Vero: An Open RL Recipe for General Visual Reasoning
Abstract: What does it take to build a visual reasoner that works across charts, science, spatial understanding, and open-ended tasks? The strongest vision-LLMs (VLMs) show such broad visual reasoning is within reach, but the recipe behind them remains unclear, locked behind proprietary reinforcement learning (RL) pipelines with non-public data. We introduce Vero, a family of fully open VLMs that matches or exceeds existing open-weight models across diverse visual reasoning tasks. We scale RL data and rewards across six broad task categories, constructing Vero-600K, a 600K-sample dataset from 59 datasets, and designing task-routed rewards that handle heterogeneous answer formats. Vero achieves state-of-the-art performance, improving over four base models by 3.7-5.5 points on average across VeroEval, our suite of 30 challenging benchmarks. Starting from Qwen3-VL-8B-Instruct, Vero outperforms Qwen3-VL-8B-Thinking on 23 of 30 benchmarks without additional proprietary thinking data. When trained from the same base model, Vero-600K exceeds existing RL datasets across task categories. Systematic ablations reveal that different task categories elicit qualitatively distinct reasoning patterns that transfer poorly in isolation, suggesting that broad data coverage is the primary driver of strong RL scaling. All data, code, and models are released.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching AI systems to “look and think” at the same time. These systems, called vision-LLMs (VLMs), can look at images and answer questions in words. The authors want one model that can handle many different kinds of picture-based problems—like reading charts, understanding science diagrams, finding and counting objects, following instructions, and even planning actions on a screen—without relying on secret data or hidden training tricks.
They introduce verocolor: a fully open recipe (data, code, and models) for training strong, general-purpose visual reasoners using reinforcement learning (RL). They show that with the right mix of diverse, high-quality training data and well-designed “reward rules,” you can reach or beat the best open models across lots of tasks.
Goals and Questions
The paper focuses on a simple set of questions:
- How can we train a model that understands many kinds of images and problems, not just one niche?
- What kind of training data and “grading rules” (rewards) does a model need to learn broad visual reasoning skills?
- Do skills learned in one area (like counting objects) carry over to others (like reading charts), or do we need a wide variety of practice?
- Can an open, transparent training process match the performance of models trained with secret methods?
How They Trained the Model (Methods)
To make this accessible, think of the model as a student, the training data as homework, and reinforcement learning (RL) as a “learn by trial-and-error with points” system.
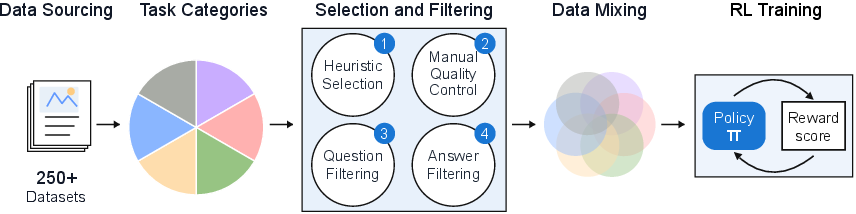
Building a big, mixed homework set
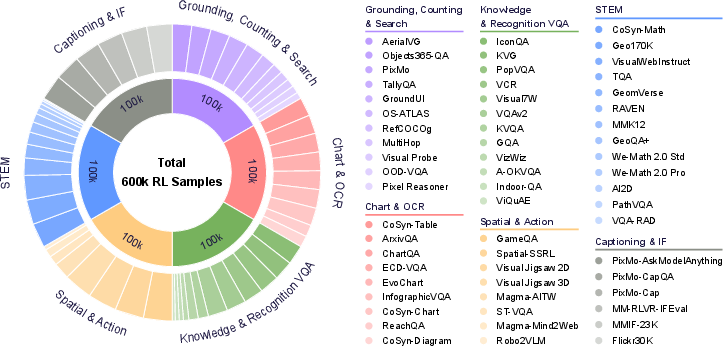
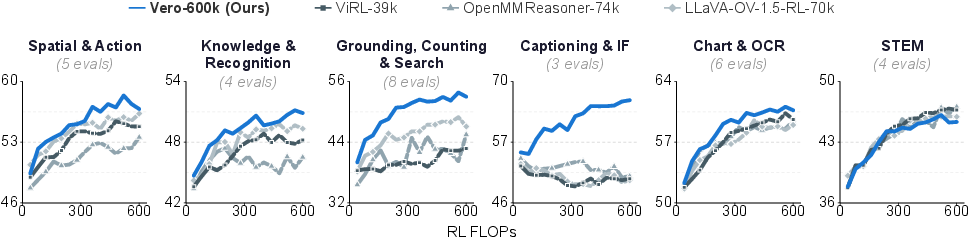
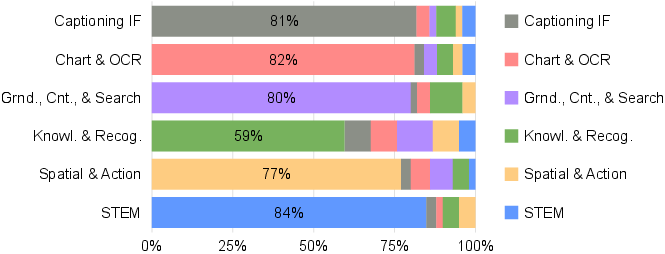
The authors created Vero-600k, a large training set of 600,000 examples collected from 59 public datasets. They organized the “homework” into six categories, each representing a different kind of visual reasoning:
- Charts and documents (reading text in charts, tables, infographics)
- STEM (math and science diagrams, medical/science figures)
- Spatial and action (understanding space, navigation, and step-by-step actions in interfaces or 3D scenes)
- Knowledge and recognition (naming objects and using facts or common sense)
- Grounding, counting, and search (finding things at specific locations, counting items, searching among distractors)
- Captioning and instruction following (describing images and following format rules)
They carefully filtered out bad or confusing questions, standardized answer formats (like ensuring numbers use the same style), and kept an even balance so each category contributed equally. This is like making sure a student gets equal practice in math, reading, science, etc., and removing poorly written questions from the homework.
