AME-2: Agile and Generalized Legged Locomotion via Attention-Based Neural Map Encoding
Abstract: Achieving agile and generalized legged locomotion across terrains requires tight integration of perception and control, especially under occlusions and sparse footholds. Existing methods have demonstrated agility on parkour courses but often rely on end-to-end sensorimotor models with limited generalization and interpretability. By contrast, methods targeting generalized locomotion typically exhibit limited agility and struggle with visual occlusions. We introduce AME-2, a unified reinforcement learning (RL) framework for agile and generalized locomotion that incorporates a novel attention-based map encoder in the control policy. This encoder extracts local and global mapping features and uses attention mechanisms to focus on salient regions, producing an interpretable and generalized embedding for RL-based control. We further propose a learning-based mapping pipeline that provides fast, uncertainty-aware terrain representations robust to noise and occlusions, serving as policy inputs. It uses neural networks to convert depth observations into local elevations with uncertainties, and fuses them with odometry. The pipeline also integrates with parallel simulation so that we can train controllers with online mapping, aiding sim-to-real transfer. We validate AME-2 with the proposed mapping pipeline on a quadruped and a biped robot, and the resulting controllers demonstrate strong agility and generalization to unseen terrains in simulation and in real-world experiments.





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What this paper is about
This paper is about teaching legged robots (like a four-legged robot dog and a two-legged humanoid) to move quickly and safely over many kinds of tricky ground—stairs, gaps, rocks, narrow footholds—using their cameras and other sensors. The authors introduce AME-2, a method that helps robots both be agile (move fast and dynamically) and generalize (handle new, unseen terrains) by combining smart “map reading” with learning to control their bodies.
The big questions the paper asks
- How can a robot use what it “sees” to pick safe, useful footholds even when parts of the ground are hidden or noisy (for example, behind obstacles or at the edge of its camera view)?
- Can we make one controller that works on very different robots and terrains without hand-tuning for each new situation?
- How do we train in simulation so that the robot works the same way in the real world?
How their approach works (in everyday language)
Think of a robot walking through a video game level. It has:
- A “mini-map” showing the nearby ground heights (like a top-down height map).
- Its own “body sense” (how its joints are bent, how fast it’s turning, etc.).
- A goal location (where it needs to go and which way to face).
The method has three key parts:
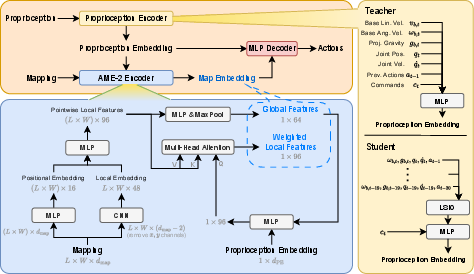
- Attention-based map understanding (the “flashlight” for the mini-map)
- The robot’s camera gives depth images (how far each pixel is). These are turned into a simple grid of ground heights near the robot, called an elevation map.
- AME-2 builds two kinds of map features:
- Local details (like the exact edge of a step or a small rock).
- Global context (the overall shape of the terrain nearby).
- An “attention” module acts like a smart flashlight: it focuses on the parts of the map that matter most for the robot’s next move, using both the global terrain picture and the robot’s body state. This helps it ignore unhelpful areas and concentrate on where to step next.
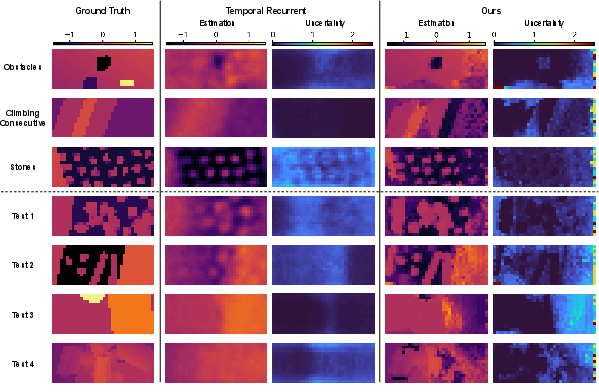
- Uncertainty-aware mapping (knowing what you don’t know)
- Real cameras see only part of the world, and some areas are noisy or blocked (occluded).
