Multi-Agent Computer Use
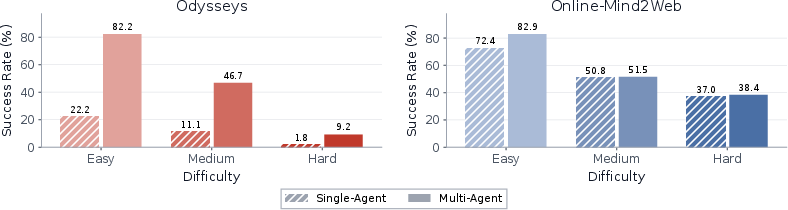
Abstract: Computer use agents (CUAs) today are primarily deployed as single serial agents. This setup is suboptimal for complex long-horizon tasks that benefit from task decomposition, parallel execution, and consistent re-planning based on new information. In this paper, we argue that we should instead move towards evaluating and building multi-agent computer use (MACU) systems. These systems, which emphasize planning and parallel execution, alleviate many of the shortcomings of single-agent CUAs. We propose a general multi-agent setup in which a manager model decomposes computer use tasks as a directed acyclic graph (DAG), encoding relevant dependencies and goals for subagents. At each iteration, the manager dispatches parallel CUA subagents to carry out nodes on the ready frontier of the DAG, and continuously revises the DAG (adding, canceling, or rewriting nodes) as new findings arrive from subagents. This design treats the partially observable environment of computer use as a first class challenge: information that downstream agents may not be able to re-observe are retained and passed forward through the manager and DAG structure. We demonstrate that MACU consistently improves over strong single-agent baselines by $3.4-25.5\%$ on desktop (OSWorld) and web navigation (Online-Mind2Web, WebTailBench, Odysseys) benchmarks, exhibits more favorable test-time scaling, and solves complex long-horizon tasks where single-agent CUAs get stuck. On Odysseys, a long-horizon web navigation benchmark, MACU improves average task completion wall-clock time by ${\sim} 1.5 \times$, demonstrating its efficacy in speeding up traditionally slow CUA pipelines. Our findings highlight that multi-agent coordination is a promising axis for scaling computer use agents to work productively for longer and more effectively. We release all code and interactive visualizations at https://jykoh.com/multi-agent-computer-use.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching AI “computer helpers” to work together as a team, instead of acting alone. Today, most computer-use AIs try to finish a task step by step by themselves. That works for simple jobs, but it often fails or gets slow on big, messy tasks (like planning a trip across multiple websites, filling out forms, collecting files, and comparing options). The authors introduce a team-based system called MACU (Multi-Agent Computer Use), where one “manager” AI plans the work and several “worker” AIs do different parts in parallel. This teamwork makes the whole system faster, more reliable, and better at long, complex tasks.
What questions did the paper ask?
- Can a team of AIs using a smart plan do better than a single AI on real computer tasks?
- What is a good way to plan and coordinate that team, especially when the computer screen and websites only show part of the needed information at a time?
- Does planning, parallel work, and constant re-planning improve success and speed?
- Which kinds of tasks benefit most from this approach?
How did they do it? (Methods)
Think of a school group project done well:
- One student (the “manager”) breaks the big task into smaller subtasks, decides who does what, and updates the plan when new info shows up.
- Several students (the “workers”) each work on their piece at the same time, like researching, filling a spreadsheet, or writing a draft.
- They share important notes and files, and at the end, the manager puts everything together.
The paper turns this idea into an AI system:
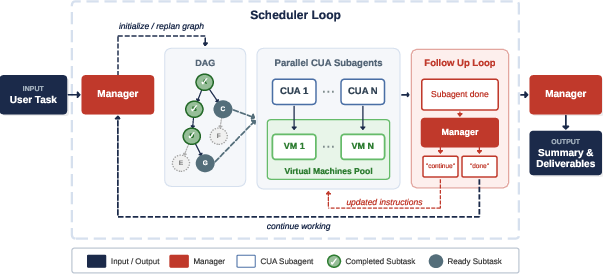
The plan: a DAG
The manager creates a plan shaped like a flowchart called a DAG (Directed Acyclic Graph). In simple terms:
- The plan is a set of subtasks (nodes) with arrows that show which tasks depend on which others.
