- The paper introduces explicit 3D representations that enable coherent multi-stage spatial reasoning, outperforming current models on benchmark tasks.
- The paper employs a multi-stage training strategy combining supervised fine-tuning and reinforcement learning, achieving a mean accuracy of 60.3% on 3DSRBench.
- The paper outlines future directions for integrating explicit 3D representations in robotics and augmented reality to enhance real-world spatial reasoning.
SpatialReasoner: Towards Explicit and Generalizable 3D Spatial Reasoning
Introduction
The quest for improved large vision-LLMs (LVLMs) that proficiently handle 3D spatial reasoning drives current research at the intersection of computer vision and natural language processing. "SpatialReasoner: Towards Explicit and Generalizable 3D Spatial Reasoning" proposes an innovative approach that leverages explicit 3D representations for coherent multi-stage spatial reasoning, outperforming both open-source and proprietary models in benchmark evaluations. This model addresses the persistent challenges in 3D spatial reasoning, particularly the intricate tasks of decomposing complex scenarios and performing accurate computations to arrive at reliable answers.
Explicit 3D Representations
To facilitate robust 3D spatial reasoning, SpatialReasoner utilizes explicit 3D representations as a central interface, thus transcending the limitations of previous models that relied on implicit reasoning via natural language alone. This approach permits precise intermediate results for object locations and orientations, serving as a foundation for accurate spatial computations (Figure 1).

Figure 1: Overview of our SpatialReasoner design. Our SpatialReasoner adopts explicit 3D representations as an interface to enable coherent and reliable multi-stage spatial reasoning, i.e., 3D parsing, computation, and reasoning.
The explicit representations are defined within a calibrated camera 3D space, simplifying the process of reasoning about spatial relationships by aligning the z-coordinates with object heights and reducing complexities in the spatial relationships to manageable 2D problems (Figure 2).
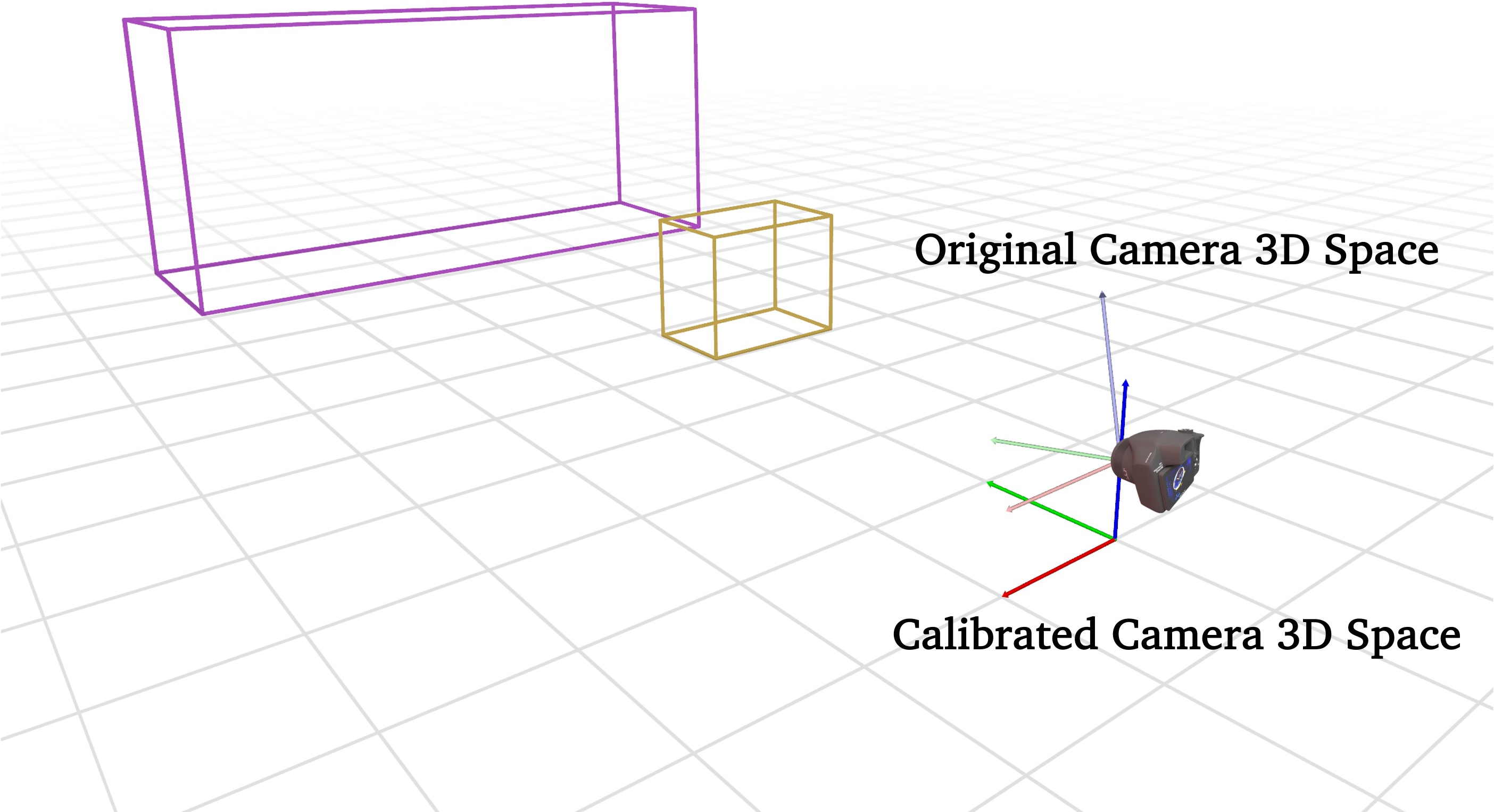
Figure 2: Comparison between original and calibrated camera 3D space. Our explicit 3D representations are defined within calibrated camera 3D space that simplifies subsequent 3D computations.
Multi-stage Training Strategy
SpatialReasoner employs a multi-stage training strategy to instill these representations in the LVLM, starting with supervised fine-tuning (SFT) to initialize the model and impart basic 3D perception and computation capabilities. The subsequent stage employs reinforcement learning (RL) to enhance the robustness and generalizability of the model's spatial reasoning abilities (Figure 3).

