- The paper proposes a hybrid method combining explicit foot position maps with a CoP-based stability reward to enhance precision and robustness in quadrupedal locomotion.
- It utilizes an attention-based neural network with enriched heightmap encodings and global velocity tracking to maintain dynamic stability and prevent reward exploitation.
- Experimental results demonstrate up to a 15% improvement in success rates on challenging terrains, with ablations confirming the benefits of each architectural component.
Introduction
This paper addresses the challenge of robust and precise quadrupedal locomotion over complex, unstructured terrain. Traditional optimization-based controllers offer high foot placement precision but lack robustness, while end-to-end deep RL methods exhibit robustness but limited control over foot placement and formal stability margins. The paper proposes a hybrid approach incorporating a novel foot position map embedded into the heightmap and a center of pressure (CoP)-based dynamic stability reward within an attention-based neural network policy. The main objectives are to enable explicit awareness of foot placement relative to exteroceptive terrain data, guide the policy toward dynamically stable behaviors, and prevent exploitation of reward functions via global velocity tracking.
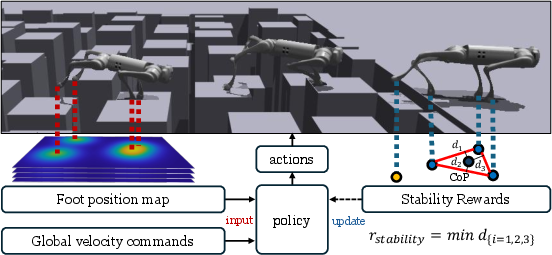
Figure 1: Overview of the proposed method. The integration of a foot position map and a stability reward enables reliable locomotion over highly challenging terrain.
Methodology
A critical innovation is the introduction of an explicit foot position map, which spatially codes the estimated foot locations in a map matching the granularity and reference frame of the terrain heightmap. Each foot is represented as a discretized Gaussian centered at its current position, yielding a tensor of shape H×W×4, where each channel corresponds to one foot. This approach sidesteps the need for the policy to implicitly decode foot positions from joint angles—a known limitation in prior attention-based methods [doi:10.1126/scirobotics.adv3604].
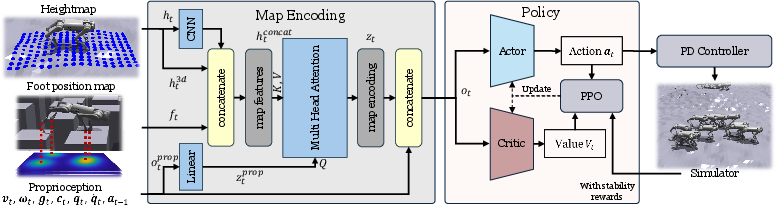
Figure 2: Architecture showing concatenation of foot position maps to the heightmap and channel-wise encoding, with the addition of a stability reward signal during training.
These enriched maps, combined with the robot's proprioceptive data, are processed through convolutional and multi-head attention layers. This results in perceptual representations that are both precise (reflecting contact status and proximity to obstacles) and informative for downstream foot placement decisions.
Dynamic Stability Reward (CoP-Based)
To promote dynamically stable locomotion, the reward function includes a term proportional to the minimum distance from the estimated center of pressure (CoP) to the boundary of the support polygon formed by ground-contacting feet. This reward is a continuous metric, encouraging the policy to maintain margin against potentially unstable edge cases while remaining agnostic to model and actuation uncertainties.
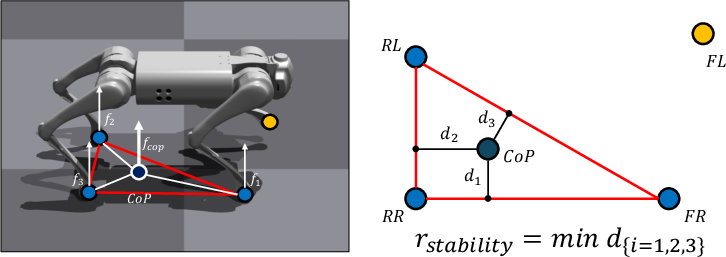
Figure 3: Calculation of the CoP-based stability reward: the minimum distance from CoP to the support polygon boundary is used as a reward signal.
Ablations demonstrate that this CoP-based reward yields a distinct improvement in both the overall success and survival rates versus static center of mass or capture point-based rewards, particularly in non-flat terrain regimes.
Global Velocity Tracking
To counteract reward hacking observed with the standard local velocity command approach (e.g., the robot rotating to avoid challenging obstacles while maximizing their reward), the paper proposes a global velocity tracking strategy. Here, target velocities are defined in global coordinates and mapped onto the robot's frame, constraining the agent to traverse intended trajectories regardless of orientation and preventing evasive shortcuts.