- “Directed” and “Acyclic” just mean the arrows always point forward and never loop back, so you don’t get stuck going in circles.
The manager
The manager AI:
- Breaks the original task into subtasks and draws the arrows (the DAG).
- Sends subtasks that are “ready” to worker AIs to run in parallel.
- Re-plans when something changes or new facts appear (for example, if a site is down, try another route).
- Decides which files to keep and pass along (like a saved spreadsheet or a downloaded PDF).
- Writes the final summary answer at the end.
The workers (computer-use agents)
Each worker AI controls a virtual computer:
- It looks at the screen, thinks about the next action, and clicks/scrolls/types.
- It follows the manager’s instructions for its subtask.
- When finished, it reports back what happened (and any files it created).
Handling “partial visibility”
Real computers and websites are only partially visible at any moment (you can’t see every tab, file, or hidden content all at once). Also, some screens or states disappear after you leave a page. The system treats this as a first-class challenge:
- Workers record important findings (like prices or links).
- The manager keeps those findings and passes them to the next subtasks, so future workers don’t lose crucial info they can’t re-open later.
Parallel work and re-planning
The manager can:
- Launch multiple workers at the same time to speed up tasks (for example, compare prices on 4 sites at once).
- Use a “re-plan budget” to revise the plan as new info arrives (like adding a retry path or swapping a stuck subtask).
What did they find? (Results)
The team tested MACU on four tough benchmarks:
- OSWorld: desktop tasks on a real operating system (like using apps, editing documents).
- Online-Mind2Web and WebTailBench-v2: real web browsing tasks across many sites.
- Odysseys: very long, realistic web journeys (like planning travel with many steps).
Main results:
- MACU beat strong single-agent baselines by 3.4% to 25.5% more tasks solved, depending on the benchmark.
- On Odysseys (the long, complex tasks), MACU improved success the most (+25.5%) and cut the average time by about 1.5×. It also earned higher “partial credit” on tasks it didn’t fully complete.
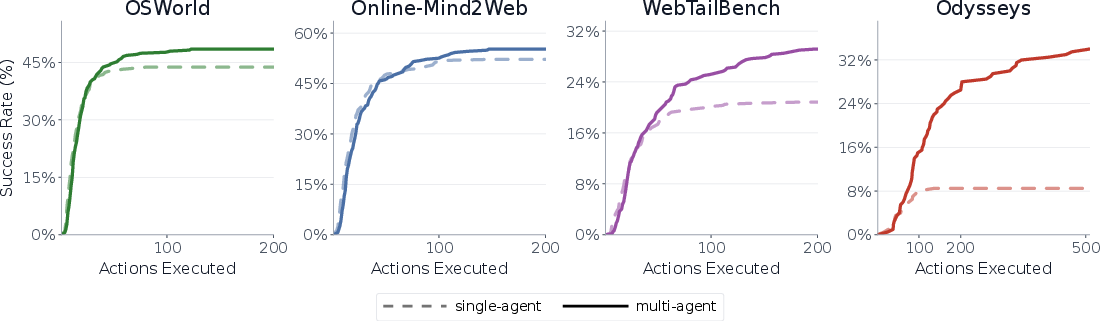
- MACU scales better with more “thinking time.” If you allow more actions, the multi-agent system keeps improving, while single agents plateau earlier.
- Re-planning matters a lot. Allowing the manager to adjust the plan mid-run boosted success far more than just making a one-time plan.
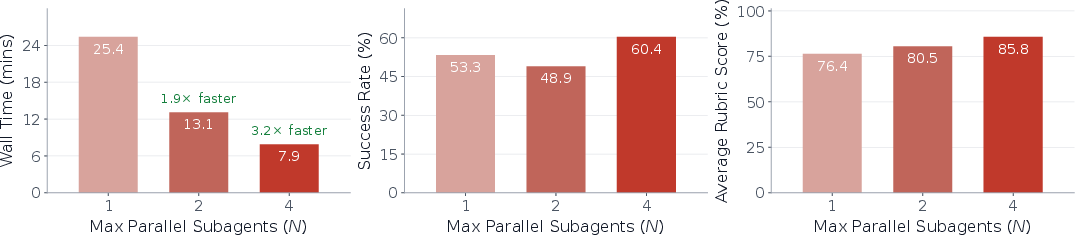
- More parallel workers reduce wall-clock time and can raise success on tasks that split naturally into independent parts.
