- The paper introduces APEIRIA, a framework that distills structured NS3D reasoning traces into 3D multi-modal LLMs using a three-stage curriculum.
- It demonstrates state-of-the-art results in spatial reasoning and visual grounding by combining perception alignment, symbolic chain-of-thought supervision, and reinforcement learning.
- Its modular design decouples planning from perception, enabling scalable updates and transparent debugging in embodied AI applications.
Distilling Neuro-Symbolic Programs into 3D Multi-modal LLMs: An Expert Synthesis
Motivation and Problem Setting
Spatial reasoning in 3D environments is foundational to embodied AI but remains limited by an apparent dichotomy in contemporary architectures. Neuro-symbolic 3D (NS3D) systems, leveraging modular programmatic reasoning, exhibit systematic, interpretable logic but cannot scale to open-vocabulary concepts or complex natural language, and require exhaustive procedural supervision. Conversely, 3D multi-modal LLMs (3D MLLMs) possess impressive semantic flexibility but function as black-box regressors, lacking transparent, stepwise reasoning or explicit spatial verification.
The work introduces APEIRIA, a neuro-symbolic 3D MLLM architecture that distills structured symbolic reasoning programs into chain-of-thought (CoT) for object-centric 3D MLLMs. This process aims to unify interpretable, compositional inference with open-set, natural language understanding in 3D spatial reasoning and to decouple concept grounding from reasoning pattern acquisition.
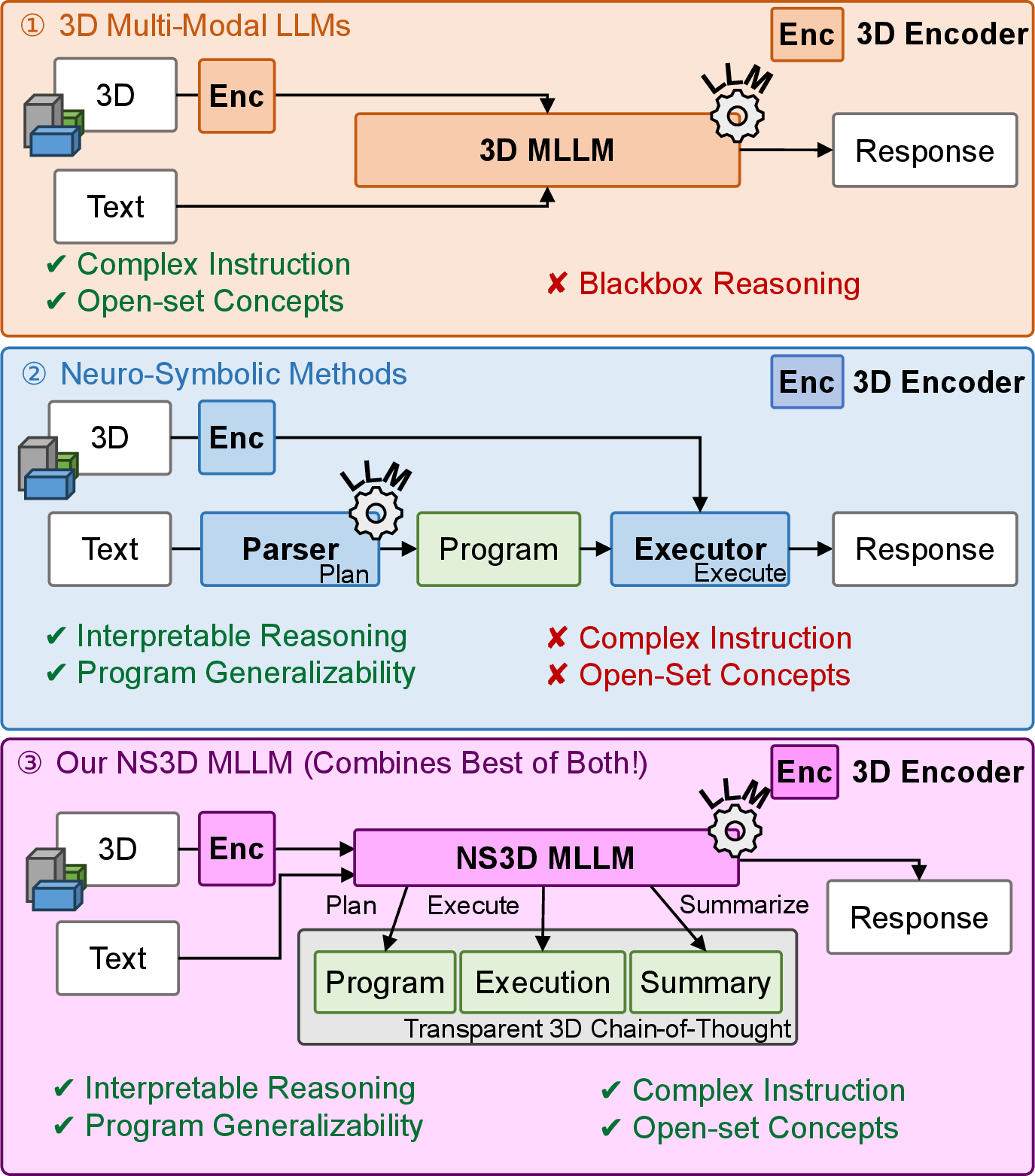
