Global-Local Attention Decomposition for Terrain Encoding in Humanoid Perceptive Locomotion
Abstract: Although reinforcement learning has significantly advanced humanoid locomotion, perceptive policies still struggle on sparse-foothold terrain and constrained environments. Success in these scenarios requires both broad terrain awareness and precise foothold selection, two perceptual roles that conventional encoders often entangle. To address this challenge, we propose Global-Local Attention Decomposition (GLAD) for terrain encoding in humanoid locomotion. Realized by a coarse-to-fine encoder over a robot-centric elevation map, GLAD explicitly separates these objectives: a global attention branch utilizes attention pooling to summarize the surrounding terrain context, while a state-conditioned local attention branch sparsifies and encodes precise foothold-relevant geometry. This explicit attention decomposition prevents the dilution of fine-grained spatial cues while reducing training overhead. Experiments demonstrate that GLAD enables reliable locomotion over challenging gaps, stepping stones, and stairs. Furthermore, the learned policy exhibits emergent terrain-responsive behaviors, autonomously following narrow paths and avoiding obstacles under simple velocity commands without explicit navigation planners. In real-world deployment on a Unitree G1 humanoid robot using onboard LiDAR, the proposed method achieves robust zero-shot sim-to-real transfer across diverse sparse-foothold and obstacle-rich domains.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching a humanoid robot (a robot shaped like a person) to walk safely and smartly over tricky ground—like stepping stones, gaps, stairs, and clutter—using what it “sees” from a laser scanner. The authors introduce a new way for the robot to understand the terrain called GLAD (Global-Local Attention Decomposition). In simple terms, GLAD helps the robot both:
- look around to understand the big picture (what’s ahead and where it’s safe), and
- zoom in to pick exact spots to place its feet.
What questions were the researchers asking?
- How can a robot learn to walk on very challenging, “sparse-foothold” terrain where it must step precisely (like on stones with gaps between them)?
- Can we design its “vision” system so it understands both the overall scene and the tiny details needed for exact foot placement?
- Will this make walking more reliable and efficient, and will it work on a real robot without extra fine-tuning?
How did they do it?
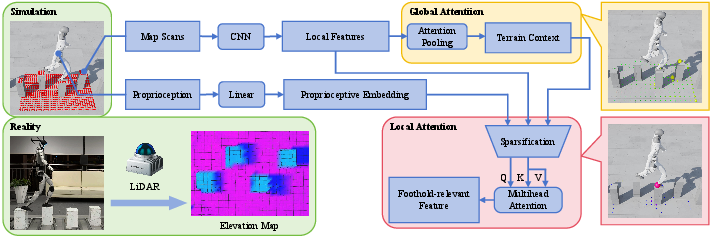
They trained a walking policy using reinforcement learning (think: trial-and-error practice in a simulator) and a new “terrain encoder” called GLAD. The terrain encoder turns a 3D map of the ground into a compact, useful summary for the walking controller.
Key ideas in everyday language:
- Elevation map: Imagine a grid around the robot where each cell says how high the ground is—like a mini 3D map centered on the robot.
- Attention: Like a spotlight for the robot’s “eyes,” highlighting the most important parts of what it sees.
- Global vs. Local attention:
- Global = the lookout scout. It summarizes the whole area to understand general safety and direction (e.g., “There’s a gap ahead; better aim left”).
- Local = the magnifying glass. It focuses on the best exact spots to put each foot right now.
- State-conditioned: The robot’s current body posture and motion guide the local spotlight to where a foot could actually reach.
What GLAD does, step by step:
- A small CNN (a type of neural network) reads the elevation map to make a grid of features (like a simplified, informative version of the map).
- Global branch (lookout): It pools information from the whole grid to build a “context” vector—what the area ahead looks like overall.
- Local branch (magnifying glass): It combines that context with the robot’s current body state to pick only the most relevant nearby spots (top-K candidates) and then applies attention to encode precise, foothold-ready details.
- The walking controller uses both the global context (big picture) and local details (exact foot spots) to decide how to move.