- Stronger manager and worker AIs both help, but even with modest models, MACU still beat a single-agent approach.
Which tasks benefit most?
- Jobs you can break into pieces and run in parallel (like “map-reduce” patterns: collect info from many sources, then combine it).
- Long-horizon tasks that need backtracking, retries, or alternate paths.
- Tasks that require keeping and passing along files or notes across steps (so later subtasks don’t lose past context).
Why this is important
This work shows that moving from “one smart helper” to “a coordinated team of helpers” can make AI much better at real computer work:
- Faster: Parallel workers cut waiting time.
- Smarter under uncertainty: Re-planning handles surprises (site changes, login issues, broken links).
- More reliable: Complex, multi-step tasks are less likely to get stuck.
In practical terms, this could improve AI assistants that:
- Research across many websites, compare options, and produce a final report or spreadsheet.
- Handle office workflows across multiple apps.
- Manage longer, real-world tasks (like travel planning, shopping with constraints, or filing forms).
The system is also future-proof: as better AI models come out, you can plug them in as workers or as the manager to get even stronger results. The authors also suggest that training (fine-tuning or reinforcement learning) specifically for teamwork could push performance even higher.
In short, the paper makes a strong case that multi-agent coordination—planning, parallel work, and constant re-planning—is a key step toward AI that can do longer, more useful computer tasks in the real world.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of concrete gaps and open questions that remain unresolved and can guide future research:
- Formal treatment of partial observability
- No principled framework (e.g., POMDP formulation) for what information subagents should persist, how to compress it, or how to guarantee that non-reobservable state is captured and propagated with minimal loss.
- Verification beyond LLM judgments
- Heavy reliance on LLM-as-a-judge (Online-Mind2Web, WebTailBench) risks evaluation bias; robust, non-LLM verifiers and task-grounded checks for web tasks remain underexplored.
- Fair compute and cost accounting
- Success-vs-steps plots count only CUA actions, omitting manager token/time costs; head-to-head comparisons under equal wall-clock, equal token, and equal dollar budgets are missing.
- Cost-aware and latency-aware scheduling
- No method to jointly optimize manager calls, subagent concurrency, and retry strategies for minimal cost/latency; the choice of N (parallelism) and B (replan budget) is static and untuned per task.
- Scalability beyond N=4 and manager bottlenecks
- No evaluation of larger parallel pools, straggler mitigation, backpressure, or manager throughput limits; unclear whether the manager becomes a systemic bottleneck as N scales.
- Adaptive gating: when to go multi-agent vs. stay serial
- No policy to detect serial tasks and avoid unnecessary parallelism/replanning (which increased wall-clock time on Online-Mind2Web); learned meta-controllers are needed.
- Learning to decompose and replan
- DAG generation and edits are purely prompted; there is no supervised, reinforcement learning, or offline RL to improve decomposition quality, edit policies, or credit assignment across agents.
- Structured communication and typed resources
- Manager–worker messages are untyped natural language; no use of typed IRs with pre/post-conditions, resource schemas, or capabilities that could reduce miscoordination and enable verification.
- Graph correctness and safety guarantees
- Beyond “valid JSON DAG,” there is no formal mechanism for cycle/deadlock detection, avoidance of orphan nodes, or guarantees that rewiring/cancellation does not create unreachable or inconsistent states.
- File management and artifact provenance
- Criteria for selecting files to persist are unspecified; no versioning, deduplication, provenance tracking, or conflict resolution when reusing or merging artifacts across VMs/subtasks.
- Shared state and session continuity across subagents
- Isolated VMs prevent carrying over cookies, authenticated sessions, or tab histories; methods for safe state sharing, session transfer, or deterministic snapshot branching remain unaddressed.
- Robustness to environment and agent failures
- No explicit strategies for crash recovery, checkpoint/rollback of VMs, retry timeouts, loop detection, or automated backoff for rate-limited sites.
