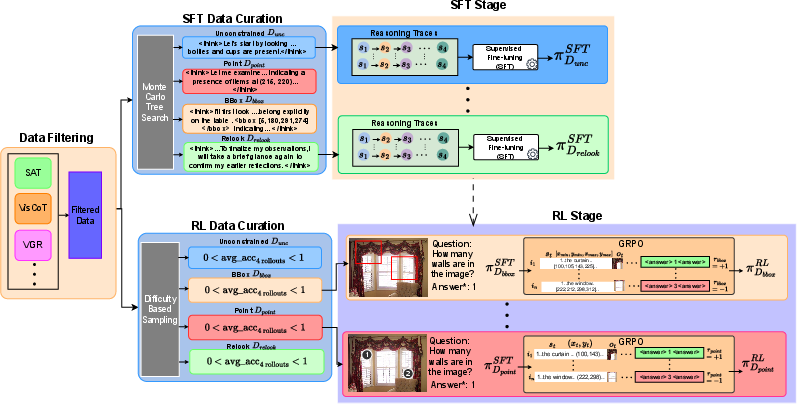
- The paper introduces a two-stage training pipeline combining supervised fine-tuning with RL fine-tuning using GRPO to enforce logical consistency and visual grounding.
- It employs verifiable reward signals and adaptive Lagrange multipliers to constrain policy optimization for task accuracy and faithful reasoning.
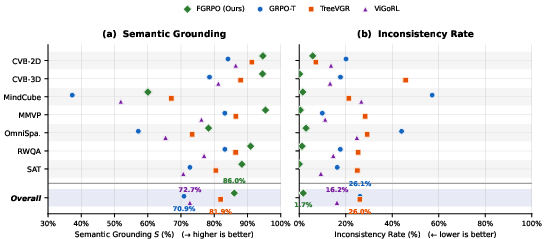
- Empirical results show significant improvements, reducing logical inconsistency from 26.1% to 1.7% and increasing semantic grounding by 13 percentage points.
Faithful GRPO: Constrained Policy Optimization for Trustworthy Visual Spatial Reasoning
Multimodal reasoning models (MRMs) trained via reinforcement learning with verifiable rewards (RLVR) have demonstrated improvements in accuracy for visual reasoning tasks. However, the observed accuracy gains often mask degraded reasoning quality—specifically, Chain-of-Thought (CoT) traces frequently exhibit logical inconsistency (reasoning does not entail the answer) and insufficient visual grounding (reasoning steps misrepresent objects, attributes, or spatial relations in the image). Empirical analysis across seven challenging spatial reasoning benchmarks confirms the presence of these defects in state-of-the-art methods, including ViGoRL-Spatial and TreeVGR, as well as models trained with Group Relative Policy Optimization (GRPO).
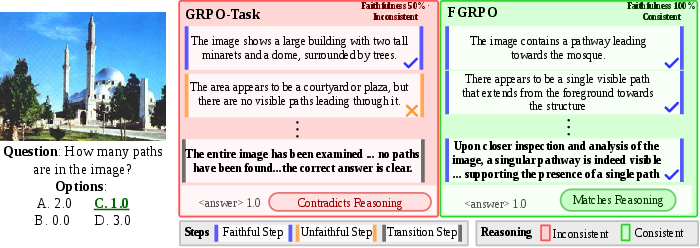
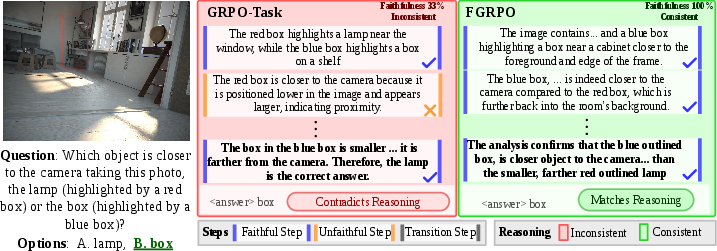
Figure 1: Unfaithful reasoning is hidden beneath correct answers; only Faithful GRPO (FGRPO) delivers visually grounded and logically consistent reasoning.
The paper delineates reasoning quality along two axes:
- Logical consistency: CoT must entail the final answer.
- Visual grounding: Each reasoning step must accurately describe the image.
These axes are orthogonal; a model can answer correctly despite inconsistent or ungrounded reasoning, producing outputs that are untrustworthy and unsuitable for real-world deployment.