Experimental Setup
The training curriculum spans six terrains (smooth, rough, discrete, stairs up, stairs down, and stepping stones), selected to build competency progressively. The stepping stone environment varies in stone size, spacing, and elevation, creating a controlled spectrum of difficulty. Training employs 4096 parallel environments using PPO in Isaac Gym [makoviychuk2021isaac], with reward components detailed for velocity tracking, regularization, and stability.
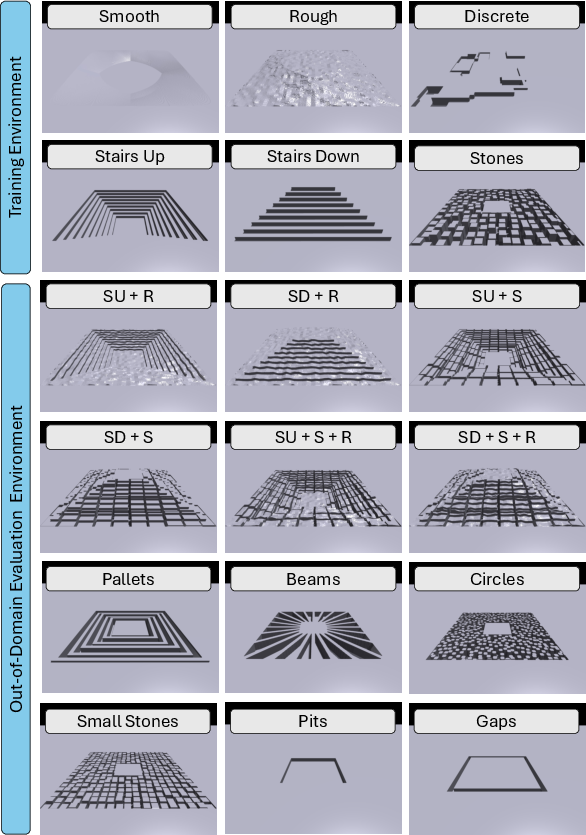
Figure 4: Spectrum of in-domain and out-of-domain terrains used for training and evaluation, including complex composites not seen during training.
Zero-shot evaluations are performed on out-of-domain (OOD) terrains including novel composites and highly sparse trajectories. Policy performance is measured by success rate (task completion), survival rate (robot not falling), velocity tracking error, and energy consumption.
Results
Quantitative Evaluation
The proposed method achieves the highest success and survival rates across all terrain types, surpassing attention, transformer, CNN, and MLP baselines by margins of up to 15% in OOD tasks.
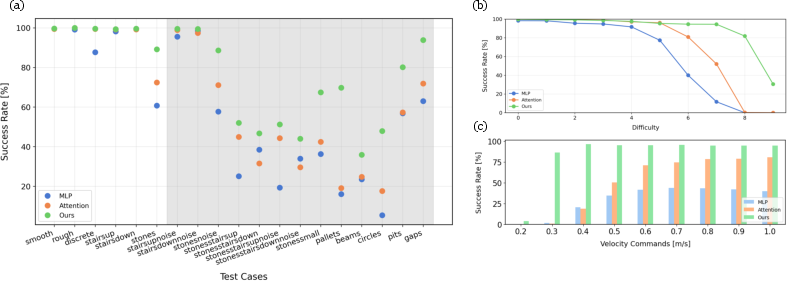
Figure 5: (a) The proposed method yields higher success rates on all terrains. (b) Improvement at higher levels of terrain difficulty. (c) Significant advantage at lower commanded velocities.
For stepping stone terrains, the method exhibits sustained high performance up to extreme difficulty levels (stone size/gap/height), where baseline policies degrade to near-zero success. Notably, with stones at level 8 difficulty, the proposed policy maintains ∼80% success, while others fail entirely above level 6–7.
Ablations indicate that introducing the footmap yields a +10% jump in success over pure attention policies, while the CoP stability reward adds a further +2.4%.
Qualitative Evaluation
Visual analysis reveals that the policy consistently adapts to abrupt terrain changes, transitioning between locomotor gaits (trot, leap) and modulating speed before complex obstacles.
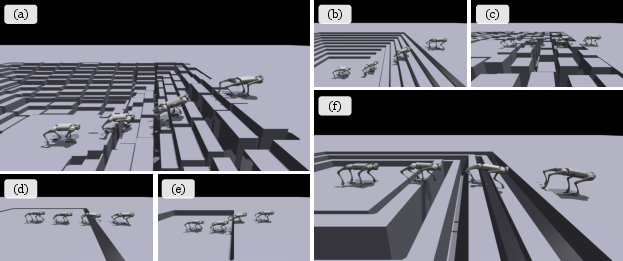
Figure 6: Trajectories over diverse challenging terrains, including combinations not encountered during training.