- Heterogeneous subagent selection
- All subagents share the same CUA backbone; dynamic model/tool selection (e.g., vision-heavy vs. DOM-heavy, code tools, retrieval tools) and routing policies are not explored.
- Comparison to strong single-agent planners
- No controlled comparisons against step-level lookahead/backtracking methods (e.g., CUA tree search) under matched budgets to isolate the benefit of subtask-level DAG orchestration.
- Decomposition error analysis
- No quantitative taxonomy of failures (bad decomposition vs. misgrounded GUI actions vs. missing evidence vs. aggregation errors); lack of targeted diagnostics to prioritize improvements.
- Memory limits and context management
- The manager sees only the “last k screenshots,” but k is unspecified and its effect unmeasured; no retrieval/memory compression strategies for very long horizons.
- Cross-site interference and non-determinism
- Parallel subagents may interfere via shared external resources (e.g., inventory counts, rate-limits); coordination protocols to avoid harmful interference are not addressed.
- Rate-limiting and anti-bot defenses
- No analysis of how parallel browsing interacts with site anti-automation measures; identity, IP diversity, and compliance strategies are undefined.
- Safety, privacy, and compliance
- Handling credentials, PII, and sensitive files across VMs is not addressed; permission models, least-privilege execution, policy guards, and ToS/legal compliance are missing.
- Real-world deployment metrics
- No user-centric metrics (e.g., human satisfaction, error severity, recovery time), SLO/SLA compliance, or cost-per-success reporting for production feasibility.
- Generalization across OSes and device types
- Evaluation is Ubuntu desktop plus web; there is no empirical validation on Windows (despite WindowsAgentArena), macOS, or mobile UIs where interaction affordances differ.
- Cross-app and mixed desktop–web workflows
- Benchmarks largely separate desktop and web; complex end-to-end workflows spanning local apps, browsers, and cloud services remain untested.
- Impact of manager strength vs. worker strength
- How performance scales when workers get much stronger (or weaker) than the manager is unclear; is there a point where multi-agent coordination yields diminishing returns?
- DAG growth control and branch pruning
- No policies for bounding branching factor, deduplicating equivalent branches, or early stopping/pruning based on utility estimates to prevent compute blow-ups.
- Evidence verification and aggregation quality
- The final aggregation relies on the manager; there is no externalized, structured evidence store with provenance or cross-checkers to prevent persuasive but incorrect summaries.
- Live web reproducibility
- Results on dynamic sites are hard to reproduce; no protocols for caching, snapshotting, or time-aware evaluation to quantify drift effects.
- Environmental and monetary cost
- Parallel VMs and frequent LLM calls incur nontrivial energy and dollar costs; there is no carbon/cost analysis or optimization objective balancing success, time, and cost.
- Security of inter-VM file transfer
- Copying artifacts between VMs introduces attack surfaces; integrity checks, malware scanning, and sandboxing policies are unspecified.
- Domain instrumentation
- The system uses screenshots; richer instrumentation (DOM diffs, accessibility trees, OS event logs) could reduce grounding errors, but is not utilized or evaluated.
- Hyperparameter auto-tuning
- N (parallelism) and B (replan budget) are fixed; adaptive per-task tuning or online bandits to trade off speed, cost, and success are unexplored.
- Multi-agent communication patterns
- Only manager–worker communication is allowed; potential benefits/risks of limited peer-to-peer coordination (with guardrails) are unstudied.
- Theoretical guarantees
- No analysis of when DAG-based multi-agent execution is provably beneficial over serial execution or over step-level search, nor bounds on regret or compute-efficiency.
- Evaluation breadth and baselines
- Limited direct comparisons to other multi-agent orchestration frameworks (e.g., specialized modules, recursive agents) under matched settings remain a benchmarking gap.
Practical Applications
Immediate Applications
These applications can be piloted or deployed today using the MACU design (manager + parallel CUA subagents with DAG-based decomposition, replanning, and file handoff), leveraging available LLMs and virtualization.
- [Software/IT] Parallel end-to-end web and desktop QA for internal products
- What: Run GUI test suites in parallel across browsers/OSes; manager replans on failures, retries alternate routes, and aggregates evidence (screenshots, logs).