Teaching with “rewards” (RL) using different rubrics
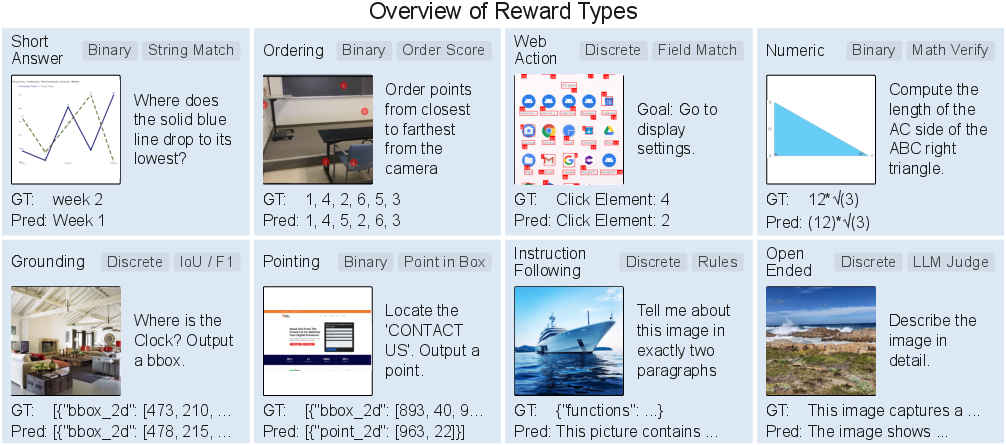
Reinforcement learning gives the model a score (reward) for each answer it tries, so it can learn what works. The paper uses “task-routed rewards,” which means:
- Different tasks are graded with different rubrics. For example:
- Exact text matches for simple answers
- Tolerance-based checks for numbers (so “3.14” ≈ “3.1416” if close enough)
- Box-overlap scores for object locating
- Click-in-box checks for UI actions
- Rule-checks for instruction following (e.g., keep answers under a certain length or in a specific format)
- An AI judge for open-ended responses when there isn’t a single “right” answer
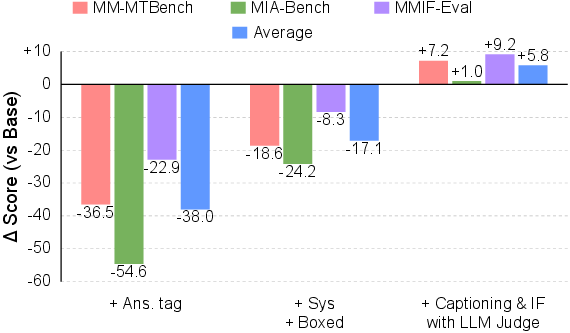
- The model is also rewarded for following a clean response format: think steps first, answer second.