FGRPO: Methodology and Constrained Optimization
Two-Stage Training Pipeline
FGRPO extends the standard RLVR paradigm with two-stage training:
Faithful GRPO (FGRPO) introduces a constrained policy optimization objective:
θmax E[Rtask]s.t.E[RC]≥τC, E[RS]≥τS, E[RG]≥τG,
where RC, RS, and RG are verifiable reward signals for logical consistency, semantic (visual) grounding, and spatial grounding (IoU of bounding boxes), with corresponding threshold hyperparameters.
A Lagrangian relaxation transforms the constrained optimization into an unconstrained objective using adaptive multipliers learned via dual ascent. Decoupled normalization of each reward within rollout groups ensures heterogeneous reward signals contribute effective gradients.
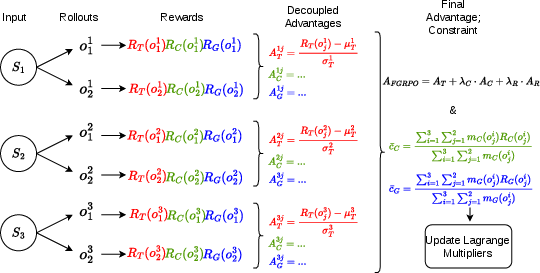
Figure 3: The FGRPO training pipeline combines decoupled group-normalized advantages for task, consistency, and grounding signals, with Lagrange multipliers adaptively enforcing constraints.
Reward Signal Design
- Consistency Reward (RC): Evaluated by a text-only LLM judge, binary signal indicating logical entailment between CoT trace and final answer.
- Semantic Grounding (RS): Per-sentence scoring via VLM judge for alignment to image content—entity, attribute, spatial relationship, and bounding-box content.
- Spatial Grounding (RG): IoU matching of generated and ground-truth bounding boxes using CIoU.
- Task Reward: Combines answer accuracy and format adherence.
Constraint rewards are masked appropriately to prevent reward hacking—e.g., only correct answers, or only bounding-box annotated samples.
Empirical Results
Reasoning Quality Breakdown
FGRPO improves both accuracy and reasoning quality on Qwen2.5-VL-7B and 3B backbones, evaluated across seven spatial reasoning benchmarks. Notable results:
Accuracy–Faithfulness Tradeoff
GRPO-T exhibits an inherent tension: increased accuracy correlates with degraded consistency and grounding, manifesting as faithfulness failures. FGRPO overcomes this tradeoff, maintaining low inconsistency while advancing accuracy.
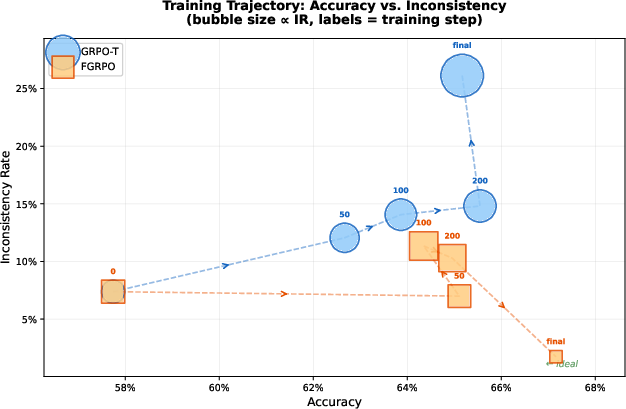
Figure 5: FGRPO (squares) maintains low inconsistency throughout training, unlike GRPO-T (circles) where inconsistency increases as accuracy improves.
Qualitative Examples
Contrastive qualitative evaluation further exposes the superiority of FGRPO reasoning. Across diverse spatial reasoning tasks—aerial perspective, signage interpretation, depth estimation, object counting, directional/egocentric inference—FGRPO outputs are consistently both visually grounded and logically entailed, while GRPO-T often provides correct answers but inconsistent or misleading reasoning traces.
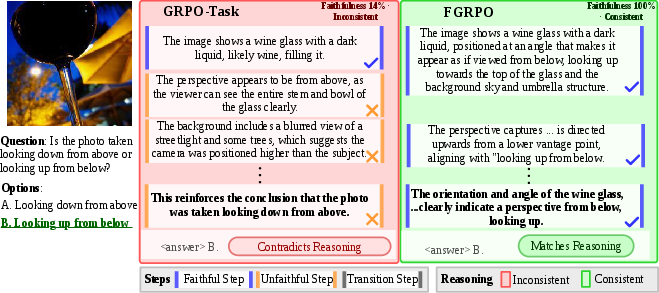
Figure 6: Perspective estimation; FGRPO accurately reasons about the viewpoint, while GRPO-Task contradicts the answer.