- Why MACU: DAG “map-reduce” test plans with on-the-fly retries improve coverage and shorten wall-clock time; file management passes artifacts between nodes.
- Tools/workflows: Test orchestrator using MACU; per-test VMs; evidence aggregator node.
- Assumptions/dependencies: Stable test environments; VM/sandbox infrastructure; credentials/secrets vault for staging; API costs and latency budgeting for manager calls.
- [Software/IT] Cross-app office automation (“RPA 2.0” for GUIs)
- What: Multi-application tasks (e.g., extract data from spreadsheets, generate slides, email summaries) executed in parallel subtasks that stitch outputs via manager-controlled file passing.
- Why MACU: DAG-based decomposition with parallel workers improves throughput and reduces operator wait times; replanning handles partial observability and flaky UI states.
- Tools/workflows: Desktop agent pool + manager; reusable DAG templates for office workflows; audit logs.
- Assumptions/dependencies: Access to robust CUA backbone; desktop VM pools; adherence to software ToS and corporate security policies.
- [E-commerce/Procurement/Finance] Market and price intelligence at scale
- What: Price/spec comparisons across retailers/sites using “map-reduce” graphs (parallel site scrapers → aggregator); supports procurement benchmarking and dynamic pricing.
- Why MACU: Parallel subagents reduce wall-clock; replanning adds fallback strategies for anti-bot blocks or layout changes.
- Tools/workflows: Retailer node library; aggregation node that normalizes formats; alerts when deltas exceed thresholds.
- Assumptions/dependencies: Respect site terms/robots; mitigation of bot detection; robust parsing across visual changes; API cost controls.
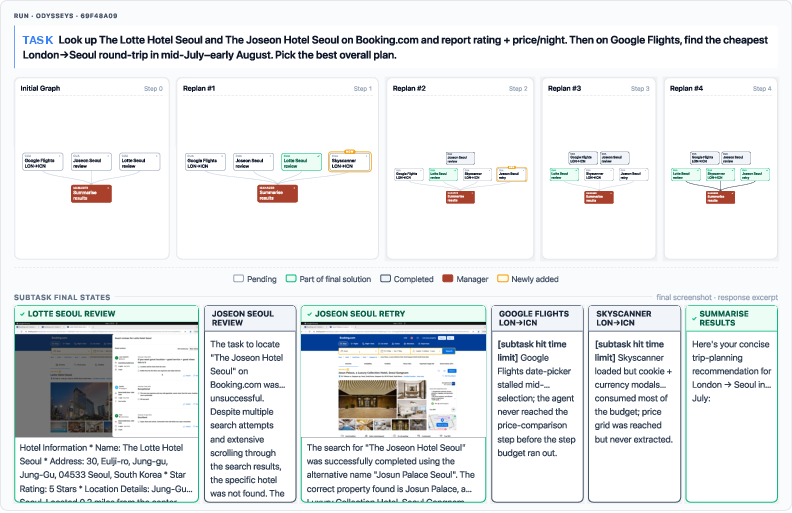
- [Travel/Corporate Ops/Consumer] Automated itinerary planning and booking assistance
- What: Parallel search for flights/hotels/activities; evidence aggregation for comparison; optional booking with human-in-the-loop approval.
- Why MACU: Demonstrated speed and completion gains on long-horizon web tasks; manager maintains ephemeral state and re-routes blocked paths.
- Tools/workflows: Travel DAG templates; approval checkpoint nodes; document/file handoff for receipts.
- Assumptions/dependencies: Account access and MFA flows; anti-bot safeguards; human approval for transactions; compliance with booking platform terms.
- [Customer Support/Knowledge Ops] Rapid multi-site knowledge gathering
- What: Collect answers/evidence from product docs, forums, and issue trackers in parallel, then synthesize a response with citations.
- Why MACU: Parallel exploration and dynamic retries improve response completeness and reduce time-to-answer.
- Tools/workflows: Source-specific nodes (docs, community, ticketing); summary/verification nodes; evidence retention.
- Assumptions/dependencies: Content licensing/ToS; LLM-as-judge alternatives for internal validation; guardrails to prevent hallucinated citations.
