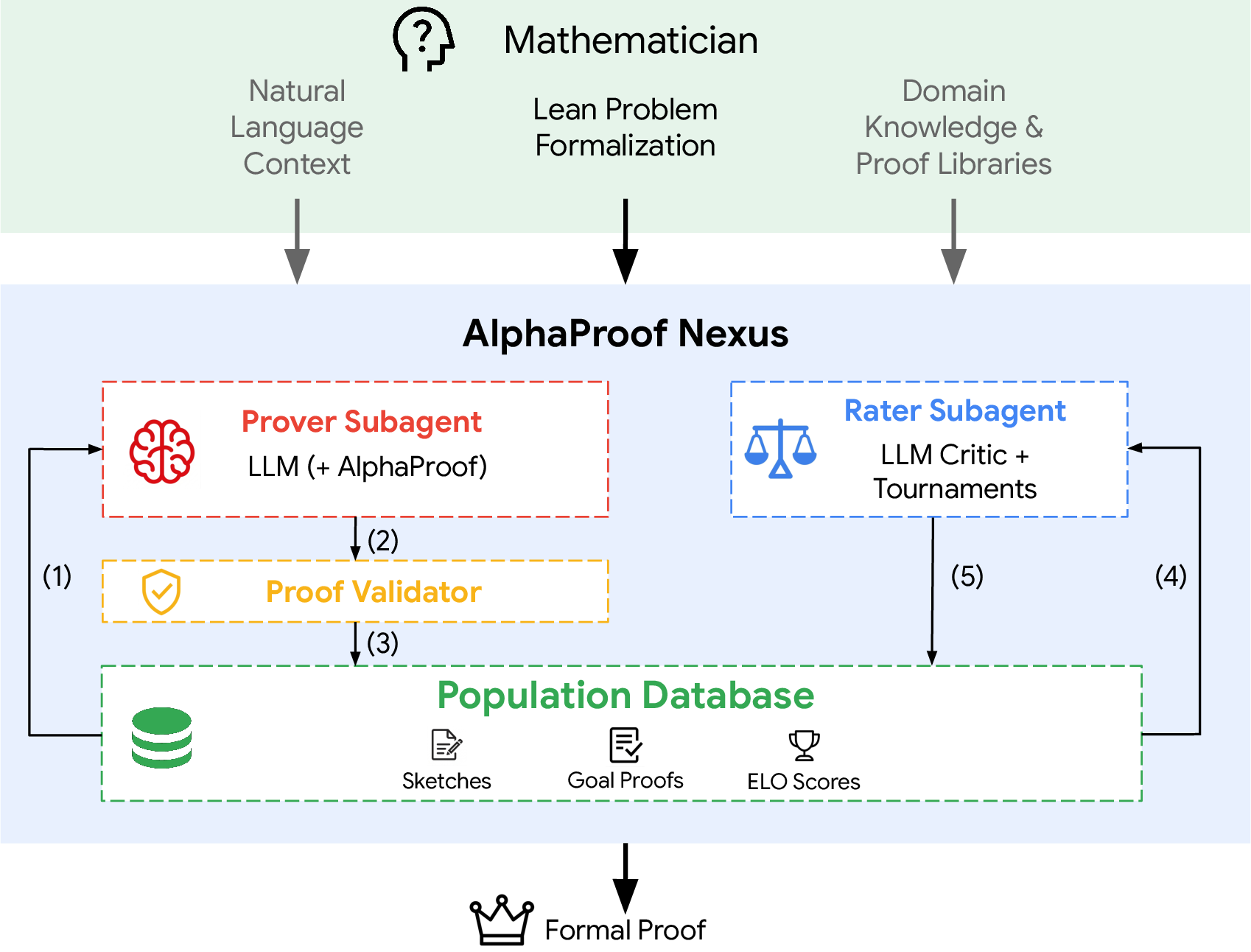
- AlphaProof Nexus: A framework for building agents that integrate LLMs with the Lean compiler to generate and verify formal proofs. "we developed a framework, {AlphaProof Nexus}, for LLM-aided proof generation"
- AlphaEvolve: An evolutionary coding/agent framework that inspires the paper’s evolutionary search component. "Separately, we developed an evolutionary agent (C), inspired by AlphaEvolve"
- Anchored Gradient Descent-Ascent (GDA): A min-max optimization algorithm with provable convergence properties under certain conditions. "Anchored Gradient Descent-Ascent (GDA) algorithm"
- arithmetic progression (3-AP): A sequence of numbers with constant difference; 3-AP means three-term arithmetic progression. "the properties of sets that avoid length-3 arithmetic progressions."