Think of this like grading math, writing, and lab reports differently, because each subject needs its own fair grading rules.
Keeping the mix balanced
They tested different ways to schedule practice across categories (like “more time on harder subjects” or “more time where the images are bigger”). Surprisingly, just giving equal time to each category worked best overall.
Testing on many tough quizzes
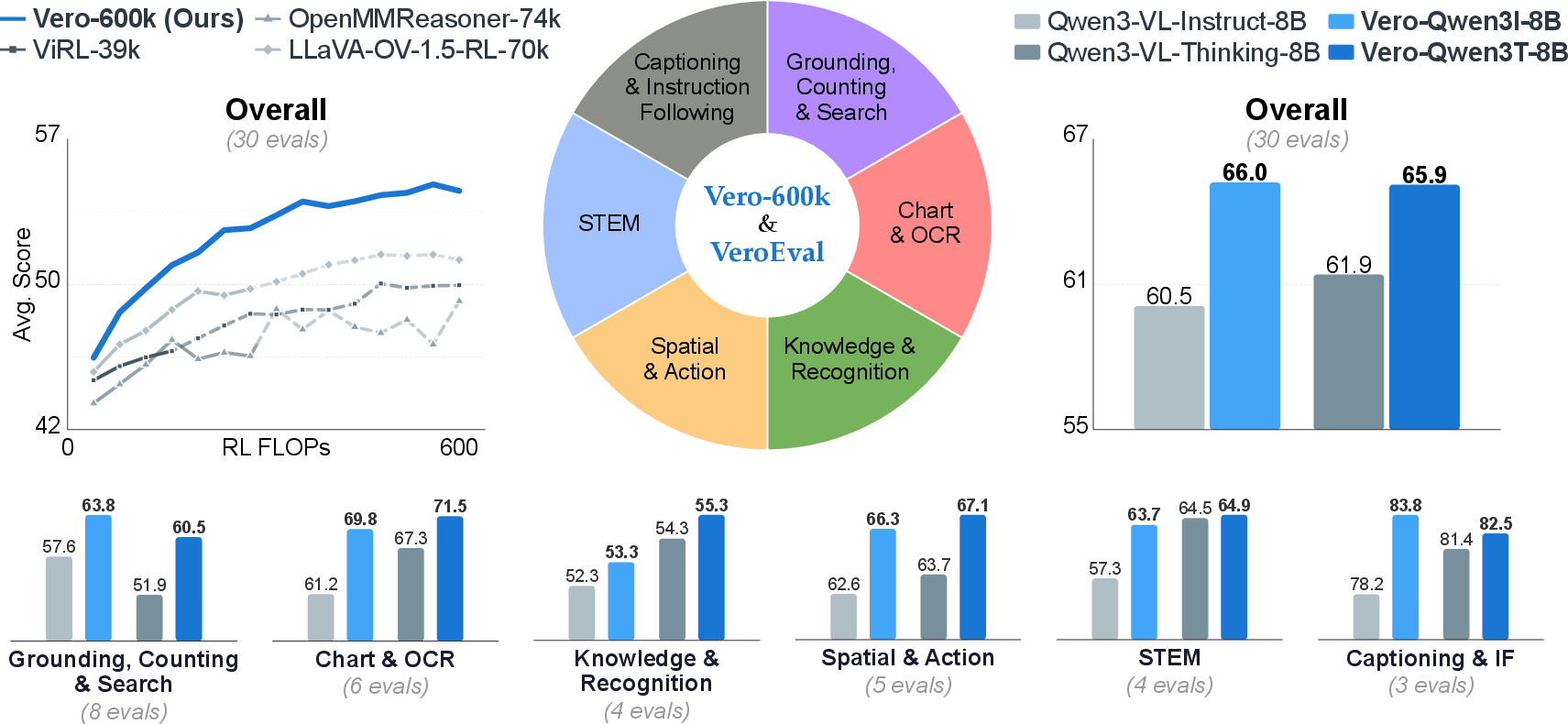
They built an evaluation suite of 30 benchmarks (tests), spanning all six categories. These benchmarks are chosen to be high-quality, varied, and challenging, so the results reflect real, broad ability—not just a couple of easy tasks.
What They Found
Here are the main takeaways, stated simply:
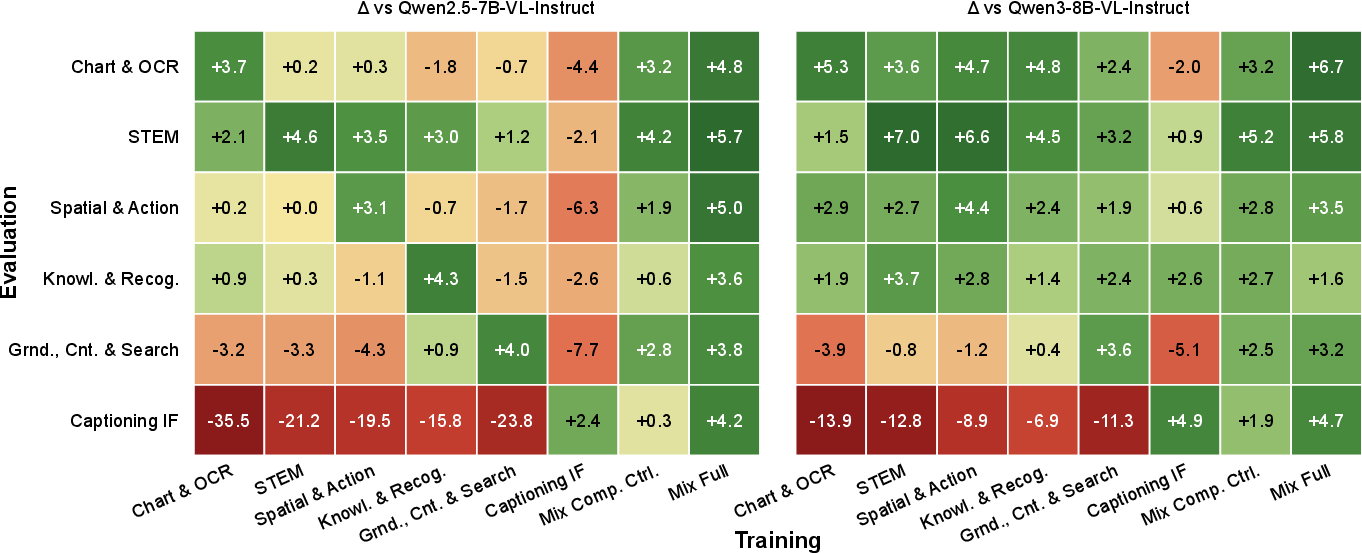
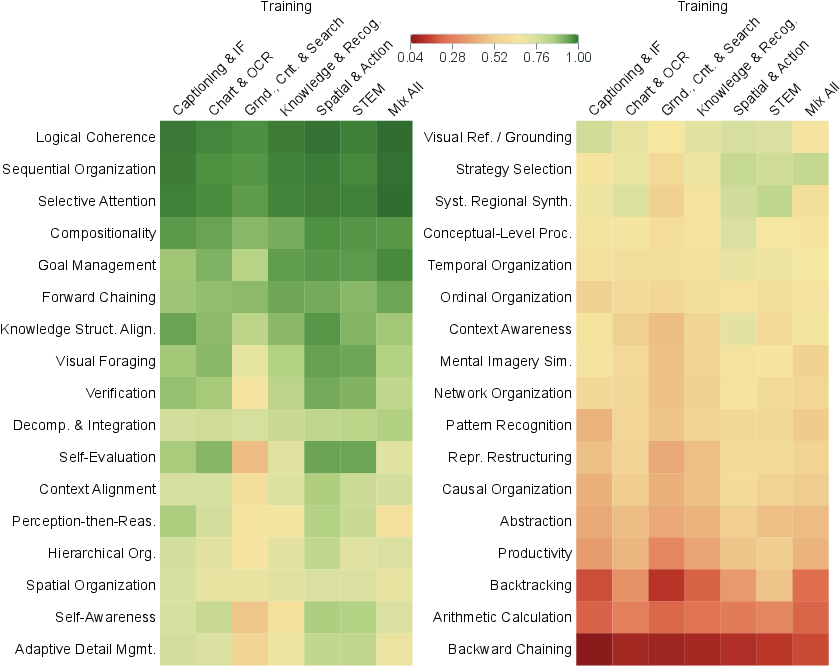
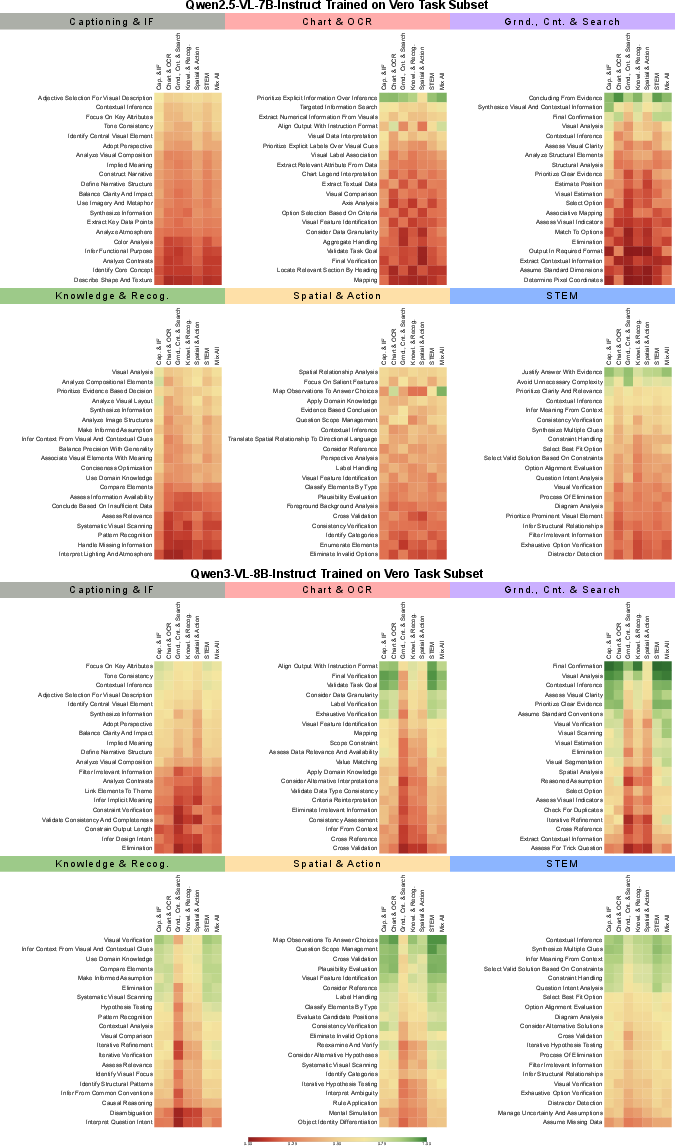
