- The paper introduces a novel task of formal counterexample generation using LLMs paired with Lean 4 for automated proof validation.
- It employs symbolic mutation to synthesize 575K counterexample instances and uses a multi-reward strategy to enhance training efficiency.
- Empirical results demonstrate up to 49% pass@1 accuracy improvement and state-of-the-art performance on new benchmarks.
Introduction and Motivation
Mathematical reasoning for AI has seen significant advances in proof construction, driven by the capabilities of LLMs adapted to interact with formal systems such as Lean, Coq, and Isabelle. However, the capacity to discover formal counterexamples—critical for disproving statements, refining conjectures, and providing self-corrective mechanisms—remains underdeveloped. The paper "Learning to Disprove: Formal Counterexample Generation with LLMs" (2603.19514) addresses this gap by formalizing the task of generating counterexamples using LLMs, with automated Lean 4 verification closing the training and evaluation loop.
The core task is formal counterexample generation: for a given universally quantified unprovable statement, the LLM must propose a concrete instance (counterexample) and formally prove its adequacy via Lean 4. This problem requires informal reasoning (counterexample search) followed by formalization and proof construction, thus integrating the guess-and-check paradigm within a formal machine reasoning process.

Figure 1: Task of formal counterexample generation, requiring an informal search for candidates and a Lean 4 formal proof that is automatically checked.
This requirement for informal-to-formal reasoning is distinct from multi-stage proof strategies ("draft-sketch-prove") where informal and formal phases closely align. Here, the transfer from the informal search space to syntactically correct, formally verifiable objects introduces unique training and data requirements, especially given the scarcity of existential theorem data.
Approach: Symbolic Mutation and Multi-Reward Expert Iteration
Symbolic Mutation for Data Synthesis
The methodology introduces symbolic mutation of provable theorems as a mechanism for large-scale counterexample data generation. By strategically dropping necessary hypotheses from formal theorems expressed in universal form, one constructs invalid variants that necessarily admit counterexamples. The approach leverages formal programmatic inspection (via Lean tactics) to ensure hypotheses are genuinely necessary, yielding mutated problems that reliably require counterexamples.
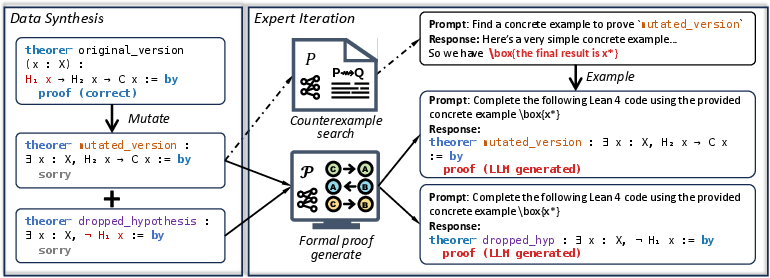
Figure 2: Framework of counterexample training combining symbolic mutation for data augmentation, followed by iterative expert feedback with multi-reward supervision.

Figure 3: Example instantiation of the framework on a concrete math competition problem, illustrating mutation and counterexample synthesis.
This process enables the synthesis of 575K counterexample instances from a diverse range of sources (Lean Mathlib, Leanworkbook, competition datasets), addressing the critical barrier of data scarcity for the counterexample problem class.
Multi-Reward Guided Expert Iteration
Conventional supervised or single-reward RL training for theorem proving is hampered by sparse rewards: most generated counterexamples are incorrect, yielding little positive feedback. To mitigate this, the framework proposes a structured multi-reward function exploiting problem decomposition. Each candidate counterexample is scored (and weighted during fine-tuning) based on:
- Its ability to formally prove the mutated theorem is false (i.e., a counterexample exists).
- Its ability to formally refute the dropped hypothesis specifically.
This double-reward structure promotes reward density and training efficiency, even when formal counterexample proofs are challenging, because proofs for dropped hypotheses are generally simpler and more attainable.
Empirical Results
Data Mutation Efficiency and Effectiveness
Empirical evaluation demonstrates the symbolic mutation approach sustains a high mutation ratio (1.65–2.48) with low computational cost, producing a 575K-scale dataset spanning elementary to undergraduate mathematics. The data quality is maintained by automatic Lean proof validation at each mutation stage.
Ablation studies reveal that models trained with the multi-reward strategy both converge faster and attain higher final performance than those using only single-reward signals. On a 3K validation set, the increase in pass@1 accuracy is 49% (multi-reward) versus 43% (single-reward). Pass@k improvements persist across k=4 and k=9.
