On the Reliability of Computer Use Agents
Abstract: Computer-use agents have rapidly improved on real-world tasks such as web navigation, desktop automation, and software interaction, in some cases surpassing human performance. Yet even when the task and model are unchanged, an agent that succeeds once may fail on a repeated execution of the same task. This raises a fundamental question: if an agent can succeed at a task once, what prevents it from doing so reliably? In this work, we study the sources of unreliability in computer-use agents through three factors: stochasticity during execution, ambiguity in task specification, and variability in agent behavior. We analyze these factors on OSWorld using repeated executions of the same task together with paired statistical tests that capture task-level changes across settings. Our analysis shows that reliability depends on both how tasks are specified and how agent behavior varies across executions. These findings suggest the need to evaluate agents under repeated execution, to allow agents to resolve task ambiguity through interaction, and to favor strategies that remain stable across runs.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “On the Reliability of Computer Use Agents”
What is this paper about?
This paper studies how trustworthy “computer-use agents” are. Think of these agents as smart software helpers that can control a computer like a human would: clicking buttons, typing, browsing the web, and using apps to finish tasks. Many of these agents can complete tough tasks and sometimes even beat humans. But there’s a catch: if you ask the same agent to do the exact same task several times, it might succeed once and fail the next time. The paper asks a simple question: if an agent can do a task once, why can’t it do it reliably every time?
What questions did the researchers try to answer?
The researchers focused on three everyday reasons why performance might bounce around:
- Randomness: Are results unstable because of “luck” or small random factors during execution (like slightly different word choices or tiny visual changes on the screen)?
- Unclear instructions: Are tasks described in a way that is open to multiple valid interpretations, some of which don’t match how the task is graded?
- Different strategies: Even when instructions are clear, do agents pick different plans each time—some sturdy, some fragile—leading to inconsistent results?
How did they study this?
They used a benchmark called OSWorld, which is a collection of realistic computer tasks (like using apps and websites). For each task, they ran the same agent multiple times to see how consistently it succeeded. Then they tried different tweaks to see what helped or hurt reliability.
To keep things understandable, here’s what they measured and tried:
- Measuring reliability (in plain terms):
- Success-once vs. success-every-time:
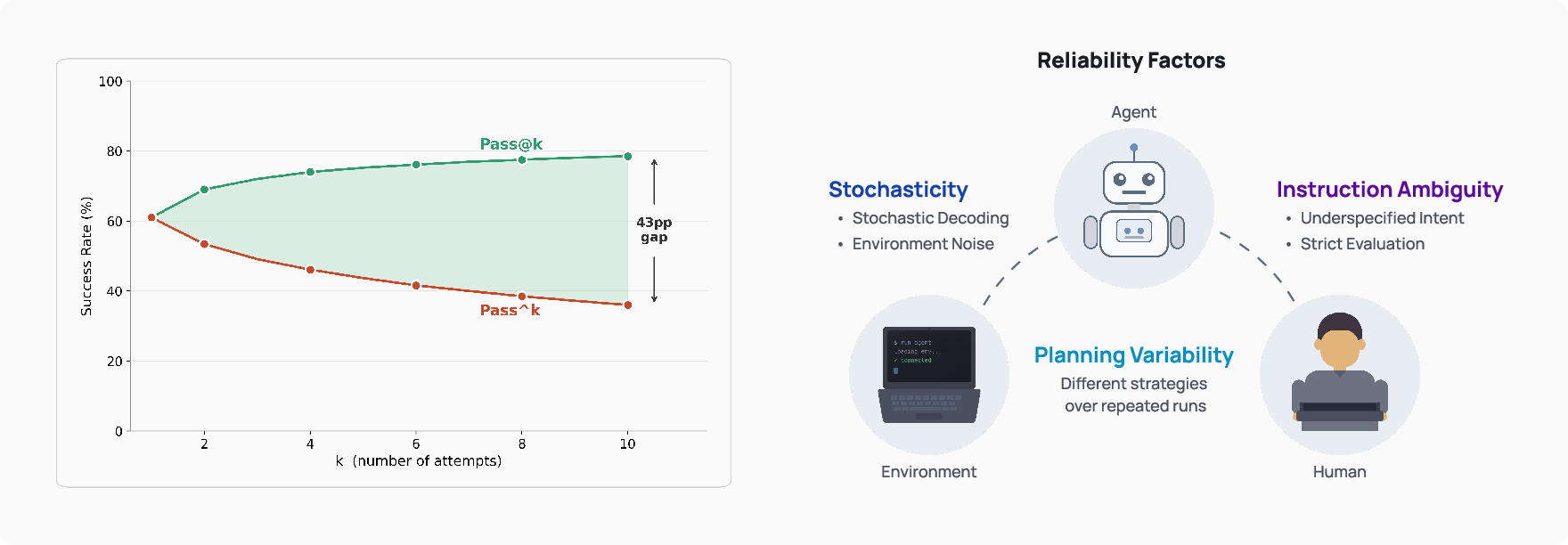
- Pass@k (common in coding): “Did the agent succeed at least once in k tries?” This is good for showing potential, but not reliability.
