- The paper introduces CReF, a framework that directly fuses forward-facing depth images with proprioceptive signals to eliminate intermediate geometric abstractions.
- The methodology employs cross-modal attention, gated residual fusion, and highway-gated GRU to integrate multimodal features and guide precise foothold placement.
- Experimental results show over 90% success rates in challenging simulated and real-world terrains, highlighting robust generalization and zero-shot transfer capabilities.
CReF: Cross-modal and Recurrent Fusion for Depth-conditioned Humanoid Locomotion
Introduction
The paper introduces CReF, a perception-driven humanoid locomotion framework that directly fuses forward-facing depth images and proprioceptive inputs to synthesize joint targets, eliminating the need for intermediate geometric abstractions. CReF’s architecture integrates cross-modal attention, gated residual fusion (GRF), and a highway-gated GRU-based recurrent module, complemented by a terrain-aware foothold placement reward. The approach is evaluated on both simulated and physical hardware, demonstrating robust, generalizable behavior in highly challenging and diverse real-world environments.
CReF explicitly challenges previous locomotion paradigms that relied on geometric terrain abstractions—such as robot-centric height maps—or supplementary supervision via auxiliary reconstruction or teacher-driven targets. Its design is motivated by the limitations of such intermediates, which tend to restrict performance in complex vertical or cluttered environments and may propagate representational biases.
CReF Architecture
CReF’s policy network accepts two sensing modalities at each timestep: rich proprioceptive signals and forward-facing depth images. Proprioceptive streams are tokenized and fused with CNN-derived depth tokens via cross-modal attention, using proprioceptive embeddings as the query for extracting action-relevant terrain cues from the depth modality. The cross-modal fusion output then proceeds through a GRF block, which mixes and gates residuals for multimodal feature integration.
For temporal reasoning, the fused feature is processed by a GRU, with a subsequent highway-style gating mechanism that adaptively blends recurrent and feedforward features dependent on the locomotion state. This design allows the policy to accentuate memory-dependent features in ambiguous or risky transitions (e.g., initiating a stair descent), while emphasizing instantaneous feedforward cues in more stable regimes.
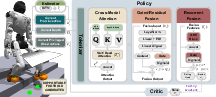
Figure 1: Overview of the CReF policy network, highlighting its cross-modal attention, GRF, recurrent fusion, and foothold placement components.
A primary contribution is the proposed terrain-aware reward for principled guidance of foothold placement. Rather than penalizing "do-not-step" zones, CReF recognizes locally supportable regions using near-foot point clouds, conditioned on the commanded locomotion. Foothold candidates are dynamically extracted based on planarity, orientation, and elevation criteria, and contact events are rewarded proportionally to their proximity to these supports. This approach results in more anticipatory, precise, and consistent contact generation, particularly critical during stair transitions and rapid terrain changes.
Experimental Results
Simulation
CReF exhibits high traversal success rates across a taxonomy of terrain categories (stairs, gaps, platforms), outperforming all ablated model variants and the HPL perceptive baseline across in-distribution and out-of-distribution (OOD) evaluations. Performance degradation is most pronounced when cross-modal attention is omitted, highlighting the critical role of proprioception-conditioned depth feature extraction. Removing GRF or the highway gate similarly reduces robustness, especially in high-difficulty regimes.
The effect of the terrain-aware foot placement reward is evident in both reduced mean deviations and lower failure rates on stairs, specifically in descent, where precision is essential to avoid edge contact and missteps.
