The Unreasonable Effectiveness of Scaling Agents for Computer Use
Abstract: Computer-use agents (CUAs) hold promise for automating everyday digital tasks, but their unreliability and high variance hinder their application to long-horizon, complex tasks. We introduce Behavior Best-of-N (bBoN), a method that scales over agents by generating multiple rollouts and selecting among them using behavior narratives that describe the agents' rollouts. It enables both wide exploration and principled trajectory selection, substantially improving robustness and success rates. On OSWorld, our bBoN scaling method establishes a new state of the art (SoTA) at 69.9%, significantly outperforming prior methods and approaching human-level performance at 72%, with comprehensive ablations validating key design choices. We further demonstrate strong generalization results to different operating systems on WindowsAgentArena and AndroidWorld. Crucially, our results highlight the unreasonable effectiveness of scaling CUAs, when you do it right: effective scaling requires structured trajectory understanding and selection, and bBoN provides a practical framework to achieve this.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper looks at “computer-use agents” (CUAs)—AI helpers that use a computer like a person would, by clicking, typing, and opening apps to finish tasks. The problem is that these agents often mess up on long, complicated tasks. The authors introduce a simple but powerful idea called Behavior Best-of-N (bBoN): run many attempts of a task in parallel, turn each attempt into a short, clear “story” of what actually happened, and have a judge pick the best one. Doing this makes the agents much more reliable and successful.
What questions did the researchers ask?
The authors wanted to know:
- Can running multiple attempts and picking the best one make computer-use agents more reliable?
- How should we summarize each attempt so a judge can compare them fairly?
- Does this approach scale (get better) as we try more attempts?
- Is their method better than other ways of judging or summarizing?
- Does it work on different operating systems (Linux/Ubuntu, Windows, Android)?
How did they study it?
To make this understandable, think of a team trying to complete a tricky assignment on a computer.
1) Try many runs at once
