- The paper introduces a hybrid agentic framework that combines coding actions with GUI manipulation to enhance efficiency and reduce errors in task automation.
- It employs a multi-agent system with an Orchestrator, Programmer, and GUI Operator to dynamically delegate tasks based on their specific requirements.
- Experimental results on the OSWorld benchmark reveal significant improvements in success rates and step efficiency compared to traditional GUI-only agents.
CoAct-1: Computer-using Agents with Coding as Actions
Motivation and Background
The automation of computer tasks by autonomous agents has traditionally relied on GUI-based interaction, leveraging vision-LLMs (VLMs) to interpret and manipulate graphical interfaces. While this paradigm has enabled progress in open-ended task completion, it is fundamentally limited by the brittleness and inefficiency of long-horizon GUI action sequences. GUI agents are susceptible to visual grounding ambiguity, error accumulation over extended workflows, and the inherent constraints of pixel-level interaction. Recent modular approaches have introduced hierarchical planners to decompose tasks, but execution remains bottlenecked by GUI manipulation, leaving high-level planning disconnected from robust low-level control.
CoAct-1 introduces a hybrid agentic framework that augments GUI-based actions with direct programmatic execution, expanding the agent's action space to include coding (Python/Bash) as a first-class modality. This design enables agents to bypass inefficient GUI workflows for tasks amenable to scripting, while retaining GUI interaction for tasks requiring visual grounding or human-like manipulation.
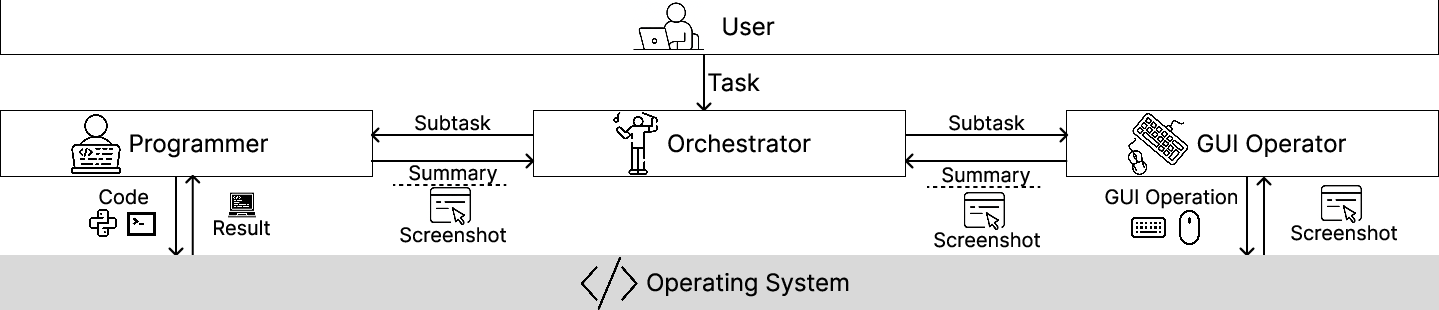
Figure 1: Multi-agent system design for CoAct-1, featuring an Orchestrator, Programmer, and GUI Operator.
System Architecture
CoAct-1 is instantiated as a multi-agent system comprising three specialized agents:
- Orchestrator: Serves as the central planner, decomposing user goals into subtasks and dynamically delegating execution to either the Programmer or GUI Operator based on subtask characteristics.
- Programmer: Executes backend operations by generating and running Python or Bash scripts, interfacing with the OS via a remote code interpreter. The Programmer operates in multi-round dialogue with the code interpreter, iteratively refining scripts based on execution feedback.
- GUI Operator: A VLM-based agent that performs frontend actions (mouse, keyboard) via GUI manipulation, interacting with the OS through a GUI action interpreter.
The agents maintain isolated conversation histories, with the Orchestrator aggregating summaries and screenshots from completed subtasks to inform subsequent planning. This separation ensures focused reasoning and prevents cross-agent contamination of context.