- Pass{k} (their focus): “Does the agent succeed in all k tries?” This captures true reliability.
- Example: An agent might solve a task at least once in 10 tries (high Pass@10), but only solve it every time across 10 tries for a much smaller fraction of tasks (lower Pass{10}). In one example, about 78% vs. 36%.
- Task-by-task comparisons across settings:
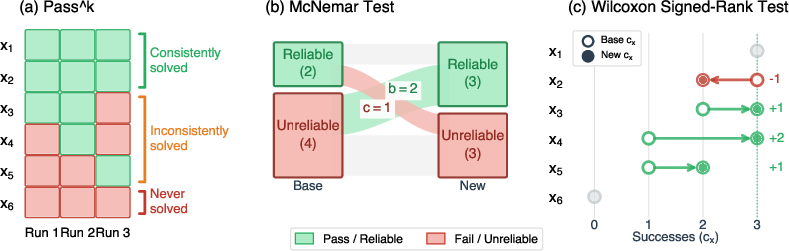
- McNemar test: Think of it as counting how many tasks switched from “always succeed” to “not always” and vice versa when you change something (like making instructions clearer). It tells you whether more tasks improved than got worse.
- Wilcoxon test: This looks at each task’s total number of successful runs (e.g., out of 3 attempts) and checks if those numbers generally go up or down after a change. It can spot small improvements even if a task isn’t perfect yet.
- What they changed (their “interventions”):
- Deterministic decoding: Make the model pick the most likely next step every time (like always choosing the same word), instead of sampling different options.
- Fixed plan: Have the agent create one high-level plan and stick to it for all runs.
- Small environment changes: Add harmless visual tweaks (e.g., tiny UI differences) to see if agents break when the screen looks slightly different.
- 2) Clear up instructions
- Before starting: Rewrite task instructions so the success criteria are very explicit (without giving away the solution).
- During the task: Use a “simulated user” to give targeted feedback when the agent goes off-track, so the agent can correct course on retries.
- 3) Stabilize strategies
- Plan extraction: Run a few attempts, learn what worked (and what failed), and turn that into a better plan for the next run.
- Iterative refinement: Repeat this process to steadily improve the plan over several rounds.
What did they find, and why does it matter?
Here are the main takeaways:
- Randomness isn’t the whole story
- Simply turning off randomness (deterministic decoding) didn’t always improve reliability. For some models, it even made things worse.
- Locking in a single plan made behavior more stable but didn’t consistently solve the reliability problem.
- Small, purely cosmetic changes to the environment (like slightly different visual layouts) often reduced reliability. This shows some agents are fragile: they memorize the exact look of a screen instead of generalizing.