Instead of relying on one agent’s single run, they start several runs (called “rollouts” or “trajectories”)—like having multiple players try the same task. More tries increase the chance that at least one gets it right.
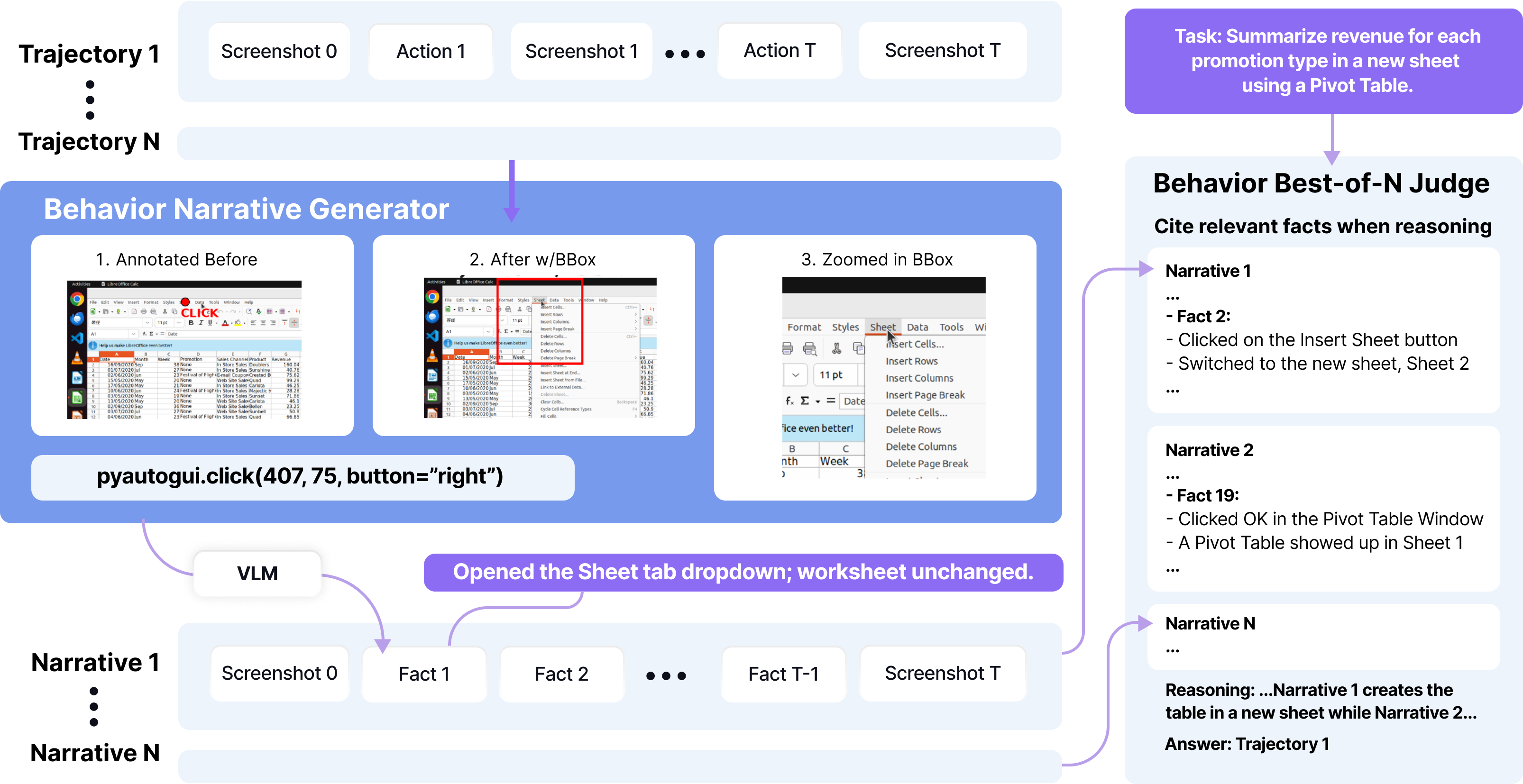
2) Turn each run into a behavior narrative (a short “play-by-play” story)
Raw runs have tons of screenshots and actions. Most details don’t matter. So they convert each step into a simple fact: what the agent did and what changed on the screen. For example:
- “Clicked the Save button; the file name appeared in the list.” They help the AI generate accurate facts by:
- Using the “before” and “after” screenshots for every action.
- Marking the pointer location (where the click happened).
- Zooming in on the important area after the action (so tiny text or buttons are easy to check).
- Waiting briefly for delayed changes (like page loads after a click). This creates a compact “behavior narrative” for each run: the starting screenshot, the sequence of action–effect facts, and the final screenshot.
3) Compare narratives and pick the best (the bBoN judge)
A vision-LLM (a type of AI that reads text and images) acts as a judge. It reads all the behavior narratives side-by-side and chooses the single best one—the run that truly completes the task correctly. This “compare-all-at-once” method avoids judging each run in isolation and makes selection more accurate.
4) Start from a stronger agent (Agent S3)
They also build an improved agent framework called Agent S3 to generate higher-quality runs:
- Flat policy: one smart “worker” agent plans and acts, instead of a slower manager–worker hierarchy.
- Coding agent: when it’s faster or more precise, the agent writes and runs code (like scripts) to make changes (e.g., renaming many files at once), then goes back to the screen to verify results.
Putting it together: multiple runs → behavior narratives → a judge picks the best.
What did they find?
Across standard benchmarks, bBoN significantly improves performance:
- On OSWorld (Ubuntu tasks), their method sets a new state of the art:
- 69.9% success at 100 steps (previous best was 59.9%).
- Human performance is about 72%, so they’re very close to human level.
- It also generalizes well:
- WindowsAgentArena: bBoN improves the baseline by about 6.4% (at 100 steps).
- AndroidWorld: bBoN improves the baseline by about 3.5%.