- Training with diverse data matters most. Practicing only one type of skill (say, STEM diagrams) did not transfer well to others (like locating objects). Different categories teach different “thinking styles,” so you need broad coverage.
- Equal balance across categories wins. Scheduling tricks (like focusing on harder tasks) helped some areas but hurt others. Equal mix gave the best overall performance.
- Smart, task-specific rewards are crucial. Using the right grading rules for each task type produced better learning than one-size-fits-all rewards.
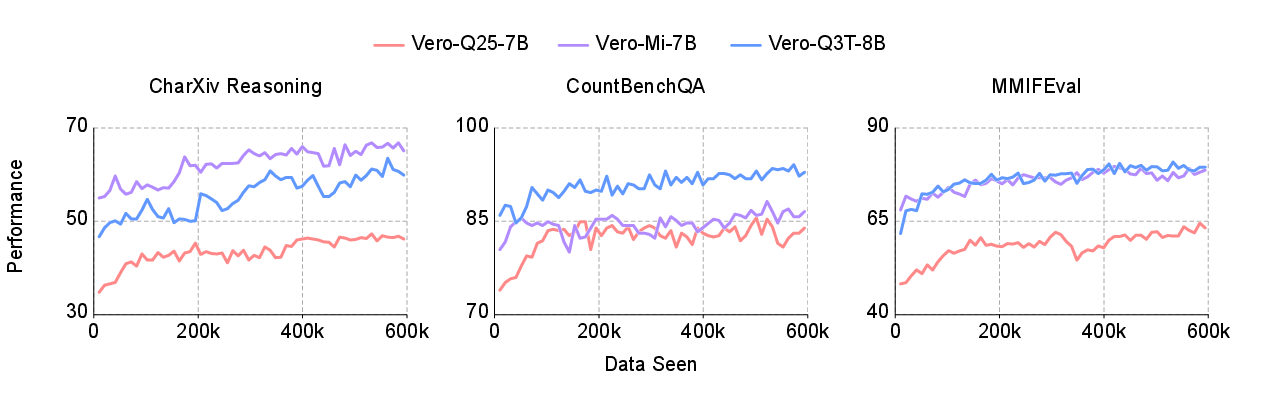
- Open RL works—and can beat “thinking” models without secret data. Starting from a popular open model (like Qwen3-VL-8B-Instruct), their verocolor models improved average scores by about 3.7–5.5 points across 30 benchmarks and beat Qwen3-VL-8B-Thinking on 23 out of 30 benchmarks without any extra proprietary “thinking” data.