- Clearer instructions help a lot
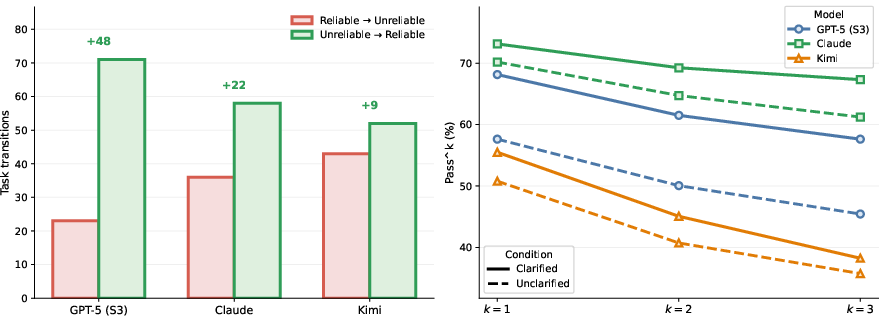
- Rewriting instructions to make success criteria crystal clear improved both one-off success and all-runs success across several models.
- Letting a “user” provide targeted feedback during retries (e.g., “you need to save the file in this folder, not that one”) beat simply retrying without guidance.
- In some cases, a single run with clearer instructions performed as well as or better than multiple blind retries. Bottom line: clarity saves runs.
- Strategy consistency is a big factor
- Agents often succeed using different strategies across runs; some strategies are robust, others are brittle.
- Learning from past attempts (plan extraction) and iteratively refining plans improved reliability for some models (notably GPT-5), but occasionally caused regressions for others if the feedback emphasized the wrong behaviors.
- With careful feedback and more refinement rounds, agents tended to get more reliable, but this depends on the quality of the guidance.
Why this matters: In the real world—think aerospace, cars, medical devices—“sometimes it works” is not good enough. Users and regulators expect the same correct result every time, especially for safety and trust.
What’s the bigger impact?
The paper suggests a mindset shift for building and testing these agents:
- Don’t just ask: “Can it solve the task once?” Instead ask: “Does it solve it every time when we repeat it?”
- Expect ambiguity and plan for it: Let agents ask questions or get feedback during the task, not just rely on a fixed prompt.
- Aim for stable strategies: Encourage agents to find and stick to robust plans that keep working across small changes.
- Blend structure and flexibility: Purely deterministic scripts can be very reliable in fixed conditions but brittle to change; purely flexible agents adapt but can be inconsistent. Combining structured guidance (like plans or simple rules) with adaptable reasoning can give both reliability and resilience.
In short, if we want computer-use agents that people can truly depend on, we need to evaluate them with repeated runs, help them clear up confusion through interaction, and guide them toward strategies that are steady, not just successful once.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues that are concrete and actionable for future research:
- Benchmark scope and generalization:
- Results are confined to OSWorld; it is unclear whether reliability findings transfer to other computer-use benchmarks (e.g., web-only, enterprise software, long-horizon repetitive tasks) or to real user desktops.
- No analysis of reliability variance across task categories (e.g., text editing vs. spreadsheet vs. multi-app workflows); per-category breakdowns could reveal targeted weaknesses.
- Reliability metric design:
- Reliability is operationalized as Pass{k} (all-k succeed) and per-task counts, but no confidence intervals or variance estimates are reported; robust estimation and uncertainty quantification are missing.
- Multiple paired statistical tests are conducted across many settings with no correction for multiple comparisons; false positive risk is unaddressed.
- The “all runs must succeed” criterion is strict; alternatives (e.g., acceptable failure rates, severity-weighted failures, mean time-to-failure) are not explored.
- Dependence across runs (e.g., due to shared plans or caching) is not modeled; Pass{k} estimates may assume independence that does not hold.
- Experimental design and reproducibility:
- The number of tasks, categories, and per-task run counts vary (Pass{3}, Pass@10 shown) without a systematic study of how reliability scales with k or horizon length.
- Environment perturbations are “cosmetic,” but the taxonomy and magnitude of perturbations are unspecified; robustness to functional UI changes (version updates, dynamic content, latency) remains untested.
- Key implementation choices are in appendices (e.g., perturbation procedures, prompts, plan extraction); core reproducibility details are not in the main text.
- API-imposed decoding settings (e.g., GPT-5 at temperature=1) may confound comparisons; a thorough temperature sweep or exploration-exploitation tradeoff is absent.
- Source attribution of failures:
- The paper does not disentangle perception/grounding errors (e.g., vision mis-detections), action execution errors (tooling), planning errors, and evaluation mismatches; targeted ablations to quantify each component’s contribution are missing.
