TRON: Targeted Rule-Verifiable Online Environments for Visual Reasoning RL
Abstract: Reinforcement learning (RL) for visual reasoning needs scalable, verifiable, and controllable training signals. Existing visual RL post-training trains on static curated datasets, with fixed image-question-answer samples bounded by their collection budget. In this work, we introduce TRON (Targeted, Rule-verifiable Online eNvironments), an online environment substrate: a training rollout is generated on demand by a controllable generator-verifier program that samples a fresh latent visual state, renders an image, asks a question, and exactly verifies the answer. A single run can therefore draw an unbounded stream of fresh instances at the difficulty level required by the current curriculum. The current TRON suite contains 520 environments organized into five ability buckets (spatial, mathematical, diagram, pattern/logic, and counting); the same substrate supports both a single full model trained on all buckets and per-bucket ability-specialist models, with no additional data collection. We also introduce a substrate analysis covering generation reliability, instance and level diversity, cross-environment near-duplicates, and base-model pass rate by difficulty level. RL post-training with METHOD consistently improves performance on ten external multimodal reasoning benchmarks across Qwen3-VL-4B, Qwen2.5-VL-7B, and MiMo-VL-7B-SFT.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What this paper is about
This paper introduces TRON, a giant “practice world” for teaching AI to solve visual puzzles and reasoning problems. Instead of giving the AI a fixed workbook full of questions, TRON is like a video game that can generate endless new levels on demand, check the AI’s answers automatically, and adjust the difficulty as the AI improves.
The goal: help vision-LLMs (AIs that look at images and read text) learn real problem-solving skills—like counting, geometry, charts, spatial reasoning, and logic—through interactive practice with precise, automatic scoring.
Goals: What the researchers set out to do
The paper asks three simple questions:
- How can we give visual AIs unlimited, high-quality practice problems with reliable automatic grading?
- Can we control what skills the AI practices (spatial, math, charts, logic, counting) and steadily raise difficulty like levels in a game?
- Will training this way actually make different AI models better on real-world tests?
How TRON works, in everyday terms
Think of each TRON “environment” like a mini game focused on one skill. For example, one might be “find the third angle in a triangle,” another “read a bar chart and add two bars,” or “navigate a maze.”
Each environment has two parts:
- A generator: makes a new problem whenever asked (picks hidden settings, draws an image, and writes the question).
- A verifier: knows the exact correct answer (because it comes from the hidden settings) and instantly checks the AI’s response for a score.