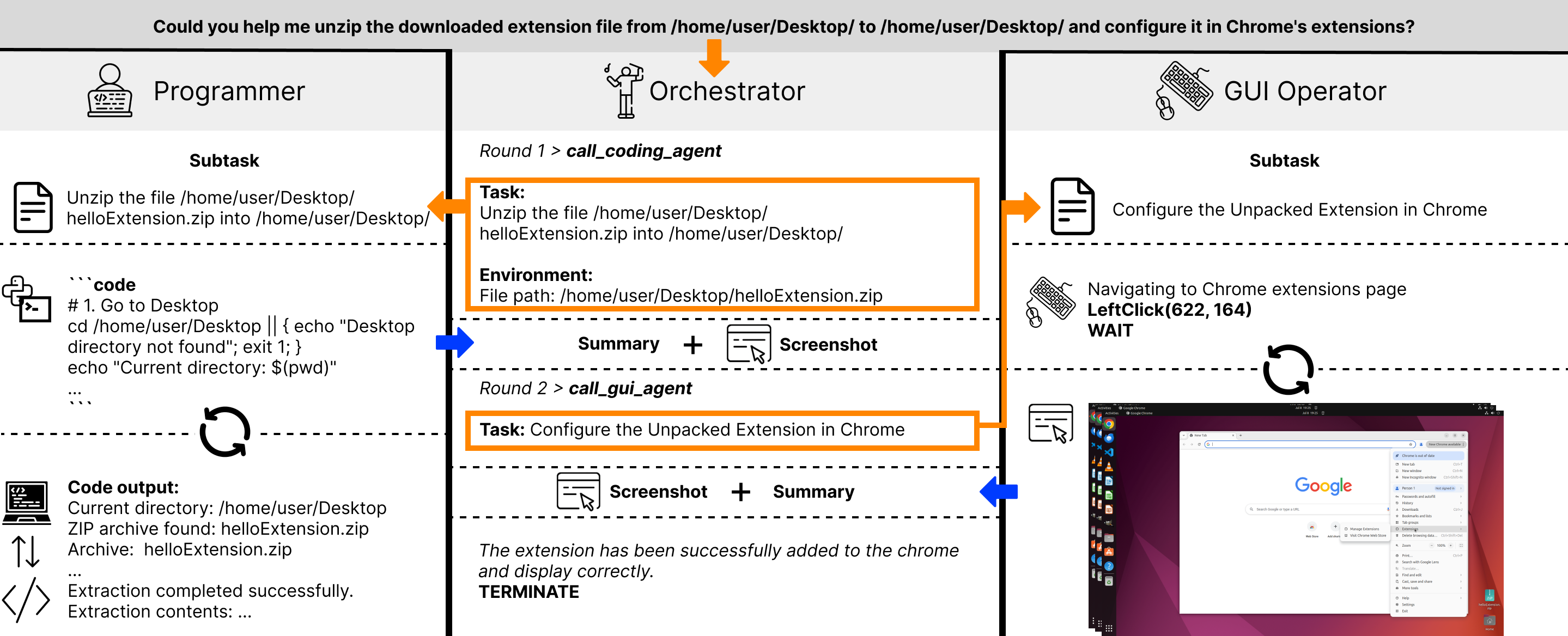
Figure 2: CoAct-1 workflow: Orchestrator delegates subtasks to Programmer (coding) or GUI Operator (GUI actions) based on task requirements.
Implementation Details
CoAct-1 is implemented atop the AG2 multi-agent orchestration framework, with backbone models selected for each agent to optimize performance:
- Orchestrator: OpenAI o3 or o4-mini, selected for strong planning and reasoning capabilities.
- Programmer: o4-mini, chosen for code generation and iterative refinement.
- GUI Operator: OpenAI CUA 4o, a VLM finetuned for computer use.
The system interfaces with the OSWorld benchmark via an extended RESTful server, supporting remote code execution and GUI action interpretation. Task budgets are enforced via step limits (max rounds for each agent), with the overall system capped at 375 interactions per task.
Experimental Evaluation
Benchmark and Baselines
CoAct-1 is evaluated on the OSWorld benchmark, which comprises 369 tasks spanning productivity tools, IDEs, browsers, file managers, and multi-app workflows. Baselines include OpenAI CUA 4o, GTA-1, UI-TARS, and other state-of-the-art agentic frameworks.
- Success Rate: Boolean task completion as determined by rule-based evaluators.
- Efficiency: Average number of steps required for successful task completion.
- Error Rate: Distribution of failures as a function of total actions.
Results
CoAct-1 establishes a new state-of-the-art on OSWorld, achieving a success rate of 60.76% in the 100+ step category, outperforming GTA-1 (53.10%) and OpenAI CUA 4o (31.40%). The system demonstrates pronounced gains in domains where programmatic control is advantageous, such as Calc (70.21%), VSCode (78.26%), and multi-app workflows (47.88%).