Other key findings:
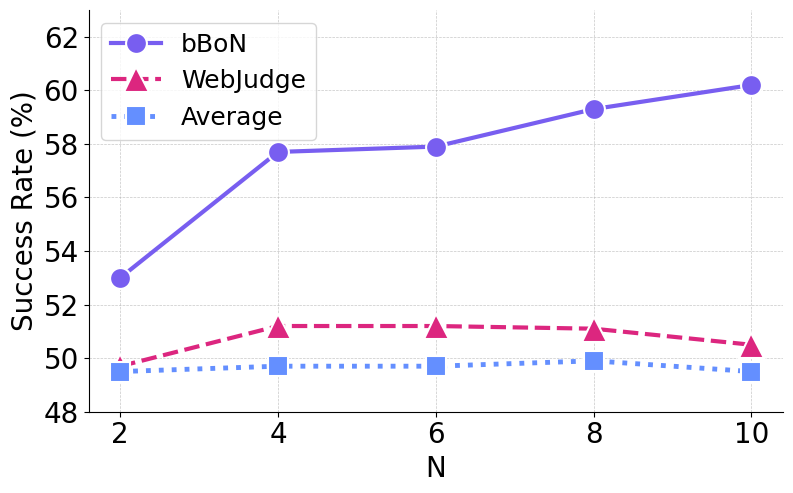
- More runs generally mean better results: as they increase the number of rollouts, success rises.
- Behavior narratives beat simpler summaries: they work better than just screenshots or basic captions because they focus on action–effect changes.
- Comparative judging beats independent ranking: judging all narratives together works better than scoring each run separately.
- A stronger base agent helps: Agent S3 alone improved speed and success, and using it inside bBoN amplified the gains.
Why is this important?
Many real computer tasks are long and messy. Small mistakes add up, and there can be multiple correct ways to finish a task. The paper shows that “scaling wisely”—trying many full solutions and selecting based on structured, easy-to-read behavior narratives—can make AI computer agents far more reliable. This approach:
- Boosts success rates and robustness.
- Works across different operating systems.
- Moves AI agents closer to human-level performance on complex tasks.
What are the limitations and what’s next?
- Multiple independent runs require controlled setups (like virtual machines with snapshots), so they don’t interfere with each other. Real desktops or shared online accounts can complicate this.
- Sometimes the narrative generator can miss fine details (like tiny text), and the judge might favor runs that look busy rather than truly finished.
Future directions include:
- Better handling of shared online resources.
- Improving visual understanding for tiny or subtle changes.
- Extending parallel rollouts to more real-world environments.
Bottom line
If you try enough complete solutions and judge them using clear, action-focused stories, computer-use agents get “unreasonably” good. The Behavior Best-of-N framework shows that smart scaling—plus thoughtful summaries and judging—can make AI much better at actually using computers to get things done.
Knowledge Gaps
Below is a single, consolidated list of concrete knowledge gaps, limitations, and open questions that remain unresolved in the paper. Each item is phrased to be actionable for future research.
- Quantify end-to-end resource costs of bBoN: report token usage, wall-clock latency, compute/VM overhead, and cost per task as N scales (e.g., N=2…32), compared against single-run baselines and step-wise BoN.
- Develop task-adaptive rollout budgets: methods to predict optimal N per task, early stopping criteria, and dynamic gating that balances marginal success gains against time/cost.
- Characterize judge scalability with context length: how comparative accuracy changes with the number of narratives in context, and techniques to compress/summarize narratives without losing discriminative signal.
- Compare selection mechanisms beyond single-round MCQ: pairwise tournaments, listwise ranking, multi-round elimination, or retrieval-style judging, measured for accuracy, token/latency, and robustness.
- Mitigate judging bias toward verbose GUI narratives: calibrate the judge to fairly assess succinct code-based rollouts and prevent preference for “richer-looking” but less correct trajectories.
- Systematically evaluate behavior narrative accuracy: build ground-truth change labels per action type (click, drag, type, scroll, code) to quantify precision/recall of generated facts and identify failure modes by modality.
- Extend narrative augmentations beyond pointer actions: design targeted augmentations for keyboard input, text edits, scrolling, window management, and multi-app transitions where changes may be subtle or off-screen.
- Replace fixed 3-second delay with adaptive change detection: event hooks, UI-tree diffs, or OS-level signals to capture delayed/async effects reliably across variable latency conditions.
- Integrate programmatic diffs and OS-level instrumentation: leverage accessibility APIs, UI trees, application logs, or file/document diffs to produce verifiable, machine-checkable state-change facts.
- Improve automatic evaluation for multi-solution tasks: learned validators or spec-based checkers that accept equivalent solutions and align more closely with human judgment across OSWorld, WindowsAgentArena, and AndroidWorld.
- Enable parallel rollouts on real desktops: techniques for isolation, side-effect containment, and concurrency control without VMs, including policies for shared online resources (accounts, carts, drives).