This means there’s no guesswork or human grading. Every attempt gets a clear correct/incorrect reward, which is perfect for reinforcement learning (RL)—a training style where the AI tries, gets feedback, and improves.
To keep practice meaningful and not repetitive, TRON adds variety in three ways:
- Across environments: different skills (spatial, math, diagram/chart, pattern/logic, counting).
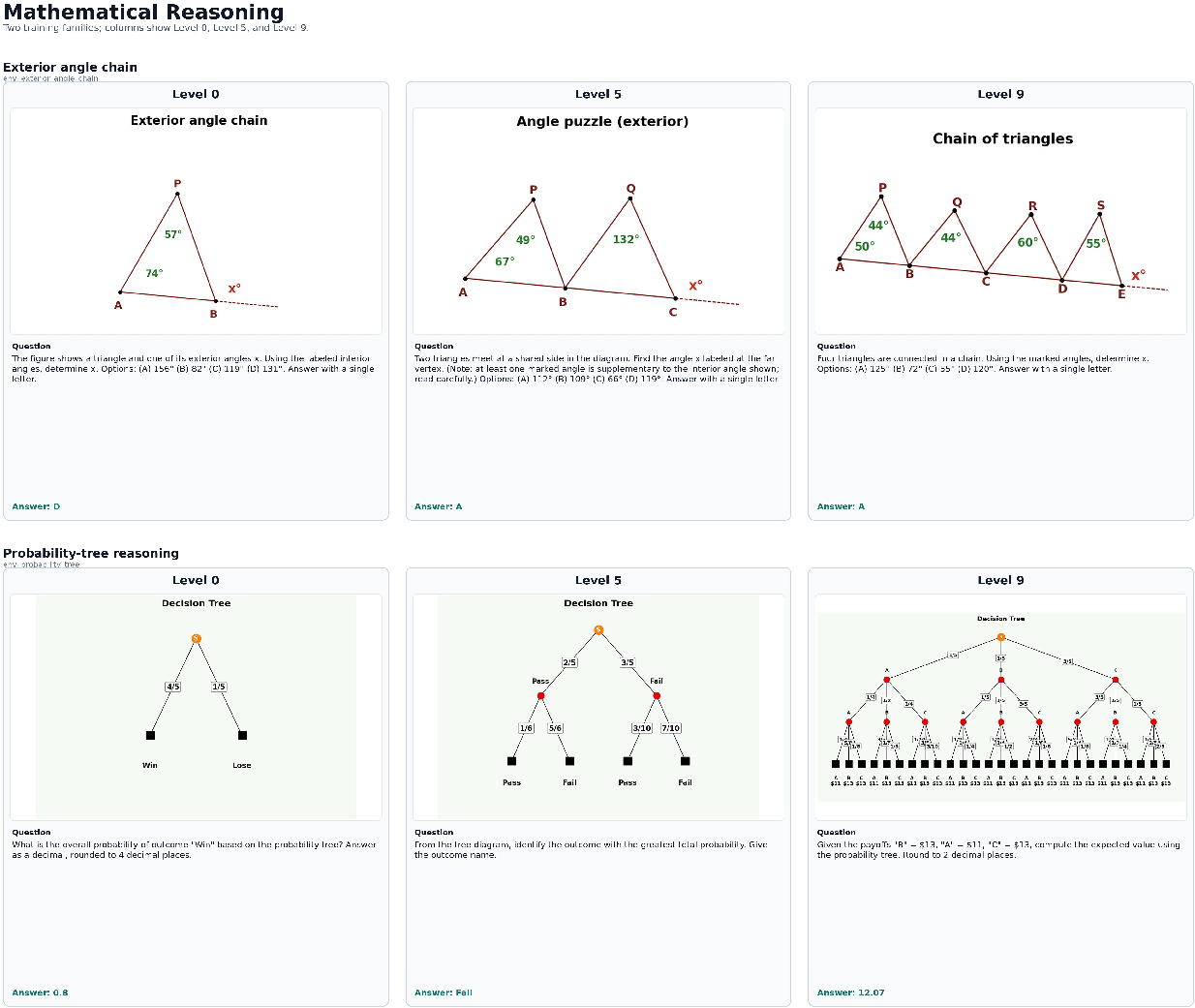
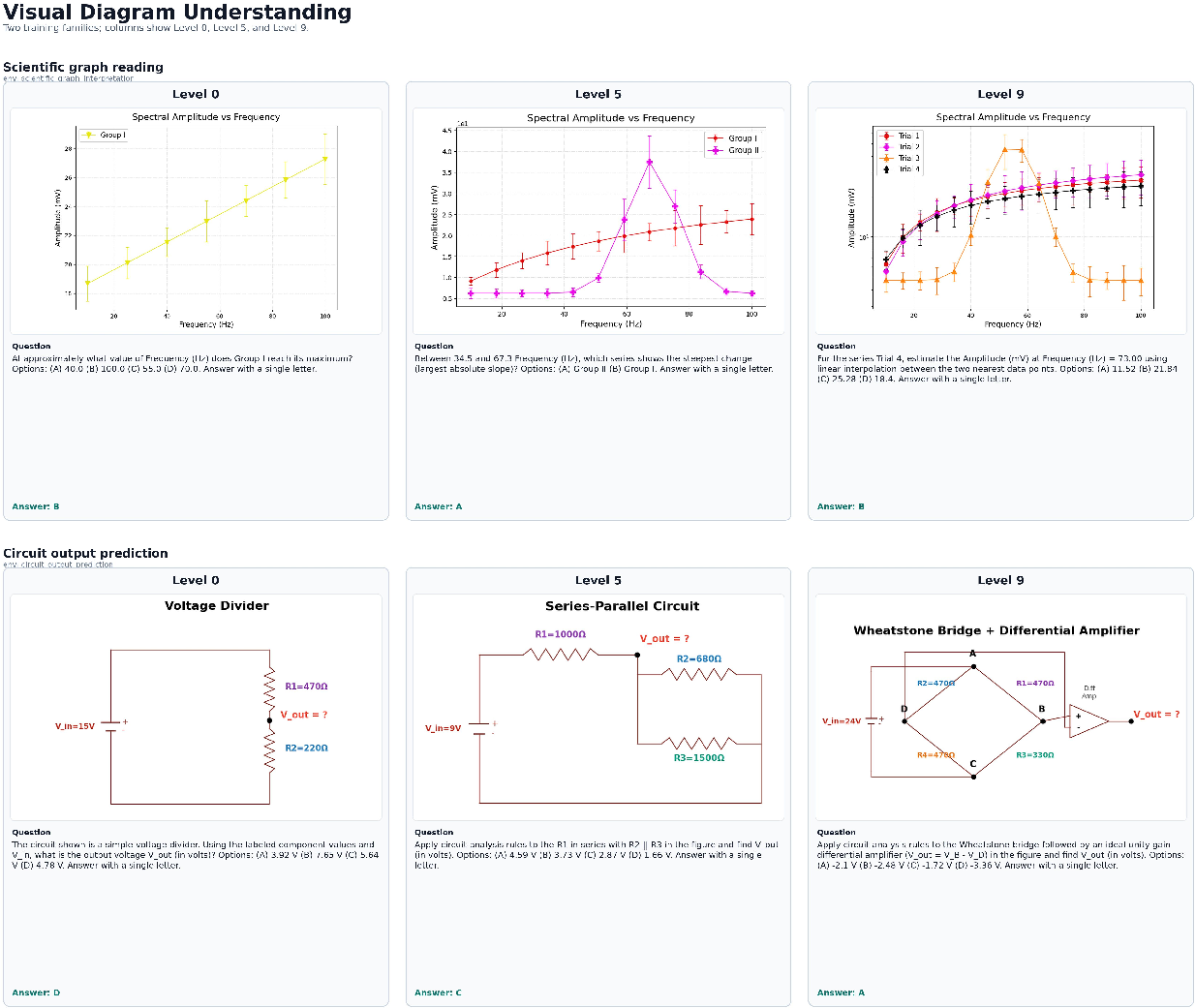
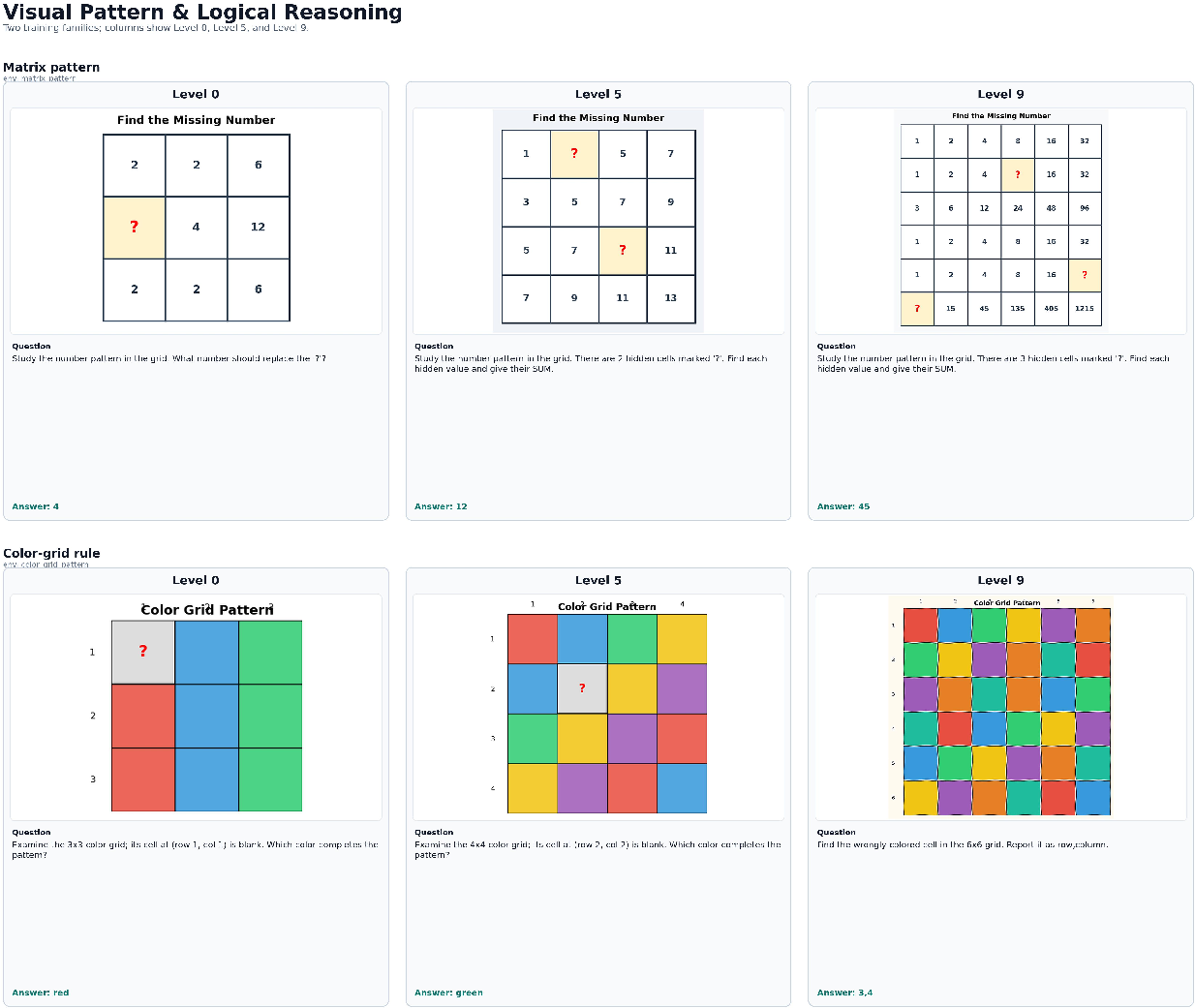
- Across levels: each environment has a difficulty ladder (levels 0–9), like going from simple triangle sums to multi-step geometry chains.
- Across seeds: each time you generate a problem, the details change (layout, numbers, colors, labels, distractors), so you don’t see the same thing twice.
Before training, the authors also “audit” the environments to ensure:
- Quality: problems render correctly and the grader works (no broken images or wrong answers).
- Diversity: different seeds and levels actually look and feel different.
- Real difficulty: higher levels are truly harder for a baseline model.
How the AI trains with TRON:
- The trainer picks an environment and level, generates fresh problems, and the model answers.
- The verifier gives exact rewards.
- A simple curriculum raises the level in that environment once the model is doing well, so the challenge keeps up with the model’s skill.