- [Data/ML/Research Ops] High-throughput web navigation for dataset creation and evaluation
- What: Use MACU to gather structured data from multiple sites in parallel; reproduce agent trajectories for benchmarking; compare algorithms at test-time under the same budget.
- Why MACU: Better test-time scaling and reproducibility with DAG logs; file management preserves intermediate states.
- Tools/workflows: Benchmark harness (OSWorld/WebTailBench/Odysseys); trajectory archiver; data quality check nodes.
- Assumptions/dependencies: Ethics approvals (if required), licensing for scraped data; storage and governance controls.
- [Public Sector/Policy] Public information aggregation and monitoring
- What: Track policy updates, RFPs, or regulatory changes across agency sites; parallelize per-agency checks; compile consolidated briefs.
- Why MACU: DAGs encode periodic checks; replanning adapts when portals change; evidence persistence supports audits.
- Tools/workflows: Scheduled DAGs; compliance and audit nodes; alerting pipelines.
- Assumptions/dependencies: Strict adherence to government site terms; accessibility constraints; auditability and chain-of-custody for outputs.
- [Sales/Recruiting/Competitive Intel] Multi-source lead and profile research
- What: Aggregate public information about leads/companies across multiple portals; produce structured reports.
- Why MACU: Parallel exploration reduces cycle time; retry nodes circumvent partial failures.
- Tools/workflows: Source-node catalog; de-duplication/merge node; human review node.
- Assumptions/dependencies: Respect platform ToS (e.g., rate limits, scraping restrictions); consent and privacy compliance.
- [Education] Course content assembly and grading assistance for web-based tasks
- What: Parallel curation of materials and examples from multiple vetted sources; run rubric-based checks on student-submitted web tasks.
- Why MACU: Map-reduce graphs fit curation/grading; reproducible DAG logs support fairness and audit.
- Tools/workflows: Instructor DAG templates; LLM- or rule-based rubric check nodes; LMS integration.
- Assumptions/dependencies: Academic integrity policies; approved source lists; maintainability of rubrics.
- [Everyday Users] Personal admin across web portals
- What: Renewals, form-filling, and document retrieval across banks/utilities/government portals with a user-in-the-loop.
- Why MACU: Parallel subtasks (e.g., downloading statements from multiple providers) reduce total time.
- Tools/workflows: Consumer agent app with secure local VM; approval steps before submissions; credential management.
- Assumptions/dependencies: Strong privacy and local isolation; explicit user consent; MFA handling; ToS compliance.
Long-Term Applications
These rely on further research, scaling, safety, or integration (e.g., enterprise-grade reliability, tighter security/compliance, or specialized training of manager/worker agents).
- [Enterprise IT/Platform] Agent orchestration platform (“AgentOS”) for knowledge-worker automation
- Vision: An enterprise scheduler that provisions VM pools, assigns subtasks dynamically, selects models per node, and offers observability, SLAs, and cost controls.
- Why MACU: The DAG/replanning core provides the scheduling abstraction; ablations show gains with more parallelism and stronger managers.
- Dependencies: RL/finetuning for manager policies; IAM/SOC integration; policy-driven tool/model selection; enterprise observability and rollback.
- [Healthcare] EHR workflow co-pilots for triage and documentation
- Vision: Parallel subtasks to gather labs, imaging, notes; propose orders or summaries; final clinician approval.
- Why MACU: Partial observability-aware state passing; resilient retries for brittle EHR GUI flows.
- Dependencies: Regulatory approvals (HIPAA/GDPR), on-prem isolation, vendor-certified integrations, formal verification, extremely low error tolerance.
- [Finance/Accounting] Close, reconciliation, and regulatory reporting automations
- Vision: Subagents operate across ERP, bank portals, and reporting dashboards; manager coordinates evidence collection and exception handling.
- Why MACU: Long-horizon tasks benefit from parallel evidence gathering and robust replanning.
- Dependencies: Segregation of duties, audit trails, model risk management, deterministic fallbacks, tamper-proof logs.
- [Security/Trust] Autonomous investigation runbooks
- Vision: Multi-branch playbooks that collect artifacts (logs, tickets, sandbox results) and synthesize an incident report; analysts approve actions.