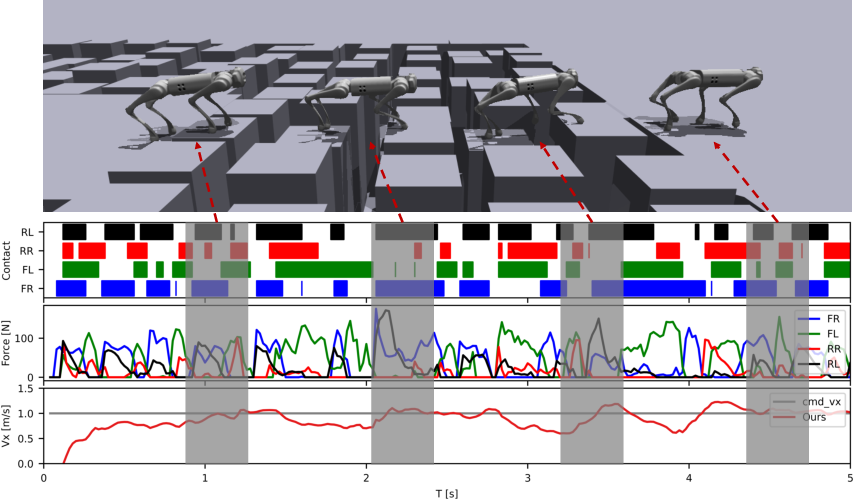
Figure 7: Detailed foot contact and movement analysis over stepping stones, showing adaptive strategy between feet (FR, FL, RR, RL).
Impact of Stability Reward Choices
CoP-based rewards outperform static CoM and capture point (CP) rewards, particularly on non-flat, dynamic regimes. CoM-based rewards degrade under complex terrain, and CP-based rewards penalize at high speed due to support polygon time horizon incongruence.
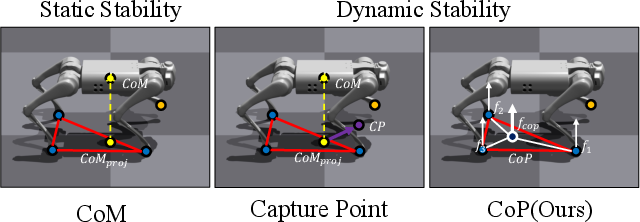
Figure 8: Comparative illustration of stability reward signals based on CoM, CP, and CoP.
Global Velocity Tracking
Global velocity tracking eliminates exploitative behaviors observed with local velocity tracking. Robots no longer “run away” from challenging areas, effectively increasing trial diversity and robustness.


Figure 9: Local velocity tracking versus global velocity tracking—global velocity tracking compels true traversal over obstacles.
Sim-to-Sim Transfer
The method generalizes successfully from simulation to the Gazebo physics engine, using Lidar-based elevation maps and domain randomization for sim-to-sim adaptation.
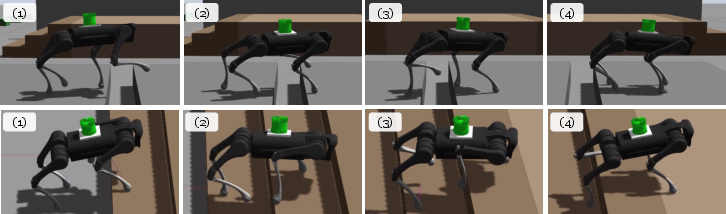
Figure 10: Transfer to the Gazebo simulator, exhibiting successful traversals of gaps and stairs.
Implications and Future Directions
The explicit incorporation of end-effector spatial representations into policy exteroception creates a paradigm where RL policies can reconcile the high-level foot placement precision of optimization-based planners with the adaptability of learning-based approaches. The CoP-based stability reward introduces a practical dynamic stability margin without requiring complex analytical models, which is promising for transfer to hardware where dynamics and actuation are only partially known.
Methodologically, this framework invites extension to other legged morphologies, complex multi-body robots, or even articulated manipulation in cluttered environments. Scaling to real-world deployment will require additional sim-to-real transfer strategies, robust sensor fusion, and potentially, adaptation to online estimation of terrain unmodeled effects.
Conclusion
The paper demonstrates that explicit spatial encoding of foot positions, combined with a dynamic stability reward and global velocity tracking, enables state-of-the-art performance in both in-domain and OOD quadrupedal locomotion tasks. This approach provides valuable architectural and reward design principles for future research in robotic autonomy over unstructured terrain, reducing reliance on brittle hand-crafted planners and advancing zero-shot generalization in robotics (2604.02744).