- They test two setups: one model trained on all 520 environments, and “ability specialists” trained on just one bucket (like only math or only spatial).
Main results: What they found and why it matters
What they built:
- 520 environments across five skill buckets: spatial, math, diagram/chart, pattern/logic, and counting.
- Each environment can generate unlimited fresh problems with exact, automatic grading and adjustable difficulty.
What they checked:
- Quality audit passed on about 99% of generated probes.
- Difficulty is real: a base model’s accuracy drops as level goes up.
- Good variety: instances and levels aren’t near-duplicates.
What improved:
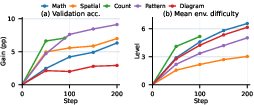
- They trained three different vision-LLMs with TRON and tested them on ten external benchmarks (covering math, spatial, charts, logic, and puzzles).
- All three models got better on average after TRON training—roughly +2 to +3 percentage points overall, with bigger jumps on some spatial and structured-reasoning tasks.
- “Ability specialist” models trained on one bucket improved tasks that matched that bucket (for example, spatial training boosted maze and position tasks). Surprisingly, skills also transferred across formats. For instance, math-focused training helped on maze-like tasks that need step-by-step reasoning, not just math.
Why this matters:
- Instead of being stuck with finite, static datasets, models can learn from endless, targeted practice with exact feedback.
- You can control what the model practices and steadily raise difficulty, which is much closer to how people learn skills.
- The gains show this method is practical and useful across different model families and test sets.
What this means going forward
- Stronger, more general visual reasoning: With a “practice world” that never runs out, models can continue to grow skills without memorizing small datasets.
- Better, fairer evaluation and training: Exact automatic grading reduces noise and makes RL training stable and scalable.
- Mix-and-match training: You can train one big model on everything or train specialists for particular abilities, then combine them or use them where they fit best.
Here are a few things to keep in mind:
- TRON’s visuals are synthetic (computer-made), so they may look different from photos or complex real-world images.
- Difficulty steps were designed by the authors and may feel uneven across some environments.
- Skill buckets overlap in real life (for example, chart questions may require counting and multi-step logic), so perfect separation isn’t possible.
Overall, TRON shows a practical way to teach visual AIs through endless, verifiable practice—like giving them a smart, self-grading workbook that adapts as they learn—and it already leads to consistent improvements on many outside tests.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of concrete gaps and open directions that remain unresolved and could guide future research.
- Real-image grounding: Assess how TRON-trained models transfer to natural, photographic, document, and scanned images (beyond rendered diagrams), e.g., DocVQA, ChartInfo-in-the-wild, PubTables-1M, and chart screenshots with cluttered backgrounds and imperfect OCR.
- Robustness to stronger perturbations: Quantify robustness under larger rotations, perspective warps, heavy compression, occlusions, cropping, partial visibility, and mixed lighting beyond the current small perturbation set; add adversarial and natural corruption suites (e.g., ImageNet-C-like for charts/diagrams).
- OCR and small-text reliability: Measure failure modes when answers depend on small text, axis ticks, legends, and dense labels; isolate perception bottlenecks vs reasoning by varying resolution, zoom, and OCR quality; add environments that stress text extraction systematically.
- Verification fragility and reward hacking: Audit verifiers against adversarial outputs (format spoofing, Unicode confusables, whitespace tricks, multi-answer payloads) and ambiguous cases (units, synonyms, rounding); introduce fuzzing/property-based tests and “red team” attacks for each verifier.
- Partial credit and graded rewards: Explore shaped rewards for near-correct outputs (e.g., numeric tolerances, set overlap, partial path correctness) to improve credit assignment versus today’s largely binary rewards.
- Step-level verifiability: Add environments with intermediate verifiable steps (program-of-thought or proof states) to test whether step-checked RL improves reasoning reliability and sample efficiency over answer-only rewards.
- Difficulty calibration at instance-level: Replace/augment author-set difficulty ladders with learned hardness models (e.g., adaptive item-response theory or adversarial sampling) and per-instance difficulty prediction validated on held-out models.
- Non-monotone difficulty: Detect and rectify environments whose level ladders are not strictly harder (local monotonicity checks, auto-tuning level parameters, or pruning sub-levels that fail to increase hardness).
- Semantic diversity measurement: Go beyond pHash/template metrics to measure mechanism-level diversity (e.g., program-structure similarity, solver-graph edit distance, reasoning-operator coverage) to avoid superficial visual diversity masking semantic redundancy.
- Cross-suite deduplication beyond visuals: Identify semantic near-duplicates across environments that differ in renderings but collapse to the same reasoning template; employ clustering on latent generator state graphs or solution programs.
- Capability coverage map: Provide a formal taxonomy/coverage report mapping each environment to atomic reasoning operators (counting, ordering, aggregation, geometric transform, path search, etc.) and quantify coverage gaps and co-occurrence patterns.
- Compositional reasoning tasks: Introduce environments that require composing multiple capabilities within an instance (e.g., chart parsing + counting + logical constraint), and evaluate deliberate transfer to multi-capability benchmark items.