- No systematic error taxonomy beyond the three high-level factors; concrete failure mode categories (e.g., off-by-one selection, window focus, widget misclassification) are not analyzed.
- Determinism vs. adaptability:
- Deterministic decoding and fixed-strategy execution yield mixed effects; the paper does not identify when determinism helps or hurts nor propose criteria for choosing an optimal determinism level.
- The interaction between determinism and environment variability (beyond cosmetic changes) remains unexplored; how to balance stability with adaptability is an open design problem.
- Instruction ambiguity and evaluation mismatch:
- “Clarified” instructions are generated with reference to evaluator scripts, which may leak evaluation criteria and overstate attainable reliability; generalization to real settings without evaluators is unclear.
- Benchmarks and evaluators accepting multiple valid outcomes (equivalence classes) are not considered; current metrics may penalize reasonable alternative interpretations.
- The method assumes that ambiguity can be resolved by textual clarification; tasks requiring preference elicitation or contextual norms are not separately studied.
- User-simulator feedback:
- The LLM-based user simulator’s accuracy, bias, and failure modes are not quantified; reliability gains could reflect simulator idiosyncrasies rather than generalizable improvement.
- Human-in-the-loop comparisons are absent; it is unknown whether simulated feedback approximates realistic user clarifications or whether mixed initiative policies degrade/improve reliability.
- Plan extraction and iterative refinement:
- Plan extraction assumes access to ground-truth success labels; in practice, judges are noisy. The impact of imperfect judges on reliability is not evaluated.
- Only up to two refinement iterations are studied; convergence properties, diminishing returns, and stability over more iterations remain unknown.
- Plans are extracted and reused, but alternatives (e.g., multiple candidate plans, robust plan selection, ensembling across trajectories, or meta-policies) are not compared.
- Model-specific regressions (e.g., Claude’s code-biased strategies) are noted but not resolved with targeted countermeasures; how to align plan extraction with each model’s strengths is open.
- Cost, latency, and safety considerations:
- Reliability improvements via retries and interaction incur additional steps; no analysis of compute/latency/reliability trade-offs or resource budgets is provided.
- Binary success ignores side effects or harmful actions; failure severity and risk-sensitive reliability are not measured (important for regulated domains).
- No discussion of monitoring, rollback, or fail-safe mechanisms to bound worst-case outcomes during repeated runs.
- Training-time interventions:
- All interventions are inference-time; training-time methods to directly optimize for reliability (e.g., objectives penalizing across-run variance, curriculum over perturbations, RL with reliability constraints) are not explored.
- The role of model scale, pretraining data, and multimodal alignment on reliability is not systematically studied (controlled scaling or ablations are absent).
- Theoretical grounding:
- Reliability is defined within a POMDP, but no formal analysis links transition stochasticity, observation noise, or partial observability to empirical Pass{k} behaviors; theoretical reliability bounds or predictors are missing.
- There is no formal framework for task ambiguity (e.g., partial orders over acceptable outcomes) or for quantifying “strategy variability” in a way that predicts reliability.
- Broader validity:
- Real-world deployment constraints (multi-user systems, background processes, permissions, network variability, concurrent apps) are not modeled.
- Long-horizon, multi-session or stateful tasks (where prior runs alter the environment for future runs) are not evaluated; reliability under path-dependent states remains open.
Practical Applications
Immediate Applications
Below are deployable use cases that translate the paper’s findings into concrete workflows, tools, and policies across sectors. Each item includes sectors and key assumptions or dependencies that affect feasibility.
- Reliability audit harness for computer-use agents
- What: Integrate repeated-run evaluation (Pass{k}, McNemar test for reliability transitions, Wilcoxon for per-task consistency) into agent QA and CI/CD. Produce per-task, per-release reliability scorecards.
- Sectors: Software/IT, RPA vendors, QA tooling, enterprise platforms, academia (benchmarks).
- Tools/products/workflows: A “reliability runner” that executes each task n times; statistical analysis module; dashboards and alerting; GitHub Actions/CI plugins.
