Gallant: Voxel Grid-based Humanoid Locomotion and Local-navigation across 3D Constrained Terrains
Abstract: Robust humanoid locomotion requires accurate and globally consistent perception of the surrounding 3D environment. However, existing perception modules, mainly based on depth images or elevation maps, offer only partial and locally flattened views of the environment, failing to capture the full 3D structure. This paper presents Gallant, a voxel-grid-based framework for humanoid locomotion and local navigation in 3D constrained terrains. It leverages voxelized LiDAR data as a lightweight and structured perceptual representation, and employs a z-grouped 2D CNN to map this representation to the control policy, enabling fully end-to-end optimization. A high-fidelity LiDAR simulation that dynamically generates realistic observations is developed to support scalable, LiDAR-based training and ensure sim-to-real consistency. Experimental results show that Gallant's broader perceptual coverage facilitates the use of a single policy that goes beyond the limitations of previous methods confined to ground-level obstacles, extending to lateral clutter, overhead constraints, multi-level structures, and narrow passages. Gallant also firstly achieves near 100% success rates in challenging scenarios such as stair climbing and stepping onto elevated platforms through improved end-to-end optimization.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces Gallant, a way to help a humanoid robot walk and find its way through tricky 3D spaces. Instead of only looking at the ground, the robot “sees” the whole space around it—walls, ceilings, platforms, steps—using laser scanners and a simple 3D map made of tiny blocks. With this, one single learned “brain” controls the robot so it can climb stairs, duck under low ceilings, pass through doors, and step across gaps.
What questions does the paper try to answer?
- How can a robot understand the full 3D shape of the world around it, not just the floor?
- Can we make perception simple and fast enough to run on the robot in real time?
- Is it possible to train one general policy (one “brain”) that handles many kinds of obstacles, instead of separate special-case controllers?
- Will training in a realistic simulator transfer to the real world without extra tuning?
How does Gallant work? (Methods explained simply)
Think of Gallant as three main pieces working together:
- Seeing the world with LiDAR
- LiDAR is like a spinning laser tape measure. It sends out many beams and measures where they hit, building a cloud of points that shows where surfaces are.
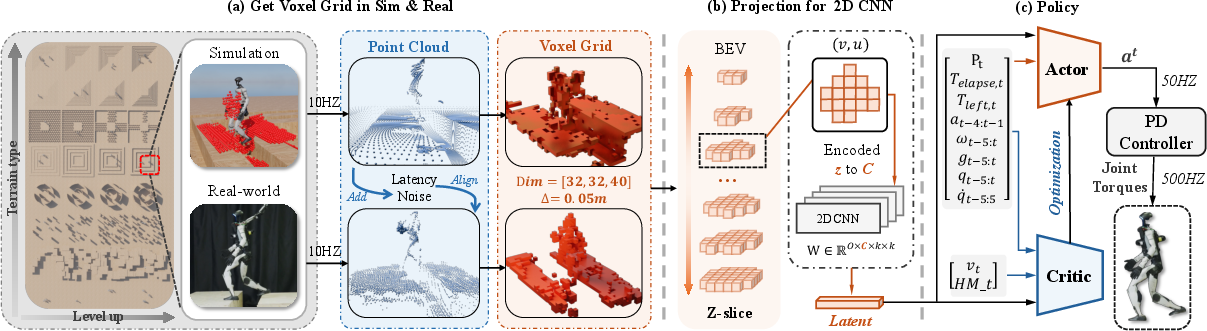
- Those points are turned into a “voxel grid,” which is like a 3D Minecraft world: space is split into small cubes (voxels), and each cube is either empty or occupied.
- Reading the voxel grid with a lightweight neural network
- The voxel grid is shaped like a stack of thin layers (from floor to ceiling).
- Gallant treats height layers like “channels” in an image and uses a fast 2D CNN (a pattern-finding tool commonly used on images) across the floor plan, while mixing the height layers like pages in a book.
- This is called a “z-grouped 2D CNN.” It keeps the good 3D information but is much faster than heavier 3D networks, making it practical on a robot’s computer.
- Training in a realistic simulator
- The team built a LiDAR simulation that adds the kinds of imperfections real sensors have, like noise, small position errors, and delay (100–200 ms). This is called domain randomization—intentionally adding “messiness” so the policy doesn’t get surprised later.
- Importantly, the simulator includes the robot’s own moving body in the LiDAR scans (self-scan), just like in real life, so the robot learns to handle occlusions (when its legs block the laser’s view).
- The robot is trained with a reward for reaching a goal within 10 seconds, across eight types of terrains that gradually get harder (a curriculum), such as stairs, doors, platforms with gaps, ceilings, and “stepping stones.”