- autoformalize: Automatically translate informal mathematical statements into a formal language like Lean. "We used Gemini to autoformalize 492 open questions from the OEIS"
- basis of order 2 (additive number theory): A set whose pairwise sums cover all sufficiently large integers; order 2 means two-term sums. "Existence of a basis of order $2$"
- Chinese Remainder Theorem (CRT): A number-theoretic theorem enabling simultaneous congruences to be solved modulo coprime moduli. "the proof integrates the Chinese Remainder Theorem"
- chain-of-thought: A reasoning style where intermediate steps are produced explicitly by an LLM. "the subagent can reason via chain-of-thought"
- codimension: In algebraic geometry/commutative algebra, the difference between ambient dimension and the dimension of a subvariety/module. "the case of codimension $3$ and type $2$"
- convex-concave optimization (min-max): Problems where one variable appears convex and the other concave, often in saddle-point formulations. "for min-max convex-concave optimization"
- cyclic group : The group of integers modulo 3 under addition. "the cyclic group "
- deck (graph theory): The multiset of vertex-deleted subgraphs of a graph. "known as its deck."
- Diophantine proximity: Closeness of integers related to powers or rational approximations, used in number-theoretic arguments. "exploits the Diophantine proximity of the two multiplicatively independent bases"
- discrete-time recurrence: A proof/analysis technique using recurrences defined step-by-step in discrete time rather than continuous ODEs. "instead using a discrete-time recurrence-based approach."
- disproof (formal): A formal proof that a proposed statement/subgoal is false. "Queries to {AlphaProof} can return a proof, disproof (a proof that the submitted subgoal is false)"
- Elo rating: A comparative, game-like rating system used here to rank proof sketches by plausibility/quality. "We aggregated these rankings into Elo ratings for the sketches"
- {Erd} problems: A collection of open problems posed by Paul Erdős and collaborators. "Our full-featured agent autonomously solved 9 {Erd} problems out of 353 attempted"
- EVOLVE-BLOCK markers: Annotations delimiting code regions the agent is allowed to modify by adding lemmas/steps. "Within EVOLVE-BLOCK markers, the agent can introduce helper lemmas, definitions, and proof steps."
- EVOLVE-VALUE markers: Annotations around expressions/parameters whose values the agent may change. "EVOLVE-VALUE markers are used to enclose expressions (e.g., parameters) whose values the agent can change."
- formal proof search: Automated/agentic exploration to construct machine-verified proofs in a formal language. "These findings demonstrate the power of AI-aided formal proof search"
- formal verification: Mechanized checking that each proof step is valid with respect to a formal system. "Formal verification can serve as a filter for determining which proofs merit human review."
- GHZ states: Highly entangled multipartite quantum states (Greenberger–Horne–Zeilinger). "high-dimensional GreenbergerâHorneâZeilinger (GHZ) states"
- graph reconstruction conjecture: The conjecture that finite simple graphs with at least three vertices are determined by their deck. "The graph reconstruction conjecture ... It asserts that every finite simple graph with at least three vertices is determined, up to isomorphism, by the multiset of its vertex-deleted subgraphs, known as its deck."
- Greedy coloring: An algorithmic coloring method extended in a combinatorial proof technique. "Greedy coloring extension with monochromatic intersection lemma"
- Hilbert function: A function encoding graded dimension or growth of components in graded algebras/ideals. "reformulation of the Hilbert function"
- Hilbert space dimension: The dimensionality of the quantum state space for each subsystem. "local Hilbert space dimension "
- independent set (graph theory): A set of vertices with no edges between them. "independent sets in the neighborhood of "
- isomorphism (graph theory): A structure-preserving bijection between graphs. "determined, up to isomorphism"
- Lean (proof assistant): A programming-language-like theorem prover with a compiler that checks proofs. "Lean \cite{moura2021lean} is a proof assistant in which definitions, theorems, and proofs are all mechanically verified code."