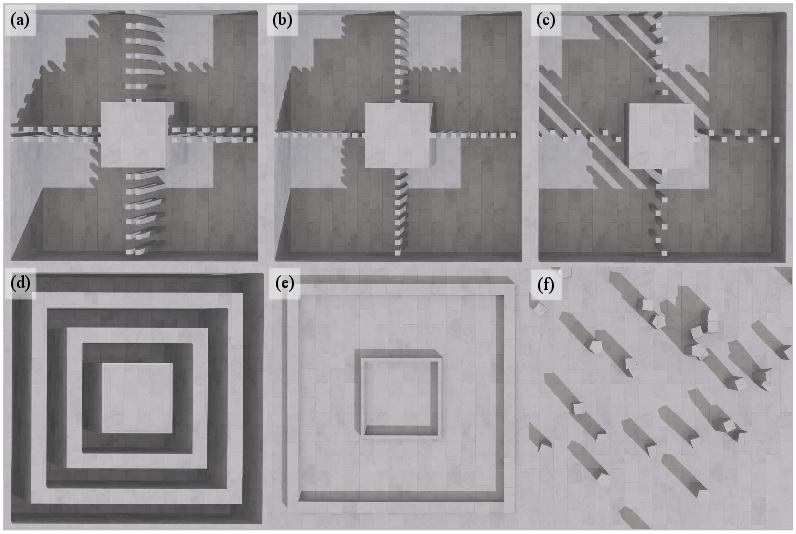
They trained this in two stages on many terrains in simulation, using thousands of parallel robots, and then tested on new, unseen terrains. Finally, they deployed it on a real Unitree G1 humanoid using only its onboard LiDAR and an elevation mapping system.
What did they find, and why is it important?
- More reliable on tough terrains:
- The robot crossed stepping stones, wide gaps (up to 70 cm), stairs, and obstacle-filled areas.
- On especially tricky tests—like cluttered pillars or a narrow winding path—GLAD beat earlier methods by a large margin. It could both aim correctly and place feet precisely.
- Emergent behaviors without extra planning:
- With simple “walk forward” commands, the robot learned to follow narrow paths and avoid obstacles on its own, just from understanding the terrain.
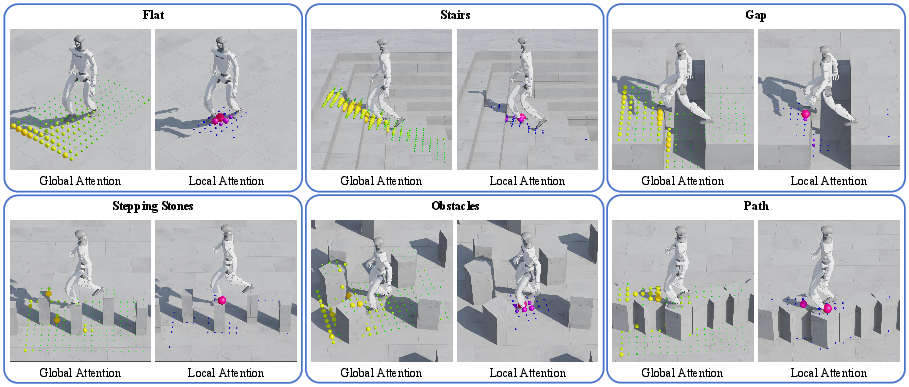
- Better “attention” where it counts:
- The local attention zeroed in on real foothold spots, especially on discrete terrains (like stepping stones), while the global branch watched for big hazards ahead.
- Splitting the roles (global vs. local) made the focus sharper and more understandable.
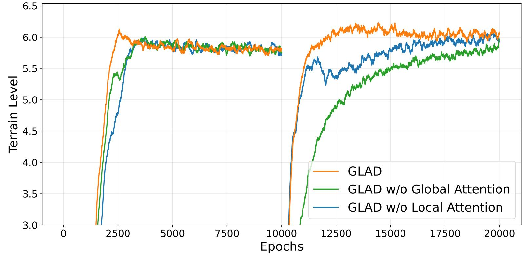
- Faster, more efficient training:
- Because the local branch only pays close attention to a small number of important spots, training time and computation dropped compared to older methods.