What did they find, and why is it important?
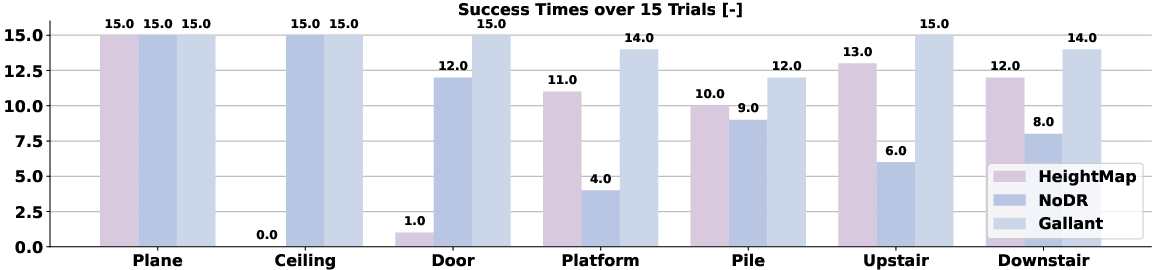
- One policy for many obstacles: Gallant learns a single end-to-end policy that works on lots of 3D challenges—ground-level obstacles, sideways clutter (like pillars and walls), and overhead obstacles (low ceilings). No hand-tuned modes needed.
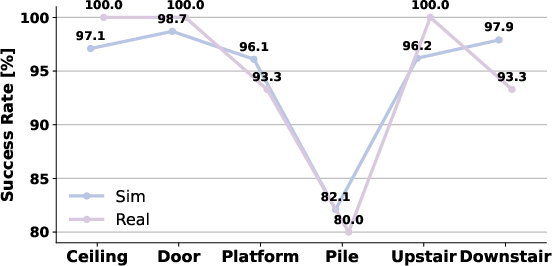
- High success in tough tasks: It gets near 100% success on climbing stairs and stepping onto elevated platforms in simulation, and it transfers well to the real robot.
- Better than “flattened” maps: Methods that compress 3D into a 2.5D elevation map (a “flattened” height picture of the ground) struggle with doors, ceilings, and multi-level structures. Gallant’s voxel grid keeps the full 3D shape, so it can duck under ceilings, pass narrow gaps, and plan steps onto platforms.
- Fast and efficient perception: The z-grouped 2D CNN processed voxel grids more efficiently than typical 3D CNNs and didn’t suffer the overhead of sparse 3D methods at this scale. That makes it practical for real-time use on the robot.
- Real-world transfer: Because the simulator modeled noise and delay, the trained policy worked on a real humanoid robot with dual LiDAR sensors, successfully handling ceilings, doors, platforms, gaps, stepping stones, and stairs.
Why does this matter?
Humanoid robots need to move safely in real places—offices, homes, factories—where hazards are not just on the ground. Gallant shows a simple, robust way to give robots a full 3D “sense” of their surroundings and turn that into stable, real-time control. This makes robots better at avoiding collisions, stepping correctly, and planning routes through tight spaces.
What are the implications and what’s next?
- Safer navigation in complex spaces: Keeping the full 3D structure makes robots better at anticipating collisions above, beside, and below them, not just on the floor.
- Sim-to-real you can trust: A realistic training pipeline with sensor noise and delay helps policies work in the real world without extra tweaking.
- Practical onboard computing: The efficient voxel-plus-2D-CNN design is light enough to run on a robot’s computer, so it can react quickly.
- Current limitation: LiDAR delay (about 100–200 ms) still makes very precise foot placement challenging, especially on small stepping stones.
- Future directions: Use faster sensors or combine Gallant with lower-latency perception so the robot can be even more reactive and push success rates closer to 100% on all terrains.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper that future researchers could address:
- Explicit latency compensation: The policy does not incorporate predictive models or temporal filtering to counter ~100–200 ms LiDAR delay (e.g., spatiotemporal voxel fusion, motion-compensated occupancy, recurrent architectures, or model-based prediction).
- Temporal perception: Voxel inputs are single-frame and lack history; evaluate stacking voxel grids over time, 4D convolutions, or memory modules (GRU/LSTM/transformers) to exploit temporal context and improve robustness to sensor lag and occlusions.
- Dynamic obstacles: Training and deployment are focused on static scenes; systematically evaluate and extend to moving obstacles (humans, pets, other robots) with explicit dynamic-object detection and avoidance.
- Foothold selection on sparse support (Pile): Failure analyses are limited; investigate per-foot local perception windows, affordance prediction (support area, friction, slope), contact-level planners, and explicit foothold candidate scoring to improve success rates on stepping-stone-like terrains.