- Compared to other open RL datasets, Vero-600k did better across categories. The broad, well-filtered data plus task-routed rewards consistently outperformed narrower collections focused on a single domain.
- Open-ended tasks are needed too. If you only train on “short-answer” tasks, the model’s general chatting and instruction-following skills can fade. Mixing in open tasks preserves those abilities.
Why this is important: It shows the community can train strong, general visual reasoners without hidden pipelines. The key is high-quality, diverse practice and fair, task-specific grading—ideas anyone can reuse.
Why It Matters
- For students and teachers: It’s like learning across subjects—variety builds well-rounded skills. AI models benefit from the same kind of balanced, diverse practice.
- For developers and researchers: The paper provides a clear, open recipe—with data, code, models, and ablations—to build VLMs that handle many real-world tasks. This helps others reproduce, test, and improve the approach.
- For real-world use: Better general visual reasoning means more reliable AI assistants for reading charts, navigating interfaces, checking documents, analyzing scientific figures, and following instructions—without needing secret training data.
In short, this work shows that smart data design and fair, task-specific rewards—applied evenly across different skills—are the secret ingredients to training broadly capable visual reasoning models in the open.
Knowledge Gaps
Unresolved gaps, limitations, and open questions
Below is a concise list of concrete knowledge gaps and limitations that remain open based on the paper; each item is phrased to enable actionable follow-up work.
- Data contamination risk: No explicit cross-dataset deduplication or leakage analysis between the 59 training datasets and the 30 evaluation benchmarks; unclear how much overlap or near-duplicate content might inflate reported gains.
- Reproducibility of filtering pipeline: Question and answer filtering critically rely on large Qwen3-235B variants; availability, reproducibility, and sensitivity to the specific scorer model (and prompts) are not assessed.
- English-only scope: Non-English content is explicitly filtered out; multilingual generalization and training/evaluation for non-English visual reasoning remain unexplored.
- Video and temporal reasoning: The recipe targets images (or sets of images) but does not address video or temporal tasks; scalability of the RL recipe and reward routing to temporal reasoning is unknown.
- Long-document and multi-page understanding: While “Chart/OCR” is included, handling of multi-page documents, long-context layouts, and page-level memory constraints is not evaluated.
- Evaluation breadth and coverage: The 30-benchmark suite may not cover key real-world tasks such as form understanding, receipt parsing, dense table structure extraction, medical report grounding, and UI agent benchmarks with dynamic states.
- Safety, bias, and harm: No analysis of demographic or content biases, safety failures, privacy leakage, or robustness to suggestive/unsafe prompts induced or amplified by RL.
- Robustness and OOD generalization: No tests for robustness to image perturbations, camera/viewpoint shifts, OCR noise, adversarial prompts, or domain shifts across visual styles.
- Reward model reliability: The LLM-as-judge component (Qwen3-32B) is not calibrated against humans; inter-rater reliability, bias, temporal drift, and reward hacking susceptibility are unreported.
- Reward coverage gaps: Current rewards do not cover program synthesis, LaTeX derivations, tool-augmented reasoning, multi-turn action plans, or multi-image cross-referencing with explicit constraints.
- Grounding metric fidelity: A single IoU threshold (0.5) and Hungarian matching may under-reward fine-grained localization; sensitivity to threshold choice and crowded scenes is not analyzed.
- Action tasks realism: “Web action/Clicking” rewards are matched to static labels; generalization to live, dynamic, or stochastic environments and real interaction loops is untested.
- Instruction-following reward gaming: Rule-based constraints can be satisfied without semantic correctness; lack of human evaluation to validate instruction-following quality beyond format compliance.
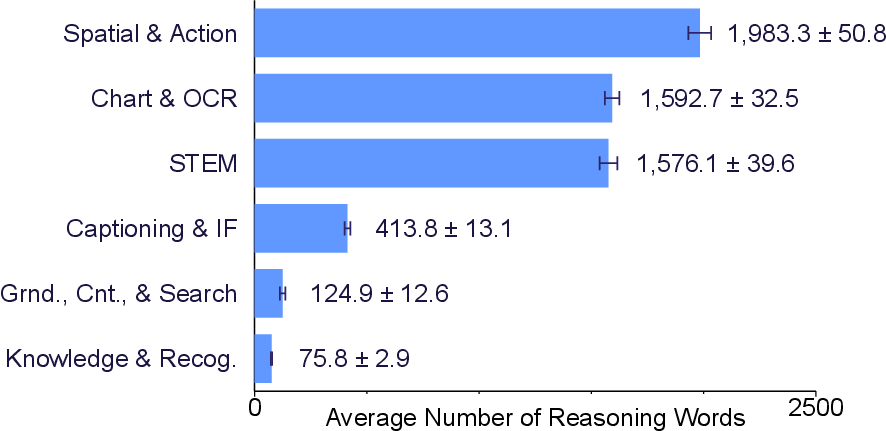
- Overlong penalty side effects: The soft overlength penalty may truncate genuinely beneficial longer chains of thought; no ablations on B, λ, or task-specific length targets to quantify trade-offs.
- Format enforcement trade-offs: Requiring > and boxed answers may harm naturalness and general downstream usability; no user-facing evaluation of formatting constraints’ impact on chat quality.
Removal of KL penalty: Eliminating KL control can cause instability or distributional drift; stability–performance trade-offs, safety impacts, and catastrophic forgetting risks are not systematically studied.