- The paper uses a small, fast neural network that turns each depth image into a local height map plus a confidence score for each cell (high confidence = likely correct; low confidence = maybe occluded or noisy).
- These local guesses are fused over time into a global map using the robot’s estimated movement (odometry).
- Instead of blindly averaging everything, they use a “probabilistic winner-take-all” rule: a new measurement only replaces the old one if it’s confident enough. That prevents the map from becoming overconfident about areas it hasn’t really seen.
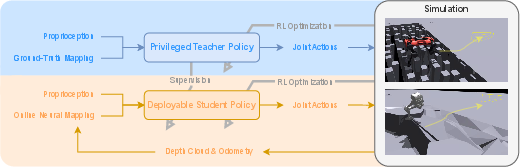
- Teacher–student training (learning in sim, working in real life)
- In simulation, a “teacher” policy learns to walk using perfect ground-truth maps.
- Then a “student” policy learns to act like the teacher while also learning with the realistic, learned mapping (with uncertainty). This makes the student fast, robust, and ready for the real world—no hidden shortcuts from simulation.
A few helpful terms in simple words:
- Reinforcement Learning (RL): trial-and-error learning. The robot tries actions, gets rewards for good progress (like moving toward the goal without falling), and learns what works.
- Proprioception: the robot’s “body sense,” like joint angles and body rotations.
- Odometry: the robot’s best guess of its position and movement over time.
- Occlusion: when the camera can’t see a part of the terrain because something is in the way.
What they found and why it matters
Main results:
- The robots (a four-legged ANYmal-D and a two-legged TRON1) learned to move quickly, precisely, and safely over many tough terrains, including ones not seen during training.
- The attention-based encoder helped the policy focus on the most important terrain features, improving generalization (doing well on new terrains) without losing agility.
- The uncertainty-aware mapping ran fast on real robot computers and was robust to noise and occlusions, supporting dynamic motions.
- Training used the same mapping pipeline in simulation and in the real world, which reduced surprises when moving from sim to reality.
Why this is important:
- Previous systems often had to choose: be agile but overfit to training courses, or generalize but move slowly and cautiously. AME-2 shows you can get both: quick and adaptable.
- Knowing what the robot is unsure about makes behavior safer (it won’t bet on a risky, unseen edge).
- The attention mechanism makes the system more interpretable: engineers can visualize which terrain regions the robot focused on.
What this could lead to
- More reliable robots for real-world jobs: search-and-rescue on rubble, inspection in cluttered factories, delivery on uneven sidewalks, or home assistance around obstacles.
- Faster deployment: one training setup worked for both a quadruped and a biped, hinting at shared “walking intelligence” across different robot bodies.
- Better human trust and debugging: attention maps and uncertainty make it clearer why the robot chose certain steps.
- A foundation for future skills: the same ideas (attention on maps plus uncertainty-aware sensing) could help with running, jumping, climbing, or using hands for balance.
In short, AME-2 gives robots a smarter way to “look, think, and step.” It teaches them to pay attention to the most useful parts of their surroundings, be honest about what they don’t know, and move with both speed and caution—even on new, challenging terrain.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of concrete gaps the paper leaves unresolved, focusing on what is missing, uncertain, or unexplored and framed so future researchers can act on them.
- Quantitative generalization claims are not substantiated: the paper asserts “strong agility and generalization” but provides no reported metrics, success rates, or statistical comparisons on unseen terrains, nor standardized benchmarks to reproduce results across labs.
- Lack of interpretability evaluation for the AME-2 attention: there is no analysis showing whether attention weights correlate with terrain saliency, foothold utility, or risk; provide visualization, attribution maps, and quantitative alignment (e.g., with human-labeled salient regions or contact heatmaps).