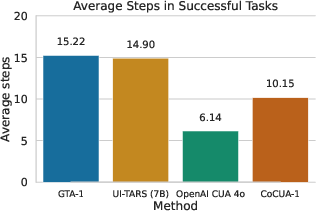
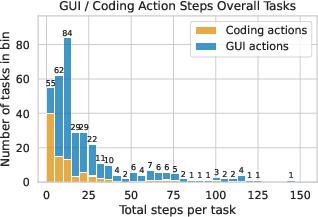
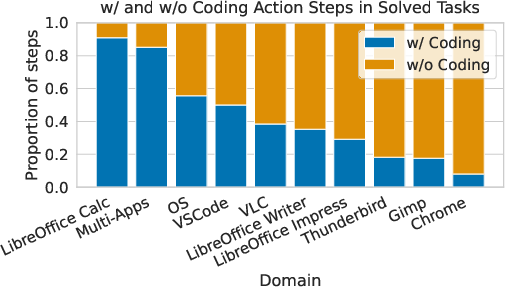
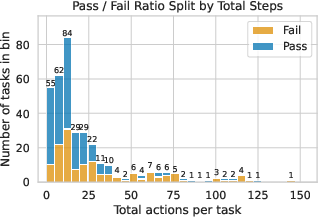
Figure 3: CoAct-1 achieves lower average steps per successful task compared to previous SOTA agentic frameworks, with higher accuracy than OpenAI CUA 4o.
Efficiency analysis reveals that CoAct-1 solves tasks in an average of 10.15 steps, compared to 15.22 for GTA-1 and 14.90 for UI-TARS. While OpenAI CUA 4o averages fewer steps (6.14), its success rate is substantially lower, indicating that CoAct-1's efficiency is coupled with greater robustness.
Additional ablation studies show that backbone selection for the Orchestrator and Programmer agents significantly impacts performance, with the best results obtained by pairing a powerful vision-centric GUI Operator (CUA 4o) with an upgraded Programmer (o4-mini).
Analysis and Discussion
Action Modality and Error Reduction
The hybrid action space enables CoAct-1 to strategically select between coding and GUI actions, reducing the total number of steps and minimizing error propagation. Coding actions are particularly effective in domains requiring batch operations, file management, and data processing, where a single script can replace a lengthy sequence of GUI manipulations. Empirical analysis shows a positive correlation between total actions and error rate, underscoring the importance of step minimization for reliability.
Failure Modes
Case studies highlight two primary sources of failure: high-level queries requiring conceptual inference beyond explicit instructions, and ambiguous queries lacking sufficient detail for disambiguation. These failures point to limitations in current LLM reasoning and context interpretation, suggesting avenues for future research in intent inference and context augmentation.
Practical and Theoretical Implications
CoAct-1 demonstrates that expanding the agentic action space to include coding yields substantial gains in both efficiency and reliability for computer automation. The multi-agent architecture facilitates modularity, enabling targeted improvements to individual agents (e.g., upgrading the Programmer for better code synthesis). The approach is scalable to heterogeneous environments and can be extended to support additional modalities (e.g., API calls, system-level hooks).
From a theoretical perspective, CoAct-1 provides evidence that hybrid action spaces mitigate the brittleness of pure GUI-based agents and enable more generalized, robust automation. The dynamic delegation mechanism implemented by the Orchestrator is a promising direction for adaptive agentic systems capable of reasoning about action modality selection.
Future Directions
Potential future developments include:
- Integration of more advanced LLMs for improved intent inference and ambiguity resolution.
- Extension to additional programming languages and system interfaces.
- Incorporation of self-evolutionary reinforcement learning for agent specialization.
- Application to broader domains beyond OS-level automation, such as web-based workflows and cloud environments.
Conclusion
CoAct-1 advances the state-of-the-art in computer-using agents by introducing coding as a core action modality, synergistically combining programmatic execution with GUI manipulation. The multi-agent system achieves superior performance and efficiency on the OSWorld benchmark, validating the efficacy of hybrid action spaces for generalized computer automation. The results suggest that future agentic frameworks should prioritize flexible action spaces and dynamic delegation to maximize robustness and scalability.