- Token-level credit assignment: The sequence-level advantage (constant within response) precludes token-level credit; whether finer-grained attribution improves learning on long reasoning traces is unknown.
- Alternative RL algorithms: Comparisons to PPO, advantage-weighted objectives, explicit value functions, or offline RLAIF/DPO variants are missing; it’s unclear if GSPO-style updates are optimal for heterogeneous multimodal tasks.
- Adaptive task mixing: Uniform task ratios outperform the tested static alternatives, but online curricula (e.g., progress-aware sampling, bandit allocation, uncertainty-driven or loss-aware routing) are not evaluated.
- Per-category interference mitigation: The paper observes cross-task interference but does not test architectural or optimization approaches (e.g., adapters, experts, gradient surgery, per-task optimizers) to reduce it.
- Scaling laws and compute efficiency: RL FLOPs vs. performance scaling is shown qualitatively, but sample/compute efficiency, scaling beyond 600K, and diminishing returns per category are not quantified.
- Model size transferability: Results focus on ~7B–8B models; whether the recipe scales to smaller (resource-constrained) or much larger models, and how gains change with size, is untested.
- Open-ended chat preservation: Including open-ended tasks is claimed necessary, yet there is no comprehensive evaluation of conversational quality, factuality, and hallucination rates post-RL.
- Inference-time strategy effects: The impact of decoding choices (temperature, top-k/p), self-consistency, or test-time compute allocation on broad visual reasoning remains unreported.
- Tool integration: The recipe is tool-free; combining RL with external OCR engines, retrieval, code execution, or geometric solvers (and corresponding verifiers) is unexplored.
- Multi-image reasoning: Although inputs may be “a set of images,” the training/evaluation setup for explicit multi-image reasoning (e.g., cross-image entity tracking) is not detailed or analyzed.
- Data selection sensitivity: Heuristic thresholds (e.g., 200K-pixel cutoff, 1K-min dataset size) may exclude valuable data; ablations on these thresholds’ impacts are not provided.
- Licensing and ethics of sources: The 59 datasets’ licenses, usage permissions, and potential personally identifiable information are not documented; auditability and compliance remain open.
- Failure case taxonomy: Beyond aggregate scores, there is limited qualitative error analysis by category (e.g., OCR misreads vs. reasoning mistakes), hindering targeted dataset/reward improvements.
- Generalization to unseen task categories: The paper highlights poor transfer across their six categories; it remains open how to design representations or curricula that generalize to entirely new visual skills.
Practical Applications
Immediate Applications
Below are practical, deployable use cases that leverage the paper’s open models, data, and RL recipe today. Each item names the sector, the application, the enabling components from the paper, and assumptions or dependencies.
- Healthcare — Visual report and chart copilot for clinicians and administrators
- What: Summarize, query, and cross-check charts, tables, and infographics in clinical reports and administrative dashboards (e.g., trends, anomalies, cohort comparisons).
- Enabled by: Chart/OCR category coverage; task-routed numeric, list, and multiple-choice rewards;
Vero-600kdata and openverocolormodels. - Dependencies: Non-diagnostic use; integration with EHR/PACS access controls; domain adaptation for medical terminology; privacy/security compliance.
- Finance — Invoice and statement understanding with reasoning
- What: Extract multi-field data (totals, taxes, dates) and verify reconciliation steps or anomalies with step-by-step reasoning.
- Enabled by: Chart/OCR category, numeric rewards, list string match, format constraints; open RL recipe and verifiers for structured outputs.
- Dependencies: High-quality scans; domain schema mapping; PII handling; tolerance settings for numeric parsing.
- Software/QA — Vision-driven UI test automation and reproducible bug reports
- What: Generate click paths and action sequences from screenshots to reproduce issues or validate flows (web action JSON fields, click-in-box).
- Enabled by: Spatial & Action category; web action and clicking rewards; GSPO-based training that respects sequence formats.
- Dependencies: Stable screenshot-to-UI element mapping; integration with test runners; sandboxed environments to prevent unintended actions.
- Retail/CPG — Shelf audit and planogram compliance
- What: Count items, localize products, and flag misplacements from shelf images; summarize compliance status.
- Enabled by: Grounding/Counting/Search category; Hungarian-matched box rewards (IoU/F1), counting verifiers.
- Dependencies: Adequate image resolution; store lighting variability; product-specific fine-tuning for SKU detection.
- Public sector — Budget and performance dashboard interpreters for transparency
- What: Explain charts, detect inconsistencies across published dashboards, and produce citizen-friendly summaries.
- Enabled by: Chart/OCR and Captioning & Instruction Following categories; instruction-following rewards; uniform mixing improves broad generalization.
- Dependencies: Data provenance and update cadence; multilingual adaptation; policy-compliant disclosures.
- Education — Diagram and figure tutor for STEM learning
- What: Help students reason through math and science diagrams, annotate key steps, and provide structured solutions.
- Enabled by: STEM category; numeric and ordering verifiers; format rewards enforcing > /<answer> structure.
> - Dependencies: Classroom policies on exposing chain-of-thought; curriculum alignment; guardrails against hallucination.
>
> - Publishing/Research — Scientific figure QA and metadata extraction
> - What: Verify axes, units, legends, and claims in figures; extract data points for meta-analysis.
> - Enabled by: Chart/OCR coverage; numeric parsing and list match rewards; dataset curation pipeline for verifiability.
> - Dependencies: Image quality, publisher workflows; domain ontologies; potential human-in-the-loop validation.