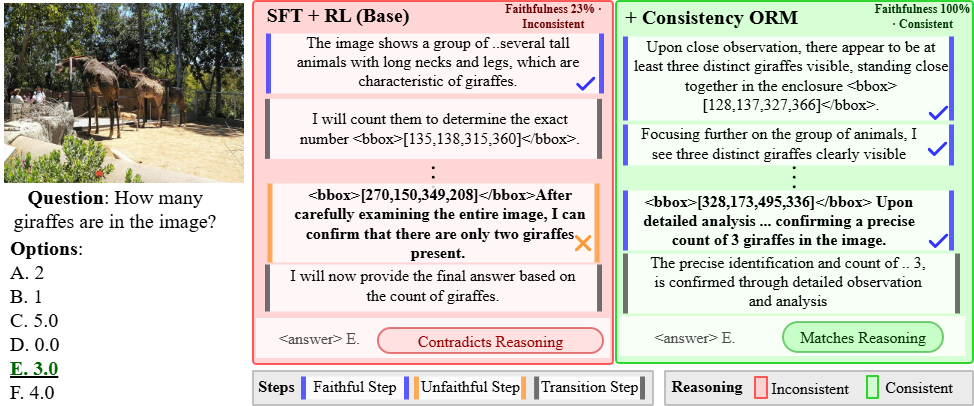
Figure 7: Object counting; FGRPO gives a faithful count and reasoning, whereas GRPO-Task miscounts but matches the answer.
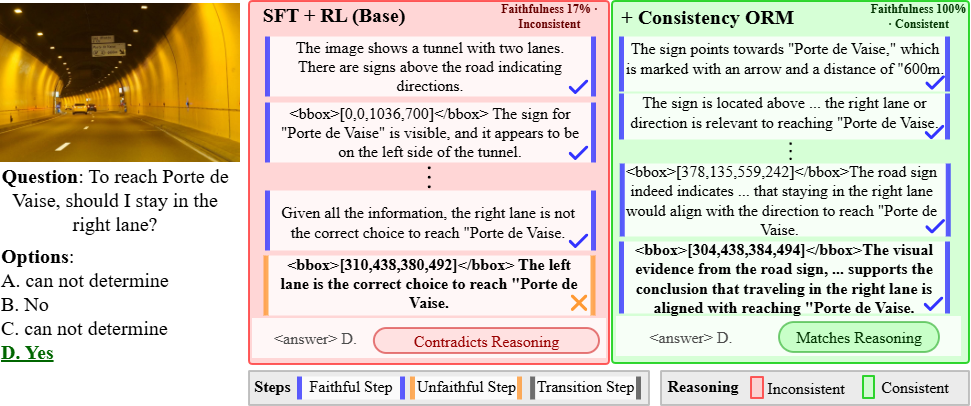
Figure 8: Directional reasoning; FGRPO decodes traffic signs and lane choice with consistent logic.

Figure 9: Eval set responses from FGRPO showing robust spatial grounding and logical consistency.
Theoretical and Practical Implications
FGRPO establishes the necessity of enforcing reasoning quality as first-class optimization constraints rather than auxiliary reward terms. Decoupled normalization and adaptive Lagrange multipliers make constraint satisfaction tractable for heterogeneous reward types. Practically, FGRPO offers significant enhancements in model trustworthiness for spatial reasoning applications; output traces become verifiable and auditable, crucial for settings where answer explanation is paramount (robotics, navigation, medical imaging, VQA-X).
Theoretically, FGRPO demonstrates that accuracy and faithful reasoning are orthogonal and complementary, not mere trade-offs. This shifts the evaluation paradigm from answer correctness alone to holistic trustworthiness in multimodal RL.
Future developments may extend the FGRPO framework:
- Incorporating additional verifiable constraints (e.g., step-wise mathematical correctness, compositionality, safety).
- Scaling to larger backbones and broader task domains including natural language planning, vision-action, and interactive RL settings.
- Integrating automatic constraint discovery and judge self-improvement for reward signal design.
Conclusion
Faithful GRPO (FGRPO) enforces logical consistency and visual grounding as hard constraints within multimodal RL training, yielding MRMs with superior spatial reasoning capabilities, consistent and auditable reasoning traces, and improved accuracy. FGRPO’s constrained policy optimization formulation resolves longstanding issues of unfaithful reasoning masked by correct answers, enabling reliable deployment of MRMs for real-world spatial intelligence tasks (2604.08476).