Real-world success:
- The same policy trained in simulation worked on the real Unitree G1 robot (this is called “zero-shot sim-to-real”), using only its onboard sensors and no special tweaks. It crossed stepping stones, a stairs+gap combo, a very wide gap, and obstacle-rich areas.
What’s the impact?
- Safer, more adaptable walking: Robots can handle human-sized obstacles and limited footholds better, which brings them closer to being useful in real buildings, construction sites, or disaster zones.
- Less manual engineering: The robot learns precise foot placement and path choices without hand-crafted rules or step-by-step planners.
- A clear design pattern: Separating “look far” (global) from “place precisely” (local) is a simple idea with big gains, and it could help other robot tasks that need both big-picture awareness and fine detail.
In short, GLAD teaches a humanoid robot to understand where it can go and exactly where to step, making it more confident and capable on hard terrain—both in simulations and the real world.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper, intended to guide future research:
- Elevation-map expressiveness: single-layer elevation maps cannot represent overhangs, multi-level structures, or negative obstacles beyond a single height per cell; quantify how such cases degrade GLAD and explore 3D or multi-layer mapping.
- Temporal perception: the encoder operates on single scans without explicit temporal fusion; assess benefits of sequence models, recurrent memory, or temporal attention for occlusions, moving obstacles, and longer lookahead.
- Mapping uncertainty: the policy treats elevation cells as deterministic; investigate uncertainty-aware encodings (e.g., per-cell covariance) and risk-sensitive control under noisy or partial reconstructions.
- Dynamic/moving obstacles: experiments emphasize static clutter; evaluate reactive avoidance of moving agents and objects, including prediction-aware perception-action coupling.
- Adverse sensing conditions: robustness to LiDAR artifacts (rain/fog, dust, reflective/specular surfaces, low-texture areas), severe occlusions, and partial FOV is not quantified; develop stress tests and targeted randomizations.
- State-estimation drift: the impact of FAST-LIO drift or transient failures on control and mapping alignment is unassessed; study robustness, detection, and fallback strategies.
- Computational deployment: results are on a powerful laptop GPU; characterize latency, throughput, and power on embedded compute typical of humanoids, including mapping–policy budget breakdowns and real-time margins.
- Long-horizon navigation: “emergent local navigation” is shown, but integration with global planners, map memory, and goal-directed long-horizon path selection beyond the 1.6×1.0 m local map remains open.
- Map horizon and scale: analyze performance vs. map size/resolution trade-offs and introduce adaptive or multi-scale fields of view for anticipatory behaviors at higher speeds.
- Hyperparameter sensitivity: only K (top-K) is partially explored; systematically study stride s, embedding dimension D, attention heads, map resolution, and their interactions on performance and compute.
- Adaptive sparsification: top-K selection is fixed and hard; explore differentiable or adaptive sparsification (e.g., soft top-k, thresholding by learned confidence) and its stability/gradient properties.
- Attention causality: attention maps are interpreted as explanations, but no intervention tests (masking attended vs. unattended regions) verify causal influence; perform causal/ablation studies for interpretability claims.
- Failure mode analysis: provide systematic characterization of where GLAD fails (e.g., extreme clutter, very low friction, deformable or compliant terrain, slippery surfaces) and why.
- Control interface limitations: actions are joint-position offsets around a standing pose; evaluate torque/impedance control, explicit foot trajectory generation, and gait timing control for agility and energy efficiency.
- Gait and timing adaptation: step timing and contact schedules are implicit; quantify cadence adaptation, stance/swing timing, and their role in crossing large gaps or highly discrete supports.
- Safety/guarantees: there are no formal safety constraints or guarantees (foot–obstacle collision avoidance, slip risk bounds, ZMP/CoM margins); investigate constraint-aware/safe RL or runtime safety filters.
- Generalization across robots: transfer to different humanoid morphologies, joint counts, and leg kinematics is untested; study retargeting or morphology-conditioned encoders.
- Sensor modality fusion: only LiDAR-based elevation maps are used; evaluate depth cameras, stereo, IMU-only fallback, or multi-modal fusion under varying conditions and compute budgets.