- Multi-image/video/3D extensions: Extend TRON beyond single images to multi-image comparisons, temporal reasoning on short clips, and 3D point-cloud/mesh projections; study whether online RL benefits carry over.
- Interactive/agentic settings: Add interactive environments (zoom, crop, pan, query metadata) with multi-step action spaces and verifiable intermediate rewards to test planning and information-gathering policies.
- Negative transfer and trade-offs: Systematically measure regressions on unrelated tasks (captioning, general VQA, OCR-heavy tasks) after TRON RL; run ablations on bucket-only vs mixed training and quantify trade-offs.
- Scheduling and environment selection: Study automatic sampling curricula across 520 environments (bandit/teacher-student schedulers) for sample efficiency, forgetting avoidance, and compute allocation; report scaling laws with number of environments and training steps.
- RL objective ablations: Compare DAPO settings (clip ranges, group filtering, KL/entropy coefficients, n-replies) with GRPO/REINFORCE++ baselines; quantify stability, variance, and sample efficiency differences in the visual setting.
- Baseline parity with SFT: Benchmark TRON RL against strong SFT on equal-compute synthetic data from the same generators to isolate the unique contribution of verifiable RL vs supervised training.
- Verifier correctness guarantees: Provide independent cross-checkers or reference solvers for each environment and publish unit/property tests with coverage metrics; quantify residual verifier error rates and their impact on policy learning.
- Environment authoring scalability: Explore semi-automated authoring via program synthesis/LLM agents with verification harnesses; measure cost, reliability, and audit pass rates compared to hand-authored environments.
- Cross-lingual generalization: Generate multilingual questions/labels and verifiers (units, numerals, scripts), and evaluate transfer to non-English benchmarks and localized scientific figures.
- Domain expansion: Add scientifically rich modalities (circuits, chemical equations, mechanics diagrams, maps with projections), and evaluate transfer to domain-specific benchmarks (e.g., AI2 Diagram Understanding, CircuitQA).
- Wrapper dependence: Quantify how much improvement depends on the required output wrapper; measure robustness to free-form answers and alternative schemas; consider wrapper-agnostic evaluation at inference time.
- Hard-negative generation: Introduce targeted distractors and confounders (near-miss paths, symmetric configurations, visually similar chart series) with verifiable distinctions to combat shortcut learning.
- Data contamination checks: Measure overlap between TRON renderings/templates and pretraining corpora of evaluated backbones; release hash/signature sets to enable contamination auditing.
- Compute and throughput reporting: Provide detailed generation/training throughput, cost, and memory profiles; compare online generation overhead vs pre-generated pools and propose caching strategies without losing curriculum freshness.
- Reproducibility of evaluations: Release fixed, hidden-seed evaluation subsets for TRON environments to track progress without leakage; define standard validation protocols alongside the open-ended generators.
- Large-model scaling: Test whether gains persist or saturate on larger backbones (e.g., 14B–72B) and with higher-resolution vision modules; study interactions with mixture-of-experts and context-length scaling.
- Safety and fairness audits: Evaluate whether training on synthetic diagrams introduces biases (e.g., culturally specific symbols, color conventions) and whether improvements transfer equally across diverse visual styles.
Practical Applications
Immediate Applications
Below are practical, deployable use cases that directly leverage TRON’s online, rule-verifiable generator–verifier environments, difficulty ladders, and the demonstrated RL gains across multiple open VLMs.
- RL post-training substrate for VLMs — software/AI
- Use TRON as a drop-in training source to boost chart, spatial, logic, and geometric reasoning in existing VLMs using DAPO/GRPO-style objectives.
- Tools/workflows: TRON sampler + verifier library; prompt-grouped-advantage RL loop; online curriculum scheduler that promotes levels as pass rates rise; robustness perturbation harness.
- Assumptions/dependencies: access to base VLMs and GPU compute (4×H100 scale in paper); domain fit is best for synthetic/diagrammatic visuals; integration with vLLM/inference stack.
- Ability-specialist fine-tuning and routing — software/AI, enterprise AI
- Train per-bucket specialists (math, spatial, diagram, pattern, counting) and deploy a router that dispatches user queries to the best specialist; improves accuracy on mixed workloads.
- Tools/workflows: specialist trainers; router policy learned from validation signatures; ensemble evaluation harness.
- Assumptions/dependencies: modest engineering to add router; specialists shine when tasks map to underlying capabilities learned in TRON.
- Chart and dashboard Q&A copilot — finance, business analytics, productivity software
- Fine-tune chart-reading modules that answer quantitative and “what-if” questions about bar/line/stacked charts; embed in BI tools, spreadsheets, or reporting workflows.
- Tools/workflows: “Diagram” bucket fine-tune; format-normalized answerers; plug-ins for Excel/Sheets/BI.
- Assumptions/dependencies: visual style of production charts should be close to TRON’s or adapted via lightweight fine-tuning; exact verifiers for in-house charts improve reliability.
- Scientific-figure assistant for researchers — academia, publishing
- Build assistants that extract numbers, compare series, and answer multi-step questions about plots and schematic figures in papers.