- Manage cross-run interference with online services: account sharding, resource virtualization, or policy-level constraints to keep trajectories independent when interacting with shared cloud assets.
- Optimize mixture-of-models under budget: methods to select and weight diverse models (e.g., GPT-5, Gemini, Claude) with formal diversity metrics, cost-aware gating, and per-task model selection.
- Design principled diversification strategies: sampling schedules (temperature/top-p), plan perturbations, goal reparameterization, or search heuristics to intentionally produce complementary solution paths.
- Explore synergy between step-wise and trajectory-level scaling: when and how to combine local BoN at critical steps with wide trajectory-level selection to maximize success with minimal overhead.
- Study scaling laws beyond N=10: diminishing returns, plateauing, and judge error accumulation at larger N; derive guidelines for “safe” scaling in terms of accuracy and cost growth.
- Assess generalization under UI drift and environmental noise: controlled tests with pop-ups, layout updates, network variability, and app version changes to measure robustness of narratives and selection.
- Address security and safety for coding actions: formal guarantees for sandboxing, side-effect auditing, data exfiltration prevention, and rollback/recovery when code edits go wrong.
- Improve reproducibility: release precise prompts, model versions, decoding parameters, seeds, and tooling; evaluate sensitivity to model updates and non-deterministic judge decisions.
- Train domain-agnostic judges: preference-learning from human pairwise labels across OS/browser/mobile domains to reduce manual rubric design and improve alignment without heavy handcrafting.
- Standardize narrative schemas: move from free-form text to structured, machine-validated representations (e.g., typed events, pre/post state predicates, verifiable constraints), enabling automated checks.
- Handle ephemeral UI elements/pop-ups: detection, stabilization, and narrative encoding for transient windows so judges can reason about short-lived but task-critical interactions.
- Provide theoretical analysis of scaling: model expected success given rollout success distribution and judge accuracy; derive optimal N and confidence estimates for selection decisions.
- Evaluate extremely long-horizon tasks (>100 steps): memory and context management for narratives and judges, partial evaluation checkpoints, and progressive verification strategies.
- Quantify token efficiency of MCQ vs alternatives: measure actual token/latency trade-offs for comparative vs tournament approaches to validate the “more token-efficient” claim.
- Bridge coding on mobile: strategies to enable code-like transformations within Android/iOS constraints (e.g., content providers, intents, on-device scripting) and incorporate them into bBoN.
- Leverage accessibility/UI-tree data in Android/Windows: use structured UI elements to create more precise narratives and stronger judges than screenshot-only inputs.
- Expand failure analysis: move beyond 12 cases to a larger, categorized corpus of judge and narrative failures; quantify the prevalence of each failure mode and test targeted fixes.
- Convert Pass@N coverage into realized SR: algorithms (e.g., re-run selection, self-correction loops) that exploit coverage to increase actual task success without linear cost growth.
- Measure robustness to frequent UI updates: longitudinal studies tracking performance as apps/OSs update, and mechanisms to automatically adapt narratives and prompts.
- Detail infrastructure and parallelization: VM orchestration strategies, snapshot policies, cache reuse, and scheduling to minimize cost while maintaining rollout independence.
- Ensure judge fairness across models: audit whether judges systematically favor certain model outputs or narrative styles; introduce calibration/equalization procedures.
- Test judge consistency: quantify variability across repeated judging on the same candidate set and implement methods for confidence estimation and tie-breaking beyond random.
Practical Applications
Immediate Applications
The following applications can be deployed today by leveraging Behavior Best-of-N (bBoN), behavior narratives, and the improved Agent S3 framework in VM/sandboxed environments or controlled desktops.
- Enterprise RPA reliability boost (software/IT operations)
- Use bBoN to run multiple parallel agent rollouts on routine back-office tasks (e.g., spreadsheet reconciliation, bulk file transforms, multi-app workflows), select the best trajectory via behavior narratives, and log an auditable summary.
- Tools/products/workflows: “bBoN Judge” microservice; “Behavior Narrative Generator” library; VM snapshot orchestration; dashboards for pass@N coverage and selection decisions.
- Assumptions/dependencies: VM/snapshotting for independent runs; access to multiple base models (mixture-of-models improves coverage); VLM judge with adequate accuracy; privacy and data-handling controls for sensitive content.