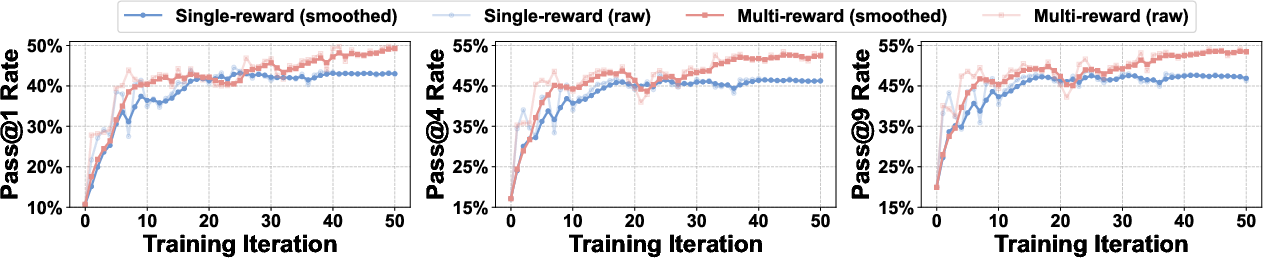
Figure 4: Multi-reward training delivers superior convergence speed and higher ultimate pass@k rates compared to single-reward baselines.
Benchmark Comparisons
Across three newly curated benchmarks—counterexample identification, verification of “auto-formalized” (potentially incorrect) formal statements, and verification of reasoning steps—the method achieves state-of-the-art results. In pass@1, the model solves 74%–56% more instances than the strongest open-source neural theorem prover baselines, and up to an order of magnitude more than large proprietary LLMs.
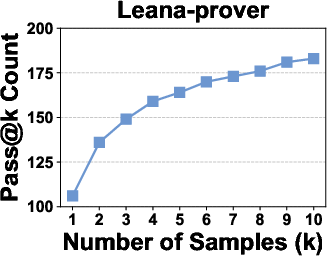
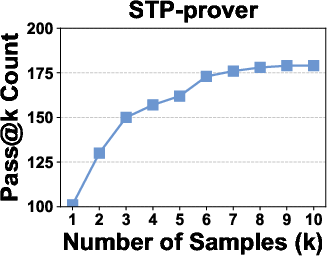
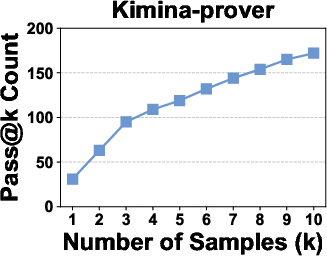
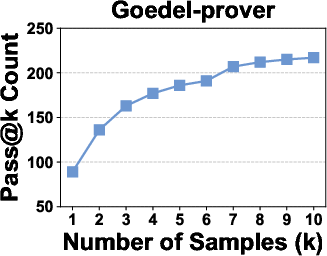
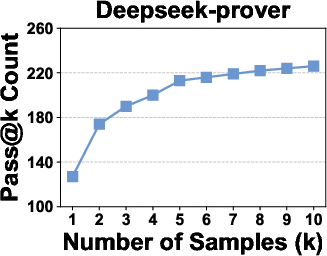
Figure 5: Pass@k curves of neural theorem provers on the For-Counter benchmark demonstrate that improvement saturates near k=10, confirming the sufficiency of k=1,4,9 for discriminative evaluation.
Implications and Future Directions
Practically, this framework delivers a scalable approach for self-disproving models, providing essential validation tools for automated formal mathematics and supporting error analysis in autoformalization pipelines. The multi-reward, mutation-driven methodology can be immediately adapted to other areas where existential counterexample synthesis is required (e.g., formal methods, program verification, self-testing for autonomous reasoning agents).
Theoretically, this work reinforces the significance of “self-reflective” and “self-corrective” LLMs—those able to not just prove, but also systematically search for failure modes within conjecture spaces. As the scale and sophistication of formal reasoning models increase, architectures that alternate between proof synthesis and counterexample generation are likely to dominate, opening avenues for automated conjecture refinement and interactive theorem exploration.
Limitations
Current limitations lie in potential synthetic data redundancy, which can reduce training efficiency; in the relatively small size and capability of the LLMs used for informal and formal reasoning; and in the generation of incorrect informal candidates that compromise subsequent proof generation. Addressing these will require higher-quality data selection, scaling model capacity, and expanding tool-use strategies (e.g., integrating external solvers).
Conclusion
This work formalizes and addresses the underexplored problem of formal counterexample generation for LLMs, proposing a framework that synthesizes large datasets via symbolic mutation and exploits multi-reward expert iteration to overcome sparse supervision. The demonstrated empirical gains in benchmark experiments establish a new baseline for self-disproving reasoning models, with implications for both theoretical AI research and practical applications in formal verification and mathematical discovery.