- Why MACU: DAGs encode branching hypotheses; replanning reacts to new evidence.
- Dependencies: Strict scopes, red-teaming, containment controls, read-only defaults, verified tool integrations.
- [Robotics/Edge UIs] GUI-mediated control of devices and legacy HMIs
- Vision: Agents manipulate on-screen HMIs for industrial systems where API access is limited, coordinating diagnostics and reporting.
- Why MACU: Parallel subtasks (e.g., multiple devices) and state passing help in partially observable setups.
- Dependencies: Safety certifications; air-gapped deployments; fail-safe designs; high reliability thresholds.
- [Education/Research] Automated, reproducible, and scalable agent-based studies
- Vision: MACU as a backbone for large-scale, long-horizon HCI/AI experiments; auto-generation of diverse DAGs and agent behaviors.
- Why MACU: Better test-time scaling and reproducibility vs. single-agent; DAGs as experiment specs.
- Dependencies: Community standards for reporting compute budgets; robust, unbiased evaluation beyond LLM-as-judge.
- [Consumer] Autonomous long-horizon digital concierge
- Vision: Persistent assistant that manages multi-week tasks (moving, visa applications, home services) with parallel subtasks and proactive replanning.
- Why MACU: Long-horizon gains and reduced wall-clock time on complex tasks (e.g., Odysseys-like scenarios).
- Dependencies: Trust, privacy, and consent frameworks; delegation boundaries; resilient handling of payments and identity verification.
- [Tooling/Model Ecosystem] Manager–worker co-training and specialization
- Vision: Finetuned or RL-trained managers and workers for coordination, node-level model selection, and domain-specialized skills.
- Why MACU: Ablations show strong sensitivity to manager quality; co-training should yield larger gains.
- Dependencies: Training data (DAGs, trajectories), safety filters, evaluation frameworks that reflect multi-agent behavior.
- [Web Infrastructure/Policy] Standards and governance for GUI agent access
- Vision: Site-side protocols (rate limits, consent tokens, agent headers) and audit APIs for agentic access.
- Why MACU: As parallel subagents scale, coordinated governance is needed to prevent abuse and ensure accountability.
- Dependencies: Cross-industry collaboration; updated robots/ToS; transparent telemetry and compliance tooling.
- [Developer Tools] Agent-aware CI/CD for front-end and workflow changes
- Vision: Pre-merge agent test DAGs auto-generated from product workflows; parallel tests across variants; failure triage reports.
- Why MACU: DAG structure maps to product flows; replanning stress-tests UX changes.
- Dependencies: Test data seeding, stable staging environments, integration with CI/CD pipelines, cost controls.
Common Assumptions and Dependencies (impacting feasibility)
- Model and infra
- Availability of capable CUA subagents and manager LLMs; manager API costs and latency can dominate for highly serial tasks.
- VM/sandbox orchestration to run multiple isolated sessions; GPU/CPU budget and autoscaling.
- Task characteristics
- Greatest gains when tasks decompose and parallelize (map-reduce, independent lookups, retries); smaller gains on inherently serial flows.
- Robustness to UI drift and anti-automation measures; careful handling of partial observability.
- Compliance and ethics
- Strict adherence to site/app ToS and data licensing; privacy and security controls for credentials/MFA; human-in-the-loop for high-impact actions.
- Auditing and traceability (DAG logs, screenshots, filesystem diffs) for compliance and incident response.
- Reliability and safety
- Guardrails for action execution (idempotency, rollback); verifiable evidence for critical outputs; fallback to deterministic scripts when needed.
- Evaluation and governance
- LLM-as-judge grading can be subjective; organizations may require rule-based or human evaluation for acceptance.
- Clear policies for delegation boundaries and user consent, especially in consumer and regulated domains.
Glossary
- Ablation: An experimental method where components or settings are varied or removed to assess their impact on performance. "We conduct a series of ablation experiments to justify the design choices made in the MACU setup."
- backbone: The base model architecture used as the foundation for subagents or systems. "We use the same CUA backbone for each subagent."
- backtracking: Revisiting earlier states or decisions to try alternative paths after failures or new information. "proposes a tree search algorithm for CUAs which performs lookahead and backtracking using a value function to score each proposed action."