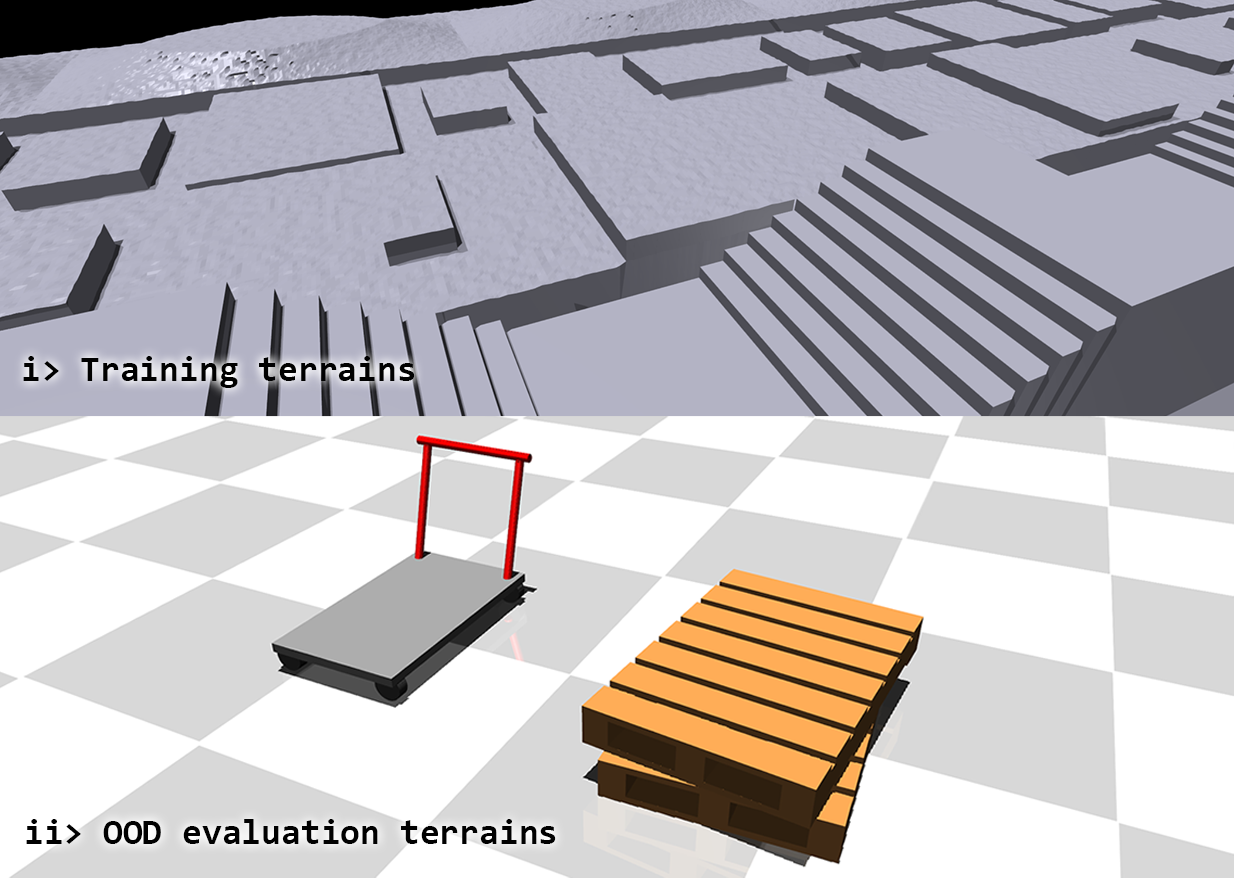
Figure 2: Simulated training and OOD terrains used for evaluation.
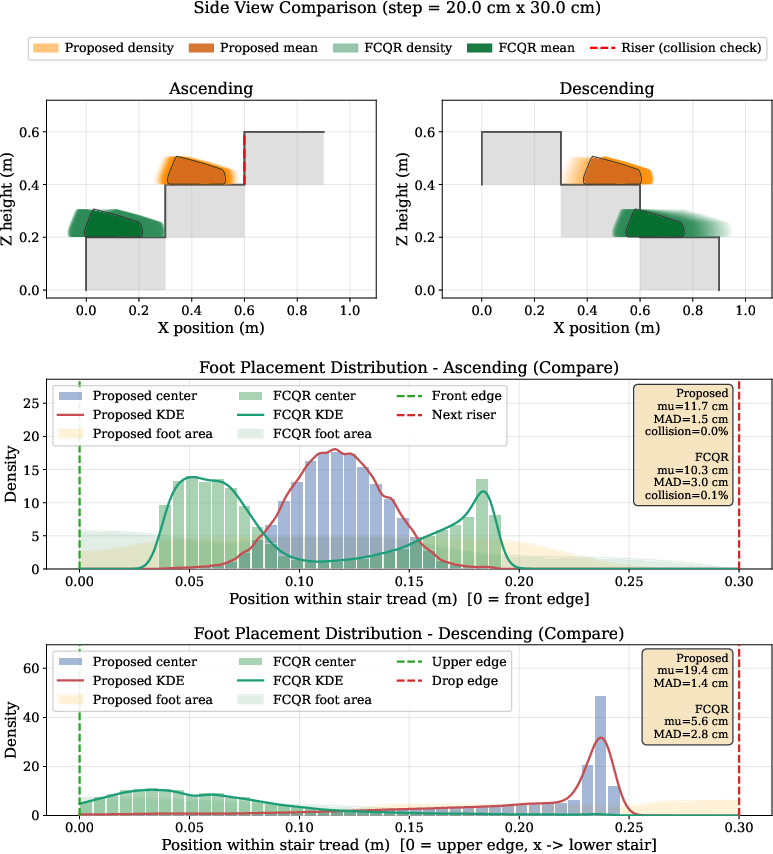
Figure 3: Comparison of stair foothold distributions with CReF's placement reward vs. the FCQR baseline; CReF yields higher precision and eliminates observed contact failures.
Memory Utilization Analysis
Analysis of the highway-gate activations demonstrates that CReF adaptively prioritizes temporal memory during phases of high risk (e.g., non-coplanar contact, large roll/pitch, or flight) and relies more on instantaneous evidence during stable support, validating the architectural hypothesis.