- linear optics: Optical systems using linear devices (beam splitters, phase shifters), often for photonic quantum computation. "realizable via linear optics"
- log-concavity: A sequence/property where each term squared is at least the product of neighbors; important in combinatorics/algebra. "The agent's proof establishes log-concavity in this case"
- lower density: The liminf of the proportion of a set of integers up to N; a notion of asymptotic density. "the interpretation of 'density' in the original informal statements was amended to 'lower density'"
- misformalization: An incorrect or ambiguous formal translation of an intended informal statement. "identified several misformalizations in the literature"
- monochromatic intersection lemma: A combinatorial lemma about intersections in colorings, used in van der Waerden-type arguments. "Greedy coloring extension with monochromatic intersection lemma"
- monochromatic quantum graph: A graph with edges assigned a single color/value in a quantum-graph construction context. "the existence of monochromatic quantum graphs with vertices and colors"
- monomial Artinian level algebra: A finite-length graded algebra generated by monomials with a uniform socle degree (level). "monomial Artinian level algebras"
- multiplicatively independent bases: Integers a, b such that am ≠ bn for all positive integers m, n. "the two multiplicatively independent bases ()."
- natural density: The limit of |A∩[1,N]|/N if it exists; a standard density notion in number theory. "using density as 'natural density.'"
- OEIS (Online Encyclopedia of Integer Sequences): A database of integer sequences and their properties/conjectures. "open conjectures from the Online Encyclopedia of Integer Sequences (OEIS)"
- ordinary differential equations (ODE): Equations involving derivatives with respect to a single variable; used in continuous-time analyses. "continuous-time ordinary differential equations (ODE) analysis"
- Pareto frontier: The set of optimal trade-offs between two competing metrics (e.g., cost vs. performance). "each curve traces the costâperformance Pareto frontier"
- P-UCB formula: A bandit-style upper-confidence-bound sampling heuristic adapted for population-based search. "used a sampling procedure based on the P-UCB formula"
- population database (evolutionary search): A shared repository of candidate solutions/attempts maintained across agents in an evolutionary algorithm. "shared population database of sketches."
- proof sketch: A Lean file containing the theorem statement, context, and placeholders guiding the proof search. "we refer to such a file as a proof sketch."
- pure O-sequence: A Hilbert function sequence arising from monomial Artinian level algebras, with specific combinatorial shape constraints. "pure -sequences, equivalently the Hilbert functions of monomial Artinian level algebras"
- rater subagent: An agent that evaluates and ranks prior attempts/sketches to guide evolutionary search. "rater subagents sample previous attempts"
- reinforcement learning: A learning paradigm where agents learn via reward signals; used to train theorem-proving tools. "a system for olympiad-level Lean theorem-proving based on reinforcement learning"
- Sidon set: A set of integers where all pairwise sums are distinct; central in additive combinatorics. "Sidon sets "
- sorry tactic: A Lean tactic that closes goals without proof, used as a placeholder during development. "Lean includes a special tactic, which immediately closes pending goals while passing the type checker."
- spanning tree leaves: Vertices of degree 1 in a spanning tree; maximizing their number is a graph optimization problem. "a bound on the maximum number of leaves over all spanning trees of a graph "
- sumset: The set A+B = {a+b : a∈A, b∈B} in additive number theory. "Problem #125 concerns the sumset "
- test lemma: Auxiliary lemmas that verify initial terms/conditions before attempting a main conjecture. "the agent was required to prove 'test lemmas' verifying the first few terms"
- tactic (Lean): An elementary proof step or procedure used to construct proofs in tactic-style proof assistants. "Proofs are constructed via a sequence of applications of tactics, or elementary proof steps."
- tree-search mode: A search strategy exploring proof states as nodes in a tree, used standalone by a prover. "We evaluated {AlphaProof} in standalone tree-search mode"
- type checker: The component verifying that terms/proofs conform to types; ensures well-typedness. "while passing the type checker."
- type-safe code: Code guaranteed by the type system not to violate type constraints; in Lean, a proxy for correct proof structure. "the generation of type-safe code without tactics."
- upper density: The limsup version of asymptotic density for sets of integers. "and 'upper density' respectively"
- van der Waerden numbers: The minimal n guaranteeing monochromatic arithmetic progressions in any k-coloring of [1..n]. "Van der Waerden numbers satisfy "
- vertex-deleted subgraph: A subgraph obtained by removing one vertex; used in reconstruction problems. "the multiset of its vertex-deleted subgraphs, known as its deck."
Collections
Sign up for free to add this paper to one or more collections.