>
> - Accessibility — Alt-text and constrained image descriptions
> - What: Generate concise, constraint-compliant alt-text (length, keywords), and tailored descriptions for educational materials.
> - Enabled by: Captioning & Instruction Following category; rule-based instruction-following rewards (MMIFeval-style constraints).
> - Dependencies: Content moderation filters; review for sensitive content; language coverage beyond English.
>
> - Customer support — Visual troubleshooting from user photos
> - What: Recognize parts, steps, and likely issues; produce actionable guidance with spatial references.
> - Enabled by: Knowledge & Recognition plus Spatial & Action categories; multi-task reward routing for heterogeneous answers.
> - Dependencies: Device-specific knowledge bases; liability disclaimers; ambiguity filtering pipeline to reduce unverifiable prompts.
>
> - Geospatial/Utilities — Aerial object localization and counting (e.g., assets, defects)
> - What: Identify and count assets (poles, panels) or visible anomalies in aerial imagery.
> - Enabled by: Grounding/Counting/Search category; box and count verifiers; evidence of transfer on AerialVG-like tasks.
> - Dependencies: Domain shift from benchmarks; georegistration; weather/lighting variations; regulatory constraints on aerial data.
>
> - Business intelligence — Chart QA copilot inside BI tools
> - What: Answer freeform questions about dashboards, reconcile figures across pages, and generate insight summaries.
> - Enabled by: ChartQA-like benchmark performance; open models usable via Hugging Face; uniform task mixture preserving visual chat.
> - Dependencies: Connector to BI schemas; row-level access control; prompt templates for enterprise tone.
>
> - MLOps/Research infrastructure — Open multi-task RL post-training lab
> - What: Reuse the paper’s open GSPO-based pipeline, routed rewards, and filtering steps to post-train domain VLMs and evaluate with the 30-benchmark suite.
> - Enabled by: Released code,
Vero-600kdata, reward toolkit, ablation-backed design decisions (uniform mixing). > - Dependencies: GPU budget; dataset licensing; prompt/answer normalization policies; adoption of structured output format. > > ## Long-Term Applications > > These opportunities require further research, domain validation, scaling, or engineering to meet reliability, regulatory, or performance thresholds. > > - Healthcare (diagnostics) — Regulatory-grade medical image reasoning > - What: Assist with triage or diagnostic suggestions from imaging plus charts, with auditable reasoning traces. > - Needs: Clinical trials; bias/fairness analysis; FDA/CE mark; robust domain-specific datasets and rewards for medical uncertainty. > > - Robotics — Vision-language control for physical actions > - What: Extend spatial/action reasoning from UI clicks to embodied manipulation and navigation with grounded plans. > - Needs: Closed-loop environments; physical reward design; safety policies; integration with robot stacks (ROS), video and 3D inputs. > > - Autonomous UI agents — End-to-end multi-step task completion across apps > - What: Plan, act, and verify across complex workflows (forms, uploads, multi-tab operations) with recovery strategies. > - Needs: Persistent memory, state tracking, hierarchical planning, stronger web action schemas, sandboxed execution. > > - Compliance and audit — Automated document review with formal guarantees > - What: Detect inconsistencies and policy violations across large document sets; produce evidence-linked reports. > - Needs: Formal verification of numeric reasoning, provenance tracking, certified evaluation harnesses, tamper-evident logs. > > - Finance — Risk analytics from mixed visual-text sources > - What: Fuse charts, filings, and external signals for risk scoring with interpretable rationales. > - Needs: Domain-specific calibration; long-context retrieval; counterfactual analysis; human-in-the-loop governance. > > - Energy/Infrastructure — Asset monitoring at scale from remote sensing > - What: Detect, count, and map assets and defects over vast areas; prioritize maintenance. > - Needs: Robust geospatial models; temporal reasoning (video/time series); labeling pipelines; edge/on-device deployment. > > - Education — Multimodal tutors with adaptive curricula > - What: Cross-image reasoning (lab setups, diagrams, experiments) and personalized scaffolding with reliable assessment. > - Needs: Curriculum-aligned rewards, learning analytics integration, privacy-preserving student models, multilingual coverage. > > - Accessibility — Real-time scene understanding on-device > - What: Mobile/edge assistants providing spatial guidance and object localization for navigation. > - Needs: Efficient 8B or smaller models; latency and battery constraints; robust perception in unconstrained environments. > > - Content integrity — Misinformation detection in charts and infographics > - What: Identify misleading scales, cherry-picked subsets, or inconsistent legends. > - Needs: Specialized datasets, deception-aware rewards, explainability tools, policy frameworks for moderation. > > - Scientific meta-research — Automated figure-to-data extraction at scale > - What: Convert scientific figures into machine-readable datasets for meta-analyses and replication studies. > - Needs: High-precision digitization, error bounds, domain ontologies, publisher collaborations, adjudication workflows. > > - Standards and policy — Open evaluation and procurement frameworks > - What: Adopt routed rewards and benchmark suites as standards for public-sector multimodal systems. > - Needs: Community governance of datasets and verifiers, certification processes, documentation requirements (model cards, training data transparency). > > - Multimodal expansion — Video, 3D, and speech integration for general visual reasoning > - What: Extend the open RL recipe to temporal and 3D tasks with heterogeneous rewards. > - Needs: New verifiers for temporal consistency and 3D grounding, scalable data curation, curriculum design to mitigate task interference. > > Notes on assumptions and dependencies common across applications: > > - Performance and reliability: Benchmarks indicate strong 8B results, but domain shifts require calibration, monitoring, and possible fine-tuning. > > - Data quality and licensing: The curation pipeline filters ambiguity and enforces verifiability; production deployments must ensure compliant data sources. > > - Structured outputs: Many rewards assume <think>/<answer> formats and\boxed{...}answers; product UIs may need to capture reasoning privately or suppress it for compliance. > > - Safety and governance: LLM-as-judge introduces subjectivity; guardrails against reward hacking and robust ambiguity filtering are advisable. > > - Compute and deployment: The open recipe runs with GRPO/GSPO variants; training needs multi-GPU; inference for 8B is feasible but may require optimization for edge scenarios.