- Unclear sensitivity of AME-2 to map size and resolution: how performance varies with grid resolution, field-of-view, and egocentric window placement (e.g., center at m vs. m) is not studied; determine scaling laws and optimal input footprints.
- Missing ablations of AME-2 vs. AME-1 and architecture components: there is no reported contribution analysis (e.g., without global features, without MHA, different positional embeddings, or alternative attention mechanisms such as Performer/FlashAttention).
- No robustness analysis to mapping errors: the policy’s sensitivity to systematic biases (height offsets), non-stationary drifts, occlusion patterns, or structured noise in the map channel is unexplored; include controlled perturbation tests and recovery behaviors.
- The mapping fusion lacks a principled treatment of odometry uncertainty: the Probabilistic Winner-Take-All (WTA) fusion does not incorporate pose covariance; evaluate SE(3) uncertainty-aware fusion (e.g., Kalman, particle, or pose graph approaches) and quantify the impact under agile motions with estimator drift.
- The WTA fusion’s stability and consistency are uncharacterized: stochastic overwrites and heuristic thresholds (0.5, 1.5, 0.2) could induce map flickering or bias; formally analyze convergence, hysteresis behavior, and long-horizon consistency, and explore deterministic alternatives or learned fusion policies.
- Uncertainty calibration of the mapping model is not validated: there are no reliability diagrams, expected calibration error (ECE) analyses, or sharpness/coverage metrics showing is well-calibrated under real occlusions and sensor artifacts; perform calibration studies and uncertainty-threshold selection.
- Unclear how the policy uses uncertainty: the student sees an uncertainty channel but there is no evidence the policy becomes risk-aware (e.g., adjusts speed/contacts in high- regions); test behavioral changes conditioned on and consider explicit uncertainty-aware rewards or constraints.
- Mapping runtime on hardware is unspecified: policy inference is 2 ms, but end-to-end mapping latency (projection + CNN + fusion + query), throughput (Hz), and CPU/GPU resource usage are not reported; profile performance and analyze latency’s impact on control stability.
- Mapping training relies solely on synthetic raytracing data: domain gap to real sensors (depth distortions, multipath, rolling shutter, textureless surfaces, outdoor lighting) is not addressed; collect real datasets for supervised or self-supervised adaptation and quantify gains from domain adaptation.
- Limited terrain modeling in mapping: elevation grids cannot represent overhangs, negative obstacles, vertical faces, deformable or compliant surfaces; examine 3D volumetric, signed distance, or affordance-aware maps, and assess benefits for climbing and sparse footholds.
- Dynamic environment handling is not studied: the pipeline does not detect moving obstacles or time-varying terrains explicitly; evaluate dynamic scene segmentation, temporal consistency, and reactive policies for moving obstacles or collapsing substrates.
- Odometry drifts under agility are only penalized, not mitigated: penalizing yaw rates >2 rad/s is a workaround; study robust state estimation under whole-body contacts, loop closures, and sensor fusion (IMU-VIO-LiDAR) integrated with the mapping.
- No analysis of sim-to-real failure modes: provide case studies of real-world failures (slips, estimator resets, sensor dropouts) and mitigation strategies (fallback controllers, failsafe behaviors, degraded modes).
- Teacher–student distillation details are underexplored: the representation MSE loss and PPO scheduling are given, but no ablations of loss weighting, surrogate disabling duration, or alternative alignment strategies (contrastive, CCA, attention alignment) are reported; study what drives successful transfer.
- Student memory design (LSIO, 20-step window) lacks sensitivity analysis: test different sequence lengths, encoders (GRU/LSTM/Transformer), and their effect on disturbance rejection, latency tolerance, and mapping delay compensation.
- Command representation clipping (goal distance capped at 2 m) is not evaluated: assess the impact on long-horizon navigation, heading bias, and integration with global planners; propose hierarchical interfaces and handoff policies.