- Assumptions/dependencies: Access to the task suite and ground-truth evaluation signals; compute budget for repeated runs; stable replay harness for GUI/web tasks.
- Deployment gates and SLAs based on Pass{n}
- What: Set minimum reliability thresholds (e.g., Pass{3} or Pass{5}) as release gates and operational SLAs for agent features.
- Sectors: Finance back office, IT operations, customer support, BPOs, enterprise software.
- Tools/products/workflows: “Go/No-Go” checks in release pipelines; live reliability dashboards; escalation policies if Pass{n} drops.
- Assumptions/dependencies: Agreement on thresholds; reliable telemetry to aggregate outcomes across repeated executions.
- Instruction rewriting/clarification before execution
- What: Automatically rewrite task/runbook instructions to make success criteria explicit (mirroring the paper’s clarified-instruction gains).
- Sectors: RPA, IT runbooks, contact center automations, internal tools, education (LMS workflows).
- Tools/products/workflows: Instruction-clarification service (prompting templates + optional human review); versioned runbooks with “explicit criteria” field.
- Assumptions/dependencies: Access to evaluation criteria or acceptance tests; guardrails to avoid leaking answers or over-specifying beyond task intent.
- Interactive clarification at run time
- What: Add a “clarify with user” or “simulated user feedback” step when an agent detects ambiguity or mismatched outcomes—shown to outperform blind retries.
- Sectors: Enterprise productivity assistants, customer service, internal automation, consumer assistants.
- Tools/products/workflows: Clarification microservice; UX affordances for users to answer targeted questions; fallback to LLM-based user simulators off-hours.
- Assumptions/dependencies: Availability of end users or high-quality domain simulators; privacy/compliance for sharing context with simulators.
- Retry-with-clarify workflow
- What: Replace blind retries with targeted feedback on failure (e.g., “Retry (Clarify)” vs “Retry (Binary)”), improving repeated-run success.
- Sectors: Web automation, e-commerce support, IT ticket resolution, form-filling automations.
- Tools/products/workflows: Failure analysis hooks; targeted prompt augmentations; up to k guided retries before escalation.
- Assumptions/dependencies: Detectable failure signals (assertions, validators); cost budget for additional attempts.
- Plan extraction and reuse
- What: After first executions, extract a high-level plan (steps, pitfalls, known-good actions) and reuse it to stabilize future runs on the same task.
- Sectors: Helpdesk automations, enterprise internal tools, back-office workflows, QA test execution.
- Tools/products/workflows: “Plan cache”/playbook memory; behavior narrative logging; plan selector by context fingerprint (URL/app/version).
- Assumptions/dependencies: Accurate plan extraction from trajectories; environment similarity between runs; storage and retrieval infra.
- Iterative plan refinement with failure memory
- What: Collect feedback across multiple runs (successes and failures) to refine plans iteratively, reducing planning variability and improving Pass{n}.
- Sectors: Agent platforms, orchestration frameworks, continuous improvement programs.
- Tools/products/workflows: Behavior judge module; failure pattern mining; plan refiner that updates shared playbooks over time.
- Assumptions/dependencies: Reliable success/failure judgments; safeguards against reinforcing brittle plans; human review in sensitive domains.
- Environment perturbation testing (“UI fuzzing for agents”)
- What: Test agents against non-functional UI variations (theme, font, layout padding, color), since the paper shows such noise can degrade reliability.
- Sectors: QA automation, browser automation vendors, OS/app integrators.
- Tools/products/workflows: Perturbation generators; A/B runs (baseline vs perturbed); regression triage on sensitivity hotspots.
- Assumptions/dependencies: Ability to inject cosmetic perturbations safely; observability to tie failures to visual or DOM changes.
- Decoding-profile selection (deterministic vs stochastic)
- What: Profile reliability across decoding temperatures and “strategy determinism” to pick per-task defaults that maximize Pass{n}.
- Sectors: Agent platforms, MLOps for LLM agents.
- Tools/products/workflows: Temperature sweeps; plan-determinism toggles; auto-selection policies per task/app.