- Perception representation granularity: Binary occupancy discards uncertainty and intensity; explore probabilistic occupancy, reflectivity, multi-return statistics, height distributions per voxel, signed distance fields, or distance transforms to encode clearance and improve contact-safe planning.
- Field-of-view and multi-scale design: The fixed local volume (1.6 m × 1.6 m × 2.0 m) may be insufficient for faster motion or anticipatory planning; evaluate adaptive volumes, multi-scale pyramids, and hierarchical voxel representations that balance near-field precision and far-field context.
- Orientation robustness: The egocentric grid rotates with the torso; characterize and improve robustness under large pitch/roll/yaw, and assess SE(3)-equivariant or rotation-aware architectures versus current z-as-channel 2D CNNs.
- Sensor configuration generality: Results are for dual Hesai JT128 LiDARs; quantify performance with single LiDAR, varied mounting positions, and alternative sensors (solid-state LiDARs, Livox-only) to understand sensitivity to hardware choices and failure modes.
- Adverse sensing conditions: Domain randomization omits material-dependent effects (specular/glass), weather (rain, fog, dust), and strong vibrations; model and evaluate these conditions in simulation and real to stress-test voxel-based policies.
- Real-time mapping pipeline characterization: OctoMap runs at 10 Hz but end-to-end latency, CPU/GPU load, and memory footprint are not reported; measure and compare against alternatives (NVBlox, Voxblox, OpenVDB) to optimize onboard performance.
- Safety guarantees: There are no formal safety constraints or verification; develop collision-avoidance guarantees (e.g., head/shoulder clearance margins), certified reachability, or runtime monitors/fail-safes for deployment among humans.
- Metrics breadth: Evaluation focuses on success rate and collision momentum; add head clearance margins, minimum distance to obstacles, foot slip rate, energy cost, path efficiency, speed, and recovery behaviors to capture safety and efficiency trade-offs.
- Long-horizon/global navigation: Tasks are limited to 10 s local goals; assess integration with global planners for multi-room navigation, longer horizons, and complex sequences (e.g., multiple doors, multi-level transitions).
- Algorithmic diversity: PPO with an MLP actor is the only tested RL setup; benchmark off-policy (SAC/TD3), model-based (Dreamer), and hierarchical methods for sample efficiency, stability, and safety-constrained optimization.
- Reward design transparency and ablation: The paper references prior rewards but does not detail collision penalties or their effects; systematically study reward components (collision penalties, clearance bonuses, energy regularization) and their impact on behavior.
- Compute and efficiency reporting: Training uses eight RTX 4090s; report training time, sample efficiency, inference latency on Orin NX, memory use, and power to enable reproducibility and to guide policy distillation/quantization for broader adoption.
- Fairness of network comparisons: 2D vs 3D/sparse CNN ablations lack parameter/compute normalization; perform controlled comparisons at matched FLOPs/parameters, and include measured inference latencies to substantiate the efficiency claims.
- Simulated LiDAR fidelity: The Warp-based raycasting does not model rolling-shutter timing, scan pattern phase, multi-path, or per-material reflectance; quantify their importance and incorporate them for closer sensor realism.
- Occlusion reasoning: The policy learns implicitly from occlusion “holes” but lacks explicit occlusion-aware features; add ray coverage, free-space confidence, or occlusion masks to reduce misinterpretation of self-occlusions.
- Generalization beyond eight terrain families: Evaluate on unseen terrain types (slopes, rubble, soft/low-friction surfaces, outdoor scenes) and larger environmental variability to establish broader generalization bounds.
- Transfer across robot platforms: Results are limited to Unitree G1; test across different humanoid morphologies, dynamics, and foot geometries to assess portability and required adaptation.
- Sensor fusion opportunities: The approach is LiDAR-only for policy inputs; explore fusing cameras/IMU/foot sensors for semantics (e.g., stair classification), friction estimation, and improved localization under sparse LiDAR returns.
- Asynchronous control–perception coupling: Control runs at 50 Hz with 10 Hz perception; study update-rate mismatches, buffering strategies, and multi-rate observers to reduce stale perception effects.
- Privileged information design: Height maps are critic-only; investigate additional privileged signals (terrain semantics, contact ground truth, friction) for better credit assignment without harming deploy-time robustness.
- Failure taxonomy and countermeasures: Provide detailed failure modes (e.g., head strikes, foot misplacement, late obstacle detection) and targeted mitigations (policy refinement, safety filters, contact replanning) to guide iterative improvement.