- Energy efficiency and hardware stress are not measured: quantify energy usage, actuator thermal load, and impact forces across terrains; tie safety penalties (e.g., thigh acceleration) to measurable hardware limits and lifetime models.
- Domain randomization parameters are not data-driven: randomization magnitudes and distributions for dynamics, sensor noise, and mapping artifacts are heuristic; derive them from real sensor logs and system identification to improve transfer predictability.
- Cross-robot generalization is narrow (two robots): test broader morphologies (hexapods, other bipeds, mini/quasi-static platforms) and analyze which architectural or reward components transfer, including few-shot adaptation or meta-learning.
- Lack of comparison to alternative fusion or mapping methods: benchmark against classical elevation mapping, learned fusion, neural processes, and uncertainty-aware Bayesian filters under equal latency constraints.
- No explicit evaluation of whole-body contact strategies: while policies sometimes use non-foot contacts, there is no analysis of when and why such contacts emerge, their safety implications, and how mapping or attention influences contact selection.
- Safety assurances are informal: provide formal safety analyses (constraint satisfaction, worst-case contact forces, bounded slip probabilities) and runtime monitors (contact anomaly detection) for deployment in human-populated environments.
- Compute scalability is high (60/30 RTX-4090-days): explore sample-efficient training (off-policy, model-based RL, curriculum optimization), shared encoders across robots, and mixed-precision/compiled inference to reduce training cost.
- Map persistence and reuse are not characterized: the approach sometimes allows “complete maps” and reuse, but policies’ behavior under partial/aging maps, session resets, and multi-episode consistency is not analyzed; study lifetime management and loop closure in the global grid.
- Sensor suite limitations: the approach uses a single depth modality; evaluate multi-sensor fusion (stereo, LiDAR, tactile, feet force sensing) and quantify redundancy benefits for occlusions and adverse conditions.
- Reward shaping is not proven terrain-agnostic: while link-level penalties replace contact-position rewards, test if this yields undesired behaviors (e.g., excessive non-foot contacts) in certain terrains and refine shaping with terrain-aware constraints or affordance priors.
- Missing end-to-end reproducibility details: hyperparameters are relegated to appendices not included here, and multiple references to sections/figures are placeholders; provide full training configs, seeds, code, and evaluation scripts for replicability.
Practical Applications
Immediate Applications
Below are practical, deployable applications that can be built now with the paper’s methods (AME-2 controller + uncertainty-aware elevation mapping + teacher–student sim-to-real pipeline), along with sector tags, potential tools/products/workflows, and key assumptions/dependencies.
- Agile inspection and maintenance on complex sites (robotics, energy, manufacturing, utilities)
- Use quadrupeds (e.g., ANYmal-class) to traverse stairs, grates, clutter, and sparse footholds with onboard depth sensing and AME-2 control for routine rounds and anomaly checks.
- Tools/products/workflows: “Perceptive Locomotion Pack” (ROS 2 nodes for mapping + policy, ONNX Runtime inference), operator waypoint interface, safety wrapper that slows/stops under high map uncertainty, attention/uncertainty visualization for teleoperation.
- Assumptions/dependencies: Depth camera or lidar; reliable odometry for map fusion; moderate lighting/visibility; robot torque/power sufficient for site obstacles; site safety policy permitting autonomous locomotion.
- Construction, mining, and tunnel mobility (robotics, construction, mining)
- Robust mobility over rubble, steps, rebar mats, and occluded voids using uncertainty-aware mapping (occlusions remain high-uncertainty and are avoided/handled).
- Tools/products/workflows: Mission templates (site ingress/egress, ad hoc inspection), map-reuse across repeated traversals (patrol routes).
- Assumptions/dependencies: Dust/fog may degrade depth; enclosure for sensors; intermittent GPS (rely on local odometry/SLAM); human-in-the-loop handoff for blocked passages.