- Assumptions/dependencies: Model APIs that expose decoding controls; awareness that determinism can hurt robustness under small variations.
- Reliability-aware procurement and vendor evaluation
- What: Require repeated-run metrics (Pass{n}, McNemar/Wilcoxon analyses) in RFPs and vendor scorecards for agentic tools.
- Sectors: Public sector procurement, enterprise IT, regulated industries.
- Tools/products/workflows: RFP templates; evaluation protocols; comparative reliability matrices per task class.
- Assumptions/dependencies: Agreement on standardized task suites and thresholds; third-party evaluators or internal labs.
- Academic benchmark upgrades
- What: Update benchmarks to include repeated-run evaluation, clarified instructions, and interactive clarification phases with user simulators.
- Sectors: Academia, open-source communities.
- Tools/products/workflows: Leaderboards reporting Pass{1}, Pass{n}; paired tests for task-level transitions; clarified-instruction corpora.
- Assumptions/dependencies: Open licensing for task definitions; reproducible environments (e.g., OSWorld-like setups).
- Consumer assistant reliability UX
- What: Surface “reliability indicator” badges for workflows the agent has repeatedly succeeded at; ask clarifying questions when confidence/reliability is low.
- Sectors: Consumer productivity, personal automation.
- Tools/products/workflows: Reliability scoring per routine; user notifications and one-tap clarifications.
- Assumptions/dependencies: Opt-in telemetry; non-intrusive UX; lightweight repeated trials during setup or on-device simulation.
Long-Term Applications
These applications require additional research, scaling, or ecosystem maturation before broad deployment.
- Certification frameworks for agent reliability
- What: Formalize reliability thresholds and test protocols (e.g., Pass{n} at set k, perturbation suites) as evidence for standards (e.g., DO-178C, IEC 61508, ISO 26262, IEC 62304, regulated AI).
- Sectors: Aerospace, automotive, medical software, critical infrastructure.
- Tools/products/workflows: Auditable reliability test batteries; assurance cases linking reliability metrics to hazard analyses.
- Assumptions/dependencies: Regulator acceptance; mappings from tasks to safety classes; third-party accredited labs.
- Symbolic–stochastic hybrid agent architectures
- What: Combine symbolic plans (for structure and determinism) with stochastic LLM control (for adaptation to UI drift), as suggested by the paper’s discussion.
- Sectors: Enterprise automation, high-reliability IT, finance ops.
- Tools/products/workflows: DSLs or statecharts for plans; runtime adapters that allow controlled stochasticity.
- Assumptions/dependencies: Mature program synthesis/execution layers; robust grounding between symbolic plans and UI.
- Domain-calibrated user simulators for clarification
- What: Build specialized simulators (healthcare, finance, legal) that deliver targeted, safe clarifications during execution.
- Sectors: Healthcare (EHRs, claims), finance (reconciliation, KYC), public services.
- Tools/products/workflows: Simulator training on domain policies; safety filters; context-limited clarifications.
- Assumptions/dependencies: Access to domain data and SMEs; privacy and security constraints; evaluation of simulator fidelity.
- Active preference elicitation at scale
- What: Agents that proactively elicit preferences and disambiguate goals (active learning of user intent) to improve repeated-run reliability.
- Sectors: Consumer assistants, enterprise productivity, education.
- Tools/products/workflows: Preference profiles; adaptive questioning strategies; longitudinal learning across tasks/users.
- Assumptions/dependencies: User consent; UX acceptance of questions; storage and governance of preference data.
- Training-time objectives for reliability
- What: Fine-tune agents to optimize repeated-run success (e.g., reward stable strategies, penalize brittle ones); include plan consistency in loss functions.
- Sectors: Foundation model providers, agent vendors.
- Tools/products/workflows: Offline rollouts with repeated-run labels; RL/IL pipelines targeting Pass{n}; counterfactual data augmentation with perturbations.
- Assumptions/dependencies: Cost of collecting repeated-run datasets; reproducible environments; robust reward signals.
- Cross-environment robustness and invariance
- What: Train and evaluate agents to be robust to non-functional UI changes (themes, resolutions, minor layout shifts) without manual re-tuning.