- Tools/workflows: Diagram + Math specialists; figure-reading + compositional reasoning pipelines; PDF-to-figure preprocessing.
- Assumptions/dependencies: figure diversity (journals/styles) requires domain adaptation; legal access to PDFs.
- Adaptive visual reasoning tutor — education/edtech
- Generate endless geometry problems, spatial puzzles, and pattern tasks with verifiable answers and personalized difficulty; support instant grading and step-by-step hints.
- Tools/workflows: per-ability curriculum scheduler; generator–verifier grading; student-model telemetry to adjust levels.
- Assumptions/dependencies: alignment to curricula and accessibility guidelines; UI for diagram rendering on web/mobile.
- Skills assessment and hiring tests — HR/assessment, education
- Create proctored, non-repeating visual reasoning assessments (e.g., spatial navigation, chart interpretation) with exact grading and calibrated difficulty.
- Tools/workflows: test form constructors drawing from TRON environments; psychometric calibration using pass-rate curves.
- Assumptions/dependencies: fairness/audit requirements; secure proctoring to prevent item leakage.
- Synthetic data augmentation for VLM SFT — software/AI
- Stream fresh, diverse diagram/Q&A pairs to augment SFT corpora before RL, improving coverage of reasoning formats not well represented in web data.
- Tools/workflows: TRON data streamer + answer normalization; curriculum-aware sampling to avoid “too-easy” data.
- Assumptions/dependencies: care to prevent overfitting to synthetic styles; mixing ratios tuned to avoid distribution drift.
- Model auditing and QA dashboard — MLOps, model governance
- Use TRON’s audit metrics (quality Q(e), diversity D(e), pass-rate-by-level) to track data quality, avoid near-duplicate tasks, and verify curriculum progression for any generator.
- Tools/workflows: audit dashboard; pHash/thumbnail/templating checks; base-model probe suite.
- Assumptions/dependencies: threshold choices and weights reflect local goals; periodic re-audits as environments evolve.
- Robustness testing for diagram/OCR systems — software QA
- Apply TRON’s controlled perturbations (rotation, JPEG, brightness, blur, noise) to stress test chart/diagram pipelines with exact-answer scoring.
- Tools/workflows: perturbation harness with verifiable grading; regression dashboards separating accuracy vs. degradation profiles.
- Assumptions/dependencies: robustness results generalize best for synthetic-style diagrams; photographic domains need extra tests.
- Domain-extended procedural packs (flowcharts, SOPs, UI diagrams) — enterprise software, documentation tooling
- Author a small set of custom generator–verifier environments for internal diagrams (e.g., process flows, swimlanes) to enable targeted RL and evaluation.
- Tools/workflows: lightweight “TRON SDK” for environment authoring; verifier templates (set/sequence/graph checks); sampler configs for specialist training.
- Assumptions/dependencies: availability of exact checkers for domain tasks; subject-matter expert input to design difficulty ladders.
- Benchmarking and leaderboard support — academia/open-source
- Use TRON-trained baselines and per-ability specialists as reference points for new multimodal benchmarks; provide standardized, verifiable training/eval protocols.
- Tools/workflows: reproducible scripts; public checkpoints; evaluation kits with format-normalized parsers.
- Assumptions/dependencies: community adoption; license compatibility of base models.
Long-Term Applications
These concepts extend TRON’s principles to broader, higher-stakes, or more embodied settings and will likely require additional research, domain verifiers, or realism.
- Robotics visual reasoning curricula — robotics
- Train perception–reasoning stacks for navigation, path planning, and object spatial relations using procedural, verifiable tasks as pre-training before sim/real.
- Tools/workflows: bridge from 2D diagrammatic tasks to 3D simulated scenes; curriculum transfer; success verifiers for navigation graphs.
- Assumptions/dependencies: sim-to-real gap; need for photo-real visuals and sensor models; reward signal integration for continuous control.
- Clinical chart and diagram understanding — healthcare
- Assistants that interpret lab charts, flowsheets, medication timelines, and annotated schematics with precise, verifiable outputs (e.g., dose calculations).
- Tools/workflows: domain-specific environment packs (e.g., ICU trend charts) with medical verifiers; alignment with EHR standards.
- Assumptions/dependencies: strict privacy/security; clinical validation and regulation; domain shift from synthetic charts.
- Industrial schematics and P&ID/CAD reasoning — energy, manufacturing, utilities
- Automated reading of process and instrumentation diagrams, circuit schematics, and layout plans for QA, maintenance, and training.
- Tools/workflows: graph-extraction modules; verifiers based on rule checks (flow continuity, valve states); integration with CMMS.
- Assumptions/dependencies: access to labeled diagrams; robust symbol libraries; safety certification.
- Geospatial and logistics planning from maps — logistics, public sector
- Agentic planners that reason over maps/route diagrams for emergency routing, last-mile delivery, or urban planning tasks.
- Tools/workflows: map-specific environments with verifiable route metrics; multi-objective curriculum (time, cost, constraints).
- Assumptions/dependencies: high-fidelity geospatial data; dynamic constraints; human-in-the-loop review.