- Search-and-rescue deployment aid (public safety, emergency response)
- Remote-operated legged robots use AME-2 to stabilize motion across debris while operators focus on victim search; uncertainty overlays cue teleop decisions in occluded areas.
- Tools/products/workflows: Teleop UI with live attention/uncertainty layers; “uncertainty gating” behaviors (crawl/feel/test footholds).
- Assumptions/dependencies: Robust comms; ruggedized hardware; pre-incident operator training; standard operating procedures for entering compromised structures.
- Warehouse back-of-house and facility logistics across mixed-level access (robotics, logistics)
- Legged platforms handle short stair segments, ramps, and threshold discontinuities that defeat wheels, supporting small-batch transport and spare-parts delivery.
- Tools/products/workflows: WMS integration to dispatch waypoints; policy runs indefinitely via goal-clipping command interface; battery-aware mission planning.
- Assumptions/dependencies: Predictable human traffic; compliance with indoor robot policies; load limits within trained dynamics.
- Field robotics for agriculture and environmental monitoring (agriculture, environmental)
- Traversal of banks, furrows, and low obstacles; uncertainty preserves occluded ditches/holes to prevent high-risk foot placements.
- Tools/products/workflows: Seasonal re-calibration and terrain data augmentation; geofenced missions with map caching for repeat passes.
- Assumptions/dependencies: Vegetation can degrade depth sensing; rain/mud protection; GNSS availability varies (use local odometry).
- Security patrols with map reuse (security, facilities)
- Repeated route traversals benefit from probabilistic map fusion and reuse, improving stability on recurring obstacles.
- Tools/products/workflows: Route scheduler; map caching; anomaly logging tied to local terrain uncertainty spikes.
- Assumptions/dependencies: Environment quasi-static between patrols; drift-bounded odometry to align reused maps.
- Academic replication and benchmarking (academia, software)
- Use the unified goal-reaching RL setup, AME-2 encoder, MoE critic, and uncertainty mapping to benchmark agility-generalization trade-offs on quadruped and biped platforms.
- Tools/products/workflows: Isaac Gym training scripts; Warp-based synthetic elevation dataset generator; ablation protocols (AME-1 vs AME-2, teacher–student alignment).
- Assumptions/dependencies: Multi-GPU access (tens of 4090-GPU-days); licensing for simulators; availability of ANYmal-like or TRON1-like models.
- Deployable software modules and SDKs (software, robotics)
- Standalone ROS 2 mapping node (uncertainty-aware elevation grid + probabilistic winner-take-all fusion), AME-2 encoder library, ONNX policies, and attention/uncertainty visualizer.
- Tools/products/workflows: CI pipelines for retraining with new terrain packs; telemetry logging with uncertainty; runtime monitors for safety thresholds.
- Assumptions/dependencies: Sensor-driver compatibility; real-time CPU budgets (~2 ms policy inference) and depth processing on embedded PCs.
- Sim-to-real training workflow for new robots (robotics R&D, OEMs)
- Template teacher–student training with representation loss alignment; actuator modeling; domain randomization curricula for dynamics and mapping noise.
- Tools/products/workflows: “Bring-up kit” (URDF + actuator model + reward presets + mapping configs) to onboard new platforms.
- Assumptions/dependencies: Accurate actuator/limits identification; synthetic mapping data generation attuned to target sensor FOV and mounting.
- Safety wrappers driven by uncertainty (software, compliance)
- Behavior trees or state machines that switch to conservative gaits, reduce speed, or request teleop when map uncertainty exceeds thresholds.
- Tools/products/workflows: Cert-ready logs of uncertainty, contact events, and interventions for incident analysis.
- Assumptions/dependencies: Threshold tuning per site; clarity on stop conditions mandated by local safety policies.
Long-Term Applications
These are promising but require further research, scaling, validation, or standardization.
- Generalist humanoids in public and commercial spaces (retail, hospitality, healthcare logistics)
- AME-2-style terrain-aware control extended to whole-body navigation in crowds and clutter while handling stairs and sparse contacts.