Glossary
- Ablations: Systematic experiments that remove or vary components to measure their effect on performance. "Accompanying technical reports often omit detailed ablations of design choices"
- Asymmetric clip-higher: A PPO-style clipping scheme that allows a larger positive update bound than the negative bound to stabilize training. "We adopt asymmetric clip-higher~\citep{dapo} ()"
- Chain-of-thought reasoning: Training or prompting models to generate step-by-step intermediate reasoning before final answers. "Chain-of-thought reasoning enables models to use additional test-time compute through step-by-step problem decomposition"
- Curriculum sampling: A training strategy that orders or weights data by difficulty or other criteria to guide learning. "have explored techniques such as RL with curriculum sampling~\citep{glmv}"
- Distillation: Training a student model to imitate a teacher model’s outputs or reasoning traces. "The two dominant approaches for training reasoning models are distillation, where a strong teacher generates reasoning traces for supervised fine-tuning"
- Grounding: Linking text to specific visual regions or objects, often via bounding boxes. "Grounding (): optimal Hungarian matching of predicted and ground-truth bounding boxes, scoring IoU/F1 with threshold 0.5."
- Group Relative Policy Optimization (GRPO): A reinforcement learning algorithm that extends PPO with group-based relative advantages. "Our RL algorithm builds on Group Relative Policy Optimization (GRPO)~\citep{grpo}"
- GSPO: An RL variant that replaces per-token importance ratios with a single ratio computed at the sequence level. "GSPO~\citep{gspo} replaces the independent per-token importance ratios of GRPO with a sequence-level ratio."
- Hungarian matching: An algorithm for optimal assignment used here to match predicted and ground-truth boxes. "optimal Hungarian matching of predicted and ground-truth bounding boxes"
- Importance ratios: Ratios of current to reference policy probabilities used to weight policy updates in PPO-like methods. "replaces the independent per-token importance ratios of GRPO"
- Intersection over Union (IoU): A measure of overlap between predicted and ground-truth regions, computed as area of intersection divided by area of union. "scoring IoU/F1 with threshold 0.5."
- KL penalty: A regularization term that penalizes divergence from a reference policy using Kullback–Leibler divergence. "remove the KL penalty~\citep{dapo,liu2025understanding} to allow less-restricted updates"
- LLM-as-judge: Using a LLM to evaluate and score model outputs as a learned reward signal. "LLM-as-judge (): We adapt the judge setup from OLMo3"
- math-verify: A tool/framework for parsing and verifying numeric or symbolic answers for exact or tolerant matching. "Numeric (): symbolic parsing via math-verify~\citep{mathverify}, with optional tolerance."
- Normalized group advantage: A standardized advantage value computed across a group of rollouts to scale policy updates. "where is the normalized group advantage;"
- On-policy RL: Reinforcement learning that collects data using the current policy being optimized. "mixed on-policy RL~\citep{mimovl}"
- Overlong penalty: A reward penalty that discourages excessively long responses by linearly reducing reward near length limits. "apply a soft overlong penalty~\citep{dapo} that linearly ramps before the context limit."
- Proximal Policy Optimization (PPO): A policy-gradient RL algorithm that uses clipped objective functions for stable updates. "methods such as PPO~\citep{schulman2017proximal} and GRPO~\citep{grpo}"
- Reward hacking: Model behaviors that exploit weaknesses in reward functions to achieve high scores without genuinely solving tasks. "explicitly penalizes self-evaluative language and meta-commentary to reduce reward hacking."
- Sequence-average log-probability difference: The average difference in log-probabilities across a generated sequence between current and reference policies. "the sequence-average log-probability difference $\bar{\Delta}_i = \frac{1}{|y_i|}\sum_{t} (\log \pi_\theta(y_{i,t}) - \log \pi_{\theta_\text{old}(y_{i,t}))$"
- Sequence-level ratio: A single importance ratio computed for the entire sequence rather than per token, used to weight updates. "with a sequence-level ratio."
- Stop-gradient: An operation that prevents gradients from flowing through certain terms during backpropagation. "where denotes stop-gradient."
- Task-routed rewards: A reward framework that selects different reward functions based on the task type or answer format. "designing task-routed rewards that handle heterogeneous answer formats."
- Token-level ratio: An importance ratio computed for each token, used in PPO-style objectives for per-token weighting. "to form a token-level ratio "
- Uniform task category weighting: Sampling training data equally across task categories to balance multi-task learning. "We use uniform task category weighting, as it achieves the best overall performance."
- Vision-LLM (VLM): A model that processes both visual inputs and text to produce multimodal reasoning and answers. "training a Vision-LLM (VLM) via reinforcement learning"
- Web action: A structured action representation (e.g., ACTION, MARK, VALUE) used to evaluate UI or web interaction tasks. "Web action (): weighted match over structured JSON fields (ACTION, MARK, VALUE), with score equal to the fraction of non-null gold fields correctly predicted."
Collections
Sign up for free to add this paper to one or more collections.