- Semantic terrain understanding: encoding is purely geometric; assess benefits of learned semantics (e.g., material, compliance, traversability classes) for foot placement and route selection.
- Baseline breadth and fairness: comparisons are limited to AME variants; include transformer/ViT encoders, graph-based encoders, and non-attention CNN baselines matched for parameter count and compute.
- Positional encoding ablation: zero padding and 3D-coordinate convolution choices are motivated but not ablated; quantify their contribution vs. alternative positional encodings.
- Curriculum and reward transparency: “standard locomotion rewards” and curricula are not fully detailed; release definitions and analyze how they shape emergent foothold precision and navigation.
- Sim-to-real analysis: provide quantitative real-world metrics (success rates, falls, collisions, clearance, tracking error, energy/torque) and ablate domain randomization components critical for transfer.
- Speed envelope: tests use moderate commanded speeds (≤1.0 m/s); characterize performance at higher speeds and during running or rapid turning, and the compute/latency limits at those regimes.
- Terrain diversity: real-world tests cover a few layouts; expand to irregular heights, deformable substrates (sand/grass), steep/uneven slopes, and compliant stepping stones to probe limits.
- Map–policy coupling: study failure due to misalignment between the robot frame and the map (latency, extrinsic calibration error) and compensate via delay-aware inference or alignment layers.
- Uncertainty-aware planning: incorporate and test risk-aware footstep selection that accounts for sensing uncertainty and unobserved areas when choosing footholds near map borders.
- Adaptive K per context: fixed K may be suboptimal across terrains; learn K or use confidence-driven sparsity to balance precision and compute dynamically.
- Reproducibility: code, trained models, and detailed training artifacts are not reported; releasing them would enable independent verification and broader benchmarking.
Practical Applications
Overview
Drawing on the paper’s findings and innovations—specifically the Global-Local Attention Decomposition (GLAD) encoder for robot-centric elevation maps, state-conditioned sparsification, efficient coarse-to-fine attention, and demonstrated zero-shot sim-to-real transfer on a Unitree G1—below are practical, real-world applications. Each item includes sector alignment, example tools/products/workflows that could emerge, and key assumptions/dependencies that impact feasibility.
Immediate Applications
- Terrain-aware locomotion module for humanoids
- Sector: Robotics (humanoids), Software
- Tools/Products/Workflows: GLAD as a drop-in terrain encoder plugin (SDK) for perceptive locomotion stacks that accept elevation maps; ROS2 node integrating elevation mapping + GLAD + PPO policy
- Assumptions/Dependencies: Onboard LiDAR or depth camera, robot-centric elevation mapping (e.g., Elevation Mapping), reliable state estimation (e.g., FAST-LIO), sufficient onboard GPU for 50 Hz inference, robot retraining/fine-tuning for platform specifics
- Warehouse and logistics aisle traversal without heavy local planners
- Sector: Logistics, Retail robotics
- Tools/Products/Workflows: Narrow-aisle following and obstacle avoidance using velocity commands only; GLAD-based “local-navigation-by-locomotion” mode replacing or simplifying local planners
- Assumptions/Dependencies: Indoor LiDAR coverage, reflective/transparent obstacles handled by mapping, safety certification for human-robot interaction, guardrails for unexpected edge cases
- Construction and facility inspection on uneven or sparse-foothold terrain
- Sector: Construction, Industrial inspection
- Tools/Products/Workflows: Traversal over stairs, gratings, rail-like features, and gaps; inspection routes where locomotion adapts to terrain without explicit footstep plans
- Assumptions/Dependencies: Dust and weather-hardened LiDAR, proper training domain randomization for site-specific hazards, fall protection policies
- Disaster response field trials in cluttered rubble and stepping-stone-like environments
- Sector: Public safety, Search and rescue
- Tools/Products/Workflows: Rapid-deploy autonomy pack combining GLAD + elevation mapping for local traversal while teleoperators set high-level velocity goals
- Assumptions/Dependencies: Robust mapping in smoke/dust (LiDAR selection and filtering), communications for teleop override, safety and triage protocols
- Hospital logistics and service robotics in tight corridors
- Sector: Healthcare, Service robotics