- Dependencies: Social navigation, human-safety certification, energy efficiency, semantic understanding; extensive real-world finetuning.
- Exoskeletons and powered prosthetics with terrain-aware assistance (healthcare)
- Attention-based terrain encoding and uncertainty gating for safe foot placement and balance support.
- Dependencies: Medical-grade safety, closed-loop human–robot interaction, haptic interfaces, clinical trials, FDA/CE approvals.
- Planetary and lunar exploration with legged rovers (aerospace)
- Uncertainty-aware elevation mapping handles occlusions and sensor degradation in extreme lighting and dust; attention focuses on sparse footholds.
- Dependencies: Radiation-hardened compute, low-power sensing, ultra-reliable odometry without GPS, extreme temperature operation.
- Cooperative multi-robot mapping and traversal (robotics, software)
- Share uncertainty-aware elevation layers across teams to accelerate safe traversal and map updates in dynamic environments.
- Dependencies: Robust multi-robot comms, map alignment under drift, conflict resolution in stochastic fusion, cybersecurity.
- Adverse-weather and degraded sensing extensions (autonomy robustness)
- Integrate radar/event cameras and multispectral depth to maintain mapping under fog, rain, snow, dust, or glare.
- Dependencies: Sensor fusion learning, new synthetic data generation pipelines, re-tuned fusion thresholds.
- Dynamic and deformable terrain reasoning (research frontier)
- Extend elevation mapping to handle moving/deformable substrates (loose gravel, mud, debris) with predictive uncertainty and contact modeling.
- Dependencies: Coupled perception–dynamics models, real-time estimation of terrain compliance and slip, new rewards/penalties for deformable contacts.
- Continual learning and on-device adaptation (software, MLOps)
- Safe field fine-tuning of mapping and control modules from logged uncertainty and attention patterns to new sites/terrains.
- Dependencies: Guarded updates, rollback mechanisms, data governance, compute budgets for on-site training.
- Standards and certification for learning-based locomotion (policy, regulation)
- Frameworks that mandate uncertainty-aware perception, interpretable attention diagnostics, safety thresholds, and post-incident audit logs.
- Dependencies: Industry–regulator working groups, shared benchmarks, third-party testing facilities.
- Cross-platform locomotion APIs and marketplace (software ecosystem)
- Interoperable SDKs that let OEMs plug AME-2-like mapping/locomotion into different form factors (quadrupeds, bipeds, centaurs).
- Dependencies: Common message schemas, capability discovery, licensing, sustained maintenance.
- Risk analytics and insurance products using uncertainty telemetry (finance, risk)
- Pricing models that factor robot-reported uncertainty, contact events, and environment classes to insure operations on risky sites.
- Dependencies: Data-sharing agreements, privacy-preserving telemetry, actuarial validation on longitudinal deployments.
- Offshore and high-consequence environments (energy, maritime, nuclear)
- Legged access to ladders, catwalks, and irregular structures under occlusion and vibration using uncertainty-aware planning.
- Dependencies: Corrosion/salt protection, intrinsically safe designs (ATEX), rigorous fail-safe verification, operator accreditation.
- Education and workforce development (education, training)
- Curriculum modules on uncertainty-aware mapping, attention diagnostics, and sim-to-real RL for legged robots.
- Dependencies: Teaching kits, affordable simulators/hardware, reproducible labs and datasets.
Notes on general assumptions/dependencies across applications:
- Sensors and state estimation: Depth sensing (camera or lidar) and drift-bounded odometry are required for the proposed mapping; severe occlusions or adverse weather may need sensor fusion.
- Compute and power: Onboard CPU inference is feasible for policies; mapping pre/post-processing must fit embedded budgets; battery life and thermal constraints limit mission duration.
- Training and domains: Significant GPU time and domain randomization are needed; generalization depends on the diversity of synthetic and simulated terrains and sensor models.