- Help desk and IT admin automation (software/IT operations)
- Automate ticket triage, software settings changes, user account operations, and configuration tasks across desktop apps, with rollouts selected by comparative narrative judging to reduce variance and retries.
- Tools/products/workflows: Agent S3 with coding agent enabled for programmatic edits; templated workflows with MCQ-based comparative selection; audit trails via narratives.
- Assumptions/dependencies: Role-based access; sandboxed execution; standardized change verification via narrative facts.
- Cross-platform GUI test-time scaling for QA (software engineering)
- Apply bBoN to GUI test suites across Ubuntu, Windows, and Android (validated on OSWorld, WindowsAgentArena, AndroidWorld) to improve flaky test pass rates by generating and selecting among diverse solution paths.
- Tools/products/workflows: CI integration where multiple agent runs are spawned per test; narrative logs for failure triage; mixture-of-model ensembles for coverage.
- Assumptions/dependencies: Deterministic test initial states; VM/emulator access; computing budget for multiple rollouts.
- Office productivity automation with fallbacks (daily life; enterprise productivity)
- Automate formatting documents, consolidating slides, cleaning data tables, and exporting media with bBoN’s selection to avoid brittle single-shot failures; Agent S3’s coding agent handles bulk operations.
- Tools/products/workflows: Desktop assistant running in a managed VM; “retry with diversity” button that triggers N rollouts and picks the best; narrative summaries for user confirmation.
- Assumptions/dependencies: App access and permissions; reliable screenshot capture and pointer overlays; user approval flow for final actions.
- Customer support content maintenance (education/knowledge management)
- Update knowledge bases, FAQs, and LMS content across multiple tools by scaling agent attempts and selecting the best successful trajectory; narratives provide explainability for audits.
- Tools/products/workflows: Process templates for content upload, tagging, and cross-linking; comparative selection judge with rubric aligned to success criteria.
- Assumptions/dependencies: Access to CMS/LMS; stable UI layouts; judge alignment to acceptance rules.
- Transparent auditing and compliance logging for agent actions (policy/compliance)
- Use behavior narratives as standardized, human-readable logs of what changed at each step (action-effects), enabling post hoc auditing and faster dispute resolution.
- Tools/products/workflows: Narrative archive with initial/final screenshots; checklist-based verifications; compliance dashboards.
- Assumptions/dependencies: Policy for storing screenshots and logs; data retention safeguards; redaction for PII.
- Data wrangling and ETL on desktops (software/data)
- Employ Agent S3’s integrated coding agent for programmatic edits (Python/Bash) alongside GUI actions, improving speed on bulk transforms and parsing; select among multiple code/GUI plans via bBoN.
- Tools/products/workflows: Sandboxed code execution; iterable code-then-verify inner loop with budget; narrative-confirmed effects.
- Assumptions/dependencies: VM sandbox; secure execution environment; clear inspection checklist for verification.
- Research benchmarking and method evaluation (academia)
- Adopt behavior narratives for trajectory representation in studies; use bBoN to compare agent policies and ensembles; report pass@N coverage to measure true upper bounds.
- Tools/products/workflows: Open prompts/templates for narrative generation; MCQ comparative judge; failure-mode labeling and analysis pipeline.
- Assumptions/dependencies: Access to benchmarks (OSWorld, WindowsAgentArena, AndroidWorld); compute for multi-rollout experiments.
Long-Term Applications
These applications require further research, scaling, or productization—especially around real-desktop concurrency, shared-resource isolation, judge robustness, and standards.
- Real-desktop wide scaling with side-effect isolation (software/OS platforms)
- Extend bBoN from VMs to live desktops: coordinate concurrent rollouts without interference, manage shared online resources (e.g., shopping carts, email, cloud drives), and enforce isolation of credentials and state.
- Tools/products/workflows: OS-level agent scheduler; “credential multiplexer” for per-rollout accounts; side-effect tracking and rollback.
- Assumptions/dependencies: OS and app vendor support for multi-session isolation; strong state management and rollback APIs.
- Enterprise-grade agent orchestrators integrated with RPA platforms (software/enterprise)
- Embed bBoN and behavior narratives into UiPath/Automation Anywhere/Blue Prism: multi-agent attempts per step or per task with principled selection, narrative-based auditing, and compliance-ready logging.