Figure 1: Conceptual depiction of bridging 3D MLLMs’ black-box semantic flexibility and NS3D programmatic transparency by distilling reasoning traces from symbolic programs into MLLMs' CoT.
Methodology: Progressive Curriculum-based Reasoning Distillation
The core technical innovation is a three-stage curriculum that injects NS3D rigor into MLLMs while leveraging their scalable semantics:
- Perception Alignment: Align object-centric 3D visual-geometric features with the MLLM's language embedding space. The model is pretrained on object recognition, localization, and captioning tasks, yielding a semantic grounding foundation.
- Symbolic Reasoning Injection (CoT-SFT): Distill programmatically structured reasoning traces (plans/executions) from verified NS3D programs to the MLLM via supervised chain-of-thought fine-tuning. Execution traces explicitly present ground-truth intermediate states with object IDs and geometry, directly teaching systematic spatial logic decomposition and verification.
- Open-Set and Complex Reasoning Generalization (CoT-RL): Expand the model’s capacity to reason about real-world, open-vocabulary queries lacking stepwise supervision using chain-of-thought RL. Group Relative Policy Optimization (GRPO) is used with composite rewards, enforcing both spatial outcome correctness (location/size similarity over sparse IoU metrics) and interpretability constraints (format validity).
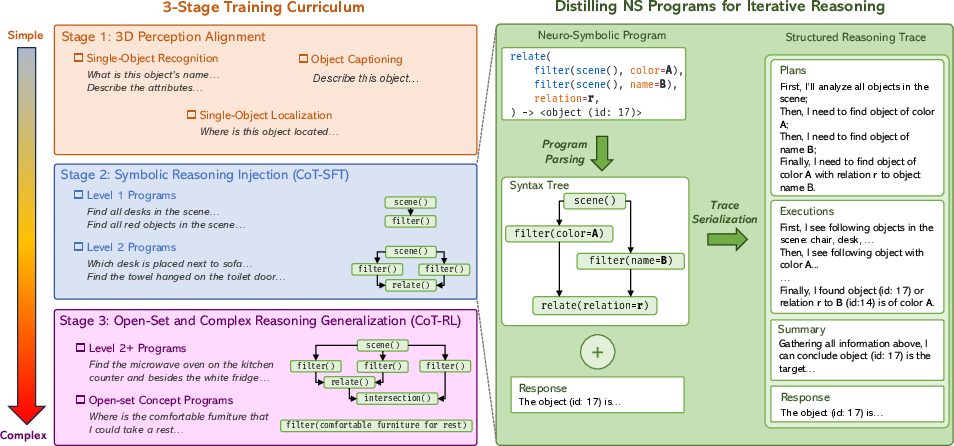
Figure 2: Schematic of the three-phase curriculum: perception grounding, symbolic reasoning distillation via CoT-SFT, and RL-driven extension to open-set, complex queries.