- Tools/Products/Workflows: Cart/trolley delivery robots that maintain forward progress and avoid nearby obstacles using GLAD-based terrain-response; simplified route configuration (velocity setpoints)
- Assumptions/Dependencies: Compliance with medical facility safety standards, disinfectant-safe sensors, 24/7 operation robustness, staff training
- Retrofitting quadrupeds and other legged robots with GLAD
- Sector: Security, Inspection, Research platforms
- Tools/Products/Workflows: Port GLAD encoder to quadrupeds for improved foot placement in clutter; share the same elevation-map workflow
- Assumptions/Dependencies: Re-training on target morphology, compatible observation spaces, tuning K (sparsification) for different gaits
- Operator UI for interpretable attention overlays
- Sector: Software tools, Robotics QA
- Tools/Products/Workflows: Real-time visualization of global/local attention on elevation maps for debugging, teleop confidence, and safety audits
- Assumptions/Dependencies: Access to attention weights at runtime, UI integration (ROS RViz, web dashboards), data logging
- Manufacturing QA test suites for perceptive locomotion
- Sector: Robotics manufacturing, Certification testing
- Tools/Products/Workflows: Standardized terrains (stepping stones, gaps, narrow paths) and metrics (success rate, attention–foothold alignment) for acceptance tests of locomotion stacks
- Assumptions/Dependencies: Benchmark fixtures, reproducible deployment scripts, agreed pass/fail thresholds
- Academic baselines and curricula for interpretable embodied RL
- Sector: Academia
- Tools/Products/Workflows: Open-source GLAD encoder, two-stage training curriculum, attention–foothold alignment metrics, and Isaac Sim environments for reproducible studies
- Assumptions/Dependencies: Code/data release, GPU access for PPO training, licensing for simulators
- Teleoperation assist through foothold-relevance cues
- Sector: Defense, Industrial maintenance
- Tools/Products/Workflows: Haptic or visual cues highlighting GLAD-selected foothold regions to reduce operator cognitive load during delicate maneuvers
- Assumptions/Dependencies: Low-latency mapping and visualization, human factors validation, UI/UX integration
Long-Term Applications
- Planner-free local navigation for legged robots at scale
- Sector: Robotics (general), Indoor autonomy
- Tools/Products/Workflows: End-to-end locomotion stacks that take only velocity commands and achieve navigation-like behavior in complex interiors
- Assumptions/Dependencies: Multi-scale terrain perception, longer-range sensing/memory, robust recovery behaviors, extensive safety validation
- Assistive exoskeletons and prosthetics with terrain-aware foot placement guidance
- Sector: Healthcare, Wearables
- Tools/Products/Workflows: GLAD-inspired encoder using lightweight depth sensors to propose footholds or modulate gait phases
- Assumptions/Dependencies: Miniaturized sensing and compute, medical-grade safety, human-in-the-loop control, rigorous clinical trials
- Standardization and certification of interpretable perceptive locomotion
- Sector: Policy, Certification, Insurance
- Tools/Products/Workflows: Guidelines requiring interpretable attention diagnostics, benchmark terrain suites, and reporting of attention–foothold alignment metrics for deployment in public spaces
- Assumptions/Dependencies: Multi-stakeholder standards bodies, shared datasets, incident reporting frameworks
- Infrastructure and energy site inspection (offshore, refineries, power plants)
- Sector: Energy, Heavy industry
- Tools/Products/Workflows: Autonomous traversal of catwalks, gratings, stairs, and pipe racks with sparse footholds; integration with inspection payloads
- Assumptions/Dependencies: ATEX/IECEx compliance where needed, ruggedization, long-duration mapping under harsh conditions
- Household service humanoids that handle cluttered living spaces
- Sector: Consumer robotics
- Tools/Products/Workflows: Robust navigation through narrow passages, toys/cables on floors, and stairs, with minimal local planning
- Assumptions/Dependencies: Cost-effective sensors/compute, home-grade safety certification, user education, privacy considerations
- Multi-robot coordination via shared GLAD-style terrain representations
- Sector: Robotics (multi-agent), Warehousing
- Tools/Products/Workflows: Common map layers with global/local attention hints to coordinate passing through bottlenecks and narrow corridors
- Assumptions/Dependencies: Low-latency map sharing, conflict resolution policies, standardized representation formats
- Cross-modal and cross-platform terrain encoding library
- Sector: Software, Robotics platforms