- Sectors: Browser automation, enterprise apps with frequent UI updates, multi-tenant SaaS.
- Tools/products/workflows: Augmented training with perturbations; perception modules that learn UI-invariant features; synthetic UI generators.
- Assumptions/dependencies: Scalable perturbation pipelines; risk of shortcut learning; benchmarks capturing real-world UI drift.
- Reliability-centered benchmarks and leaderboards
- What: Community-wide pivot to reliability-first metrics (Pass{n}, task-level transition stats) and multi-iteration trials with plan refinement and clarification.
- Sectors: Research community, open-source ecosystems.
- Tools/products/workflows: Public leaderboards; challenge tracks for ambiguity resolution and planning stability.
- Assumptions/dependencies: Shared task suites; compute sponsorship for repeated runs; standardization of statistical reporting.
- OS and app APIs for agent observability and stability
- What: Platform-level affordances to reduce partial observability and state ambiguity (e.g., stable selectors, declarative intents, state snapshots).
- Sectors: OS vendors, productivity suites, enterprise app platforms.
- Tools/products/workflows: Accessibility and automation APIs exposing semantic UI state; traceable state transitions for agents.
- Assumptions/dependencies: Vendor buy-in; security considerations; backward compatibility.
- Reliability provenance and privacy-preserving audit trails
- What: Secure logs and proofs that an agent meets reliability requirements, with redaction and differential privacy for sensitive contexts.
- Sectors: Finance, healthcare, government.
- Tools/products/workflows: Tamper-evident logs; selective disclosure for audits; data minimization policies.
- Assumptions/dependencies: Cryptographic infrastructure; regulatory alignment on acceptable evidence formats.
- Safety-case linking of reliability metrics to risk
- What: Connect repeated-run reliability to system-level risk models (fault trees, FMEA), guiding where agents can operate autonomously vs with oversight.
- Sectors: Safety-critical systems, industrial automation, transportation.
- Tools/products/workflows: Model-based systems engineering integrations; automated generation of safety-case artifacts from reliability data.
- Assumptions/dependencies: Mature hazard modeling; data pipelines from agents to safety tools; domain-specific acceptance criteria.
Notes on feasibility across all applications
- Ambiguity resolution depends on high-quality user input or simulators; simulator fidelity and safety constraints are critical.
- Plan extraction and refinement require accurate success/failure judgments (“Behavior Judge” quality); human-in-the-loop may be necessary initially.
- Determinism can reduce adaptability; robustness must be validated under environmental perturbations.
- Repeated-run evaluations incur compute costs; sampling strategies and task selection must be optimized.
- Data governance, privacy, and compliance requirements may limit logging and simulator interactions in sensitive domains.
These applications collectively operationalize the paper’s core insights: evaluate agents via repeated runs, resolve instruction ambiguity dynamically, and reduce planning variability through plan reuse and refinement—while recognizing that pure determinism is insufficient and robustness to environment variation is essential.
Glossary
- Action space: The set of permissible actions an agent can take in an environment. "𝒜 is the action space of the agent (e.g. and $agent.type(...))"
- Batch-invariant inference: An inference setup designed so outputs do not depend on other examples in the batch, aiding determinism. "deterministic decoding with temperature 0 and batch-invariant inference."
- Behavior Judge: A component that evaluates trajectories to generate feedback about agent behaviors. "We modify the Behavior Judge \cite{agents3} to generate feedback over behavior narrative representations of trajectories."
- Best-of-N: An evaluation setting that reports the best outcome over N attempts, rather than consistency across attempts. "single-run, averaged multi-run, or Best-of-N settings do not capture how reliably agents behave on repeated runs of each individual task"
- Clarified instructions: Task descriptions rewritten to make success criteria explicit and reduce ambiguity. "a single execution with clarified instructions from Section~\ref{sec:clarification} can match or exceed the performance of Retry (Binary)"
- Deterministic decoding: Inference with fixed randomness (e.g., temperature 0) to produce the same output given the same input. "comparing a stochastic decoding baseline to deterministic decoding with temperature 0 and batch-invariant inference."