- Data and reproducibility: Key training details are deferred to Appendix; release complete hyperparameters, terrain generators, LiDAR simulators, and code to facilitate independent replication and extension.
Practical Applications
Applications of the Gallant Framework
Based on the analysis of the provided research paper, "Gallant: Voxel Grid-based Humanoid Locomotion and Local-navigation across 3D Constrained Terrains," the following bullet-point list outlines actionable use cases categorized into "Immediate Applications" and "Long-Term Applications" for industry, academia, policy, and daily life. These applications will be especially explored with reference to the sectors they are most relevant to.
Immediate Applications
- Robotics Industry
- High-throughput Automation Facilities: Deploy Gallant in manufacturing plants with 3D constrained terrains such as high shelves, overhead tracks, or narrow passages, enabling robots to maneuver efficiently amidst structural complexities.
- Warehouse Logistics Optimization: Implement in warehouses for humanoid robots to autonomously navigate and handle inventory in dense, multi-level storage environments with stairways and platforms.
- Construction Site Navigation: Use Gallant-equipped robots to traverse construction sites with uneven terrains and obstacles, enhancing worker safety by preemptive obstacle analysis and navigation.
- Policy and Daily Life
- Urban Search and Rescue Operations: Equip rescue robots with Gallant's voxel grid perception to efficiently navigate urban disaster sites (e.g., collapsed buildings) with overhead ceilings, narrow spaces, and unstable grounds.
- Smart Home Robotics: Integrate into home robotics systems for improved maneuverability in cluttered domestic settings with objects such as furniture and appliances, complementing current depth-sensor-based navigation solutions.
Long-Term Applications
- Healthcare Sector
- Adaptive Assistive Devices: Develop advanced robotic prosthetics or exoskeletons using Gallant's perception system to facilitate locomotion on complex terrains for individuals with mobility impairments, necessitating further research in hardware miniaturization and power efficiency.
- Academic Research and Development
- Development of Real-Time Micronavigation Frameworks: Research and improve Gallant's algorithms to enable real-time micronavigation and precise movement within highly dynamic and changing environments, supporting studies in mobile robotics and autonomous systems.
- Simulation Training Platforms: Use the framework to enhance virtual training environments for humanoid robots in robotics courses at universities, facilitating experiential learning about navigation in constrained and obstacle-laden terrains.
- Energy and Technology Sectors
- Infrastructure Maintenance: Develop modular robotic units equipped with Gallant's perception system to perform maintenance tasks in large-scale energy facilities, involving scaling and inspecting complex structures, requiring further developments in robustness and autonomy.
Tools, Products, or Workflows
- Robotics Navigation Software: Workflow tools integrating Gallant's perception frameworks for creating modular navigation and movement strategies adaptable across different robots and terrains.
- Voxel-Based Terrain Analytics Tools: Advanced analytics tools for classifying terrains based on voxel data to simulate navigation processes and predict robot interactions in varying environments.
Assumptions and Dependencies
- Real-World Data Collection: Deployment feasibility highly depends on high-fidelity LiDAR systems and datasets reflecting real-world terrains, which are necessary for accurate voxel representation and navigation algorithm training.
- Hardware Compatibility and Scalability: The effectiveness of Gallant may be limited by current sensor and actuator hardware capabilities and its scalability across varied robotic platforms and industries.
- Regulatory and Safety Constraints: Policies regulating the operational safety and testing protocols for humanoid robots in industry and public spaces will impact the scope of deploying Gallant navigation solutions.
These applications showcase how Gallant's innovations extend beyond theoretical advancements, offering significant practical impact across portions of industry, academia, policy, and daily life, while acknowledging the assumptions and dependencies affecting implementation.
Glossary
- Ablation: The systematic removal or alteration of components to evaluate their impact on performance. "Ablation-specific analyses are summarized as follow:"
- Actor–critic: A reinforcement learning architecture with separate policy (actor) and value (critic) networks trained together. "train an actorâcritic policy using Proximal Policy Optimization (PPO)"
- Bounding Volume Hierarchy (BVH): A tree-based spatial acceleration structure used to speed up ray–geometry intersection queries. "Traditional raycasting builds a Bounding Volume Hierarchy (BVH) over scene geometry"
- Collision momentum: A metric quantifying cumulative momentum transferred through unintended contacts to assess collision avoidance. "Collision momentum $E_{\mathrm{collision}$}: cumulative momentum transferred through unnecessary contacts"
- Curriculum-based training: A training strategy that gradually increases task difficulty to improve generalization and robustness. "We adopt a curriculum-based training strategy where terrain difficulty increases progressively."