- Safety and compliance: High-uncertainty handling, conservative modes, logging, and human override are critical for real deployments; sector-specific regulations apply.
Glossary
- Actuator dynamics: The physical behavior of robot actuators (motors and transmissions) modeled to match real hardware behavior during control and simulation. "We model the actuator dynamics for sim-to-real transfer."
- Actuator network: A learned model that approximates actuator behavior to improve realism in simulation or control. "In simulation, we use the actuator network~\cite{hwangbo2019learning} for ANYmal-D"
- Action distillation: A training technique where a student policy learns to mimic the actions of a teacher policy, often to improve efficiency or robustness. "our student training objective linearly combines the RL losses from PPO, the action distillation losses from~\cite{wang2025integrating}, and a representation loss"
- Asymmetric actor–critic: A reinforcement learning setup where the actor and critic use different observation sets or architectures (e.g., the critic may have privileged information). "We adopt asymmetric actorâcritic training~\cite{DBLP:conf/rss/PintoAWZA18}."
- Attention-based Map Encoding (AME-2): An encoder architecture that extracts local and global features from maps and applies attention to focus on salient regions, producing a terrain-aware representation for control. "we present AME-2, a unified RL framework for perceptive legged locomotion with an Attention-based Map Encoding architecture trained jointly with the controller."
- Bayesian learning: A probabilistic training approach that models uncertainty (e.g., predicting distributions rather than point estimates). "uses a lightweight neural network trained via Bayesian learning~\cite{kendall2017uncertainties} to predict local elevations with per-cell uncertainty estimates."
- Convolutional neural network (CNN): A neural network architecture using convolutional layers, commonly for spatial feature extraction. "The AME-2 encoder first extracts local map features with a convolutional neural network (CNN)"
- DC-motor model: A physics-based model of a DC motor used to simulate or identify actuator behavior. "and an identified DC-motor model for TRON1."
- Domain randomization: Training-time randomization of environment and sensor parameters to improve robustness and transfer to real-world conditions. "We employ domain randomization~\cite{tobin2017domain} during training to enhance robustness and facilitate sim-to-real transfer."
- Egocentric elevation grid: A height map represented in the robot’s local (ego) frame, encoding the 3D coordinates of terrain points. "Ground-truth mapping represents each point in the egocentric elevation grid by its 3D coordinates ."
- Egocentric elevations: Local terrain height values queried around the robot’s current pose for control input. "We then query egocentric elevations and associated uncertainties as the map inputs for the controller."
- Isaac Gym: A GPU-accelerated physics simulation platform for large-scale parallel training of robotic policies. "We train our controllers in Isaac Gym~\cite{makoviychuk2021isaac} with the PPO implementation in RSL-RL~\cite{schwarke2025rsl}."
- Joint PD targets: Desired joint positions and velocities provided to proportional–derivative controllers to generate torques. "The policy actions are joint PD targets~\cite{xbpeng_choiceofA} tracked at 400 Hz on real hardware."
- Left-right symmetry augmentation: A training augmentation that mirrors motions or states to exploit bilateral symmetry for sample efficiency and style. "We also apply left-right symmetry augmentation from \cite{hoeller2024anymal} to the critic to improve sample efficiency and motion style"
- Long-Short I/O (LSIO): A temporal encoding method that processes stacked observations to capture both short- and long-term dynamics. "we stack the proprioceptive observations... from the past 20 steps and use Long-Short I/O (LSIO)~\cite{li2024reinforcement} to obtain a temporal embedding"
- Mixture-of-experts (MoE): An architecture that combines multiple expert subnetworks with a gating mechanism for improved function approximation. "we use the mixture-of-experts (MoE) design from~\cite{chen2025gmt}, which is powerful for function fitting yet much more computationally efficient to optimize."
- Multi-head attention (MHA): An attention mechanism that uses multiple parallel attention heads to capture diverse dependencies. "a multi-head attention (MHA) module~\cite{vaswani2017attention} with the pointwise local features serving as keys and values."