- Tools/Products/Workflows: GLAD extended to RGB-D, stereo, or event cameras; unified encoder API across humanoids, quadrupeds, and micro-mobility robots
- Assumptions/Dependencies: Robust sensor fusion to elevation-like representations, domain adaptation, calibration tooling
- Embedded efficiency and energy-optimized autonomy
- Sector: Edge AI, Mobile robotics
- Tools/Products/Workflows: Sparsification-aware inference engines, quantized GLAD models, and real-time elevation mapping accelerators to extend battery life
- Assumptions/Dependencies: Hardware accelerators, optimized mapping pipelines, thermal constraints management
- Public deployment policy for legged robots in transit hubs and buildings
- Sector: Policy, Urban mobility
- Tools/Products/Workflows: Operating permits tied to performance on standardized terrains (e.g., stairs, gaps) and interpretable logs for post-incident analysis
- Assumptions/Dependencies: Legal frameworks for autonomous operations, liability models, public acceptance
- Digital-twin testbeds and procurement benchmarks
- Sector: Government, Enterprise buyers, Simulation vendors
- Tools/Products/Workflows: GLAD-based benchmark suites embedded in digital twins of facilities; procurement checklists that score sim-to-real transfer and attention interpretability
- Assumptions/Dependencies: High-fidelity digital twins, shared scenario libraries, vendor-neutral evaluation protocols
Cross-cutting assumptions and dependencies
- Sensing and mapping: Availability of reliable, low-latency robot-centric elevation maps (LiDAR/depth), robust state estimation, and sensor fusion under real-world noise.
- Compute: Sufficient onboard compute for 50 Hz mapping + policy inference; future embedded optimization may be necessary for consumer-grade devices.
- Training and transfer: Simulation assets, domain randomization, and occasional platform-specific retraining; quality and diversity of training curricula affect generalization.
- Safety and compliance: Human-in-the-loop overrides, fail-safe behaviors, and certification processes for operation near people and on hazardous terrain.
Glossary
- AME: An attention-based map encoder for perceptive locomotion that uses attention to fuse terrain features and robot state. "AME \cite{he2025attention} introduces an attention-based map encoder that uses multi-head attention (MHA) to aggregate local terrain features conditioned on proprioception"
- AME-2: A successor to AME that incorporates additional global context into the terrain encoder. "AME-2 \cite{zhang2026ame} further augments this design with additional global context."
- Anthropomorphic body plan: A human-like robot morphology that enables humanoid mobility and interaction. "Humanoid robots, owing to their anthropomorphic body plan and legged mobility, are a promising platform"
- Attention entanglement: Unwanted coupling of distinct perceptual roles within a single attention mechanism, reducing clarity and effectiveness. "By separating global terrain-context aggregation from state-conditioned local foothold encoding, GLAD reduces attention entanglement"
- Attention pooling: A mechanism that computes weighted sums of features using attention weights to produce a compact summary. "a global attention branch utilizes attention pooling to summarize the surrounding terrain context"
- Attention weights: The normalized importance scores assigned by an attention mechanism to input features. "Visualization of global and local attention weights."
- Coarse-to-fine encoder: An architecture that first captures broad context at lower resolution and then focuses on fine-grained local details. "Realized by a coarse-to-fine encoder over a robot-centric elevation map, GLAD explicitly separates these objectives"
- Domain randomization: A training technique that randomizes environment and sensor parameters to improve policy robustness and transfer. "Observation noise and domain randomization are introduced mainly in the second stage"
- Elevation map: A robot-centric grid storing terrain geometry (e.g., heights or 3D coordinates) used for foothold reasoning. "A CNN first extracts spatially aligned local features from a robot-centric elevation map."
- Elevation mapping: The process of constructing an elevation map from sensor data for terrain perception. "Using only onboard LiDAR-based elevation mapping, without pre-mapping or external motion capture, the learned policy achieves robust zero-shot sim-to-real transfer"
- Exteroceptive observations: Sensor measurements about the external environment (e.g., depth, elevation) used for terrain-aware control. "perceptive locomotion policies must incorporate exteroceptive observations such as elevation maps or depth images."