- Tools/products/workflows: Orchestrator plugins; policy-driven ensemble selection; cost/latency-aware scaling heuristics.
- Assumptions/dependencies: Vendor APIs; governance and cost controls; judge calibration to enterprise acceptance criteria.
- Safety, governance, and standards for “behavior narratives” (policy/standards)
- Establish a cross-industry standard for narrative facts (schemas for action-effects, evidence crops, timestamps), enabling interoperable auditing, risk assessments, and procurement evaluations for agent systems.
- Tools/products/workflows: Standardized narrative format; auditing playbooks; certification programs; benchmark-aligned rubrics.
- Assumptions/dependencies: Multi-stakeholder consensus; privacy-preserving logging; legal safe harbors for storing UI evidence.
- High-stakes automation in regulated sectors (healthcare, finance, public sector)
- Deploy agents for EHR form filling, claims processing, reconciliation, and regulatory filings under bBoN selection to reduce variance and provide strong auditability; narratives aid inspectors and compliance staff.
- Tools/products/workflows: Domain-specific judges and rubrics; role-based VM sandboxes; human-in-the-loop checkpoints.
- Assumptions/dependencies: PII/PHI handling; domain-tuned visual understanding; formal acceptance criteria and audit procedures.
- Robust judge models and training with narrative supervision (academia/ML research)
- Train domain-specific judges on behavior narratives to improve alignment with human evaluation for multi-solution tasks; explore multi-round comparative tournaments, active adjudication, and self-grounded verification.
- Tools/products/workflows: Narrative datasets; judge reliability metrics; agreement-bias mitigation; cross-domain transfer studies.
- Assumptions/dependencies: Curated labels; coverage of multi-path solutions; continual evaluation against human raters.
- Adaptive ensemble selection and cost-aware scaling (software/AI operations)
- Develop policies that choose number of rollouts and model mixtures per task difficulty, balancing success rate against latency and cost; integrate pass@N predictions and uncertainty estimates.
- Tools/products/workflows: Task difficulty classifiers; dynamic budgets; mixture-of-models orchestration; telemetry.
- Assumptions/dependencies: Robust signals for difficulty; cost models; API availability across model vendors.
- Desktop-to-web and industrial HMI extension (software/industrial automation)
- Apply bBoN to web agents and industrial human–machine interfaces: scale solution paths where multiple valid sequences exist, judge by narratives of control actions and state changes.
- Tools/products/workflows: Browser and HMI adapters for pointer overlays and crops; domain-specific judges; safety interlocks.
- Assumptions/dependencies: Access to HMI emulators/test rigs; safety certification; visual grounding for fine-grained displays.
- Consumer OS-level “agent reliability firewall” (software/consumer)
- Ship an OS feature that runs multiple agent attempts behind the scenes, selects the best, and presents a single, verified outcome with a concise narrative; users gain reliability without managing complexity.
- Tools/products/workflows: OS agent orchestrator; UX for narrative confirmation; privacy guardrails.
- Assumptions/dependencies: OS vendor support; on-device or edge compute; local model availability or secure cloud usage.
- Education automation at scale with trustworthy logs (education)
- Manage LMS tasks, grading assistance, and content organization with narrative-backed automation that is reviewable and comparable; educators can inspect what changed and why it was selected.
- Tools/products/workflows: Rubric-driven judges; reviewer dashboards; versioned narratives.
- Assumptions/dependencies: Institutional policies for agent use; content rights; tune judges to pedagogical rules.
In all cases, feasibility hinges on several common dependencies:
- Independent, repeatable initial states (ideally via VM snapshots/emulators).
- Access to capable base models and the option to use mixtures for diversity.
- A reliable visual-language judge aligned with task-specific rubrics and human judgment.
- Security, privacy, and compliance controls for screenshots, logs, and code execution.
- Cost and latency budgets for scaling rollouts, with adaptive policies to balance performance vs. resources.
Glossary
- Ablations: Systematic experiments that remove or alter components to assess their impact on performance. "with comprehensive ablations validating key design choices."
- Agentic framework: A structured system that organizes how an agent perceives, plans, and acts across tools and modalities. "we created an improved baseline agentic framework, Agent S3, which achieves a new SoTA even before incorporation into bBoN."