- AR/VR interactive tutoring with live diagrams — edtech, XR
- Overlay step-by-step visual reasoning on real or virtual whiteboards, adapting difficulty in real time.
- Tools/workflows: on-device distilled specialists; low-latency verifiers for user interactions.
- Assumptions/dependencies: efficient edge models; robust tracking of user drawings/gestures.
- Continual, always-fresh training for deployed copilots — software/AI
- Run “evergreen” curricula where production models periodically train on new procedural instances to hedge against stagnation and dataset contamination.
- Tools/workflows: scheduled RL fine-tunes; drift detectors linked to difficulty ladders; safety-guarded deployment pipeline.
- Assumptions/dependencies: guardrails against catastrophic forgetting; eval gates; cost control.
- Certification frameworks with verifiable capability suites — policy/regulation
- Standards bodies define certified visual reasoning batteries (generator–verifier based) for regulated industries (e.g., medical, automotive documentation).
- Tools/workflows: open test suites with auditable difficulty and diversity; pass/fail criteria linked to verifiers.
- Assumptions/dependencies: consensus on capability definitions; governance for updates/versioning.
- Personalized cognitive training apps — daily life/consumer
- Gamified apps that track and improve users’ spatial, pattern, and numeracy skills using adaptive, non-repeating puzzles with objective scoring.
- Tools/workflows: user modeling + curriculum; progress analytics; accessibility variants.
- Assumptions/dependencies: evidence of real-world transfer; privacy-by-design.
- Program induction from diagrams (autoformalization) — software engineering, scientific computing
- Systems that infer executable specifications (e.g., graph algorithms, flowcharts) from visual artifacts, enabling automated testing or code generation.
- Tools/workflows: diagram-to-IR pipelines; verifier-backed unit tests; synthesis engines.
- Assumptions/dependencies: robust symbol/structure extraction; standardized notations across documents.
- Edge-model distillation for document intelligence — mobile/embedded
- Use TRON-based RL to train strong teachers, then distill into compact models for on-device chart/diagram understanding (e.g., scanning receipts, forms, lab plots).
- Tools/workflows: teacher–student distillation with verifier-labeled data; quantization; on-device evaluation harness.
- Assumptions/dependencies: latency/energy budgets; privacy constraints; acceptable accuracy trade-offs.
- Multimodal governance dashboards for enterprises — governance, risk, compliance
- Track model capability shifts and data health using TRON-like audits (diversity, difficulty monotonicity, near-duplicates) as part of internal AI governance.
- Tools/workflows: continuous audit pipelines; red-team generators for edge cases; incident response triggers.
- Assumptions/dependencies: organizational processes for model risk; integration with MLOps stacks.
Notes on feasibility across applications:
- Synthetic-to-real gap: TRON’s visuals are synthetic/diagrammatic; photographic or highly stylized domains need additional domain adaptation and new verifiers.
- Verifier availability: high-stakes domains require exact, domain-validated verifiers; building them can be the critical path.
- Compute and tooling: RL post-training benefits from multi-GPU setups and mature inference/training stacks (e.g., vLLM); smaller setups may prefer distillation or partial fine-tunes.
- Capability vs. visual format: the strongest transfer arises when the underlying capability demanded by the target task matches what was practiced; visual format alignment alone is insufficient.
Glossary
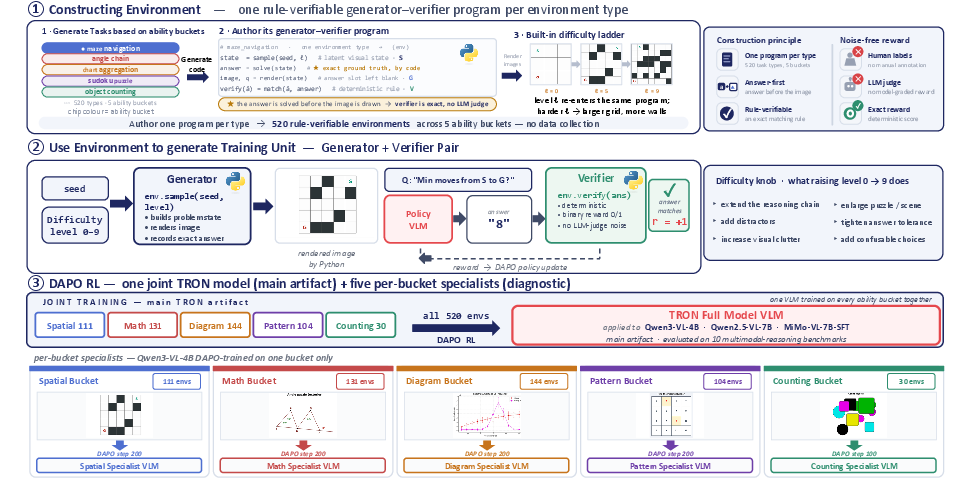
- Ability buckets: Thematic groupings of environments by core visual reasoning capabilities (e.g., spatial, math, diagram, pattern/logic, counting). "TRON organizes 520 rule-verifiable generators into ability buckets covering spatial, mathematical, diagram, pattern, and counting skills."