- Domain randomization: Randomizing simulation parameters (e.g., noise, latency, poses) to improve sim-to-real transfer robustness. "we apply domain randomization:"
- Egocentric grid: A robot-centered spatial representation aligned to the robot’s frame that changes with its pose. "Our voxel input is a compact, egocentric grid of "
- Elevation map: A 2.5D representation that stores terrain heights per ground-plane cell, flattening vertical structure. "Existing perception modules, such as those based on depth images or elevation maps"
- End-to-end optimization: Training that maps raw inputs directly to outputs without intermediate hand-engineered stages. "enabling fully end-to-end optimization."
- FastLIO2: A fast LiDAR-inertial odometry method for real-time pose estimation. "process its data using FastLIO2"
- Field of view (FoV): The angular extent over which a sensor can observe the environment. "their narrow field of view (FoV) and limited range impede reasoning"
- Height map: A grid of elevation values used as a perception signal; here, included as privileged information for the critic. "Gallant feeds a voxel grid to the actor and a voxel grid plus a height map to the critic."
- Latency: Sensing or processing delay that can affect real-time control and perception. "Latency: Simulated at 10 Hz with 100â200 ms delay;"
- LiDAR: A laser-based sensing technology that measures distance to surfaces to form 3D geometry. "In contrast, 3D LiDAR provides detailed scene geometry with a wide FoV"
- Multi-layer perceptron (MLP): A feedforward neural network composed of multiple fully-connected layers. "passed to a multi-layer perceptron (MLP)-based actor for whole-body control"
- OctoMap: An octree-based 3D occupancy mapping framework that builds probabilistic maps from range data. "OctoMap serves as a lightweight preprocessing step"
- Occupancy grid: A discretized 2D or 3D grid where cells represent whether space is occupied or free. "generating a binary occupancy grid at $10Hz$."
- Occupancy tensor: A multi-channel grid (tensor) encoding occupancy across spatial dimensions and height slices. "producing a binary occupancy tensor "
- Partially observable Markov decision process (POMDP): A decision-making model where the agent has incomplete state information. "We formulate humanoid perceptive locomotion as a partially observable Markov decision process (POMDP)"
- Point cloud: A set of 3D points captured by sensors like LiDAR representing scene surfaces. "but its raw point clouds are sparse and noisy"
- Privileged inputs: Additional information available during training (e.g., to the critic) but not used by the deployed policy. "Actor and critic share all features except privileged inputs, which are critic-only."
- Proprioception: Internal sensing (e.g., joint positions, velocities) providing the robot’s body-state information. "These features are fused with proprioceptive signals"
- Proximal Policy Optimization (PPO): An on-policy reinforcement learning algorithm that constrains policy updates for stability. "train an actorâcritic policy using Proximal Policy Optimization (PPO)"
- Raycast-voxelization pipeline: A pipeline that raycasts against geometry and converts returns into voxel occupancy. "we implement a lightweight, efficient raycast-voxelization pipeline using NVIDIA Warp"
- Raycasting: Computing intersections of rays with scene geometry to determine visible surfaces. "Traditional raycasting builds a Bounding Volume Hierarchy (BVH) over scene geometry"
- Rulebook overhead: The bookkeeping cost in sparse convolution frameworks for managing indices and kernel application. "the rulebook overhead of sparse kernels becomes a dominant cost at this scale."
- Simulation-to-reality (sim-to-real): Transferring policies trained in simulation to real-world deployment without performance loss. "simulation-to-reality (sim-to-real) gap"
- Sparse convolution: Convolution tailored to sparse data that avoids computation on empty regions. "sparse convolutions offer little advantage"
- Solid angle: A measure (in steradians) of angular extent used to quantify sensor FoV. "FoV in Solid Angles are computed by parameter of the used sensors."
- Translation-equivariant: A property where shifting the input spatially results in a corresponding shift in the output. "approximately translation-equivariant in yet rotates with the body."
- Voxel grid: A 3D grid of volumetric pixels encoding occupancy, preserving multi-layer scene structure. "We propose voxel grid as a lightweight yet geometry-preserving representation"
- Voxelization: Converting continuous geometry or point clouds into discrete voxel representations. "raycast-voxelization pipeline"
- Warp: A high-performance GPU framework from NVIDIA for simulation and graphics. "using NVIDIA Warp"
- z-grouped 2D CNN: A 2D convolutional network that treats height slices (z) as channels to capture vertical structure efficiently. "We verify that -grouped 2D CNN effectively processes voxel grids"
- Zero-shot sim-to-real transfer: Deploying a policy on real hardware without fine-tuning after simulation training. "enables zero-shot sim-to-real transfer across diverse obstacles"
Collections
Sign up for free to add this paper to one or more collections.