- Behavior Best-of-N (bBoN): A trajectory-level selection method that generates multiple candidate rollouts and chooses the best using compact behavior summaries. "We introduce Behavior Best-of-N (bBoN), a method that scales over agents by generating multiple rollouts and selecting among them using behavior narratives"
- Behavior Best-of-N Judge: The model component that compares behavior narratives across rollouts to pick the final trajectory. "Behavior Narrative Generator and Behavior Best-of-N Judge."
- Behavior narrative: A concise, stepwise summary of action-effect facts extracted from a trajectory to highlight task-relevant changes. "behavior narratives that describe the agents' rollouts."
- Behavior Narrative Generator: A component that converts raw transitions (before/after screenshots and action) into factual action-effect descriptions. "the Behavior Narrative Generator derives facts from each transition"
- Best-of-N (BoN): A test-time scaling strategy that generates K candidates and selects the best according to a judge or reward. "step-wise BoN \citep{zhu2025scalingtesttimecomputellm}, where at each step the agent generates candidate actions"
- Code-GUI handoff: The coordination boundary where control passes between code execution and GUI manipulation within an agent. "Code-GUI handoff failures (4)."
- Comparative evaluation: Judging multiple candidates side-by-side to decide which is best, rather than scoring them independently. "we instantiate comparative evaluation using a single-round multiple-choice question (MCQ) format"
- Comparative selection: Choosing a winner by directly comparing candidates against each other. "How does comparative selection compare to independent ranking?"
- Flat policy: A non-hierarchical control policy that plans and replans directly at each step without a separate manager layer. "We remove hierarchical planning in favor of a flat policy"
- Graphical user interface (GUI) agent: An agent that perceives and acts on screen-based interfaces using clicks, typing, and other UI interactions. "graphical user interface (GUI) agents"
- Hierarchical planning: A multi-level planning scheme that decomposes high-level goals into subgoals for lower-level policies. "We remove hierarchical planning in favor of a flat policy"
- Long-horizon trajectories: Executions that span many steps, where small errors can accumulate over extended interactions. "Long-horizon trajectories are information-dense"
- Mixture-of-models ensemble: An ensemble strategy that draws candidate rollouts from multiple distinct base models to increase diversity. "How should we select a mixture-of-models ensemble?"
- Partially Observable Markov Decision Process (POMDP): A decision-making formalism where an agent acts under uncertainty with incomplete observations of the true state. "partially observable Markov Decision Process (POMDP)"
- Pass@N: The probability that at least one out of N generated candidates is correct, used as an upper bound on success. "or Pass@N \citep{chen2021evaluatinglargelanguagemodels}."
- Rollout: A sequence of states and actions produced by executing a policy on a task instance from start to finish. "generating multiple rollouts and selecting among them"
- Sandboxed VM: An isolated virtual machine environment used to safely execute code and agent actions without affecting the host system. "to be executed in a sandboxed VM"
- Step-wise scaling: A scaling approach that expands candidates at each decision step and selects locally, as opposed to full-trajectory selection. "GTA1 (step-wise scaling)"
- Stochastic decoding: Sampling-based generation from a model’s distribution to produce diverse candidate trajectories. "sampled via stochastic decoding"
- Test-time scaling: Improving performance by generating multiple candidates at inference time and selecting or refining the output. "is through test-time scaling"
- Trajectory-level BoN: Best-of-N selection applied to whole trajectories, enabling exploration of alternative solution paths before choosing one. "our work investigates the wide scaling approach using trajectory-level BoN"
- Transition function: In an MDP/POMDP, the probabilistic mapping from a state and action to a distribution over next states. " is a stochastic transition function"
- Vision-LLM (VLM): A model that jointly processes images and text, used here for understanding screenshots and judging trajectories. "vision-LLMs (VLMs) as judges"
- Wide scaling: Generating many diverse candidate trajectories in parallel and selecting among them to boost robustness and success. "A natural way to mitigate this fragility is wide scaling:"
- Zero-shot generalizability: The ability to perform well on new domains or tasks without task-specific training data. "strong zero-shot generalizability"
Collections
Sign up for free to add this paper to one or more collections.