- FAST-LIO: A LiDAR–IMU fusion odometry framework for high-rate, robust state estimation. "For deployment, we use FAST-LIO \cite{xu2021fast} to fuse LiDAR and IMU measurements for state estimation"
- Foothold placement: The precise selection of foot contact locations to ensure stable traversal of discrete supports. "learn not only precise foothold placement but also terrain-responsive motion adjustment"
- Global attention branch: The component that aggregates broad terrain information into a compact context vector. "A global attention branch utilizes attention pooling to summarize the surrounding terrain context."
- Global-attention logit: The pre-softmax scalar score computed per feature to derive global attention weights. "we apply a linear layer to each local feature to produce a global-attention logit"
- Global-Local Attention Decomposition (GLAD): The proposed encoder that separates global context aggregation from local foothold-focused attention. "we propose Global-Local Attention Decomposition (GLAD) for terrain encoding in humanoid locomotion."
- IMU (Inertial Measurement Unit): A sensor providing accelerations and angular velocities, often fused for state estimation. "synchronized inertial measurement unit (IMU) measurements"
- Key and value (in attention): Feature vectors used by attention to compute relevance (keys) and retrieve content (values). "The retained features are then processed by MHA as key and value"
- LiDAR: A laser-based range sensor that provides 3D point clouds of the environment. "Using only onboard LiDAR-based elevation mapping"
- Livox Mid-360: A specific LiDAR device model used for real-world deployment. "equipped with a Livox Mid-360 LiDAR"
- Multi-head attention (MHA): An attention mechanism with multiple parallel heads to capture diverse feature relationships. "The MHA module is configured with $16$ attention heads."
- Partially observable Markov decision process (POMDP): A formalism for decision-making with incomplete observations of the system state. "We formulate humanoid perceptive locomotion as a partially observable Markov decision process (POMDP)"
- Proprioceptive embedding: A learned vector summarizing internal robot state signals for conditioning attention. "We then concatenate with the -dimensional proprioceptive embedding"
- Proprioceptive measurements: Internal sensor readings (e.g., joint positions, velocities) describing the robot’s own state. "composed of proprioceptive measurements and exteroceptive terrain perception"
- Proximal Policy Optimization (PPO): A reinforcement learning algorithm used to train the locomotion policy. "We train the policy using proximal policy optimization (PPO) \cite{schulman2017proximal}."
- Query vector: The attention vector that probes keys/values to retrieve relevant information conditioned on state. "project the result into a state-conditioned query vector "
- Robot-centric elevation map: An elevation representation expressed in the robot’s base frame for local terrain encoding. "over a robot-centric elevation map"
- Sim-to-real transfer: Applying a policy learned in simulation directly to real robots. "achieves robust zero-shot sim-to-real transfer"
- Sparse-foothold terrain: Terrain with limited discrete support regions requiring precise foot placement. "perceptive policies still struggle on sparse-foothold terrain"
- State-conditioned sparsification: Selecting a subset of local features based on the current robot state to focus attention. "thereby implementing state-conditioned sparsification over the local terrain features."
- Strided downsampling: Convolutional reduction of spatial resolution via strides to shorten feature sequences. "The first convolutional layer performs strided downsampling with a stride of ."
- Surrounding terrain context: A compact representation summarizing nearby terrain relevant to locomotion decisions. "summarize the surrounding terrain context"
- Top-K retention: Keeping only the K highest-scoring features after relevance scoring. "retaining only the top- candidates."
- Traversability cues: Indicators of whether nearby terrain is feasible to traverse. "reason about broad traversability cues and precise support-region geometry"
- Zero padding: Padding convolution inputs with zeros to preserve spatial alignment and boundary information. "Both convolutional layers use zero padding to preserve boundary information"
- Zero-shot transfer: Deploying a learned policy to new domains without additional fine-tuning. "robust zero-shot sim-to-real transfer"
Collections
Sign up for free to add this paper to one or more collections.