- Environment perturbations: Controlled changes to observations (often cosmetic) used to test robustness without altering task correctness. "controlled environment perturbations, which introduce non-functional variations in observations to evaluate how reliability changes under these variations."
- Grounding: The linkage between model outputs and concrete actions or references in the environment. "adopt the Agent S3 \citep{agents3} settings for action space and grounding"
- Ground-truth signals: Trusted labels or indicators of correctness used to assess outcomes without ambiguity. "We assume access to ground-truth signals to label rollout task success to avoid confounds from imperfect judge signals."
- Instruction reward function: A function that maps a trajectory (and instruction) to a scalar indicating task success or quality. " denotes the instruction reward function that assigns a scalar reward to a trajectory"
- Iterative plan refinement: A process of repeatedly updating an execution plan using feedback from prior runs to improve reliability. "Reliability metrics across iterations of plan extraction and iterative plan refinement."
- McNemar’s test: A statistical test for paired nominal data used to detect changes between two conditions on the same items. "We apply McNemarâs test~\citep{mcnemar} to paired outcomes ."
- Observation space: The set of all possible observations an agent can receive (e.g., screenshots). "𝒪 is the observation space such as desktop screenshots,"
- OSWorld: A benchmark/environment for evaluating computer-use agents on real computer tasks. "We analyze these factors on OSWorld using repeated executions of the same task together with paired statistical tests that capture task-level changes across settings."
- Paired statistical tests: Tests that compare outcomes on the same items across two conditions to assess significant changes. "together with paired statistical tests that capture task-level changes across settings."
- Partially observable Markov Decision Process (POMDP): A framework modeling decision-making with hidden states and observations. "we model task execution as a partially observable Markov Decision Process (POMDP) defined as "
- Pass@k: A metric that checks if at least one of k attempts succeeds, emphasizing capability over reliability. "Metrics such as Pass@k \citep{chen2021codex} measure whether an agent can succeed at least once across multiple attempts"
- Pass{1}: The marginal success rate across executions (single-run success probability). "Pass{1}, the marginal success rate across executions, given by $\text{Pass{1} = \mathbb{E}_{x \sim \mathcal{X} \left[ \frac{c_x}{n} \right]$"
- Pass{k}: A repeated-run success metric estimating the probability that k runs of the same task all succeed. "More recent work introduces repeated-run success metrics such as Pass{k} \citep{yao2024tau}"
- Pass{n}: The fraction of tasks that succeed on all n repeated executions, directly measuring reliability. "Pass{n}, the fraction of tasks that succeed on all repeated executions, given by $\text{Pass{n} = \mathbb{E}_{x \sim \mathcal{X} \left[ \mathbf{1}[c_x = n] \right]$"
- Policy: The agent’s decision-making function mapping states or observations to actions. "For each task , we execute the policy times, yielding binary outcomes "
- Repeated-run success: Performance consistency across multiple executions of the same task. "Pass{k} (repeated-run success) estimates the probability that executions of a task succeed, averaged across tasks."
- Rollout: A complete execution trajectory generated by running the policy on a task. "we perform multiple rollouts of the same task and extract structured feedback from these trajectories"
- State space: The set of all possible environment states. "𝒮 is the state space encoding the computer state,"
- Stochastic transition function: A probabilistic mapping from state-action pairs to next-state distributions. " is a stochastic transition function,"
- Strategy determinism: Constraining the agent to follow a fixed high-level plan across runs to reduce variability. "Qwen (S3) & Strategy Determinism & 0.313 & 0.219 & -1 & -0.047"
- Temperature-0 decoding: Sampling-free decoding (zero temperature) that eliminates token-level randomness. "agent-side determinism, which removes variability in both token sampling and strategy by using temperature-0 decoding with batch-invariant inference"
- User simulator: An automated component that plays the role of a user to provide feedback or clarifications during execution. "providing feedback during execution using an LLM-based user simulator"
- Wilcoxon signed-rank test: A nonparametric paired test comparing median differences, used to detect consistency changes. "apply the Wilcoxon signed-rank test~\citep{wilcoxon}"
Collections
Sign up for free to add this paper to one or more collections.