The object-centric scene representation encodes each instance with visual (Uni3D, DINOv2) and spatial (lattice-based positional embeddings) features, interleaved with natural language tokens, maintaining architectural simplicity and computational efficiency (400 tokens vs. 10k–40k of video-centric models).
Modular Neuro-Symbolic Inference
APEIRIA's architecture preserves a hard separation between planning and execution. This enables:
- Plan injectivity—external, possibly more powerful planners (e.g., SGLang, GPT-4) can provide decomposition traces, which the MLLM then executes visually and spatially;
- Perception module replacement—the execution component for perception can be swapped out for state-of-the-art instance segmentation models (e.g., SegDINO3D) without retraining, providing scalability as better detectors become available.
This modularity ensures future-proof upgradability and robust error analysis, as any failure can be directly attributed to the planning or perception branch.
Experimental Results
APEIRIA achieves state-of-the-art results across multiple 3D spatial reasoning, QA, and captioning datasets:
- Spatial Reasoning/3D Visual Grounding: On ScanRefer and Multi3DRefer, APEIRIA achieves 58.4% [email protected] and 59.2% [email protected], respectively—outperforming prior SOTA 3D MLLMs and NS3D methods.
- Open-set Transfer: In zero-shot evaluation on Nr3D (natural instructions, unseen concepts), APEIRIA (trained only on synthetic Sr3D programs) surpasses a fully-supervised NS3D baseline by +2.6%, empirically validating concept generalization via MLLM semantics.
- Cross-task Generalization: On Scan2Cap (dense captioning) and SQA3D (situated QA), the model matches or outperforms specialist methods, by simply swapping RL objectives for each downstream task without re-engineering the core symbolic pipeline.
APEIRIA shows greater RL-driven improvements for long, compositional queries, where symbolic CoT supervision alone is unavailable, confirming the RL benefit for complex spatial inferential chains.
Emergent Reasoning Patterns
Qualitative analyses reveal that beyond the fixed symbolic templates injected during supervised distillation, CoT-RL enables the model to:
- Dynamically compose logical primitives (e.g., intersection, union) for nested or conjunctive constraints.
- Adapt symbolic primitives—e.g., filter() and relate()—to open-vocabulary predicates, reflecting the VLM’s integrated semantic knowledge.
This emergent behavior demonstrates that reasoning patterns, not just symbolic program templates, are internalized and transferable.
Implications and Future Directions
APEIRIA breaks the trade-off between interpretability and open-vocabulary flexibility in 3D scene understanding. The modular neuro-symbolic pipeline decouples planning from execution, supporting continual upgrades as new LLMs and visual detectors are published. Its design enables transparent debugging and supports scalable reasoning in embodied agents—critical for trust, deployment, and diagnostics in safety-critical applications.
However, limitations persist: overall accuracy is fundamentally bounded by the quality of the 3D perception system; reasoning fidelity for very deep logical nesting and for physical-causal inference remains limited. The paradigm's extension to non-indoor or navigation domains would require expanding the program primitive set and empirical validation.
Conclusion
APEIRIA offers a principled framework for injecting systematic, interpretable reasoning from NS3D programs into the flexible, open-world semantics of 3D MLLMs. The proposed curriculum distillation and modular inference set a unified standard for transparent, robust 3D spatial reasoning in large-scale language-vision models, supporting scalable, interpretable embodied agents. The results empirically demonstrate not just performance gains but the practical integration of symbolic logic with deep-seated learned semantics—paving the way for future advancements in flexible, verifiable 3D scene reasoning (2606.01215).