- Negative log-likelihood (NLL) loss: A probabilistic loss function that encourages models to fit predicted distributions to observed data. "Compared to the standard negative log-likelihood (NLL) loss used in classical Bayesian learning~\cite{kendall2017uncertainties}"
- Neural mapping: A learned mapping approach where neural networks produce terrain representations (e.g., elevations and uncertainties) from sensor data. "Our neural mapping augments this with an uncertainty channel and produces a 4D representation "
- Neural processes: A class of models that combine neural networks with stochastic processes to model uncertainty and spatial functions. "leverages neural processes~\cite{kim2019attentive} to model terrain elevation"
- Odometry: Estimation of a robot’s pose over time based on motion sensors, used to fuse local maps into a global frame. "These local maps are fused into a consistent global frame with odometry, providing a fast and uncertainty-aware representation"
- ONNX Runtime: A high-performance inference engine for running machine learning models in the ONNX format. "We deploy the controllers using ONNX Runtime~\cite{onnxruntime}."
- Partially observable Markov decision process (POMDP): A framework for decision-making under uncertainty where the agent has incomplete observations of the environment state. "We formulate the problem as a partially observable Markov decision process (POMDP)"
- Probabilistic Winner-Take-All: A stochastic map fusion strategy that overwrites cells based on the relative precision of measurements to avoid overconfidence in uncertain regions. "Instead, we employ a Probabilistic Winner-Take-All strategy."
- Proprioception: Internal sensing of the robot’s state (e.g., velocities, joint positions) used as policy input. "Proprioception observations include base linear velocity ... base angular velocity , projected gravity , joint positions , joint velocities , previous actions, and goal commands ."
- Proximal Policy Optimization (PPO): A reinforcement learning algorithm that optimizes policies with clipped surrogate objectives for stability. "and optimize the policies using PPO~\cite{schulman2017proximal} in parallel simulation"
- Raytracing: A geometric technique to compute intersections (e.g., sampling elevations) by casting rays into scene meshes. "using raytracing with Warp~\cite{warp2022}"
- Reinforcement learning (RL): A learning paradigm where agents learn policies by maximizing cumulative rewards through interaction. "We use RL to train terrain-aware locomotion policies that reach position and heading goals."
- RSL-RL: A reinforcement learning library providing implementations (e.g., PPO) for robotics. "with the PPO implementation in RSL-RL~\cite{schwarke2025rsl}."
- Sensorimotor policies: End-to-end policies mapping raw sensory inputs and proprioception directly to actions. "These sensorimotor policies have demonstrated highly agile behaviors on challenging courses~\cite{cheng2024extreme, zhuang2025humanoid,chanesane2025soloparkour}"
- Sim-to-real transfer: Techniques to ensure policies trained in simulation perform well on real hardware. "aiding sim-to-real transfer."
- Stop-gradient: An operation that prevents gradients from flowing through a tensor during backpropagation. "The operator denotes the stop-gradient operation."
- Teacher–Student RL: A training paradigm where a student policy learns under supervision from a more capable teacher policy, often with privileged inputs. "We use TeacherâStudent RL~\cite{lee2020learning, miki2022learning, rudin2025parkour, wang2025integrating} to facilitate sim-to-real transfer."
- U-Net: A convolutional encoder–decoder architecture with skip connections, commonly used for dense predictions. "We use a lightweight U-Net~\cite{ronneberger2015u} model with a gated residual design for the estimation."
- Uncertainty-aware terrain representations: Map representations that explicitly encode prediction uncertainty (e.g., variance) to handle occlusions and noise. "provides fast, uncertainty-aware terrain representations robust to noise and occlusions"
- Warp: A GPU-accelerated simulation and computation library used here for fast geometric operations. "using raytracing with Warp~\cite{warp2022}"
Collections
Sign up for free to add this paper to one or more collections.