- Ability-specialist models: Models trained only on a specific ability bucket to specialize in that capability. "the same substrate supports both a single full model trained on all buckets and per-bucket ability-specialist models, with no additional data collection."
- Audit: A systematic check of environment quality, diversity, and difficulty alignment before training. "TRON therefore couples controllable generation with a substrate audit that checks rendering and verifier correctness, measures diversity across instances and difficulty levels, detects near-duplicate environments, and verifies that higher difficulty levels correspond to genuinely harder tasks"
- Chart aggregation: Operations that require reading and combining values across chart elements to compute answers. "For operations such as chart aggregation, cube rotation, occluded counting, visual analogy, or graph search, we instantiate task environments centered on those operations."
- Clip-higher: An asymmetric clipping strategy in DAPO that uses a higher clip bound to encourage exploration on negative samples. "We use DAPO clip-higher (low/high clip ratio $0.2/0.28$) for exploration on negative samples"
- Curriculum: A training schedule that modulates difficulty over time to match model ability. "at the difficulty level required by the current curriculum."
- Curriculum accumulator: Per-environment tracking of recent performance that governs level promotion and sampling. "uninformative rollouts still contribute their signal to the per-environment curriculum accumulator."
- DAPO: A policy-optimization objective used for RL post-training of language and vision-LLMs. "We optimize with a DAPO-style objective"
- Deterministic verifier: A rule-based checker that provides exact, non-stochastic rewards for a predicted answer. "the environment's deterministic verifier scores each response"
- Difficulty ladder: A structured progression of harder instances within an environment. "each environment has a difficulty ladder that produces progressively harder versions of the same operation."
- Difficulty parameter : A per-sample control input that selects the instance difficulty for curriculum learning. "The difficulty parameter is a curriculum-controlled input set per sample rather than a set-and-forget artifact."
- Entropy coefficient: The weight on the policy entropy term in the RL objective that controls exploration. "and the entropy coefficient is set to $0$."
- Generator--verifier program: A paired component where the generator creates instances and the verifier checks answers for reward. "a training rollout is generated on demand by a controllable generator--verifier program"
- GRPO: A reinforcement-learning variant that organizes advantages within prompt groups to stabilize optimization. "variants such as GRPO and DAPO refining the optimization"
- Group filtering: Dropping prompt groups that are uniformly correct or incorrect to focus updates on informative samples. "and group filtering to drop prompt groups that are all-correct or all-wrong from the policy update"
- Jaccard distance: A set-based dissimilarity metric used to measure template diversity across levels. "Level diversity aggregates cross-level pHash distance, template-Jaccard distance, and foreground-complexity shift over adjacent audited pairs"
- KL regularization: A Kullback–Leibler penalty that constrains the policy to stay close to a reference distribution. "KL regularization uses a low-variance estimator with coefficient $0.005$ and is not added to the reward"
- Latent visual state: The unrendered internal state that defines the instance from which the image and answer are generated. "samples a fresh latent visual state, renders an image, asks a question, and exactly verifies the answer."
- Near-duplicate predicate: A detector that flags environments whose outputs are effectively the same despite different names. "and a cross-environment near-duplicate predicate."
- Perceptual hash (pHash): A visual fingerprinting method used to quantify image-level diversity and similarity. "Seed diversity aggregates same-level perceptual-hash (pHash) spread"
- Procedural environments: Programmatically generated task settings that produce fresh instances on demand. "visual reasoning RL should train on a diverse suite of procedural environments rather than on a fixed collection of static VQA examples."
- Prompt-grouped advantages: Advantage estimates computed across multiple responses to the same prompt to stabilize training. "with a DAPO-style objective and prompt-grouped advantages in the spirit of GRPO"
- Reinforcement learning with verifiable rewards (RLVR): RL where rewards come from exact, rule-based verification instead of heuristic judges. "Reinforcement learning with verifiable rewards (RLVR) has become a central recipe for improving language-model reasoning"
- Rollout: A sampled interaction consisting of problem presentation and model responses used to compute RL updates. "a training rollout is generated on demand by a controllable generator--verifier program"
- Tensor parallelism: A model-parallel technique splitting tensors across devices to scale inference/training. "with vLLM tensor parallelism $4$"
- TRON: Targeted, Rule-verifiable Online eNvironments; the proposed suite of live generator–verifier environments for visual reasoning RL. "We propose TRON (Targeted, Rule-verifiable Online eNvironments), an online visual reasoning substrate"
- Verifier sanity: A quality check ensuring that correct answers are accepted and fixed wrong answers are rejected. "and verifier sanity (fraction of where the wrapped correct answer is accepted and a fixed wrong payload is rejected)"
- Vision-LLMs (VLMs): Models that jointly process images and text for multimodal reasoning and understanding. "newer VLMs absorb many popular reasoning datasets during pretraining and supervised fine-tuning"
- vLLM: A high-throughput inference/training engine used to serve and parallelize large models. "with vLLM tensor parallelism $4$"
Collections
Sign up for free to add this paper to one or more collections.