Figure 3: Overview of our SpatialReasoner training. We adopt a multi-stage training strategy: In Stage I, we apply supervised fine-tuning (SFT) to equip the LVLM with explicit 3D representations; then in Stage II, we leverage reinforcement learning (RL) to develop robust and generalizable 3D spatial reasoning built on explicit 3D representations.
This RL stage incorporates rewards to optimize both the correctness of final answers and the coherence of intermediate computations, thereby fostering a flexible decision-making capability that remains robust against a variety of unseen scenarios.
Experimental Results
SpatialReasoner sets a new benchmark across multiple spatial reasoning datasets, such as 3DSRBench and CVBench-3D. It significantly outperforms existing models, achieving a mean accuracy of 60.3% on 3DSRBench, and addressing complex multi-object interaction questions with notable precision (Figure 4).

Figure 4: Comparing 3D spatial reasoning of our SpatialReasoner with previous state-of-the-art models. Our SpatialReasoner builds on explicit 3D representations, performs 3D computation, and reasons about the final answer. Although Gemini 2.0 can also break down complex 3D spatial reasoning questions into small and tractable steps, it lacks reliable 3D computation that leads to the correct answer.
However, a distinct trade-off is observed: while performance on test datasets with prevalent spurious correlations (e.g., 2D reasoning shortcuts in CVBench-3D) slightly declines, robust real-world application accuracy, as shown in 3DSRBench, is substantially enhanced.
Implications and Future Research
SpatialReasoner not only advances the state-of-the-art in 3D spatial reasoning but also lays groundwork for future exploration into the integration of explicit representations across different levels of multimodal learning. The potential of explicit 3D representation for not only enhancing precision but also for studying the failure modes of LVLMs offers new insights into developing more accurate and interpretable models.
In terms of practical implications, SpatialReasoner's framework can be extended to complex environments involving robotics and augmented reality, where precise 3D reasoning is paramount. Future research can focus on refining these explicit interfaces to reduce reliance on costly ground-truth datasets, potentially through semi-supervised or self-supervised learning approaches.
Conclusion
"SpatialReasoner: Towards Explicit and Generalizable 3D Spatial Reasoning" epitomizes a transformative stride in vision-LLMs by exploiting explicit 3D representations for enhanced spatial reasoning capabilities. This paper not only marks a significant improvement over existing methods but also projects a path forward for future advancements in AI's ability to interact with and reason about the three-dimensional world.