- computational graph: A representation of a system as nodes and edges that can be dynamically adjusted and orchestrated. "Many of these works frame the system as a computational graph that can be dynamically adjusted and scaled"
- diff: A summary of changes between two filesystem states. "the manager is provided with a diff of the filesystem to identify added or modified files."
- directed acyclic graph (DAG): A directed graph with no cycles, used to structure dependencies among subtasks. "a manager model decomposes computer use tasks as a directed acyclic graph (DAG) of subtasks"
- execution-based grading: Evaluation by running automated checks to verify whether task requirements are met. "OSWorld established an execution-based grading of 369 open ended Ubuntu tasks spanning various native apps and multi-application workflows."
- followup hook: A programmatic signal to trigger additional actions or decisions after a subagent finishes or reaches a checkpoint. "Wait until a subagent completes or for a followup hook"
- groundtruth evaluator: An oracle or authoritative evaluator used to determine whether an outcome is correct. "despite pass@ having access to the groundtruth evaluator."
- LLM-as-a-judge: An evaluation approach where a LLM assesses trajectories or outputs against task criteria. "Success rate is measured through calling an LLM-as-a-judge on the completed trajectories to judge if the CUA accomplished the task."
- long-horizon tasks: Tasks that require many steps, extended planning, or sustained interaction over time. "complex long-horizon tasks that benefit from task decomposition, parallel execution, and consistent re-planning based on new information."
- lookahead: Anticipating and evaluating the outcomes of future actions before committing to them. "proposes a tree search algorithm for CUAs which performs lookahead and backtracking"
- map-reduce: A pattern where multiple parallel subtasks collect information (map) and a subsequent step aggregates results (reduce). "Map-reduce: Manager (A) creates parallel restaurant lookups (B--F), which feed a spreadsheet worker (G), then a manager action (H) reports."
- multi-agent computer use (MACU): A system design where multiple coordinated agents plan and execute computer use tasks in parallel. "we argue that we should move towards multi-agent computer use (MACU): systems which emphasize planning and parallel execution"
- partial observability: A condition where the agent cannot fully observe the environment’s state at a given time. "We treat partial observability as a first-class consideration in MACU"
- pass@: A metric/strategy where success is counted if any of k independent attempts succeed. "A natural baseline to compare MACU against is pass@: we run a single-agent repeatedly up to times, stopping when the groundtruth evaluator reports a success."
- ReAct: A loop that interleaves reasoning and acting steps for agents to plan and execute actions. "Each subagent executes a standard ReAct loop used by most frontier CUA models."
- ready frontier: The set of DAG nodes whose dependencies are satisfied and can be dispatched immediately. "subtasks on the ready frontier of the DAG"
- replan budget: A limit on how many modifications to the task graph the manager is allowed to make during execution. "Each edit consumes a unit of the replan budget ."
- replanning: Revising the task plan or graph in response to new observations or outcomes. "We also perform replanning intermittently if we have additional worker capacity that is not being used"
- retry chain: A sequential pattern of repeated attempts until success or termination. "Retry chain: Manager (A) launches an attempt (B) that is repeatedly retried (C--E) until it succeeds"
- rewire: To change the dependency connections among nodes in a graph. "with the ability to add, cancel, rewire, or modify the instructions of pending subtasks."
- runtime retry expansion: Dynamically adding alternate attempts or branches during execution to recover from failures. "Runtime retry expansion: Manager (A) creates the initial search (B) and alternate search variants (C--E), then a manager action (F) selects evidence."
- test-time compute scaling: How performance changes as more inference-time computation (e.g., actions, steps, or parallelism) is allocated. "exhibits more favorable test-time compute scaling"
- tree search: A method that explores actions as branches in a tree to find successful sequences. "proposes a tree search algorithm for CUAs"
- value function: A function estimating the expected utility or quality of states or actions to guide decisions. "using a value function to score each proposed action."
- virtual machines (VMs): Isolated computing environments used to run subagents independently. "operate in isolated virtual machines (VMs)."
- wall-clock time: The real elapsed time taken to complete tasks, as experienced by a user. "improves average task completion wall-clock time by "
Collections
Sign up for free to add this paper to one or more collections.