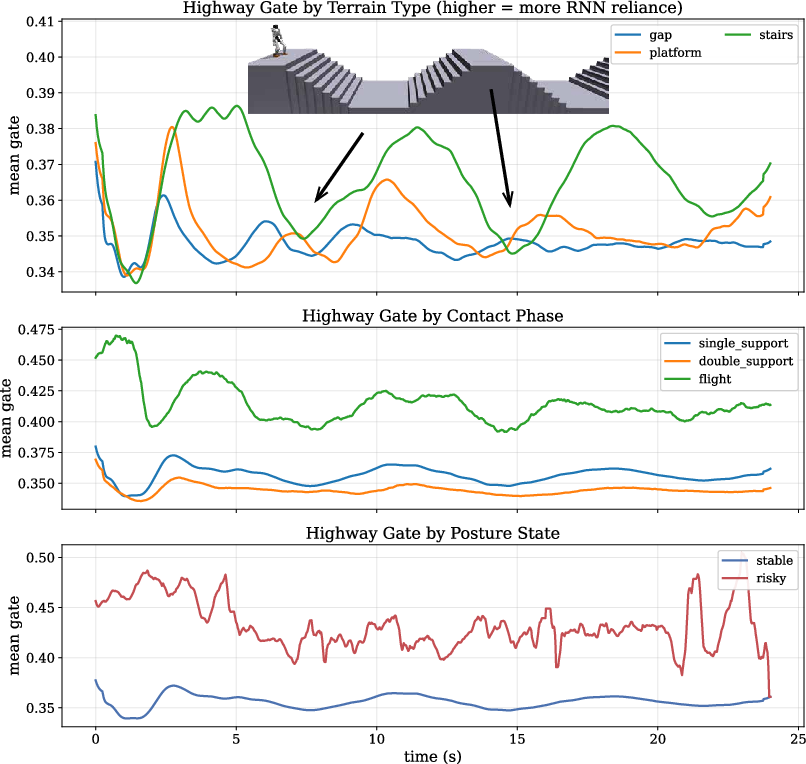
Figure 4: The policy’s highway gate allocates greater weight to recurrent memory under ambiguous or high-risk locomotion states.
Real-World Deployment
Without domain randomization or synthetic depth corruption during training, CReF transfers zero-shot to a physical humanoid on the AGIBOT X2 Ultra. It achieves high reliability across multiple terrain classes, including indoor stairs, 40 cm high platforms, 80 cm gaps, and OOD configurations, with success rates above 90% across diverse trials.
Real-world tests also validate robust generalization in the presence of hardware sensor imperfections such as depth holes, reflective interference, and visually cluttered or unexpected geometry—including scenarios with handrails, hollow assemblies, and outdoor settings with heavy occlusion and non-traversable regions.

Figure 5: Robust real-world locomotion, including stair, gap, and platform traversal, with transfer well beyond the simulation terrain distribution.

Figure 6: Hardware deployments in diverse scenes, with the policy maintaining stable control and robust responses to OOD perception artifacts.
Practical and Theoretical Implications
CReF substantiates the viability of direct, raw, proprioception-depth fusion for anticipatory humanoid locomotion, bypassing intermediate geometric surrogates or the need for privileged supervision. This paradigm enables policies to capture aspects of the environment that are lost or abstracted away in planar or height-based terrain representations, facilitating better anticipation and adaptability—especially vital for vertical and non-planar obstacles common in human-centric environments.
On a theoretical level, the work demonstrates that task-conditioned cross-modal attention and adaptive temporal fusion can significantly enhance sample efficiency, foot placement accuracy, and zero-shot transfer robustness. The terrain-aware reward—by providing dense, anticipatory shaping—moves beyond purely prohibitive strategies, suggesting extensions to more dexterous or non-standard morphologies, dynamic tasks, or highly variable environments. The demonstrated zero-shot sim-to-real transfer also supports the effectiveness of the system’s inductive biases and training realism.
Future Directions
Current limitations include reliance on depth-only sensing, which is vulnerable to failures in high-reflectance, transparent, or textureless scenes, and discards rich appearance cues available in RGB. Future research should explore integrating binocular or multimodal (RGB-D) perception, as well as leveraging scene semantics for even stronger anticipatory control. Investigations into extending the architecture to whole-body manipulation, dynamic non-contact tasks, or lifelong adaptation in-the-wild could significantly broaden the practical impact.
Conclusion
CReF establishes that direct, cross-modal, and recurrent fusion of proprioception and depth is a scalable and robust approach for perception-driven humanoid locomotion in diverse, real-world settings. The architecture’s design choices—particularly cross-modal attention, GRF, highway-gated recurrence, and terrain-aware contact rewards—enable significant improvements in both policy robustness and generalization, advancing the state-of-the-art in zero-shot transfer for legged robots (2603.29452).